一、SQL Server优化概述
1.1-性能好坏的评判标准?
相应时间快、稳定
什么叫慢?
现有资源没有达到最大吞吐量的前提下,系统如果不能满足合理的预期表现,就可以定义为性能问题。
没有达到最大吞吐量:说明硬件资源充足
合理的预期表现:几个亿数据几毫秒查询出来,不合理
1.2-性能优化的目的?
通过最小化SQL的相应时间、合理增加吞吐量、减少网络延时,去协调、平衡、合理的请求相应。
1.3-有哪些相关误区?
- 误区1:加硬件能够解决性能问题
- 有可能是对的;但是核心公司业务一般不会缺少资源,不到万不得已不会用这种手段。
- 误区2:只要数据库性能好就没问题。
- 小白:将本该在应用层实现的逻辑,放在数据库中去实现,然后通过简单的优化数据库解决这这样的问题。
- 误区3:任何数据库性能问题都可以通过索引解决。
- 索引能够解决单个SQL性能问题,但是也很可能导致其他SQL语句出现性能问题。
- 误区4:编码过于极端
- 所有的逻辑在应用层实现或者都是用存储过程来实现。
1.4-在性能方面有哪些场景的影响因素?
- 数据库结构的设计
- 了解业务:重中之重,只有了解了系统业务逻辑,才能更好的去优化他。
- 优先考虑第三范式设计:冗余
- 避免关联查询带来的好处多一点,还是维护成本高带来的坏处多一点。
- 有一个查询,查询超过10万次/天,3天才修改1次,就可以使用冗余
- 表关联尽可能少
- 让业务逻辑用简单SQL语句实现,避免表关联
- 坚持最小原则
- 适当的地方要使用约束
- 从安全方法考虑;可能会出现性能的影响。
- 事务和隔离级别(ACID重要性)
- SQL语句的编写
- 明确了解业务的需求,需要过滤非必须字段,能否添加索引,如果某个字段有索引,就不要在该字段上使用任何的计算、函数。会发生扫描操作。
- 小表操作优先,小表驱动大表。
- 只查询要的字段,不要使用”*”号
- 简单SQL语句
- 简单的关联2-4个表,或者是单表查询
- 没有复杂的过滤条件,只有2-3个条件判断,并且有一个过滤条件明确可以使用所有操作。
- 如果是过于复制的SQL语句,看能不能查分成几个简单的SQL语句。
- 数据文件配置
- TempDb部署
- SQL Server系统库、全局
- 连接SQL Server所有用户使用
- 建议将TempDb存放在独立的驱动器上,减少分配使用。
- 用户数据库和日志文件隔离存放
- TempDb部署
- 执行计划分析
- SQL语句——>语法分析——>绑定——>优化——>执行——>返回结果
- 数据库能理解的语言:
- 逻辑查询树的节点 与 数据库实际对象绑定,然后将逻辑查询树转换成绑定数,然后加载源数据(字段属性、约束信息、关联等),然后在优化阶段,只是尽可能寻找优化方案,为什么呢?
- 可选方案太多了
- 2表关联=1种方案
- 3表关联=6种方法
- 1000表关联==xxxx…
- 优化器:有限的时间内、有限的资源、有限的优化
- 可选方案太多了
- 逻辑查询树的节点 与 数据库实际对象绑定,然后将逻辑查询树转换成绑定数,然后加载源数据(字段属性、约束信息、关联等),然后在优化阶段,只是尽可能寻找优化方案,为什么呢?
- 数据库能理解的语言:
- SQL语句——>语法分析——>绑定——>优化——>执行——>返回结果
//查询优化的流程:
- 简化:检查当前SQL语句是否缓存了,如果没有执行缓存,才进行之后的操作,进行简化。例子:where 1=1 and xxx条件。
- 当一眼看不出,有很多优化时,才真正开始的优化,基于开销的优化(CBO阶段):
- 阶段0:分析一系列的执行计划【3张表关联以上才会进行阶段0,因为只有一种方案】
- 阶段1:快速计划,会使用SQL Server所以一系列规则,然后生成可执行的计划,然后比较成本,找到最低的成本。如果还没用找到,就判断是否可以使用并行执行计划。当并行小于串行计划,才使用下一步优化。如果还没用找到,就执行阶段2。
- 阶段2:完全优化,不比阈值了;找到一个最低的,退出优化。
二、SQL Server性能优化
2.1-常见的运算符
- 逻辑运算符
- 物理运算符
- 数据访问运算符:访问表,根据表的类型不同。
- 根据表的所有不同:堆表、聚集索引表
- 扫描运算符:表扫描(堆表==全表查询)、聚集索引扫描、非聚集索引扫描
- 查找运算符:发生在索引上的
- 聚集索引查找
- 非聚集索引查找
//标签查找(键查找、RID查找):使用了非聚集索引的语句中。
2.1-编写健壮的SQL语句
- select:来自什么表?哪些字段?哪些特定条件的数据?排序、汇总等等。
- 不要使用”*”号,要显示什么数据,就显示对应的字段
