- abs()
- all()
- any()
- bin()
- bytes()
- callable()
- chr()
- complex()
- dir(obj)
- dict()
- divmod()
- eval()
- exec()
- enumerate()
- filter()
- float()
- format()
- frozenset()
- hash()
- hex()
- int()
- id()
- isinstance(object, classinfo)
- issubclass(class, classinfo)
- len()
- list()
- map(function, iterable, …)
- max()
- min()
- next()
- oct()
- ord()
- open()
- pow(x,y)
- raw_input([prompt])
- repr()
- round(x,[y])
- range()
- set()
- setattr,getattr,delattr,hasattr
- 1
- 5
- False
abs()
all()
函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
元素除了是 0、空、FALSE 外都算 TRUE。
any()
函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。
bin()
返回一个整数 int 或者长整数 long int 的二进制表示。
bytes()
callable()
函数用于检查一个对象是否是可调用的。如果返回True,object仍然可能调用失败;但如果返回False,调用对象ojbect绝不会成功。
chr()
complex()
函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
complex(1, 2) #--------- (1 + 2j)complex(1) # 数字-------- (1 + 0j)complex("1") # 当做字符串处理 -----------(1 + 0j)
dir(obj)
dict()
函数用于创建一个字典。
dict() # 创建空字典 {}dict(a='a', b='b', t='t') # 传入关键字 {'a': 'a', 'b': 'b', 't': 't'}dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典 {'three': 3, 'two': 2, 'one': 1}dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典 {'three': 3, 'two': 2, 'one': 1}
divmod()
函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
divmod(7, 2)#------ (3, 1)
eval()
函数用来执行一个字符串表达式,并返回表达式的值。
x = 7eval( '3 * x' ) #---------- 21eval('pow(2,2)') #--------------4eval('2 + 2') #--------------4
exec()
执行储存在字符串或文件中的 Python 语句
exec(object[, globals[, locals]])
- globals:可选参数,表示全局命名空间(存放全局变量),如果被提供,则必须是一个字典对象。
- locals:可选参数,表示当前局部命名空间(存放局部变量),如果被提供,可以是任何映射对象。
exec("print ('runoob.com')")多行语句字符串exec ("""for i in range(5):print (i) """)exec ("y=1+1")print(y)>>>2
enumerate()
用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标seq = ['one', 'two', 'three']for i, element in enumerate(seq):print(i, element)...0 one1 two2 three...
filter()
函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象
def is_odd(n):return n % 2 == 1tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])newlist = list(tmplist)print(newlist)
float()
format()
格式化函数
"{} {}".format("hello", "world") # 不设置指定位置,按默认顺序 'hello world'"{0} {1}".format("hello", "world") # 设置指定位置 'hello world'"{1} {0} {1}".format("hello", "world") # 设置指定位置 'world hello world'# 通过字典设置参数site = {"name": "菜鸟教程", "url": "www.runoob.com"}print("网站名:{name}, 地址 {url}".format(**site))# 通过列表索引设置参数my_list = ['菜鸟教程', 'www.runoob.com']print("网站名:{0[0]}, 地址 {0[1]}".format(my_list)) # "0" 是必须的#通过对象设置参数class AssignValue(object):def __init__(self, value):self.value = valuemy_value = AssignValue(6)print('value 为: {0.value}'.format(my_value)) # "0" 是可选的
