数据集的概念
根据数据源联合构建一个全新的数据模型,简单说就是联合各个信息库,管理用户需要分析报表的数据
备注:数据集不做任何有关的原数据更改的操作,也不做具体分析的操作,只负责搭建数据模型
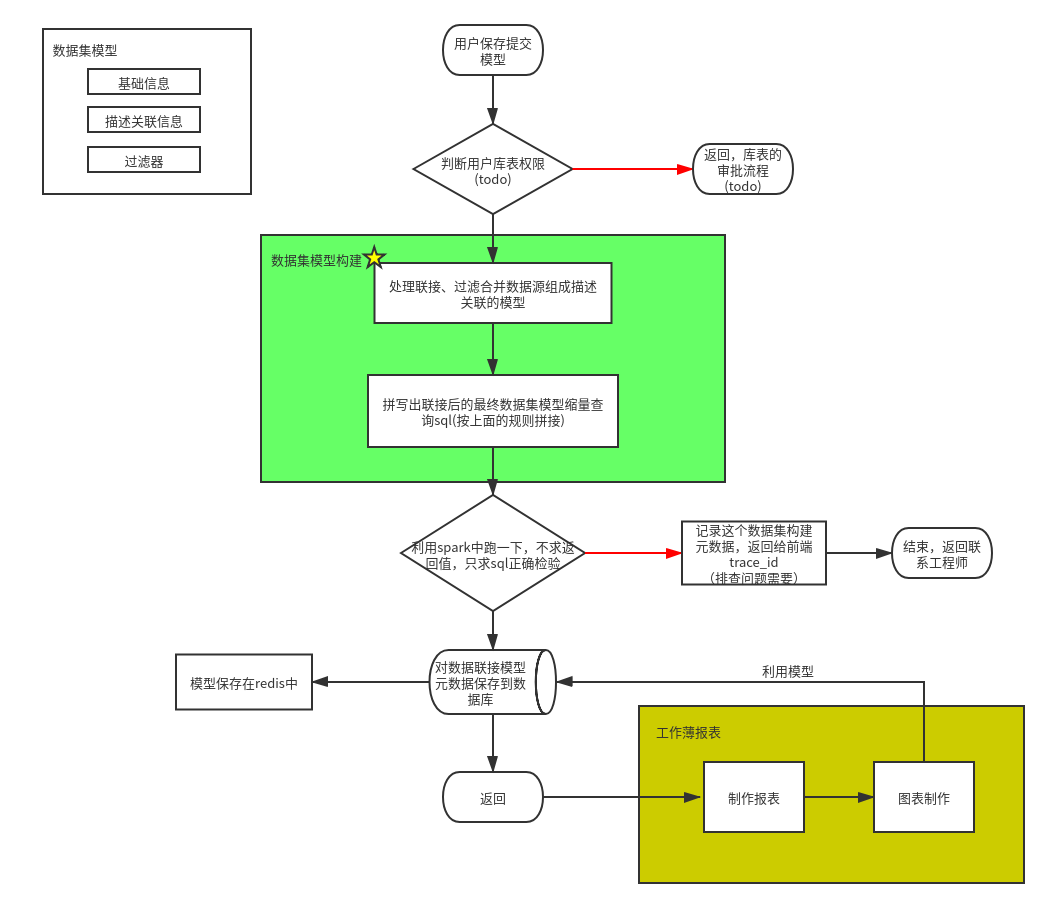
数据集用户操作流程
- 打开数据集界面,显示该用户的数据集信息
- 新建数据模型,显示用户所能看到所有的数据源的表数据
- 用户联接表之间的关系(主要是联接方式)、表达出想显示表的字段、[过滤掉用户想要数据信息+提供sql写法过滤,利用函数过滤]、模型基本信息设置,提交保存数据集模型,改用户为owner
- 权限(读写)分享,分享给其他需要以这个模型作为构建报表分析的同学,被分享的同学提供删除分享,可以改数据集模型,但不能直接删除整个数据集,权限在owner那里
- 设计图….
