URL解析
1、地址解析
浏览器会根据你的输入来判断该输入是一条合法的URL,还是需要被搜索的关键词。并且根据你输入的内容进行自动完成、字符编码等操作。
2、其他操作
目前大部分浏览器都会强制客户端使用HTTPS协议以保证信息传输的安全性。同时还会进行一些额外的操作,比如安全检查、访问限制等。
3、缓存检查
有时候博客在gitee上进行了更新,但是通过谷歌浏览器查看博客时,仍是更新前的博客,这是因为浏览器中缓存了之前的博客界面。
浏览器会先检测是否缓存了目标URL的页面,如果有且缓存未过期,则直接展示缓存页面,无需再向服务器进行请求
DNS解析
DNS解析是寻找所需要的资源的IP地址的过程。因为互联网中每一台连网的机器都有唯一IP作为标识,但是它是一串数字,记忆太过困难。所以就需要将网址和IP地址进行转换,也就是DNS解析。其具体步骤如下。
第一步:检查浏览器缓存中是否缓存过该域名对应的IP地址
用户通过浏览器浏览过某网站之后,浏览器就会自动缓存该网站域名对应的地址,当用户再次访问的时候,浏览器就会从缓存中查找该域名对应的IP地址,因为缓存不仅是有大小限制,而且还有时间限制(域名被缓存的时间通过属性来设置),所以存在域名对应的找不到的情况。当浏览器从缓存中找到了该网站域名对应的地址,那么整个解析过程结束,如果没有找到,将进行下一步骤。对于的缓存时间问题,不宜设置太长的缓存时间,时间太长,如果域名对应的发生变化,那么用户将在一段时间内无法正常访问到网站,如果太短,那么又造成频繁解析域名。
第二步:如果在浏览器缓存中没有找到IP,那么将继续查找本机系统是否缓存过IP
如果第一个步骤没有完成对域名的解析过程,那么浏览器会去系统缓存中查找系统是否缓存过这个域名对应的地址,也可以理解为系统自己也具备域名解析的基本能力。在系统中,可以通过设置文件来将域名手动绑定到某上,文件位置在。对于普通用户,并不推荐自己手动绑定域名和,对于开发者来说,通过绑定域名和,可以轻松切换环境,可以从测试环境切换到开发环境,方便开发和测试。在系统中,黑客常常修改他的电脑的文件,将用户常常访问的域名绑定到他指定的上,从而实现了本地解析,导致这些域名被劫持。在或者系统中,文件在,修改该文件也可以实现同样的目的。
- 查找路由器缓存,通过路由器看看有没有DNS缓存
前两步都是在本机上完成的,所以没有在上面示例图上展示出来,从第三步开始,才正在地向远程DNS服务器发起解析域名的请求。
第三步:向本地域名解析服务系统发起域名解析的请求
如果在本机上无法完成域名的解析,那么系统只能请求本地域名解析服务系统进行解析,本地域名系统一般都是本地区的域名服务器,比如你连接的校园网,那么域名解析系统就在你的校园机房里,如果你连接的是电信、移动或者联通的网络,那么本地域名解析服务器就在本地区,由各自的运营商来提供服务。对于本地服务器地址,系统使用命令就可以查看,在和系统下,直接使用命令来查看服务地址。一般都缓存了大部分的域名解析的结果,当然缓存时间也受域名失效时间控制,大部分的解析工作到这里就差不多已经结束了,负责了大部分的解析工作。
第四步:向根域名解析服务器发起域名解析请求
本地域名解析器还没有完成解析的话,那么本地域名解析服务器将向根域名服务器发起解析请求。
第五步:根域名服务器返回gTLD(通用顶级域名)域名解析服务器地址
本地域名解析向根域名服务器发起解析请求,根域名服务器返回的是所查域的通用顶级域()地址,常见的通用顶级域有cn、com、edu等。
第六步:向gTLD服务器发起解析请求
本地域名解析服务器向gTLD服务器发起请求。
第七步:gTLD服务器接收请求并返回Name Server服务器
服务器接收本地域名服务器发起的请求,并根据需要解析的域名,找到该域名对应的域名服务器,通常情况下,这个服务器就是你注册的域名服务器,那么你注册的域名的服务商的服务器将承担起域名解析的任务。
第八步:Name Server服务器返回IP地址给本地服务器
服务器查找域名对应的地址,将地址连同值返回给本地域名服务器。
第九步:本地域名服务器缓存解析结果
本地域名服务器缓存解析后的结果,缓存时间由时间来控制。
概述版
1)查询缓存
我们的浏览器、操作系统、路由器都会缓存一些URL对应的IP地址,统称为DNS高速缓存。这是为了加快DNS解析速度,使得不必每次都到根域名服务器中去查询。
2)递归解析
输入www.baidu.com网址后,首先在高速缓存中查找,没找到去根域名服务器查找,没有再去com顶级域名服务器查找,依次类推,直到找到IP地址,然后把它记录在本地告诉缓存中,供下次使用。
大致过程就是.-> .com ->baidu.com. -> www.baidu.com.
