
简介
LevelDB是google开发的,一个速度非常快的KeyValue持久化存储库,key和value可以是任意的byte数组,并且这种映射关系按key排序。
典型应用场景
计数器功能,更新非常频繁,且数据不可丢失
特性
- key和value可以是任意的byte数组
- 数据按照key排序
- 使用者可以自定义排序规则
- 基本操作方法为Put(key,value), Get(key), Delete(key).
- 多个更改可以作为一个原子操作
- 用户可以创建一个临时快照来获得一致的数据视图
- 数据支持向前和向后迭代.
- 数据自动使用 Snappy compression library压缩存储
- 外部活动(文件系统操作等)通过虚拟接口,以便用户可以自定义操作系统交互
限制
- LevelDB不是关系型数据库,不支持关联数据模型,SQL查询和索引
- 一次只能有一个单独的进程(可能是多线程)可以访问特定的数据库
- 该库不内置Client和Server功能,需要这些功能的应用程序自己进行封装
性能
测试库共100w行记录,每条记录16字节的key,100字节的value,压缩后的value大概50字节
写性能
- 顺序写:平均每次操作耗时1.765微秒,即支持每秒大概55w次顺序写操作
- 顺序写+每次都刷盘:平均每次操作耗时268.409微妙,即支持每秒大概3700次的刷盘写操作
- 随机写:平均每次操作耗时2.460微秒,即支持每秒大概40w次随机写操作
- 更新写:平均每次操作耗时2.380微秒,性能和随机写差不多
读性能
- 随机读:平均每次操作耗时16.677微秒,即支持每秒大概6w次随机读操作
- 顺序读:平均每次操作耗时0.476微秒,即支持每秒大概210w次顺序读操作
- 逆序读:平均每次操作耗时0.724微秒,即支持每秒大概130w次逆序读操作
上述性能都是在没有打开“压缩”功能下的结果,如果打开“压缩”选项,性能会有所提升,例如随机读性能会提升至11.602微秒,即8.5w次每秒
RocksDB

Google的leveldb是个很优秀的存储引擎,但还是有一些不尽人意的地方,比如leveldb不支持多线程合并,对key范围查找的支持还很简单,未做优化措施,等等。
而Facebook的RocksDB是个更彪悍的引擎,实际上是在LevelDB之上做的改进,在用法上与LevelDB非常的相似。
现代开源市场上有很多数据库都在使用 RocksDB 作为底层存储引擎,比如TiDB。
存储和检索
在讲述LevelDB的实现时,我想从数据存储和检索开始论述,讨论不同结构的存储方式的演进与区别。
在最基础的层面,一个数据库应该能做两件事:
- 给数据库一些数据,它应该能够存储这些数据
- 找数据库要回这些数据,它应该能够给你这些数据
SimpleDB
我们尝试实现一个最简单的KeyValue持久化数据库,支持以下功能:
- 持久化
- set(String key, String value)
- get(String key)
新建项目SimpleDB,构建一个Server,支持
- set接口将收到的Key和Value拼接成KeyValue结构的JSON字符串追加到指定持久化文件中
- get接口按照参数Key的值去持久化文件中匹配对应的Value
Set
@GetMapping(path = "set")public String set(@RequestParam("key") String key, @RequestParam("value") String value) {if (StringUtils.isEmpty(key) || StringUtils.isEmpty(value)) return "FALSE";String recordLine = buildRecordLine(key, value);FileUtil.writeString(recordLine, PATH, UTF_8, true);return "OK";}
Get
