- 1 分配问题
- 2 区间问题
- 3 练习题
- 605. Can-Place-Flowers(Easy)">605. Can-Place-Flowers(Easy)
- 452. Minimum Number of Arrows to Burst Balloons (Medium)">452. Minimum Number of Arrows to Burst Balloons (Medium)
- 763. Partition Labels (Medium)">763. Partition Labels (Medium)
- 122. Best Time to Buy and Sell Stock II (Easy)">122. Best Time to Buy and Sell Stock II (Easy)
- 406. Queue Reconstruction by Height (Medium)">406. Queue Reconstruction by Height (Medium)
- 665. Non-decreasing Array (Easy)">665. Non-decreasing Array (Easy)
贪心算法(Greedy Algorithm),又称贪婪算法,是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法。如出名的旅行商问题TSP,如果旅行员每次都选择最近的城市,则是一种贪心算法。
贪心算法在有最优子结构的问题中尤为有效。最优子结构的意思是局部最优解能决定全局最优解。简单地说,问题能够分解成子问题来解决,子问题的最优解能递推到最终问题的最优解。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
最小生成树的算法如Prim算法、Kruskal算法均为贪心算法,其中Prim算法是对图上的节点贪心,而Kruskal算法是对图上的边贪心。
1 分配问题
455 Assign Cookies (easy)
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
示例 1:
输入: g = [1,2,3], s = [1,1] 输出: 1 解释: 你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。 虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。 所以你应该输出1。
示例 2:
输入: g = [1,2], s = [1,2,3] 输出: 2 解释: 你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。 你拥有的饼干数量和尺寸都足以让所有孩子满足。 所以你应该输出2.
提示:
1 <= g.length <= 3 * 1040 <= s.length <= 3 * 1041 <= g[i], s[j] <= 231 - 1
题解:
/**解法1. 给饥饿度最小的孩子分配最小的饼干*/class Solution {public int findContentChildren(int[] g, int[] s) {// sort g and sArrays.sort(g);Arrays.sort(s);int count = 0;int cookie = 0;// compare min g[i] and min s[j], if match, then count ++while (count < g.length && cookie < s.length) {if (g[count] <= s[cookie]) ++count;++cookie;}return count;}}/**解法2. 给饥饿度最大的孩子分配最大的饼干*/class Solution {public int findContentChildren(int[] g, int[] s) {// sort g and sArrays.sort(g);Arrays.sort(s);int count = 0;int cookie = s.length - 1;// compare min g[i] and min s[j], if match, then count ++for (int i = g.length - 1; i >= 0; i --) {if (cookie >= 0 && g[i] <= s[cookie]) {++count;--cookie;}}return count;}}
两种方法在时空上有少许差别,但本质是一样的,并未确定为何leetcode的衡量数据有偏差。因为这里需要获取饥饿度及饼干大小的关系,因此先排序再处理起来会更方便。
135 Candy (easy)
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
你需要按照以下要求,帮助老师给这些孩子分发糖果:
- 每个孩子至少分配到 1 个糖果。
- 相邻的孩子中,评分高的孩子必须获得更多的糖果。