其中.代表根域名服务器。
3)DNS负载均衡
访问baidu.com的时候,每次响应的可能并非是同一个服务器(IP地址不同),一般大公司都有成百上千台服务器来支撑访问,DNS可以返回一个合适的机器的IP给用户,例如可以根据每台机器的负载量,该机器离用户地理位置的距离等等,这种过程就是DNS负载均衡。
建立TCP连接
TCP/IP 分为四层,在发送数据时,每层都要对数据进行封装
TCP协议
发送HTTPS请求
大致过程如下
查询MAC地址
这一步主要负责为打包好的数据+TCP首部+IP首部寻找传输路线,找到IP对应的物理机,这里会用到ARP协议。
ARP协议
ARP、RARP、RIP、OSPF
请求在Tomcat中的处理流程
Web 容器以进程的方式在计算机上运行,它主要负责接收请求,并将其投送至特定的应用,但Web容器并不属于计算机网络的组成部分。接下来将以Tomcat为例介绍Web容器的核心组件。
Tomcat的核心组件
Tomcat的核心组件主要有:Server、Service、Connector、Engine、Host和Context。
一个Server可以包含多个Service,一个Service可以包含多个Connector,但只能包含一个Engine,一个Engine可以包含多个Host,一个Host可以包含多个Context。
它们之间的关系如下图所示
配置文件的结构如下
<Server><Service><Engine><Host><Context /></Host><Host><Context /></Host></Engine><Connector /><Connector /></Service></Server>
Server
Server 是整个配置文件的唯一根元素,代表整个 Tomcat 容器。Server 内部可以包含多个 Service,其主要职责就是管理多个 Service,对外提供给客户端访问,同时维护所有 Service 的生命周期,包括初始化服务、结束服务、定位客户端要访问的 Service 等等。
Service
Service 的主要职责就是将 Engine 与 Connector 装配在一起对外提供服务。一个 Service 可以包含多个 Connector,但只能包含一个 Engine,其中 Connector 负责从客户端接收请求,Engine 负责处理 Connector 接收进来的请求。
Connector
Connector是主要负责接收请求的组件。
Tomcat有以下两种工作模式
- 作为Web服务器,直接接收客户端的请求
- 作为Java Web服务器,接收前置Web服务器的请求

每个 Service 可以有一个或多个 Connector,不同工作模式下,Tomcat 需要为各种类型的请求分别定义相应的 Connector,这样才能正确接收客户端对应协议的请求。定义 Connector 可以使用多种属性,某些属性只适用于某种特定的 Connector 类型。
一般说来,常见的 Connector 有 4 种类型
- HTTP
- HTTPS
- AJP
- Proxy

Connector作为通信接口,它为其所属特定的 Service 接收外部客户端请求,以及回送应答至外部客户端。具体职责包括创建 Request、Response 对象用于跟外部客户端交换数据,并将 Request 交给配套的 Engine 来处理。
Engine
Engine 是 Service 组件中负责请求处理的组件,其内部可以包含多个 Host。Engine 从一个或多个 Connector 中接收请求并处理,并将处理结果封装成应答交给 Connector,最终回传给外部客户端。
Host
Host 代表一个虚拟主机,它对应计算机网络上的一个实体。即某个在 DNS 服务器上注册过的域名或者 IP 地址,例如:www.baidu.com或 201.187.10.21。Host 内部可以包含多个 Context,每个 Context 表示一个 Web 应用。Host 负责安装、展开、启动和结束每个 Web 应用。