@GetMapping(path = "get")public String get(String key) {List<String> recordLines = FileUtil.readLines(PATH);List<Record> targetRecords = recordLines.stream().map(line -> JsonUtil.decodeJson(line, Record.class)).filter(record -> key.equals(record.getKey())).collect(Collectors.toList());return CollectionUtils.isEmpty(targetRecords) ? null : targetRecords.get(targetRecords.size() - 1).getValue();}
使用
执行以下set请求
http://localhost:8080/set?key=name&value=yuminghttp://localhost:8080/set?key=age&value=24http://localhost:8080/set?key=name&value=yuming2
持久化文件内容
{"key":"name","value":"yuming"}{"key":"age","value":"24"}{"key":"name","value":"yuming2"}
执行以下get请求
http://localhost:8080/get?key=namehttp://localhost:8080/get?key=age
响应为
yuming224
分析写操作
set操作非常简单,收到请求追加到持久化文件中,因为是顺序写所以效率会很高。
类似的很多内部基于日志的数据库也是将数据追加到文件中,当然真正的数据库有更多的问题需要处理(如并发控制,回收磁盘空间以避免日志无限增长,处理错误与部分写入的记录),但基本原理是一样的。
并发写
现有的set方法并不支持,不过只需要简单改造一下,保证实际上的写线程只有一个即可。
private static ExecutorService executorService = Executors.newSingleThreadExecutor();/*** set接口将收到的Key和Value拼接成KeyValue结构的JSON字符串追加到指定持久化文件中** @param key* @param value* @return*/@GetMapping(path = "set")public String set(@RequestParam("key") String key, @RequestParam("value") String value) {if (StringUtils.isEmpty(key) || StringUtils.isEmpty(value)) return "FALSE";String recordLine = buildRecordLine(key, value);Future<?> future = executorService.submit(() -> FileUtil.writeString(recordLine, PATH, UTF_8, true));try {future.get();return "OK";} catch (Exception e) {LOGGER.error("writeString error", e);return "FALSE";}}
分析读操作
再来看Get操作,由于每次查询都需要遍历整个日志文件(O(n)),当日志文件越来越大时,Get操作的性能不容乐观。
能否优化
第一个思路是能不能加缓存,但是随着数据量越来越多内存明显是不够用的。
如果热数据比较多,大多数key很快被覆盖,甚至后续我们提供删除方法(追加value为null的行,后续压缩线程处理)实际上的KeyValue对数没那么多,是不是就能使用缓存了呢?
对于这种情况首先是需要处理缓存和文件内容的数据一致性问题。
第二点就是既然都是热数据,实际的有效数据根本没那么多,我们为什么要使用缓存,而不是把数据存放在内存中呢?
Redis
Redis直接将数据保存在内存中,为了实现持久化功能也会将数据追加到日志文件中,日志文件只在启动时恢复数据使用(顺序读,且只执行一次)。