那么这样下来,老师至少需要准备多少颗糖果呢?
示例 1:
输入: [1,0,2] 输出: 5 解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。
示例 2:
输入: [1,2,2] 输出: 4 解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。 第三个孩子只得到 1 颗糖果,这已满足上述两个条件。
分析:
- 要求1: 每个孩子最少一个糖果,且已经有序(从左到右、从右到左)
- 要求2: 糖果数跟评分高低有关系,且跟相邻位置有关系
- 老师只想发出最少的糖果,因此只需要给相邻2个孩子评分高的多发一个即可
这里很容易想到对数组进行遍历,然后比较左右相邻的评分及糖果大小,分别处理,但时间复杂度分布为:空间 O( ), 时间O(n)。
), 时间O(n)。
题解:
class Solution {
public int candy(int[] ratings) {
int[] count = new int[ratings.length];
// 所有人默认给1颗
for (int i = 0; i < ratings.length; i ++) {
count[i] = 1;
}
for (int i = 1; i < ratings.length; i++) {
if (ratings[i] > ratings[i - 1]) {
count[i] = count[i - 1] + 1;
}
}
for (int j = ratings.length - 2; j >= 0; j--) {
if (ratings[j] > ratings[j + 1]) {
if (count[j] < count[j + 1] + 1) {
count[j] = count[j + 1] + 1;
}
}
}
int sum = 0;
for (int k = 0; k < count.length; k ++) {
sum += count[k];
}
return sum;
}
}
- 空间:O(n), 长度为n的数组4次遍历
- 时间:O(n),每个数组元素一次操作
另外,还有一种思路是:将规则分为从左到右、从右到左,2个数组,则针对i, 取左右的最大值即可同时满足左右规则,即满足条件。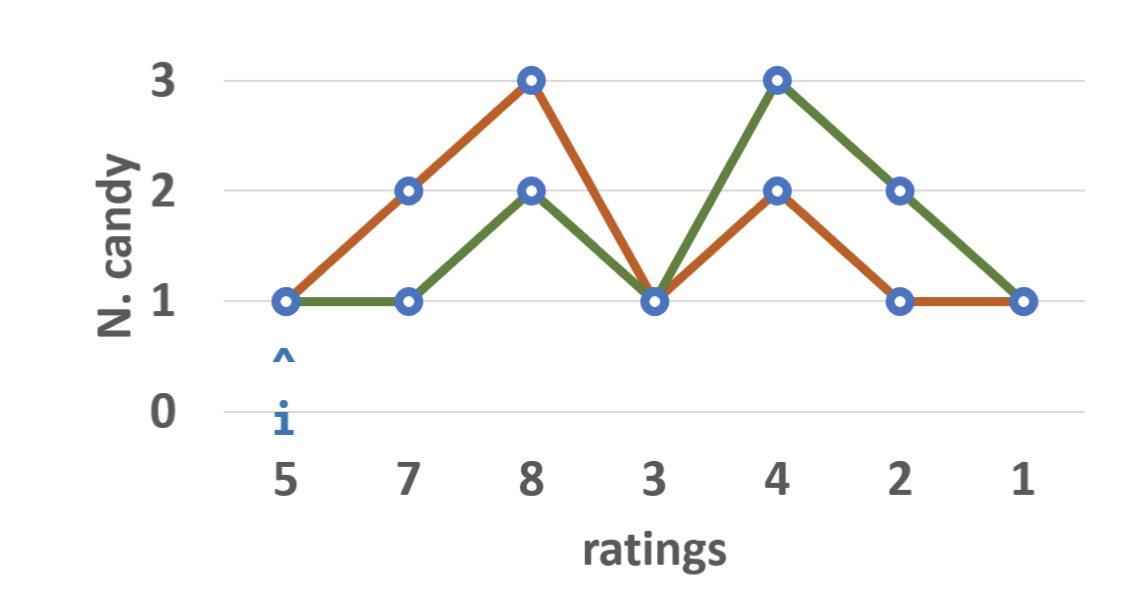
关于上面其实有一点绕的是,为什么取左右最大值即是最优解,如ratings[2],根据规则从左到右,count[2]为3,从右到左,count[2]为2,则取3一定同时满足左右条件,即比左右两边的糖果数更多,因此此时3即是ratings[i]的最优解。推荐题解:双数组题解
2 区间问题
435 Non-overlapping Intervals (Medium)
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
注意:
- 可以认为区间的终点总是大于它的起点。
- 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。
示例 1:
输入: [ [1,2], [2,3], [3,4], [1,3] ] 输出: 1 解释: 移除 [1,3] 后,剩下的区间没有重叠。
示例 2:
输入: [ [1,2], [1,2], [1,2] ] 输出: 2 解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。
示例 3:
输入: [ [1,2], [2,3] ] 输出: 0 解释: 你不需要移除任何区间,因为它们已经是无重叠的了。
题解:
贪心策略,先计算最多能组成的不重叠区间个数,然后用区间总个数减去不重叠区间的个数。
在每次选择中,选择的区间结尾越小,留给后面的区间的空间越大,那么后面能够选择的区间个数也就越大。
按区间的结尾进行升序排序,每次选择结尾最小,并且和前一个区间不重叠的区间。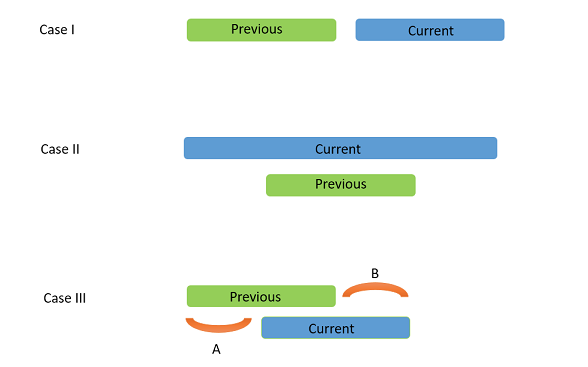
case 1:
当前考虑的两个区间不重叠: 在这种情况下,不移除任何区间,将 prev 赋值为后面的区间。
Case 2:
两个区间重叠,当前区间的终点在前一个区间的终点之后。 在这种情况下,如图所示,前一个区间是当前区间的真子集。因此,移除当前区间可以给别的区间更多的容纳空间。因此,保留前一个区间不变,更新当前区间。
Case 3:
两个区间重叠,当前区间的终点在前一个区间的终点之前。 在这种情况下,出现了唯一有可能移除前一个区间的机会,因为移除前一个区间可以带来 A 的额外空间。然而,类似于上图的 3a 和 3b,此时也不应该移除前一个区间。然而,移除当前区间却可以带来 B 的额外空间。因此,保留前一个区间不变,更新当前区间。
也可以从起点开始比较,判断终点是否重叠,思路相同。
class RangeEndSort implements Comparator<int[]> {
@Override
public int compare(int[] a, int[] b) {
return a[1] - b[1];
