概要(ReadMe)
- 集群使用kubeadm搭建, k8s version: 1.9.4/kernel version: 3.10.0;
- 官方的部署文件会出现水土不服情况,建议在部署过程中关注Prometheus各组件的日志。本文着重讲解这部分;
- 如何接入钉钉告警;
- 业务服务如何接入监控体系;
- 本文默认你已了解Prometheus-operator各组件的作用;
部署打怪
kube-controller-manager/kube-scheduler的target为0/0
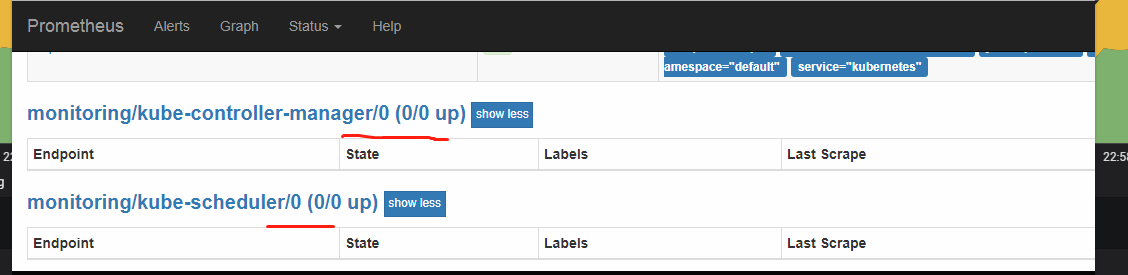
- 原因
serviceMonitor根据svc的label作为筛选条件。在kubeadm安装的集群中,没有创建kube-controller-manager/kube-scheduler的svc/endpoint - 修复
根据serviceMonitor文件中对svc label的要求,手工创建上述两者的svc,endpoint会自动出现。 ``` apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-controller-manager labels: k8s-app: kube-controller-manager spec: selector: component: kube-controller-manager type: ClusterIP clusterIP: None ports:- name: http-metrics port: 10252 targetPort: 10252 protocol: TCP
apiVersion: v1 kind: Service metadata: namespace: kube-system name: kube-scheduler labels: k8s-app: kube-scheduler spec: selector: component: kube-scheduler type: ClusterIP clusterIP: None ports:
- name: http-metrics port: 10251 targetPort: 10251 protocol: TCP ```
kube-controller-manager/kube-scheduler的target connection refused