这样Redis就能保证:
- 写操作,先写到内存中,后续顺序写入磁盘,速度快
- 读操作,直接在内存中查找,速度快
由于数据存储在内存中,Redis也能够实现以下功能:
- 基于内存的复杂而高效的数据结构
- 单个处理线程,实现串行化
如何压缩日志文件
- 读取原有日志文件压缩后生成新文件
- 直接根据内存中的数据生成新日志文件
索引
不是所有的场景都能够将数据全存储在内存中,那么我们还是需要探索一下有没有其他方案。
为了高效查找数据库中特定键的值,我们需要一个数据结构:索引(index)。
索引背后的大致思想是,保存一些额外的元数据作为路标,帮助你找到想要的数据。如果你想在同一份数据中以几种不同的方式进行搜索,那么你也许需要不同的索引,建在数据的不同部分上。
索引是从主数据衍生的附加结构,这种结构必然不是简单的追加日志。许多数据库允许添加与删除索引,这不会影响数据的内容,它只影响查询和插入的性能。维护额外的结构会产生开销,特别是在写入时。
写入性能很难超过简单地追加写入文件,因为追加写入是最简单的写入操作。任何类型的索引通常都会减慢写入速度,因为每次写入数据时都需要更新索引。

这是存储系统中一个重要的权衡:精心选择的索引加快了读查询的速度,但是每个索引都会拖慢写入速度。因为这个原因,数据库默认并不会索引所有的内容,而需要你通过对应用查询模式的了解来手动选择索引。你可以选择能为应用带来最大收益,同时又不会引入超出必要开销的索引。
哈希索引
我们继续优化我们的SimpleDB,之前有讨论对读操作加缓存,我们提到对所有数据都加缓存内存是无法承受的。
为了减少缓存的大小,我们可以不全量缓存,只缓存部分热数据,使用LRU淘汰不常用的缓存。
使用这种方案在缓存未命中的时候需要遍历整个日志文件,数据量很大的时候查找时间无法接受,并且查询的响应时间区别太大。
既然不能部分缓存,那么我们能否压缩一下我们的缓存。
我们之前的缓存构建的是Map
我们构建的这样一个结构其实就是哈希索引。
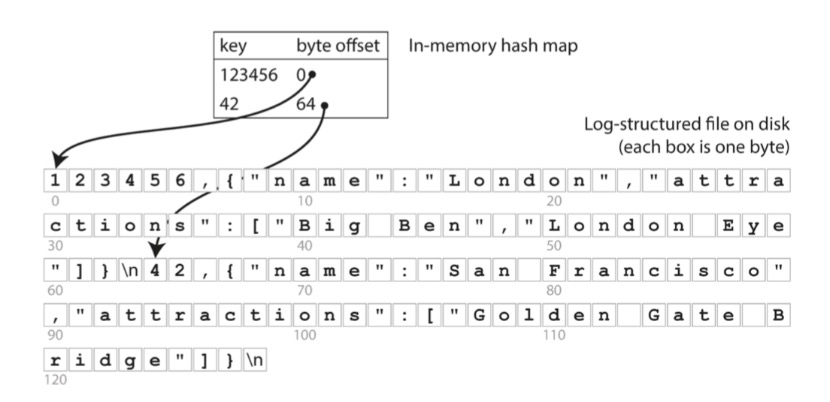
这样的存储引擎非常适合每个键的值经常更新的情况。例如,键可能是视频的URL,值可能是它播放的次数(每次有人点击播放按钮时递增)。
在这种类型的工作负载中,有很多写操作,但是没有太多不同的键——每个键有很多的写操作,但是将所有键保存在内存中是可行的。
压缩
直到现在,我们只是追加写入一个文件 —— 所以如何避免最终用完磁盘空间?一种好的解决方案是,将日志分为特定大小的段,当日志增长到特定尺寸时关闭当前段文件,并开始写入一个新的段文件。
然后,我们就可以对这些段进行压缩,如下图所示。压缩意味着在日志中丢弃重复的键,只保留每个键的最近更新。

而且,由于压缩经常会使得段变得很小(假设在一个段内键被平均重写了好几次),我们也可以在执行压缩的同时将多个段合并在一起,如下图所示。段被写入后永远不会被修改,所以合并的段被写入一个新的文件。
冻结段的合并和压缩可以在后台线程中完成,在进行时,我们仍然可以继续使用旧的段文件来正常提供读写请求。合并过程完成后,我们将读取请求转换为使用新的合并段而不是旧段 —— 然后可以简单地删除旧的段文件。

为什么使用追加日志而不是覆盖旧值
- 追加和分段合并是顺序写入操作,通常比随机写入快得多,尤其是在磁盘旋转硬盘上。在某种程度上,顺序写入在基于闪存的固态硬盘上也是优选的。
- 如果段文件是附加的或不可变的,并发和崩溃恢复就简单多了。例如,不必担心在覆盖值时发生崩溃的情况,而将包含旧值和新值的一部分的文件保留在一起。
局限性
- 散列表必须能放进内存,原则上可以在磁盘上保留一个哈希映射,不幸的是磁盘哈希映射很难表现优秀。它需要大量的随机访问I/O,当它变满时增长是很昂贵的,并且散列冲突需要很多的逻辑。
- 范围查询效率不高。例如,无法轻松扫描kitty00000和kitty99999之间的所有键——您必须在散列映射中单独查找每个键。
SSTable
使用哈希索引当数据量很多时我们无法将所有索引数据都放入内存,那么我们能否只存储部分索引呢?基于之前的文件结构显然是无法支持的。如果我们的文件内容是有序排列的,是不是就可以只存储部分索引呢?
