1. 什么是Job
一个 job 就是一个实现了 Job 接口的类,该接口只有一个方法:
Job 接口:
package org.quartz;public interface Job {public void execute(JobExecutionContext context)throws JobExecutionException;}
2. 定义一个Job(基于输入)
(1)一个Job类
public class HelloJob implements Job {// Job必须有一个无参构造方法public HelloJob() {}@Overridepublic void execute(JobExecutionContext context)throws JobExecutionException{System.err.println("Hello! HelloJob is executing.");}}
这里定义了一个实现Job接口的类,这个类仅仅表明该job需要完成什么类型的任务,除此之外,Quartz还需要知道该Job实例所包含的属性;这将由JobDetail类来完成。
JobDetail实例是通过JobBuilder类创建的,导入该类下的所有静态方法,会让你编码时有DSL的感觉:
import static org.quartz.JobBuilder.*;
(2)定义一个Job实例
Quartz 提供的“builder”类,可以认为是一种领域特定语言(DSL,Domain Specific Language)。这种级联的 API 非常方便用户使用。
DSL 的静态导入可以通过以下导入语句来实现:
import static org.quartz.JobBuilder.*;import static org.quartz.SimpleScheduleBuilder.*;import static org.quartz.CronScheduleBuilder.*;import static org.quartz.CalendarIntervalScheduleBuilder.*;import static org.quartz.TriggerBuilder.*;import static org.quartz.DateBuilder.*;
JobBuilder类被用来实例化JobDetail。
客户端代码可以使用DSL编写这样的代码:
// 定义一个Job实例,并将其绑定到HelloJob类JobDetail helloJob = newJob(HelloJob.class).withIdentity("helloJob", "group1") // 名称: "helloJob", 组: "group1".build();
代码解释:newJob()方法创建一个JobBuilder对象,
然后通过DSL风格级联调用withIdentity(…)方法指定JobKey标识JobDetail,The builder总是试图保持自己处于有效状态,并在任何时候调用build()设置合理的默认值。例如,如果你不调用withIdentity(..) 方法,则将为你生成一个作业名称,也可以进行分组。 再级联调用build()方法,产生一个JobDetail对象。
再级联调用build()方法,产生一个JobDetail对象。
我们在创建JobDetail时,将要执行的job的类名传给了JobDetail,所以scheduler就知道了要执行何种类型的job;每次当scheduler执行job时,在调用其execute(…)方法之前会创建该类的一个新的实例;执行完毕,对该实例的引用就被丢弃了,实例会被垃圾回收;这种执行策略带来的一个后果是,job必须有一个无参的构造函数(当使用默认的JobFactory时);另一个后果是,在job类中,不应该定义有状态的数据属性,因为在job的多次执行中,这些属性的值不会保留。
那么如何给job实例增加属性或配置呢?如何在job的多次执行中,跟踪job的状态呢?答案就是:JobDataMap,这是JobDetail对象的一部分。
(3)JobDataMap
JobDataMap中可以包含不限量的(序列化的)数据对象,在job实例执行的时候,可以使用其中的数据;JobDataMap是Java Map接口的一个实现,额外增加了一些便于存取基本类型的数据的方法。
将job加入到scheduler之前,在构建JobDetail时,可以将数据放入JobDataMap,如下示例:
// 定义一个job并将其绑定到HelloJob.classJobDetail job = newJob(HelloJob.class).withIdentity("helloJob", "group1") // 名称: "helloJob", 组: "group1".usingJobData("jobSays", "Hello World!") //放入一个键值对.usingJobData("myFloatValue", 3.141f) //放入一个键值对.build();
usingJobData()方法: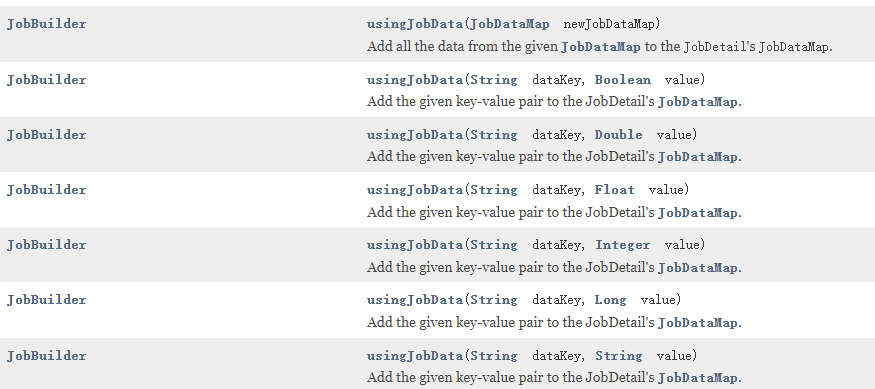
在job的执行过程中,可以从JobDataMap中取出数据,如下示例:
public class HelloJob implements Job {public HelloJob() {}@Overridepublic void execute(JobExecutionContext context) throws JobExecutionException {JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getJobDetail().getJobDataMap();//从JobDataMap中取出数据String jobSays = dataMap.getString("jobSays");float myFloatValue = dataMap.getFloat("myFloatValue");//打印数据System.out.println("Hello, HelloJob is executing.");System.out.println("jobSays:" + jobSays);System.out.println("myFloatValue:"+myFloatValue);}}
执行结果如下: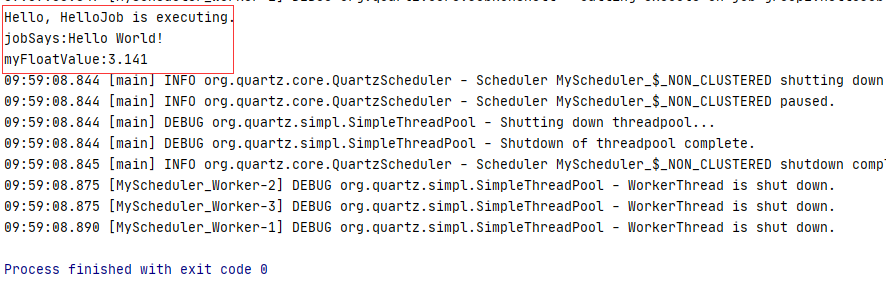
如果你使用的是持久化的存储机制(本教程的JobStore部分会讲到),在决定JobDataMap中存放什么数据的时候需要小心,因为JobDataMap中存储的对象都会被序列化,因此很可能会导致类的版本不一致的问题;Java的标准类型都很安全,如果你已经有了一个类的序列化后的实例,某个时候,别人修改了该类的定义,此时你需要确保对类的修改没有破坏兼容性;更多细节,参考现实中的序列化问题。另外,你也可以配置JDBC-JobStore和JobDataMap,使得map中仅允许存储基本类型和String类型的数据,这样可以避免后续的序列化问题。
如果你在job类中,为JobDataMap中存储的数据的key增加set方法(如在上面示例中,增加setJobSays(String val)方法),那么Quartz的默认JobFactory实现在job被实例化的时候会自动调用这些set方法,这样你就不需要在execute()方法中显式地从map中取数据了。
在Job执行时,JobExecutionContext中的JobDataMap为我们提供了很多的便利。它是JobDetail中的JobDataMap和Trigger中的JobDataMap的并集,但是如果存在相同的数据,则后者会覆盖前者的值。
下面的示例,在job执行时,从JobExecutionContext中获取合并后的JobDataMap:
public class DumbJob implements Job {public DumbJob() {}public void execute(JobExecutionContext context)throws JobExecutionException{JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getMergedJobDataMap(); // 注意这里和上例不一样String jobSays = dataMap.getString("jobSays");float myFloatValue = dataMap.getFloat("myFloatValue");ArrayList state = (ArrayList)dataMap.get("myStateData");state.add(new Date());System.err.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);}}
打印结果:
如果你希望使用JobFactory实现数据的自动“注入”,则示例代码为:
public class DumbJob implements Job {//成员变量String jobSays;float myFloatValue;ArrayList state;public DumbJob() {}public void execute(JobExecutionContext context)throws JobExecutionException{JobKey key = context.getJobDetail().getKey();JobDataMap dataMap = context.getMergedJobDataMap();state.add(new Date());System.err.println("Instance " + key + " of DumbJob says: " + jobSays + ", and val is: " + myFloatValue);}//set方法public void setJobSays(String jobSays) {this.jobSays = jobSays;}public void setMyFloatValue(float myFloatValue) {this.myFloatValue = myFloatValue;}public void setState(ArrayList state) {this.state = state;}}
打印结果:
你也许发现,整体上看代码更多了,但是execute()方法中的代码更简洁了。而且,虽然代码更多了,但如果你的IDE可以自动生成setter方法,或者使用lombok插件,你就不需要写代码调用相应的方法从JobDataMap中获取数据了,所以你实际需要编写的代码更少了。当前,如何选择,由你决定。
注意,Job实现类的成员变量名要和定义JobDetail实例时的名称一样。
(4)Job实例
很多用户对于Job实例到底由什么构成感到很迷惑。我们在这里解释一下,并在接下来的小节介绍job状态和并发。
你可以只创建一个job类,然后创建多个与该job关联的JobDetail实例,每一个实例都有自己的属性集和JobDataMap,最后,将所有的实例都加到scheduler中。