备注:后续可以有复制数据集、增加维度(计算字段,增加列),为数据模型扩充预留
技术实现
采用拼写sql方式构建数据集模型信息,用模型代表数据集联系关系,记录模型配置,用模型实现不同种类的功能区域,为了快速显示结果模型信息,有以下规定:
- 在显示各个数据源时,每个表显示10条数据
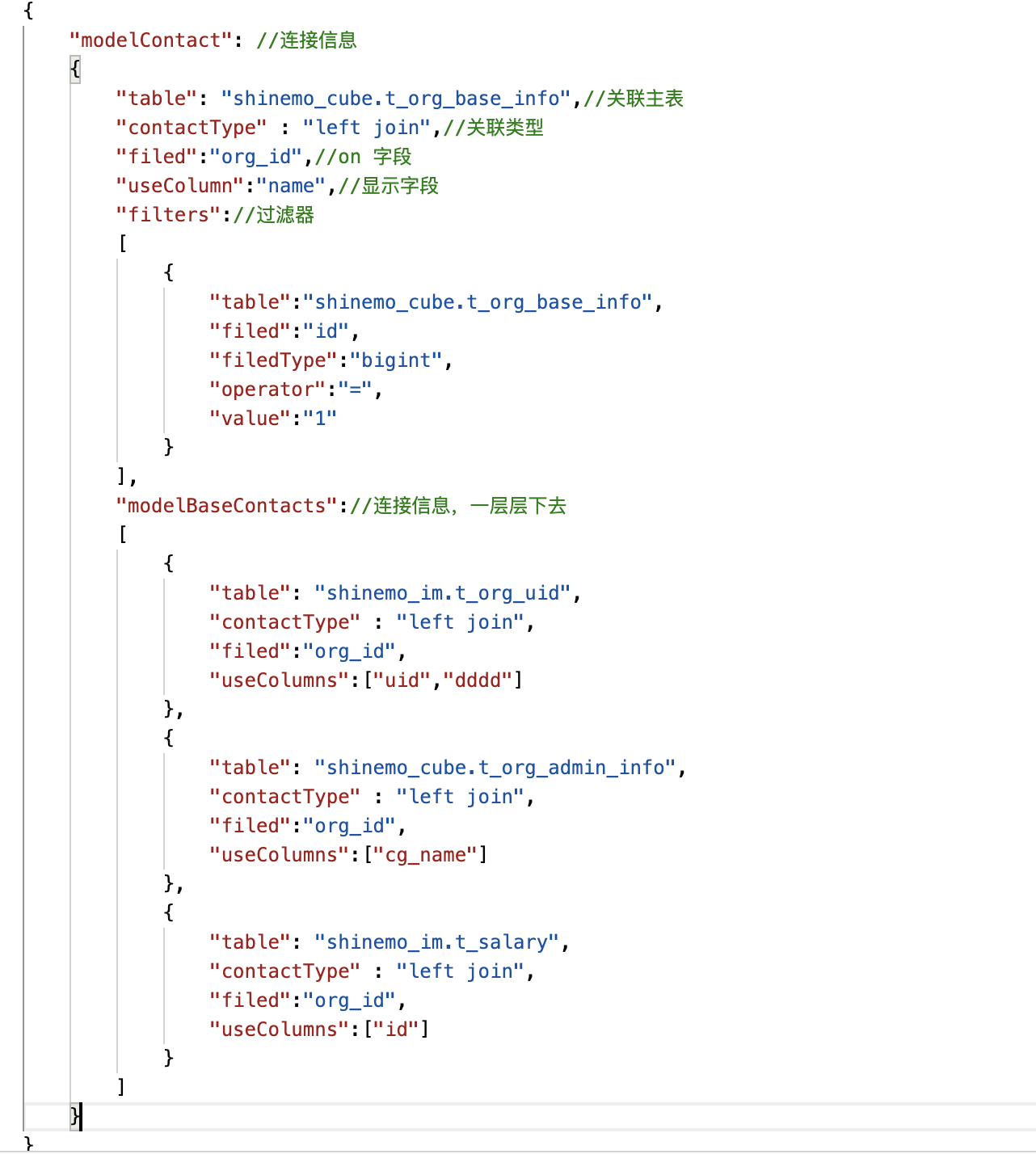
- 关联拼接信息对每个关联信息,主表控制的数据处理都截取limit 2000(在hive中查询响应速度ok的),表的别名表名去掉“.”,如:select shinemocubet_org_base_info.name
名称,shinemo_imt_org_uid.uid用户主键,shinemo_cubet_org_admin_info.cg_name `cg名称`,shinemo_imt_salary.id from (select * from shinemo_cube.t_org_base_info where city=’杭州’ limit 2000) shinemo_cubet_org_base_info left join shinemo_im.t_org_uid shinemo_imt_org_uid on shinemo_cubet_org_base_info.org_id = shinemo_imt_org_uid.org_id left join shinemo_cube.t_org_admin_info shinemo_cubet_org_admin_info on shinemo_cubet_org_base_info.org_id = shinemo_cubet_org_admin_info.org_id left join shinemo_im.t_salary shinemo_imt_salary on shinemo_cubet_org_base_info.org_id = shinemo_imt_salary.org_id - 过滤数据采用和后面报表实现一样的通用实现方式,对操作符(=,like,!=,<,>,between and…)和字段类型单独判断处理条件
表结构设计
t_data_set_info(数据集信息)
| 字段 | 类型 | 是否可为空 | 说明注释 |
|---|---|---|---|
| id | bigint | 否 | 主键 |
| gmt_create | varchar | 否 | 记录创建时间 |
| gmt_modified | varchar | 否 | 记录修改时间 |
| name | varchar | 否 | 数据集名称 |
| owner | varchar | 否 | 拥用者用户id |
| owner_name | varchar | 否 | 拥用者用户名称 |
| description | varchar | 是 | 描述这个数据集数据来源 |
t_data_set_share(数据集分享)
| 字段 | 类型 | 是否可为空 | 说明注释 |
|---|---|---|---|
| id | bigint | 否 | 主键 |
| gmt_create | varchar | 否 | 记录创建时间 |
| gmt_modified | varchar | 否 | 记录修改时间 |
| set_id | bigint | 否 | 数据集id |
| user_id | varchar | 否 | 用户id |
| user_name | varchar | 否 | 用户名称 |
| reason | varchar | 是 | 原因说明 |
| status | int | 否 | 标示:0—失效,1—修改权利,2—可读 |
t_data_set_contact(数据集关联模型记录表)
| 字段 | 类型 | 是否可为空 | 说明注释 |
|---|---|---|---|
| id | bigint | 否 | 主键 |
| gmt_create | varchar | 否 | 记录创建时间 |
| gmt_modified | varchar | 否 | 记录修改时间 |
| contact_id | bigint | 否 | 业务id |