客户端在填写目标地址时会通过主机名来标识它希望访问的服务器,Tomcat 将从 HTTP 请求头的 Host 字段提取主机名,然后再匹配对应的虚拟主机。如果没有找到匹配的,HTTP 请求将被发送至默认主机 defaultHost。
Context
Context 代表在特定虚拟主机上运行的一个 Web 应用,负责处理某个特定 Web 应用的所有请求。
Tomcat处理HTTP请求
当以 HTTP 请求到达Tomcat服务器(Server)以后,Tomcat会进行以下几个步骤,将请求交给对应的Web应用进行处理
- 根据协议类型和端口号选定 Service 和 Engine
- Connector 主要负责接收请求。当 Connector 接收到特定协议和特定端口的请求后,其所属的 Service 和 Service 下的 Engine 也就确定了
- 根据域名或 IP 地址选定 Host
- Engine一旦确定了,就会根据 IP 来选择对应的虚拟主机Host来处理请求。如果匹配失败了,则会使用默认虚拟主机来处理请求
- 根据 URI 选定 Context
- URI 中的 context-path 指定了 HTTPS 请求将要访问的 Web 应用
- 当请求抵达时,Tomcat 将根据 Context 的属性 path 取值与 URI 中的 context-path 的匹配程度来选择 Web 应用处理相应请求
请求在Web应用中的处理流程
请求被 Web 容器中的 Connector 捕获,选取对应的 Server 中的 Engine ,Engine 再根据IP选择对应的虚拟主机,虚拟主机根据URI将请求交给对应的Web应用进行处理。接下来将介绍请求在Web请求中的处理过程。
介绍处理过程前,先对Web应用的基本组件进行简单介绍。
Web应用核心组件
Listener
监听器 Listener 主要用于监听 Application、Session、Request 等对象的变化,每当这些对象发生变化就会回调用对应的监听方法。
Filter
过滤器 Filter 负责对请求做预处理,接着将请求交给 Servlet 进行处理并生成响应,最后 Filter 再对响应进行后处理。
从请求的处理过程来看,Filter 主要参与以下几个环节
- 在 HttpServletRequest 到达 Servlet 之前,拦截客户的 HttpServletRequest
- 根据需要检查 HttpServletRequest,也可以修改 HttpServletRequest 报文头和数据
- 在 Servlet 生成的 HttpServletResponse 抵达客户端之前,拦截 HttpServletResponse
- 根据需要检查 HttpServletResponse,也可以修改 HttpServletResponse 报文头和数据
简单来说就是在真正处理请求以及返回响应之前,通过过滤器对内容再进行一些修改
Servlet
Servlet 负责处理客户端访问动态资源的 HTTP 请求,接口 javax.servlet.Servlet 定义了所有 Servlet 必须要实现的方法
public interface Servlet {// 由 Servlet 容器调用,完成 Servlet 初始化,启动对外服务void init(ServletConfig var1) throws ServletException;// 获取 Servlet 初始化和启动时参数的配置信息对象 ServletConfigServletConfig getServletConfig();// 由 Servlet 容器调用,让 Servlet 处理某个 HTTP 请求void service(ServletRequest var1, ServletResponse var2) throws ServletException, IOException;// 获取 Servlet 的说明信息,包括:作者、版本和版权等等String getServletInfo();// 由 Servlet 容器调用,用于关闭停止 Servlet 提供的服务void destroy();}
从 HTTP 请求的处理过程来看,Servlet 主要参与以下几个环节