比如,你创建了一个实现Job接口的类“SalesReportJob”。该job需要一个参数(通过JobdataMap传入),表示负责该销售报告的销售员的名字。因此,你可以创建该job的多个实例(JobDetail),比如“SalesReportForJoe”、“SalesReportForMike”,将“joe”和“mike”作为JobDataMap的数据传给对应的job实例。
当一个trigger被触发时,与之关联的JobDetail实例会被加载,JobDetail引用的job类通过配置在Scheduler上的JobFactory进行初始化。默认的JobFactory实现,仅仅是调用job类的newInstance()方法,然后尝试调用JobDataMap中的key的setter方法。你也可以创建自己的JobFactory实现,比如让你的IOC或DI容器可以创建/初始化job实例。
在Quartz的描述语言中,我们将保存后的JobDetail称为“job定义”或者“JobDetail实例”,将一个正在执行的job称为“job实例”或者“job定义的实例”。当我们使用“job”时,一般指代的是job定义,或者JobDetail;当我们提到实现Job接口的类时,通常使用“job类”。
(5)Job状态与并发
关于job的状态数据(即JobDataMap)和并发性,还有一些地方需要注意。在job类上可以加入一些注解,这些注解会影响job的状态和并发性。
@DisallowConcurrentExecution:将该注解加到job类上,告诉Quartz不要并发地执行同一个job定义(这里指特定的job类)的多个实例。请注意这里的用词。拿前一小节的例子来说,如果“SalesReportJob”类上有该注解,则同一时刻仅允许执行一个“SalesReportForJoe”实例,但可以并发地执行“SalesReportForMike”类的一个实例。所以该限制是针对JobDetail的,而不是job类的。但是我们认为(在设计Quartz的时候)应该将该注解放在job类上,因为job类的改变经常会导致其行为发生变化。
@PersistJobDataAfterExecution:将该注解加在job类上,告诉Quartz在成功执行了job类的execute方法后(没有发生任何异常),更新JobDetail中JobDataMap的数据,使得该job(即JobDetail)在下一次执行的时候,JobDataMap中是更新后的数据,而不是更新前的旧数据。和 @DisallowConcurrentExecution注解一样,尽管注解是加在job类上的,但其限制作用是针对job实例的,而不是job类的。由job类来承载注解,是因为job类的内容经常会影响其行为状态(比如,job类的execute方法需要显式地“理解”其”状态“)。
如果你使用了@PersistJobDataAfterExecution注解,我们强烈建议你同时使用@DisallowConcurrentExecution注解,因为当同一个job(JobDetail)的两个实例被并发执行时,由于竞争,JobDataMap中存储的数据很可能是不确定的。
(6)Job的其他特性
通过JobDetail对象,可以给job实例配置的其它属性有:
- Durability:如果一个job是非持久的,当没有活跃的trigger与之关联的时候,会被自动地从scheduler中删除。也就是说,非持久的job的生命期是由trigger的存在与否决定的;
- RequestsRecovery:如果一个job是可恢复的,并且在其执行的时候,scheduler发生硬关闭(hard shutdown)(比如运行的进程崩溃了,或者关机了),则当scheduler重新启动的时候,该job会被重新执行。此时,该job的JobExecutionContext.isRecovering() 返回true。
3. 相关操作
(1)定义并调度一个Job
// 定义一个Job实例JobDetail job1 = newJob(ColorJob.class).withIdentity("job1", "group1").build();//定义一个触发器,即时触发且不会重复Trigger trigger = newTrigger().withIdentity("trigger1", "group1").startNow().build();// 调用作业和触发器sched.scheduleJob(job, trigger);
(2)取消调度一个Job
取消调度Job的一个具体trigger
// 取消调度Job的一个具体trigger (一个Job可能不止一个trigger)scheduler.unscheduleJob(triggerKey("trigger1", "group1"));
删除一个Job并删除它所有调度的触发器
// 删除一个Job并删除它所有调度的触发器scheduler.deleteJob(jobKey("job1", "group1"));
(3)存储一个Job并在后来使用它
```java // 定义一个持续性的Job实例 (持续性的job可以脱离触发器存在) JobDetail job1 = newJob(MyJobClass.class) .withIdentity(“job1”, “group1”) .storeDurably() .build();
// 将Job添加到scheduler’s store sched.addJob(job, false);
<a name="ooGQH"></a>## (4)调度一个已经保存的Job```java// 定义一个即时触发器,将他绑定到Job上Trigger trigger = newTrigger().withIdentity("trigger1", "group1").startNow().forJob(jobKey("job1", "group1")).build();// 调度这个triggersched.scheduleJob(trigger);