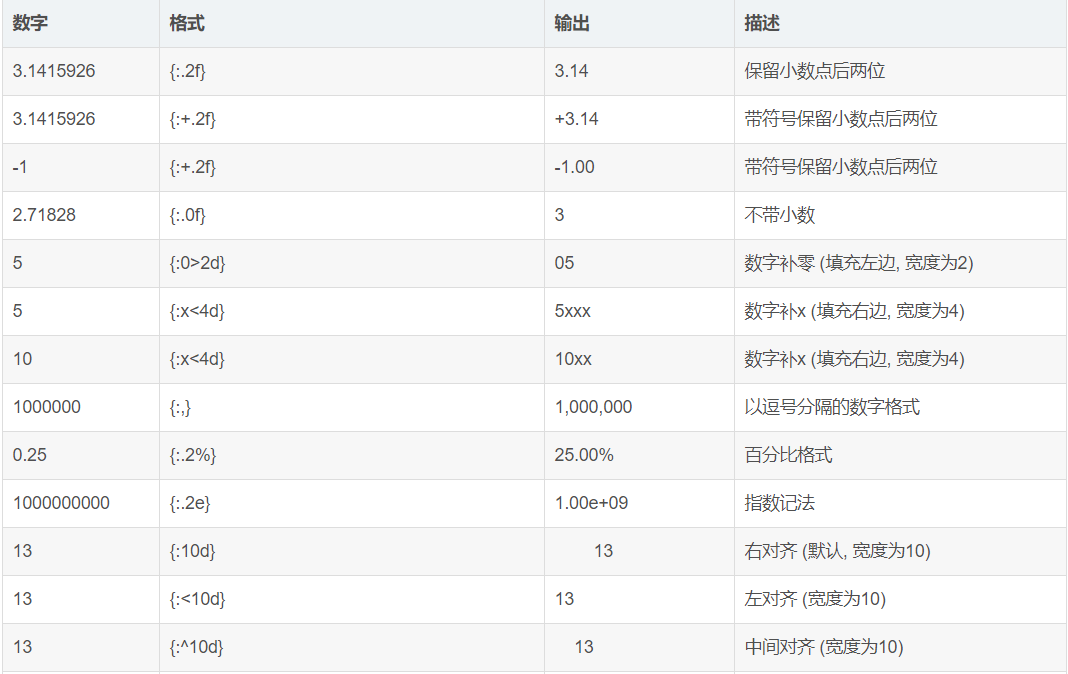
frozenset()
hash()
hex()
int()
id()
isinstance(object, classinfo)
issubclass(class, classinfo)
判断参数 class 是否是类型参数 classinfo 的子类。
len()
list()
map(function, iterable, …)
会根据提供的函数对指定序列做映射。
def square(x) :return x ** 2map(square, [1,2,3,4,5]) #-----------------[1, 4, 9, 16, 25]# 使用 lambda 匿名函数map(lambda x: x ** 2, [1, 2, 3, 4, 5]) #-----------------[1, 4, 9, 16, 25]# 提供了两个列表,对相同位置的列表数据进行相加map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) #--------- [3, 7, 11, 15, 19]
max()
min()
next()
oct()
ord()
它以一个字符串(Unicode 字符)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值。
快速打印a-zfor i in range(26):print(chr(i+ord('a')))
open()
pow(x,y)
raw_input([prompt])
将所有输入作为字符串看待,prompt: 可选,字符串,可作为一个提示语。
repr()
函数将对象转化为供解释器读取的形式,可以解决变量无法在前面+‘r’而导致的自动转义
round(x,[y])
x:数值,y:要保留小数点,默认为0
round对小数的精确度采用了四舍六入五成双的方式。
例如对于一个小数a.bcd,需要精确到小数点后两位,那么就要看小数点后第三位:
- 如果d小于5,直接舍去
- 如果d大于5,直接进位
- 如果d等于5:
- 情况一:后面没有数据,且c为偶数,那么不进位,保留c
- 情况二:d后面没有数据,且c为奇数,那么进位,c变成(c + 1)
- 情况三:如果d后面还有非0数字,例如实际上小数为a.bcdef,此时一定要进位,c变成(c + 1)
关于奇进偶舍,有兴趣的同学可以在维基百科搜索这两个词条:数值修约和奇进偶舍。所以,round给出的结果如果与你设想的不一样,那么你需要考虑两个原因:你的这个小数在计算机中能不能被精确储存?如果不能,那么它可能并没有达到四舍五入的标准,例如1.115,它的小数点后第三位实际上是4,当然会被舍去。如果你的这个小数在计算机中能被精确表示那么,round采用的进位机制是奇进偶舍,所以这取决于你要保留的那一位,它是奇数还是偶数,以及它的下一位后面还有没有数据。
range()
函数返回的是一个可迭代对象range(start, stop[, step])#step默认为1(加),支持-1(减)list(range(0, 5)) #----0,1,2,3,4list(range(0, 10, 2)) #----[0, 2, 4, 6, 8]
set()
函数创建一个无序不重复元素集setattr,getattr,delattr,hasattr
```python class A(object): bar = 1 a = A() getattr(a, ‘bar’) # 获取属性 bar 值1
setattr(a, ‘bar’, 5) # 设置属性 bar 值,属性不存在会创建 a.bar
5
hasattr(a,’bar’)
False
delattr(a,’bar’) a.bar#报错
<a name="Oaq3v"></a>## sorted(iterable, key=None, reverse=False)函数对所有可迭代的对象进行排序操作。```python'''iterable -- 可迭代对象。key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。'''list1=[[1,3],[3,2],[5,1]]list(sorted(list1,lambad x:x[1]))>>>[[5,1],[3,2],[1,3]]dict1={'a':2,'b':1,'c':3}dict(sorted(dict1.items,lambad x:x[1],reverse=True))>>>{'c':3,'a':2,'b':1}
str()
sum()
super()
tuple()
type()
zip()
函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组
a = [1,2,3]b = [4,5,6]c = [4,5,6,7,8]zipped = zip(a,b)list(zipped)>>>[(1, 4), (2, 5), (3, 6)]list(zip(a,c)) >>>[(1, 4), (2, 5), (3, 6)]#解压d=[[1,2,3,4],[5,6,7,8]]zip(*d)>>>[[1,5],[2,6],[3,7],[4,8]]

若有收获,就点个赞吧
0 人点赞