- 接收请求
- 客户端请求会被封装成 HttpServletRequest 对象,包含报文头参数和报文体等信息
- 处理请求
- 通常调用 Servlet 的方法 service、doPost 或 doGet 等方法处理请求,并进一步调用业务层相应逻辑对其进行处理等
- 反回响应
- 处理完请求后,可以转发(forward)、重定向(redirect)到某个视图页面或者直接返回结果数据
Web应用处理HTTP请求流程
Web 应用处理 HTTP 请求的流程主要是穿越 Listener 和多个 Filters,最终抵达 Servlet 的过程,Servlet再进行下一步的处理。
具体流程如下图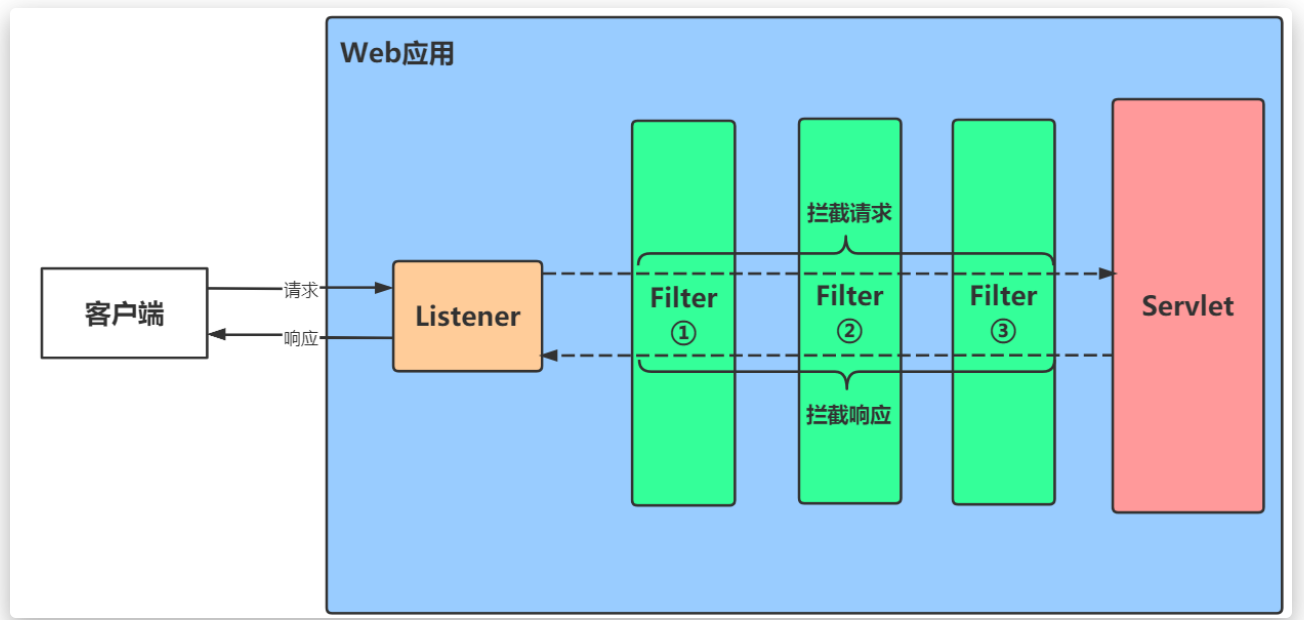
请求在Spring Web应用中的处理流程
因为使用 SSM 框架,所以 Spring MVC 中的 DispatcherServlet 充当了 Web 应用中的 Serlvet,负责将任务分配给对应的Controller,并将最终视图返回给 Web 容器。
Spring MVC的核心组件
DispatcherServlet
DispatcherServlet 是整个流程控制的中心,由它来接收请求并调用其它组件处理用户的请求,同时还负责响应结果。DispatcherServlet的存在降低了组件之间的耦合性。
HandlerMapping
HandlerMapping 负责根据用户请求映射获得对应的 Handler和 HandlerInterceptor。处理方法为从 URL 获得 URI,在通过 URI 从 HandlerMapping 中找到对应的 Handler 和 HandlerInterceptor,即处理器和拦截器。
HandlerAdapter
HandlerAdapter 负责按照特定规则去执行 Handler。
如果 Handler 有对应的 HandlerAdapater,HandlerAdapater 则会在调用 Handler 之前执行 HandlerInterceptor 的 preHandler() 方法对 Handler 进行拦截。
HandlerInterceptor
HandlerInterceptor 主要负责在执行 Handler 前对其进行拦截。HandlerInterceptor 中的 preHandler() 方法将会提取 HTTP 请求中的数据填充到处理器 Handler 的中。
Handler
Handler 即Controller ,是处理业务代码的核心器件。这部分由程序员自行编写,一般的SSM框架中,其下层还有Service和Dao。
Spring MVC处理请求流程
当 Web 容器中的 Host 会选择对应的 Web应用来处理请求,这里将请求交给了 Spring MVC 中的 DispatcherServlet 来进一步处理请求。
- DispatcherServlet 通过解析 HTTP 请求的 URL 获得 URI,再根据该 URI 从 HandlerMapping 当中获得该请求对应的 Handler 和 HandlerInterceptor
- DispatcherServlet 根据获得的 Handler 选择合适的 HandlerAdapter。如果成功获得 HandlerAdapter,HandlerAdapater 则会在调用 Handler 之前执行 HandlerInterceptor 的 preHandler() 方法对 Handler 进行拦截
- Handler 即 Controller 会进行请求的处理,并向下调用 Service 和 Dao 来处理请求
- Hander 处理完成请求后会返回模型数据,模型数据由 DispatcherServlet 封装后返回给Web 容器
处理的流程图如下
返回过程
Web 应用处理完请求并将结果返回给 Web 容器后,容器会将响应结果返回给客户端,这是上面流程的逆过程。浏览器收到响应结果后,会对结果进行解析和渲染。这样我们就能看到浏览器给我们显示的网页了。

若有收获,就点个赞吧
0 人点赞