| set_id | bigint | 否 | 数据集id |
| parent_id | bigint | 否 | 子id层级 |
| table_name | varchar | 否 | 表名称(库+表) |
| contact_type | varchar | 是 | 关联类型(left join、right join) |
| parent_field | varchar | 是 | 上级关联字段 |
| parent_field_type | varchar | 是 | 上级关联字段类型 |
| field | varchar | 是 | 关联字段 |
| field_type | varchar | 是 | 关联字段类型 |
| data_distinct | int | 否 | 是否要去重 |
| level_number | int | 是 | 层级数 |
t_useful_field(数据集-报表字段使用表)
| 字段 | 类型 | 是否可为空 | 说明注释 |
|---|---|---|---|
| id | bigint | 否 | 主键 |
| gmt_create | varchar | 否 | 记录创建时间 |
| gmt_modified | varchar | 否 | 记录修改时间 |
| resource_id | bigint | 否 | 资源来源id |
| type | varchar | 否 | 来源类型 |
| table_name | varchar | 否 | 表名称(库+表) |
| field | varchar | 否 | 使用有效字段 |
| field_type | varchar | 否 | 字段类型 |
| alias | varchar | 是 | 别名 |
t_data_filter(过滤器)
| 字段 | 类型 | 是否可为空 | 说明注释 |
|---|---|---|---|
| id | bigint | 否 | 主键 |
| gmt_create | varchar | 否 | 记录创建时间 |
| gmt_modified | varchar | 否 | 记录修改时间 |
| set_id | bigint | 否 | 数据集id |
| resoure_id | bigint | 否 | 要过滤的资源id |
| type | varchar | 否 | 类型(哪种资源) |
| table_name | varchar | 否 | 表名 |
| field | varchar | 否 | 字段 |
| field_type | varchar | 否 | 字段类型 |
| operator | varchar | 否 | 值操作符 |
| value | varchar | 否 | 值 |
| contact_operator | operator | 是 | 多字段过滤联接操作符,最后一个必为空 |
t_compute_field(计算字段信息)
| 字段 | 类型 | 是否可为空 | 说明注释 |
|---|---|---|---|
| id | bigint | 否 | 主键 |
| gmt_create | varchar | 否 | 记录创建时间 |
| gmt_modified | varchar | 否 | 记录修改时间 |
| set_id | varchar | 否 | 数据集id |
| column_info | varchar | 否 | 计算字段计算信息 |
| alias | varchar | 否 | 别名 |
接口文档
url:/das/dataSet/create
mothed:post
param:
| 参数名 | 类型 | 是否必填 | 说明 |
|---|---|---|---|
| id | number | 有就是add,没有就是update | 主键 |
| name | String | 必填 | 数据集名称 |
风险预估点
- 带这个子过滤条件时,主表数据控制在2000,可能会<2000,数据字段细分时会有偏差
- 修改数据集关联关系时,现在无法对某个关联表作出具体的修改,要后面改造,目前的做法是,先删除再重建
表与数据集的权限

若有收获,就点个赞吧
0 人点赞
