索引简介
定义
MySQL官方对索引的定义为:索引是帮助MySQL高效获取数据的数据结构。
可以得到索引的本质:索引是数据结构。
简单理解:排好序的快速查找数据结构。
一般来说索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。
我们平常所说的索引,如果没有特别指明,都是指B树(多路搜索树,不一定是二叉树)结构的索引。
其中聚集索引,次要索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引。除了B+树这种类型的索引之外,还有哈希索引等。
优势
类似于大学图书馆建数目索引,提高数据检索的效率,降低数据库的IO成本。
通过索引列队数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势
虽然索引大大提高了查询速度,同时会降低表的更新速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
索引只是提高效率的一个因素,如果你的MySQL有大数据量的表,就需要花时间研究建立最优秀的索引,或优化查询。
索引分类
单值索引
一个索引列只包含单个列,一个表可以有多个索引。
唯一索引
索引列的值必须唯一,但允许有空值。
复合索引
一个索引包含多个列。
覆盖索引
SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据,即查询字段为索引字段。
基本语法
- 创建
CREATE [UNIQUE] INDEX <index_name> ON <table_name>(<column_name>(length));ALTER TABLE <table_name> ADD [UNIQUE] INDEX <index_name> ON (<column_name>(length));
- 删除
DROP INDEX <index_name> ON <table_name>;
- 查看
SHOW INDEX FROM <table_name>;
- ALTER
-- 添加主键,即唯一索引ALTER TABLE <table_name> PRIMARY KEY (column_list);-- 创建唯一索引ALTER TABLE <table_name> UNIQUE <index_name>(column_list);-- 添加普通索引ALTER TABLE <table_name> INDEX <index_name>(column_list);-- 指定全文索引ALTER TABLE <table_name> FULLTEXT index_name>(column_list);
索引结构
索引
- BTREE
- HASH
- FULL-TEXT
- R-TREE
需要建立索引的情况
- 主键自动建立唯一索引
- 频繁作为查询条件的字段应该创建索引
- 查询中与其它表关联的字段,外键关系建立索引
- 频繁更新的字段不适合创建索引
- Where条件里用不到的字段不创建索引
- 单值/组合索引的选择,在高并发下倾向创建组合索引
- 查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
- 查询中统计或者分组字段
不需要建立索引的情况
- 表记录太少 [原因:低于百万数的表MySQL还是扛得住的。]
- 经常增删改的表 [原因:提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件。]
- 数据重复且分布均匀的表字段,因此应该只为最经常查询和最经常排序的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果 [例如:性别等字段。]
Join查询
join说明
- LEFT JOIN:返回左表中的所有记录和右表中联结字段相等的记录。
- 格式:
SELECT ... table1 LEFT JOIN table2 ON ... - 说明:会取得table1全部记录,即使table2没有匹配记录
- 格式:
- RIGHT JOIN:返回右表中的所有记录和左表中联结字段相等的记录。
- 格式:
SELECT ... table1 RIGHT JOIN table2 ON ... - 说明:会取得table2全部记录,即使table1没有匹配记录
- 格式:
- INNER JOIN:只返回两个表中联结字段相等的记录。
- 格式:
SELECT ... table1 INNER JOIN table2 ON ... - 说明:会取得table1table2联结字段相等的记录
- 格式:
join图示
SELECT <select_list> from table_a a LEFT JOIN table_b b ON a.key = b.key
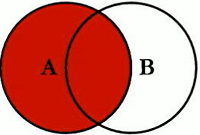
SELECT <select_list> from table_a a LEFT JOIN table_b ON a.key == b.key WHERE b.key is NULL
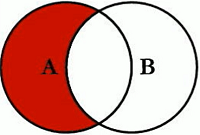
SELECT <select_list> from table_a a INNER JOIN table_b b ON a.key = b.key
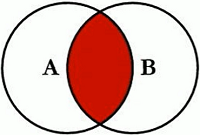
SELECT <select_list> from table_a a RIGHT JOIN table_b b ON a.key = b.key
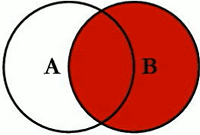
SELECT <select_list> from table_a a RIGHT JOIN table_b ON a.key = b.key WHERE a.key is NULL
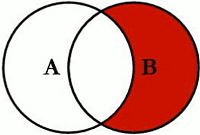
-- Oracle支持 FULL OUTER JOIN,但是MySQL不支持-- OracleSELECT <select_list> FROM table_a a FULL OUTER JOIN table_b b ON a.key = b.key-- MySQLSELECT <select_list> from table_a a LEFT JOIN table_b b ON a.key = b.keyunionSELECT <select_list> from table_a a RIGHT JOIN table_b b ON a.key = b.key