我们可以对段文件的格式做一个简单的改变:我们要求键值对的序列按键排序。乍一看,这个要求似乎打破了我们使用顺序写入的能力。
我们把这个格式称为排序字符串表(Sorted String Table),简称SSTable。我们还要求每个键只在每个合并的段文件中出现一次(压缩过程已经保证)。与使用散列索引的日志段相比,SSTable有几个很大的优势:
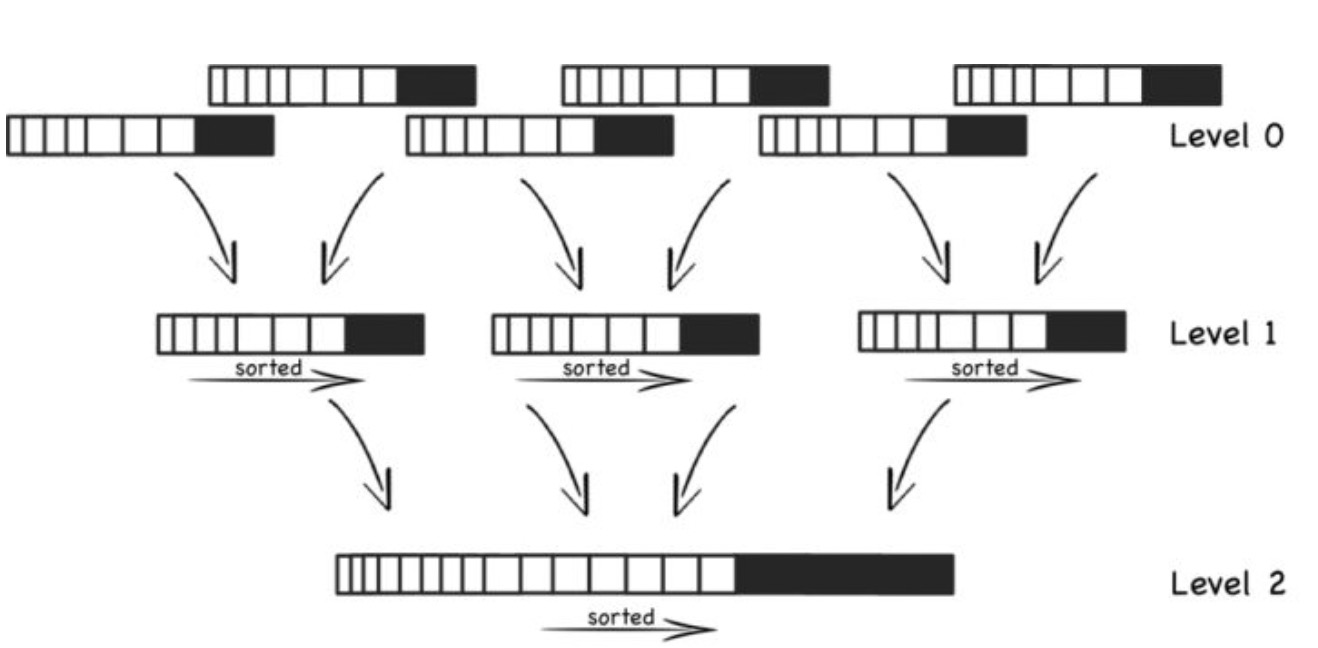
- 合并段是简单而高效的,即使文件大于可用内存。这种方法就像归并排序算法中使用的方法一样,如下图所示:您开始并排读取输入文件,查看每个文件中的第一个键,复制最低键(根据排序顺序)到输出文件,并重复。这产生一个新的合并段文件,也按键排序。

如果在几个输入段中出现相同的键,该怎么办?请记住,每个段都包含在一段时间内写入数据库的所有值。这意味着一个输入段中的所有值必须比另一个段中的所有值更新(假设我们总是合并相邻的段)。
当多个段包含相同的键时,我们可以保留最近段的值,并丢弃旧段中的值。
2. 为了在文件中找到一个特定的键,你不再需要保存内存中所有键的索引。以下图为例:假设你正在内存中寻找键 handiwork,但是你不知道段文件中该关键字的确切偏移量。
然而,你知道 handbag 和 handsome 的偏移,而且由于排序特性,你知道 handiwork 必须出现在这两者之间。这意味着您可以跳到 handbag 的偏移位置并从那里扫描,直到您找到 handiwork(或没找到)。
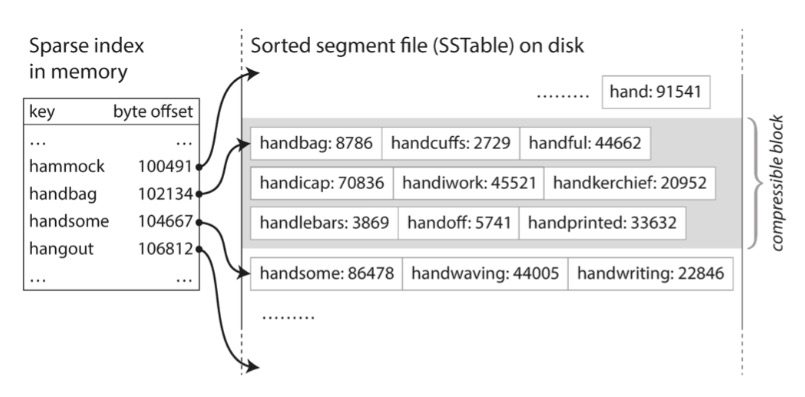
您仍然需要一个内存中索引来告诉您一些键的偏移量,但它可能很稀疏:每几千字节的段文件就有一个键就足够了,因为几千字节可以很快被扫描。
3. 由于读取请求无论如何都需要扫描所请求范围内的多个键值对,因此可以将这些记录分组到块中,并在将其写入磁盘之前对其进行压缩(如上图中的阴影区域所示)。
稀疏内存中索引的每个条目都指向压缩块的开始处。除了节省磁盘空间之外,压缩还可以减少IO带宽的使用。
构建和维护SSTables
写入
到目前为止,但是如何让你的数据首先被按键排序呢?我们的传入写入可以以任何顺序发生。