}
}
class Solution {
public int eraseOverlapIntervals(int[][] intervals) {
if (intervals.length == 0) {
return 0;
}
Arrays.sort(intervals, new RangeEndSort());
int prev = intervals[0][1];
int count = 0;
for (int i = 1; i < intervals.length; i ++) {
if (intervals[i][0] < prev) {
count ++;
} else {
prev = intervals[i][1];
}
}
return count;
}
}
另外,此题也可以通过动态规划的思路来解,具体实现将在第6节中补充。
392 Is-Subsequence
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
你可以认为 s 和 t 中仅包含英文小写字母。字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=100)。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,”ace”是”abcde”的一个子序列,而”aec”不是)。
示例 1:
s = “abc”, t = “ahbgdc” 返回 true.
示例 2:
s = “axc”, t = “ahbgdc” 返回 false.
后续挑战 :
如果有大量输入的 S,称作S1, S2, … , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
题解:
- t: 500,000长度
- s: <=100
贪心的思路就是对s和t做遍历,每次都匹配s[i]在t[j]中最近的,对于s中的每个字符都有序在t中出现,即可认为是t的子序列。复杂度:空间O(n),时间O( )。
)。
class Solution {
public boolean isSubsequence(String s, String t) {
int sLen = s.length();
int tLen = t.length();
if (sLen == 0) {
return true;
}
int i = 0;
int j = 0;
while(i < sLen && j < tLen) {
if (s.charAt(i) == t.charAt(j)) {
i ++;
j ++;
} else {
j ++;
}
}
return i == sLen;
}
}
上面办法对于挑战题则不可行,k >= 10亿,在复杂度上会有问题,思路暂未想明白,leetcode有相应的题解可以去学习下,题解是对t做变化,减少了匹配t中字符的操作次数,在一定程度上做了优化,但是k >= 10亿这个却没有办法。更新:我好像明白了那个题解的道理,不管s和t的长度是多少,本质是对于s[i], 如果s[i]在t中出现,则有可能是子序列,此时需要判断的是s[i]在t中出现的位置一定大于是s[i-1]在t中出现的位置,这样才能保证相对顺序。对t做结构上的处理,可以表示为26个小写字母,分别出现的位置集合,letter[26][pos]。如字符串abcdddffeea,处理后的结果为(注意:颜色深浅代表匹配顺序):
| a | b | c | d | e | f |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 8 | 6 |
| 10 | 4 | 9 | 7 | ||
| 5 |
将一个长字符转变为一个哈希桶的结构,然后利用二分法来匹配位置大小,比直接遍历长字符效率肯定好很多。
假设待判定字符串为: bda,用pos表示上一个匹配的位置;当遍历到d时,pos=1,我们需要在letter[d]中找到比1更大但离1最近的位置(3),更新pos=3;遍历到a时也做相同的处理。如果在匹配中未找到符合条件的位置则无法构成子序列。
再以字符串: ead为例,当匹配到d时,当前的pos为10,在letter[d]中,d没有比10更大的位置,因此无法构成子序列
| a | b | c | d | e | f |
|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 8 | 6 |
| 10 | 4 | 9 | 7 | ||
| 5 |
3 练习题
605. Can-Place-Flowers(Easy)
452. Minimum Number of Arrows to Burst Balloons (Medium)
763. Partition Labels (Medium)
122. Best Time to Buy and Sell Stock II (Easy)
406. Queue Reconstruction by Height (Medium)
665. Non-decreasing Array (Easy)

若有收获,就点个赞吧
0 人点赞