# OracleSELECT <select_list> FROM table_a a FULL OUTER JOIN table_b b ON a.key = b.key WHERE a.key is NULL or b.key is NULL# MySQLSELECT <select_list> from table_a a LEFT JOIN table_b b ON a.key = b.key where b.id is nullunionSELECT <select_list> from table_a a RIGHT JOIN table_b b ON a.key = b.key where a.id is null
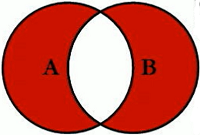
SQL执行顺序
- 手写
SELECT DISTINCT<select_list>FROM<left_table> <join_table>JOIN <right_table> ON <join_condetion>WHERE<where_condition>GROUP BY<group_by_list>HAVING<having_condition>ORDER BY<order_by_condition>LIMIT <limit_number>
- 机读

性能分析
MySQL Query Optimizer
MySQL中有专门负责优化SELECT语句的优化器模块,主要功能:通过计算分析系统中收集到的统计信息,为客户端请求的Query提供他认为最优的执行计划(它认为最优的数据检索方式,但不见得是DBA认为是最优的,这部分最耗费时间)
当客户端向MySQL请求一条Query,命令解析器模块完成请求分类,区别出是SELECT并转发给MySQL Query Optimizer时,MySQL Query Optimizer 首先会对整条Query进行优化,处理掉一些常量表达式的预算,直接换算成常量值。并对Query 中的查询条件进行简化和转换,如去掉一些无用或显而易见的条件、结构调整等。然后分析Query 中的Hint 信息(如果有),看显示Hint信息是否可以完全确定该Query的执行计划。如果没有Hint或Hint信息还不足以完全确定执行计划,则会读取所涉及对象的统计信息,根据Query进行写相应的计算分析,然后再得出最后的执行计划。
MySQL性能瓶颈
CPU: CPU在饱和的时候一般发生在数据装入内存或从磁盘上读取数据的时候
IO: 磁盘I/O瓶颈发生在装入数据远大于内存容量的时候
服务器硬件的性能瓶颈:top、free、iostat、vmstat来查看系统的性能状态
Explain
官网介绍:https://dev.mysql.com/doc/refman/8.0/en/explain-output.html
使用目的:
- 表的读取顺序
- 数据读取操作的操作类型
- 可以使用的索引
- 实际使用的索引
- 表之间的引用
- 每张表被优化器查询的行数
使用方法:explain + sql语句
字段解释
| 字段 | 描述 |
|---|---|
| id | 查询序列号 |
| select_type | 查询的类型 |
| partitions | 匹配的分区 |
| type | 表的连接类型 |
| possible_keys | 可能使用的索引 |
| key | 实际使用的索引 |
| key_len | 索引字段的长度 |
| ref | 列与索引的比较 |
| rows | 预估读取的行数 |
| filtered | 按表条件过滤的行百分比 |
| Extra | 执行情况的描述和说明 |
(1)id
解释:
select查询的序列号,包含一组数字,表示查询中执行的select子句或操作表的顺序。
说明:
- id相同,执行顺序由上至下;
- id不同,如果是子查询,id递增,id值越大优先级越高,越先被执行;
- id相同不同,同时存在,id如果相同,可以认为是一组,从上往下顺序执行,在所有组中,id值越大,优先级越高。
(2)select_type
解释:
查询的类型:SIMPLE、PRIMARY、SUBQUERY、DERIVED、UNION、UNION RESULT。查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
说明:
- SIMPLE:简单的select查询,查询中不包含子查询或者UNION;
- PRIMARY:查询中若包含任何复杂的子部分,最外层查询责则被标记为PRIMARY;
- SUBQUERY:在SELECT或WHERE列表中包含了子查询;
- DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生),MySQL会递归执行这些子查询,把结果放在临时表里;
- UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被被标记为:DERIVED;
- UNION RESULT:从UNION表获取结果的SELECT。
(3)table
解释:输出结果集的表。
(4)type
解释:表的访问类型。
说明:
从最好到最差依次是:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL。
常见的是:system > const > eq_ref > ref > range > index > ALL。
一般来说,得保证查询至少达到range级别,最好能到ref。
- system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,这个也可以忽略不计。
- const:表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。
- eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。
- ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
- range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where语句中出现了between、<、>、in等的查询这种范围扫描索引会比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
- index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然ALL和index都是全表,但index是从索引出发的,而ALL是从硬盘读取的。)
- ALL:Full Table Scan,将扫描全表以找到匹配的行。