在磁盘上维护有序结构是可能的(参考“B树”),但在内存保存则要容易得多。有许多可以使用的众所周知的树形数据结构,例如红黑树或AVL树。使用这些数据结构,您可以按任何顺序插入键,并按排序顺序读取它们。
现在我们可以使我们的存储引擎工作如下:
写入时,先将其添加到内存中的平衡树数据结构(例如,红黑树)。这个内存树有时被称为内存表(memtable)。

当内存表大于某个阈值时,将其作为SSTable文件写入磁盘。这可以高效地完成,因为树已经维护了按键排序的键值对。新的SSTable文件成为数据库的最新部分。当SSTable被写入磁盘时,写入可以继续到一个新的内存表实例。
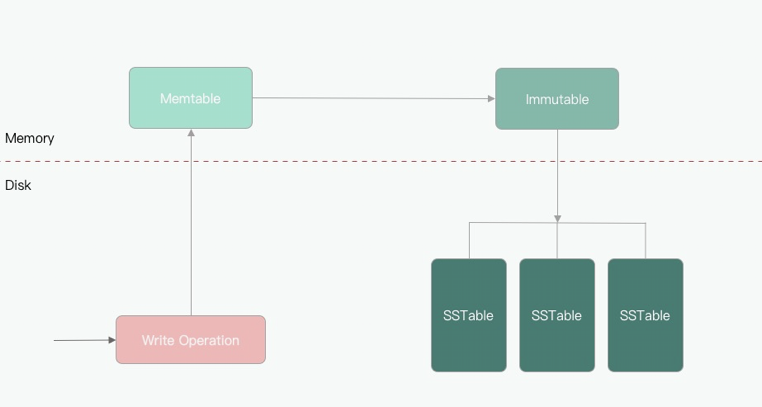
为了提供读取请求,首先尝试在内存表中找到关键字,然后在最近的磁盘段中,然后在下一个较旧的段中找到该关键字。
在后台会运行合并和压缩过程以组合段文件并丢弃覆盖或删除的值。
这个方案效果很好。它只会遇到一个问题:如果数据库崩溃,则最近的写入(在内存表中,但尚未写入磁盘)将丢失。为了避免这个问题,我们可以在磁盘上保存一个单独的日志,每个写入都会立即被附加到磁盘上。
该日志不是按排序顺序,但这并不重要,因为它的唯一目的是在崩溃后恢复内存表。每当内存表写出到SSTable时,相应的日志都可以被丢弃。

读取
从 LevelDB 中读取数据其实并不复杂,memtable 和 imm 更像是两级缓存,它们在内存中提供了更快的访问速度,如果能直接从内存中的这两处直接获取到响应的值,那么它们一定是最新的数据。
LevelDB 总会将新的键值对写在最前面,并在数据压缩时删除历史数据。

数据的读取是按照 MemTable、Immutable MemTable 以及不同层级的 SSTable 的顺序进行的,前两者都是在内存中,后面不同层级的 SSTable 都是以 *.ldb 文件的形式持久存储在磁盘上,而正是因为有着不同层级的 SSTable,所以我们的数据库的名字叫做 LevelDB。
当 LevelDB 在内存中没有找到对应的数据时,它才会到磁盘中多个层级的 SSTable 中进行查找,这个过程就稍微有一点复杂了,LevelDB 会在多个层级中逐级进行查找,并且不会跳过其中的任何层级.