- 使用like比使用Left函数性能要高一些,前提该字段使用了索引,并且使用了索引的字段上不好使用进行计算。
- 排序(Order by)性能:性能取决于参数排序的数量的大小,排序操作是对筛选出来的结果集进行排序。
- 创建索引(聚集索引),对排序的操作有一定的好处;
- 排序对Tempdb有影响:
- Tempdb是公共系统数据库;他用于查询过程中存储的中间数据;如果查询工作区内存不足,他就会用户Tempdb数据库完成查询排序的操作;Tempdb在磁盘上,会有IO开销;
- 看SQL语句执行频率、数据量的大小
- 分组(Group by)性能:一般伴随排序和聚合的操作
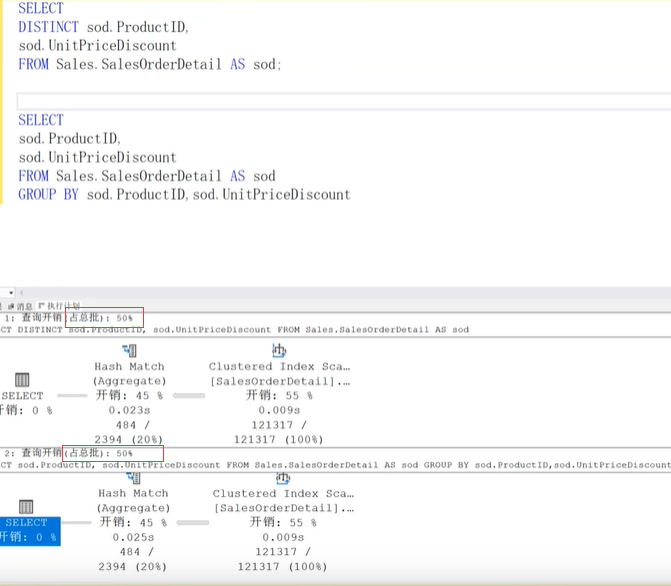
- distict和group by是一样的;
- 添加/删除聚集索引:
----添加聚集索引USE [FLHall]GOCREATE NONCLUSTERED INDEX IX_SPOON [dbo].[T_EPG] ([EPGGroupID])GO----删除聚集索引drop index IX_SPO on [dbo].[T_EPG]
三、SQL Server索引优化
3.1-update
- 流程:
- 将符合的条件查询出来——>锁(对更新的数据添加更新锁)——>然后转换为:排他锁——>更新数据
- 查询语句是:共享锁
- 保证更新语句的效率
- 数据量较大,有索引
- 小数据先使用唯一键、主键进行刷选
3.2-delete
- 流程:
- 将符合的条件查询出来——>锁——>转换为:排他锁——>删除数据
- Delete布局使用排他锁,他还会影响表中索引
- 为了保证事务的完整性(ACID),会将删除的数据记录在日志中,确保能回滚操作;也就是删除大批量的数据,会记录大批量的数据到日志中。
- Truncate table:这个删除表数据,但不会生成删除日志的;删除大表数据,建议使用这个。
3.3-where子句
- 评估语句是否合理?因素有哪些?
- 使用这个子句,有没有合适的索引(合理索引的选择、对索引的高效应用),能否为我所用?
- 字段上是否有函数进行计算?
- 返回的结果集是不是很大?
- 只查询需要的字段
3.3-编写SQL语句的流程
需要做什么?怎么做?是否正确/符合需求?
3.4-子查询
使用简单SQL语句、尽量集中在Where子句中,子查询数据最高不超过3个,这个查询语句涉及的表不超过5个。
建议使用确定型的运算符:”= / in”,避免使用”any / some / all”
//注意:数据库表结果的设计,是占第一位的!
- 如果既是执行的热点语句 ,同时也造成了性能问题:
- 修改表结构
- 小修:增加冗余字段
- 大修:重新设计数据库
- 在应用层做
- 修改表结构
//查询关键字(性能都差不多):
- in:
- exists
- left join
3.5-索引
- 两种功能:
- 提高查询性能
- 维护数据一致性
- 按照预期的顺序排列和组织数据
- 理想的索引:
- 突出”少”字,充分利用索引来实现需求,提高性能。
- 索引的碎片增长也会比较慢
- SARG:高效利用索引的查询语句
- 非SARG:
- Where条件符号左边出现标量函数:where Upper(列名)=’A’ —改为-> where(列名=’A’ or xx)
- Where 列-1=X —改为-> Where 列=X+1
- Left(列,3)=’ABC’ —改为-> 模糊查询
- 扩展思维:在应用层解决
- 如何分析索引的问题?
- 索引过多:扰乱查询优化器分析(分析时间、次数边长变多)、存储空间增大、维护开销增大(重建、重组、调整索引的开销);
- 解决:在分析现有索引的基础上,去除多余的索引。
- 单例索引:select Name,Phone from where Name=’admin’
- 首列相同的索引:可以通过合并索引来减少数量;
- 首列数据不合理的索引:
- 解决:在分析现有索引的基础上,去除多余的索引。
- 索引不足
- 解决:在分析现有索引的基础上,进行修改、整合;
- 索引不正确索引的第一列是最重要的;选择度很低的索引;
- 列选择不合理
- 没有重复使用包含索引
- 索引过多:扰乱查询优化器分析(分析时间、次数边长变多)、存储空间增大、维护开销增大(重建、重组、调整索引的开销);
//【单列索引】和【复合索引】对比;复合索引性更高;
- 复合索引的首列也是有讲究的:
- 首列的数据类型尽可能的小;避免是字符串类型
- 首列的选择度尽可能的高,也就是说首列的胃唯一值尽可能的少;
- 存在大量null的类不适合做索引列;

若有收获,就点个赞吧
0 人点赞