(5)possible_keys
解释:
显示可能应用在这张表中的索引,一个或多个。
查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。
(6)key
解释:MySQL实际使用的索引。如果为NULL,则没有使用索引。查询中若使用了覆盖索引,则该索引仅出现在key列表中。
(7)key_len
解释:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精确性的情况下,长度越短越好。key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len时根据表定义计算而得,不是通过表内检索出的。
计算:
- 字符串
- char(n):n字节长度
- varchar(n):2字节存储字符串长度,如果是utf-8,则长度 3n + 2
- 数值类型
- tinyint:1字节
- smallint:2字节
- int:4字节
- bigint:8字节
- 时间类型
- date:3字节
- timestamp:4字节
- datetime:8字节
- 如果字段允许为 NULL,需要1字节记录是否为 NULL
索引最大长度是768字节,当字符串过长时,mysql会做一个类似左前缀索引的处理,将前半部分的字符提取出来做索引。
(8)ref
解释:
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
(9)rows
解释:
mysql预估要读取并检测的行数,注意这个不是结果集里的行数。
(10)Extra
解释:
包含不适合在其他列中显示但十分重要的额外信息。
说明:
using index:这发生在对表的请求列都是同一索引的部分的时候,返回的列数据只使用了索引中的信息,而没有再去访问表中的行记录,是性能高的表现。如果同时出现using where,表明索引被用来执行索引键值的查找;如果没有同时出现using where,表明索引用来读取数据而非执行查找动作。using filesort:MySQL会对结果使用一个外部索引排序,而不是按索引次序从表里读取行。此时MySQL会根据联接类型浏览所有符合条件的记录,并保存排序关键字和行指针,然后排序关键字并按顺序检索行信息。这种情况一般是很危险的,九死一生。using temporary:MySQL需要创建一张临时表来处理查询,对于查询结果排序时使用临时表,常见于排序order by和分组查询group by。常见于这种情况就更加危险了,十死无生。using where:使用where过滤。using join buffer:使用连接缓存。impossible where:where子句总是false,不能用来获取任何元组。select tables optimized away:在没有GROUP BY子句的情况下,基于索引优化MIN/MAX或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化。distinct:一旦MySQL找到了与行相联合匹配的行,就停止搜索。
SQL优化
案例1
建表:
CREATE TABLE `tb2_article` (`id` int NOT NULL AUTO_INCREMENT,`author_id` int NOT NULL,`category_id` int NOT NULL,`views` int NOT NULL,`comments` int NOT NULL,`title` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,`content` text NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO `tb2_article` VALUES (1, 1, 1, 1, 1, '1', '1');INSERT INTO `tb2_article` VALUES (2, 2, 2, 2, 2, '2', '2');INSERT INTO `tb2_article` VALUES (3, 3, 3, 3, 3, '3', '3');
第一次explain:
EXPLAIN SELECT id, author_id FROM tb2_article WHERE category_id = 1 AND comments > 1 order by views desc limit 1;
结果:
+----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+| 1 | SIMPLE | tb2_article | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 50.00 | Using where; Using filesort |+----+-------------+-------------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
建立索引:
CREATE INDEX idx_article_ccv on tb2_article(category_id,comments, views);
第二次explain:
EXPLAIN SELECT id, author_id FROM tb2_article WHERE category_id = 1 AND comments > 1 order by views desc limit 1;
结果:
+----+-------------+-------------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+| 1 | SIMPLE | tb2_article | NULL | range | idx_article_ccv | idx_article_ccv | 8 | NULL | 1 | 100.00 | Using index condition; Using filesort |+----+-------------+-------------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
发现key中已经显示了刚刚建立的索引,但是依然使用了文件排序。
第三次explain:
EXPLAIN SELECT id, author_id FROM tb2_article WHERE category_id = 1 AND comments = 1 order by views desc limit 1;
结果:
+----+-------------+-------------+------------+------+-----------------+-----------------+---------+-------------+------+----------+---------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------------+------------+------+-----------------+-----------------+---------+-------------+------+----------+---------------------+| 1 | SIMPLE | tb2_article | NULL | ref | idx_article_ccv | idx_article_ccv | 8 | const,const | 1 | 100.00 | Backward index scan |+----+-------------+-------------+------------+------+-----------------+-----------------+---------+-------------+------+----------+---------------------+
当把查询条件修改为等于时,发现ref中出现两个常量,即两个查询常量,并且没有使用文件排序。说明当查询条件为大于号时,索引失效。
浅析第二次加了索引之后explain依然使用filesort:
按照BTree的工作原理,先排序category_id,如果遇到相同的category_id则再排序comments,如果遇到相同的commnents则再排序views。当comments字段在联合索引里处于中间位置时,因comments > 1条件是一个范围值(range),MySQL无法利用索引再对后面的views部分进行检索,即range类型查询字段后面的索引无效。
删除索引:
DROP INDEX idx_article_ccv ON tb2_article;
新建索引:
CREATE INDEX idx_article_cv ON tb2_article(category_id, views);
再次explain:
EXPLAIN SELECT id, author_id FROM tb2_article WHERE category_id = 1 AND comments > 1 order by views desc limit 1;
结果:
+----+-------------+-------------+------------+------+----------------+----------------+---------+-------+------+----------+----------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-------------+------------+------+----------------+----------------+---------+-------+------+----------+----------------------------------+| 1 | SIMPLE | tb2_article | NULL | ref | idx_article_cv | idx_article_cv | 4 | const | 1 | 50.00 | Using where; Backward index scan |+----+-------------+-------------+------------+------+----------------+----------------+---------+-------+------+----------+----------------------------------+
可以看到type变成了ref,Extra中的using filesort也消失了,结果非常理想。
结论:建立复合索引的时候最好不要带上含有范围查询的字段。
案例2
继续建表:
CREATE TABLE `tb2_class` (`id` int NOT NULL AUTO_INCREMENT,`card` int NOT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE TABLE `tb2_book` (`bookid` int NOT NULL AUTO_INCREMENT,`card` int NOT NULL,PRIMARY KEY (`bookid`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO tb2_class(card) VALUES(FLOOR(1 + RAND() * 20));INSERT INTO tb2_book(card) VALUES(FLOOR(1 + RAND() * 20));
第一次explain:
EXPLAIN SELECT * FROM tb2_class LEFT JOIN tb2_book on tb2_class.card = tb2_book.card;
结果:
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+| 1 | SIMPLE | tb2_class | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | NULL || 1 | SIMPLE | tb2_book | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using join buffer (hash join) |+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
可以看到type都为ALL。
建立右表tb2_book索引:
ALTER TABLE tb2_book ADD INDEX(card);
第二次explain:
EXPLAIN SELECT * FROM tb2_class LEFT JOIN tb2_book on tb2_class.card = tb2_book.card;
结果:
+----+-------------+-----------+------------+------+---------------+------+---------+----------------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------+------------+------+---------------+------+---------+----------------------------+------+----------+-------------+| 1 | SIMPLE | tb2_class | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | NULL || 1 | SIMPLE | tb2_book | NULL | ref | card | card | 4 | mysql_learn.tb2_class.card | 1 | 100.00 | Using index |+----+-------------+-----------+------------+------+---------------+------+---------+----------------------------+------+----------+-------------+
可以看到tb2_class的type依然是ALL,tb2_book的type优化为ref。
删除tb2_book的索引:
DROP INDEX card ON tb2_book;
建立左表tb2_class索引:
ALTER TABLE tb2_class ADD INDEX(card);
第三次explain:
EXPLAIN SELECT * FROM tb2_class LEFT JOIN tb2_book on tb2_class.card = tb2_book.card;
结果:
+----+-------------+-----------+------------+-------+---------------+------+---------+------+------+----------+--------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------+------------+-------+---------------+------+---------+------+------+----------+--------------------------------------------+| 1 | SIMPLE | tb2_class | NULL | index | NULL | card | 4 | NULL | 9 | 100.00 | Using index || 1 | SIMPLE | tb2_book | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using join buffer (hash join) |+----+-------------+-----------+------------+-------+---------------+------+---------+------+------+----------+--------------------------------------------+
可以看到tb2_class的type为index,tb2_book的type下降为ALL。
最后再次建立tb2_book的索引:
ALTER TABLE tb2_book ADD INDEX(card);
第四次explain:
EXPLAIN SELECT * FROM tb2_class LEFT JOIN tb2_book on tb2_class.card = tb2_book.card;
结果:
+----+-------------+-----------+------------+-------+---------------+------+---------+----------------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------+------------+-------+---------------+------+---------+----------------------------+------+----------+-------------+| 1 | SIMPLE | tb2_class | NULL | index | NULL | card | 4 | NULL | 9 | 100.00 | Using index || 1 | SIMPLE | tb2_book | NULL | ref | card | card | 4 | mysql_learn.tb2_class.card | 1 | 100.00 | Using index |+----+-------------+-----------+------------+-------+---------------+------+---------+----------------------------+------+----------+-------------+
发现type都提升了,index和ref,结果很理想。
结论:对于JOIN连接查询的两张表最好都在联结字段建立单值索引。
案例3
继续建表:
CREATE TABLE `tb2_phone` (`phoneid` int NOT NULL AUTO_INCREMENT,`card` int DEFAULT NULL,PRIMARY KEY (`phoneid`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO tb2_phone(card) VALUES(FLOOR(1 + (RAND()*20)));
第一次explain:
EXPLAIN SELECT * FROM tb2_class LEFT JOIN tb2_book ON tb2_class.card = tb2_book.card LEFT JOIN tb2_phone ON tb2_book.card = tb2_phone.card ;
结果:
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+| 1 | SIMPLE | tb2_class | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | NULL || 1 | SIMPLE | tb2_book | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using join buffer (hash join) || 1 | SIMPLE | tb2_phone | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | Using where; Using join buffer (hash join) |+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+--------------------------------------------+