在查找的过程就涉及到一个非常重要的数据结构 FileMetaData:

FileMetaData 中包含了整个文件的全部信息,其中包括键的最大值和最小值、允许查找的次数、文件被引用的次数、文件的大小以及文件号,因为所有的 SSTable 都是以固定的形式存储在同一目录下的,所以我们可以通过文件号轻松查找到对应的文件。

查找的顺序就是从低到高了,LevelDB 首先会在 Level0 中查找对应的键。但是,与其他层级不同,Level0 中多个 SSTable 的键的范围有重合部分的,在查找对应值的过程中,会依次查找 Level0 中固定的 4 个 SSTable。
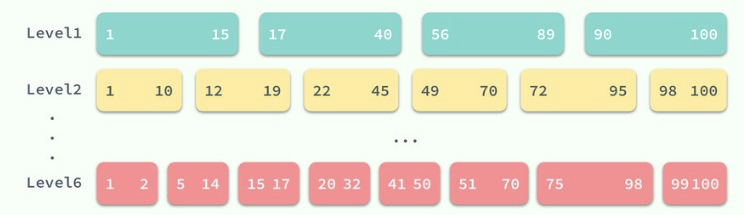
但是当涉及到更高层级的 SSTable 时,因为同一层级的 SSTable 都是没有重叠部分的,所以我们在查找时可以利用已知的 SSTable 中的极值信息 smallest/largest 快速查找到对应的 SSTable,
再判断当前的 SSTable 是否包含查询的 key,如果不存在,就继续查找下一个层级直到最后的一个层级 kNumLevels(默认为 7 级)或者查询到了对应的值。
LSM树(Log-Structured Merge Tree)
这里描述的算法本质上是LevelDB和RocksDB中使用的关键值存储引擎库,被设计嵌入到其他应用程序中。除此之外,LevelDB可以在Riak中用作Bitcask的替代品。在Cassandra和HBase中使用了类似的存储引擎,这两种引擎都受到了Google的Bigtable文档(引入了SSTable和memtable)的启发。
最初这种索引结构是由Patrick O’Neil等人描述的。在日志结构合并树(或LSM树)的基础上,建立在以前的工作上日志结构的文件系统。基于这种合并和压缩排序文件原理的存储引擎通常被称为LSM存储引擎。
Lucene是Elasticsearch和Solr使用的一种全文搜索的索引引擎,它使用类似的方法来存储它的词典。全文索引比键值索引复杂得多,但是基于类似的想法:在搜索查询中给出一个单词,找到提及单词的所有文档(网页,产品描述等)。这是通过键值结构实现的,其中键是单词(关键词(term)),值是包含单词(文章列表)的所有文档的ID的列表。在Lucene中,从术语到发布列表的这种映射保存在SSTable类的有序文件中,根据需要在后台合并。
性能优化
与往常一样,大量的细节使得存储引擎在实践中表现良好。例如,当查找数据库中不存在的键时,LSM树算法可能会很慢:您必须检查内存表,然后将这些段一直回到最老的(可能必须从磁盘读取每一个),然后才能确定键不存在。
为了优化这种访问,存储引擎通常使用额外的Bloom过滤器。 (布隆过滤器是用于近似集合内容的内存高效数据结构,它可以告诉您数据库中是否出现键,从而为不存在的键节省许多不必要的磁盘读取操作。