- 修复
sudo sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-controller-manager.yamlsudo sed -e "s/- --address=127.0.0.1/- --address=0.0.0.0/" -i /etc/kubernetes/manifests/kube-scheduler.yaml
coredns的target为0/0
- 原因
官方prometheus-serviceMonitorCoreDNS.yaml中kube-dns的port_name为metrics,但kube-dns并未暴露此port;kube-dns暴露的port_name为dns(53端口),但此端口没有metrics信息. 修复
- 修改集群的kube-dns svc,使之暴露两个port:skydns/dnsmasq
apiVersion: v1kind: Servicemetadata:creationTimestamp: 2018-11-05T08:09:51Zlabels:k8s-app: kube-dnskubernetes.io/cluster-service: "true"kubernetes.io/name: KubeDNSname: kube-dnsnamespace: kube-systemresourceVersion: "30186373"selfLink: /api/v1/namespaces/kube-system/services/kube-dnsuid: 2b8fcef0-e0d2-11e8-8ed0-0cc47a4de248spec:clusterIP: 10.96.0.10ports:- name: dnsport: 53protocol: UDPtargetPort: 53- name: dns-tcpport: 53protocol: TCPtargetPort: 53- name: http-metrics-skydnsport: 10055protocol: TCPtargetPort: 10055- name: http-metrics-dnsmasqport: 10054protocol: TCPtargetPort: 10054selector:k8s-app: kube-dnssessionAffinity: Nonetype: ClusterIPstatus:loadBalancer: {}
- 修改集群的kube-dns svc,使之暴露两个port:skydns/dnsmasq
修改prometheus-serviceMonitorCoreDNS.yaml
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:k8s-app: corednsname: corednsnamespace: monitoringspec:endpoints:- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/tokeninterval: 15sport: http-metrics-skydns- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/tokeninterval: 15sport: http-metrics-dnsmasqjobLabel: k8s-appnamespaceSelector:matchNames:- kube-systemselector:matchLabels:k8s-app: kube-dns
宿主机的cpu数据无法被收集
现象
time=”2019-04-30T02:14:36Z” level=error msg=”ERROR: cpu collector failed after 0.002016s: open /host/sys/devices/system/cpu/cpu0/cpufreq/cpuinfo_cur_freq: permission denied” source=”collector.go:132”
原因
官方yaml文件中pod的运行权限较低- 修复
修改node-exporter-daemonset.yaml中pod.securityContext为runAsUser: 0
pod的数据无法被收集
现象
Apr 25 18:01:52 kubelet[92619]: W0425 18:01:52.860982 92619 container.go:507] Failed to update stats for container “%s”: %s/kubepods/burstable/pod0ef56d74-5bf6-11e9-ae19-0cc47a4e0d6e/2822489b4b17c2190cf7c9230b78eace7ef8059bee88c78f6163f0e1bad21ca7failure - /sys/fs/cgroup/cpuset,cpu,cpuacct/kubepods/burstable/pod0ef56d74-5bf6-11e9-ae19-0cc47a4e0d6e/2822489b4b17c2190cf7c9230b78eace7ef8059bee88c78f6163f0e1bad21ca7/cpuacct.stat is expected to have 4 fields, continuing to push stats
修复
问题源码
方法一: 修改源码,重新recompile kubelet -> restart kubelet;
方法二:update kernel,在4.9.93没有上述问题;
node-exporter导致宿主机的其他container无法被删除
现象
Apr 30 17:46:18 kubelet[74493]: E0430 17:46:18.096190 74493 kuberuntime_gc.go:126] Failed to remove container “201915893e178390c88968bd5ba3b62897ed4cf65ea2ff66c8c6a50360d024e9”: rpc error: code = Unknown desc = failed to remove container “201915893e178390c88968bd5ba3b62897ed4cf65ea2ff66c8c6a50360d024e9”: Error response from daemon: driver “overlay” failed to remove root filesystem for 201915893e178390c88968bd5ba3b62897ed4cf65ea2ff66c8c6a50360d024e9: remove /home/.docker/overlay/31a2c2864b399169317fe37ab337d71beeb15dab3d5f474878e40fb5dfeaba16/merged: device or resource busy
原因
node-exporter由于要统计宿主机的filesystem使用情况,故mount了宿主机的根目录- 修复
方法一: 升级内核至4.9.93,没有上述问题;
方法二: 修改docker的MountFlags为slave。但这样配置后,服务对挂载点的操作只在自己的Namespace内生效,不会反映到主机上。本集群使用fluentd作为日志收集器,其会在宿主机记录其偏移量。故方法二并不适合本集群;
如何接入钉钉告警
总体思路
alertmanager会使用secret保存告警规则。在告警规则中,使用自己编写的alert-center服务作为webhook_config
概览
check告警规则
kubectl -n monitoring get secret alertmanager-main -ojson | jq -r '.data["alertmanager.yaml"]' | base64 -d
update告警规则
kubectl -n monitoring create secret generic alertmanager-main --from-literal=alertmanager.yaml="$(< alertmanager.yaml)" --dry-run -oyaml | kubectl -n monitoring replace secret --filename=-
cat告警规则 ``` global: resolve_timeout: 5m route: group_interval: 5m group_by: [alertname, cluster, service] group_wait: 30s repeat_interval: 4h receiver: cluster-administers routes:
- match: alertname: Watchdog receiver: admin-on-duty repeat_interval: 24h
- match: alertname: CPUThrottlingHigh receiver: nonwhere inhibit_rules:
- source_match: severity: critical target_match: severity: warning equal: [alertname, cluster, service] receivers:
- name: cluster-administers
webhook_configs:
- url: {POST_URL}
- name: admin-on-duty
webhook_configs:
- url: {POST_URL}
name: nonwhere ```
钉钉机器人效果

业务服务如何接入监控体系
总体思路
prometheus-operator会监控serviceMonitor文件的变更,以此热更新需要监控的服务。也即,需要编写业务的serviceMonitor文件
概览
apiVersion: monitoring.coreos.com/v1kind: ServiceMonitormetadata:labels:{key}: {value}name: {name}namespace: monitoringspec:endpoints:- interval: 30sport: httppath: /actuator/prometheusnamespaceSelector:matchNames:- {namespace_name}selector:matchLabels:{svc_label_key}: {svc_label_value}
Reference

若有收获,就点个赞吧
0 人点赞