发现三张表的type都是ALL。
建立tb2_phone和tb2_book的索引:
ALTER TABLE tb2_phone INDEX(card);ALTER TABLE tb2_book ADD INDEX(card);
第二次explain:
EXPLAIN SELECT * FROM tb2_class LEFT JOIN tb2_book ON tb2_class.card = tb2_book.card LEFT JOIN tb2_phone ON tb2_book.card = tb2_phone.card ;
结果:
+----+-------------+-----------+------------+------+---------------+------+---------+----------------------------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+-----------+------------+------+---------------+------+---------+----------------------------+------+----------+-------------+| 1 | SIMPLE | tb2_class | NULL | ALL | NULL | NULL | NULL | NULL | 9 | 100.00 | NULL || 1 | SIMPLE | tb2_book | NULL | ref | card | card | 4 | mysql_learn.tb2_class.card | 1 | 100.00 | Using index || 1 | SIMPLE | tb2_phone | NULL | ref | card | card | 5 | mysql_learn.tb2_book.card | 1 | 100.00 | Using index |+----+-------------+-----------+------------+------+---------------+------+---------+----------------------------+------+----------+-------------+
发现tb2_phone和tb2_book的type被优化为ref,并且rows也优化的很好。
结论:
- 永远用小结果集驱动大结果集
- 尽可能减少Join语句中的NestedLoop的循环总次数
- 优先优化NestedLoop的内存循环
- 保证Join语句中被驱动表上Join条件字段已经被索引
- 当无法保证被驱动表的Join条件字段被索引且内存资源充足的前提下,不要太吝啬JoinBuffer的设置
索引失效
SQL脚本
CREATE TABLE `tb3_staff` (`id` int NOT NULL AUTO_INCREMENT,`name` varchar(20) DEFAULT NULL,`age` int DEFAULT NULL,`pos` varchar(20) DEFAULT NULL,`add_time` timestamp NULL DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP,PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;INSERT INTO tb3_staff(name, age, pos, add_time) VALUES ( 'KHighness', 19, 'manager', NOW());INSERT INTO tb3_staff(name, age, pos, add_time) VALUES ( 'FlowerK', 18, 'dev', NOW());INSERT INTO tb3_staff(name, age, pos, add_time) VALUES ( 'UnknownK', 17, 'dev', NOW());ALTER TABLE tb3_staff ADD INDEX id_staff_nameagepos(name, age, pos);
生效场景
EXPLAIN SELECT * FROM tb3_staff WHERE name = 'KHighness';EXPLAIN SELECT * FROM tb3_staff WHERE name = 'KHighness' and age = 19;EXPLAIN SELECT * FROM tb3_staff WHERE name = 'KHighness' and age = 19 and pos = "dev";
失效场景
EXPLAIN SELECT * FROM tb3_staff WHERE age = 19 and pos = "dev";EXPLAIN SELECT * FROM tb3_staff WHERE pos = "dev";
部分失效
EXPLAIN SELECT * FROM tb3_staff WHERE name = 'KHighness' and pos = "dev";
总结
1、最理想的情况就是查询字段与索引字段相同
2、最佳左前缀法则
3、不在索引列上做任何操作(计算、函数、(自动or手动)类型转换),会导致索引失效而转向全表扫描
4、存储引擎不能使用索引中范围条件右边的列
5、尽量使用覆盖索引(只访问索引的查询(索引列和查询列一致)),减少select *
6、使用不等于(!= 或者 <>)的时候索引失效会导致range(MySQL5中是ALL)
7、使用is null或者is not null的时候索引失效会导致range(MySQL5中是ALL)
8、like以通配符开头索引失效会导致ALL,建立覆盖索引可以防止
9、MySQL5中字符串不加单引号索引失效会导致ALL,MySQL8中直接报错
10、使用or连接索引失效会导致ALL
索引面试
SQL语句