还有不同的策略来确定SSTables如何被压缩和合并的顺序和时间。最常见的选择是大小分层压实。 LevelDB和RocksDB使用平坦压缩(LevelDB因此得名),HBase使用大小分层,Cassandra同时支持。
在规模级别的调整中,更新和更小的SSTables先后被合并到更老的和更大的SSTable中。在水平压实中,关键范围被拆分成更小的SSTables,而较旧的数据被移动到单独的“水平”,这使得压缩能够更加递增地进行,并且使用更少的磁盘空间。
即使有许多微妙的东西,LSM树的基本思想 —— 保存一系列在后台合并的SSTables —— 简单而有效。即使数据集比可用内存大得多,它仍能继续正常工作。
由于数据按排序顺序存储,因此可以高效地执行范围查询(扫描所有高于某些最小值和最高值的所有键),并且因为磁盘写入是连续的,所以LSM树可以支持非常高的写入吞吐量。
B树
刚才讨论的日志结构索引正处在逐渐被接受的阶段,但它们并不是最常见的索引类型。使用最广泛的索引结构在1970年被引入,不到10年后变得“无处不在”,B树经受了时间的考验。在几乎所有的关系数据库中,它们是标准的索引实现。
像SSTables一样,B树保持按键排序的键值对,这允许高效的键值查找和范围查询。但这就是相似之处的结尾:B树有着非常不同的设计理念。
我们前面看到的日志结构索引将数据库分解为可变大小的段,通常是几兆字节或更大的大小,并且总是按顺序编写段。
相比之下,B树将数据库分解成固定大小的块或页面,传统上大小为4KB(有时会更大),并且一次只能读取或写入一个页面。这种设计更接近于底层硬件,因为磁盘也被安排在固定大小的块中。
查找
每个页面都可以使用地址或位置来标识,这允许一个页面引用另一个页面 —— 类似于指针,但在磁盘而不是在内存中。我们可以使用这些页面引用来构建一个页面树,如图所示。

插入&修改
如果要更新B树中现有键的值,则搜索包含该键的页,更改该页中的值,并将该页写回到磁盘(对该页的任何引用保持有效)。
如果你想添加一个新的键,你需要找到其范围包含新键的页面,并将其添加到该页面。如果页面中没有足够的可用空间容纳新键,则将其分成两个半满页面,并更新父页面以解释键范围的新分区,如图所示。
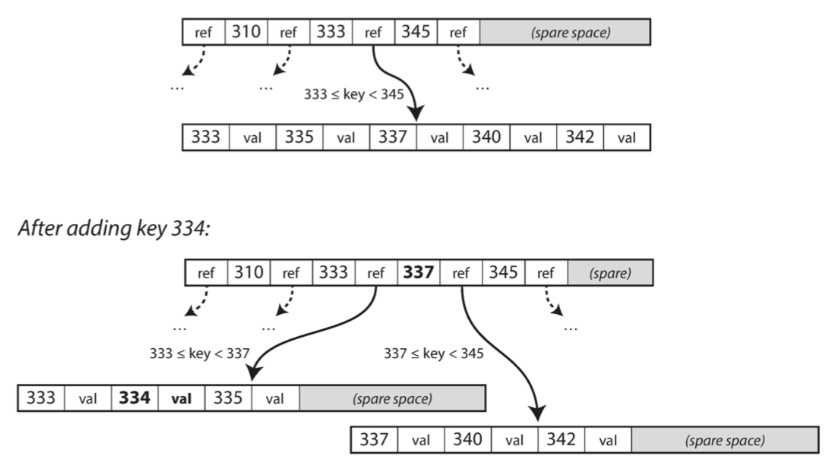
该算法确保树保持平衡:具有 n 个键的B树总是具有 O(log n) 的深度。大多数数据库可以放入一个三到四层的B树,所以你不需要遵追踪多页面引用来找到你正在查找的页面。(分支因子为 500 的 4KB 页面的四级树可以存储多达 256TB 。)
保证可靠
B树的基本底层写操作是用新数据覆盖磁盘上的页面。假定覆盖不改变页面的位置;即,当页面被覆盖时,对该页面的所有引用保持完整。这与日志结构索引(如LSM树)形成鲜明对比,后者只附加到文件(并最终删除过时的文件),但从不修改文件。
redo log
为了使数据库对崩溃具有韧性,B树实现通常会带有一个额外的磁盘数据结构:预写式日志(WAL, write-ahead-log)(也称为重做日志(redo log))。这是一个仅追加的文件,每个B树修改都可以应用到树本身的页面上。当数据库在崩溃后恢复时,这个日志被用来使B树恢复到一致的状态。