(5)更新一个存在的Job
// 条件一个新的Job到调度器, 并通过指定的name和group(如果存在的话)来通知调度器取代现有的jobJobDetail job1 = newJob(MyJobClass.class).withIdentity("job1", "group1").build();// 保存,将重写标志值为"true"scheduler.addJob(job1, true);
4. 使用调度程序来初始化作业数据
你可以使用XML SchedulingDataProcessorPlugin(使用1.8版本替代之前的版本)来预定义Job和Trigger。下例提供了这个插件工作原理的简短描述。
- 首先,我们需要在调度器属性中显示的声明我们要使用XML SchedulingDataProcessorPlugin。这是一个quartz.properties的部分示例:
```xml
===================================================
Configure the Job Initialization Plugin
===================================================
org.quartz.plugin.jobInitializer.class = org.quartz.plugins.xml.XMLSchedulingDataProcessorPlugin org.quartz.plugin.jobInitializer.fileNames = jobs.xml org.quartz.plugin.jobInitializer.failOnFileNotFound = true org.quartz.plugin.jobInitializer.scanInterval = 10 org.quartz.plugin.jobInitializer.wrapInUserTransaction = false
属性解释:- **fileName**:以逗号分隔的文件名列表(带有路径)。这些文件包含job和trigger的xml定义。- **failOnFileNotFound**:如果xml定义文件未找到,插件是否会抛出一个异常,从而阻止它自己(插件)的初始化。- **scanInterval**:如果检测到文件更改,则可以重新加载xml定义文件。这是查看文件的时间间隔(以秒为单位)。设置为0以禁用扫描。- **wrapInUserTransaction**:如果使用XMLSchedulingDataProcessorPlugin的JobStoreCMT,请确保将此属性的值设置为true,否则可能会遇到意外行为。jobs.xml文件(或您在文件名属性中使用的任何其他名称)声明性地定义了作业和触发器。它还可以包含要删除现有数据的指令。这里有一个不言自明的例子:```xml<?xml version='1.0' encoding='utf-8'?><job-scheduling-data xmlns="http://www.quartz-scheduler.org/xml/JobSchedulingData"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.quartz-scheduler.org/xml/JobSchedulingData http://www.quartz-scheduler.org/xml/job_scheduling_data_1_8.xsd"version="1.8"><schedule><job><name>my-very-clever-job</name><group>MYJOB_GROUP</group><description>The job description</description><job-class>com.acme.scheduler.job.CleverJob</job-class><job-data-map allows-transient-data="false"><entry><key>burger-type</key><value>hotdog</value></entry><entry><key>dressing-list</key><value>ketchup,mayo</value></entry></job-data-map></job><trigger><cron><name>my-trigger</name><group>MYTRIGGER_GROUP</group><job-name>my-very-clever-job</job-name><job-group>MYJOB_GROUP</job-group><!-- trigger every night at 4:30 am --><!-- do not forget to light the kitchen's light --><cron-expression>0 30 4 * * ?</cron-expression></cron></trigger></schedule></job-scheduling-data>
更多请查阅XML。
5. 查找作业的触发器
List<Trigger> jobTriggers = sched.getTriggersOfJob(jobKey("jobName", "jobGroup"));

若有收获,就点个赞吧
0 人点赞