CREATE TABLE `tb4_test` (`id` int NOT NULL AUTO_INCREMENT,`c1` char(10) DEFAULT NULL,`c2` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`c3` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`c4` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,`c5` char(10) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE INDEX idx_tb4_test_c1234 ON tb4_test(c1, c2, c3, c4);INSERT INTO `mysql_learn`.`tb4_test`(`id`, `c1`, `c2`, `c3`, `c4`, `c5`) VALUES (1, 'a1', 'a2', 'a3', 'a4', 'a5');INSERT INTO `mysql_learn`.`tb4_test`(`id`, `c1`, `c2`, `c3`, `c4`, `c5`) VALUES (2, 'b1', 'b2', 'b3', 'b4', 'b5');INSERT INTO `mysql_learn`.`tb4_test`(`id`, `c1`, `c2`, `c3`, `c4`, `c5`) VALUES (3, 'c1', 'c2', 'c3', 'c4', 'c5');INSERT INTO `mysql_learn`.`tb4_test`(`id`, `c1`, `c2`, `c3`, `c4`, `c5`) VALUES (4, 'd1', 'd2', 'd3', 'd4', 'd5');INSERT INTO `mysql_learn`.`tb4_test`(`id`, `c1`, `c2`, `c3`, `c4`, `c5`) VALUES (5, 'e1', 'e2', 'e3', 'e4', 'e5');
EXPLAIN测试
-- 最好索引如何创建就如何使用,避免让MySQL自己再翻译优化 ---- 1. 用到索引c1 c2 c3 c4全字段,全值匹配EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' AND c3 = 'a3' AND c4 = 'a4';-- 2. 用到索引c1 c2 c3 c4全字段,查询优化器会优化SQL语句的执行顺序EXPLAIN SELECT * FROM tb4_test WHERE c4 = 'a4' AND c3 = 'a3' AND c2 = 'a2' AND c1 = 'a1';-- 3. 用到索引c1 c2 c3字段,c4字段失效,范围之后全失效EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' AND c3 > 'a3' AND c4 = 'a4';-- 4. 用到索引c1 c2 c3 c4全字段,查询优化器会优化SQL语句的执行顺序EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' AND c4 > 'a4' AND c3 = 'a3';-- order by排序一定要注意顺序,这个顺序MySQL不会自动优化 ---- 5. 用到索引c1 c2 c3字段,c1 c2用于查找,c3用于排序,但是没有统计到key_len中,c4字段失效EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' AND c4 > 'a4' ORDER BY c3;-- 6. 用到索引c1 c2字段,c1 c2用于查找,c4排序产生了Using filesort说明c4失效EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' ORDER BY c4;-- 7. 用到索引c1 c2 c3字段,c1用于查找,c2 c3用于排序EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c5 = 'a5' ORDER BY c2, c3;-- 8. 用到索引c1字段,c1用于查找,c3 c2失效,产生了Using filesortEXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c5 = 'a5' ORDER BY c3, c2;-- 9. 用到索引c1 c2 c3字段,c1 c2用于查找,c2 c3用于排序EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' AND c5 = 'a5' ORDER BY c2, c3;-- 10. 用到索引c1 c2 c3字段,c1 c2用于查找,c3才用于排序-- 没有产生Using filesort,因为c2查找时已经确定了,排序时c2已经不用排序了EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c2 = 'a2' AND c5 = 'a5' ORDER BY c3, c2;-- group by虽然是分组,但是分组之前必然排序 ---- 11. 用到索引c1 c2 c3字段,c1用于查找,c2 c3用于排序,c4失效EXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c4 = 'a4' GROUP BY c2, c3;-- 12. 用到索引c1字段,c1用于查找,c2 c3失效,产生了Using temporaryEXPLAIN SELECT * FROM tb4_test WHERE c1 = 'a1' AND c4 = 'a4' GROUP BY c3, c2;
总结
- 定值、范围还是排序,一般order by是给个范围。
- group by基本上都需要进行排序,会有临时表产生。
- like匹配%在字符串最右边会使用使用,%在字符串最左边不会使用。
一般性建议
- 对于单键索引,尽量选择针对当前query过滤性更好的索引。
- 在选择组合索引的时候,当前query中过滤性最好的字段在索引字段顺序中,位置越靠前越好。
- 在选择组合索引的时候,尽量选择可以能够包含当前query中的where子句中更多字段的索引。
- 尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的。
优化口诀
带头大哥不能死,中间兄弟不能断;
覆盖索引不写星,索引列上少计算;
不等有时会失效,范围之后全失效;
LIKE百分写最右,一般SQL少用OR。

若有收获,就点个赞吧
0 人点赞