并发控制
更新页面的一个额外的复杂情况是,如果多个线程要同时访问B树,则需要仔细的并发控制 —— 否则线程可能会看到树处于不一致的状态。这通常通过使用锁存器(latches)(轻量级锁)保护树的数据结构来完成。日志结构化的方法在这方面更简单,因为它们在后台进行所有的合并,而不会干扰传入的查询,并且不时地将旧的分段原子交换为新的分段。
比较B树和LSM树
尽管B树实现通常比LSM树实现更成熟,但LSM树由于其性能特点也非常有趣。根据经验,通常LSM树的写入速度更快,而B树的读取速度更快。 LSM树上的读取通常比较慢,因为它们必须在压缩的不同阶段检查几个不同的数据结构和SSTables。
LSM树的优点
写入快
B树索引必须至少两次写入每一段数据:一次写入预先写入日志,一次写入树页面本身(也许再次分页)。即使在该页面中只有几个字节发生了变化,也需要一次编写整个页面的开销。有些存储引擎甚至会覆盖同一个页面两次,以免在电源故障的情况下导致页面部分更新。
碎片少
LSM树可以被压缩得更好,因此经常比B树在磁盘上产生更小的文件。 B树存储引擎会由于分割而留下一些未使用的磁盘空间:当页面被拆分或某行不能放入现有页面时,页面中的某些空间仍未被使用。由于LSM树不是面向页面的,并且定期重写SSTables以去除碎片,所以它们具有较低的存储开销,特别是当使用平坦压缩时。
LSM树的缺点
压缩阻塞
日志结构存储的缺点是压缩过程有时会干扰正在进行的读写操作。尽管存储引擎尝试逐步执行压缩而不影响并发访问,但是磁盘资源有限,所以很容易发生请求需要等待而磁盘完成昂贵的压缩操作。而B树的行为则相对更具可预测性。
压缩速率
压缩的另一个问题出现在高写入吞吐量:磁盘的有限写入带宽需要在初始写入(记录和刷新内存表到磁盘)和在后台运行的压缩线程之间共享。写入空数据库时,可以使用全磁盘带宽进行初始写入,但数据库越大,压缩所需的磁盘带宽就越多。
如果写入吞吐量很高,并且压缩没有仔细配置,压缩跟不上写入速率。在这种情况下,磁盘上未合并段的数量不断增加,直到磁盘空间用完,读取速度也会减慢,因为它们需要检查更多段文件。通常情况下,即使压缩无法跟上,基于SSTable的存储引擎也不会限制传入写入的速率,所以需要进行明确的监控来检测这种情况。
事务
B树的一个优点是每个键只存在于索引中的一个位置,而日志结构化的存储引擎可能在不同的段中有相同键的多个副本。
这个方面使得B树在想要提供强大的事务语义的数据库中很有吸引力:在许多关系数据库中,事务隔离是通过在键范围上使用锁来实现的,在B树索引中,这些锁可以直接连接到树。
结论
B树在数据库体系结构中是非常根深蒂固的,为许多工作负载提供始终如一的良好性能,所以它们不可能很快就会消失。
在新的数据存储中,日志结构化索引变得越来越流行。没有快速和容易的规则来确定哪种类型的存储引擎对你的场景更好,所以值得进行一些经验上的测试。
参考

若有收获,就点个赞吧
0 人点赞
