翻译自:https://docs.oracle.com/javase/tutorial/essential/io/streams.html
IO Streams
java.io包中包含了基本的IO操作类,基于流模型实现,大大简化了IO操作。
流模型:一个io流代表了输入源 或者 输出目标。一个流可以代表不同类型的源和目标,包括磁盘文件、设备,其他程序和内存数组。
流支持许多不同类型的数据,包括简单的字节,原始数据类型,本地化字符和对象。有些流只是传递数据,大部分流用以操纵和转换数据。
无论流内部是如何工作的,所有流都为使用它们的程序提供了相同的简单模型:流是一系列数据。程序用一个输入流从源读数据,one item at a time:
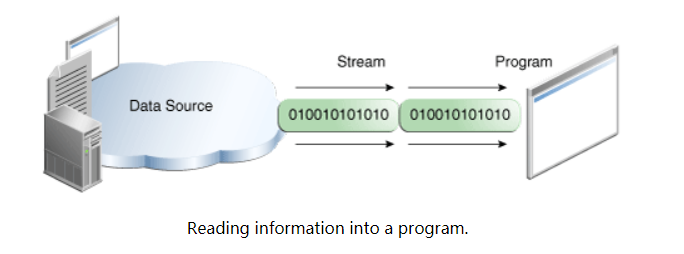
程序用一个输出流写数据到 destination,one item at a time:
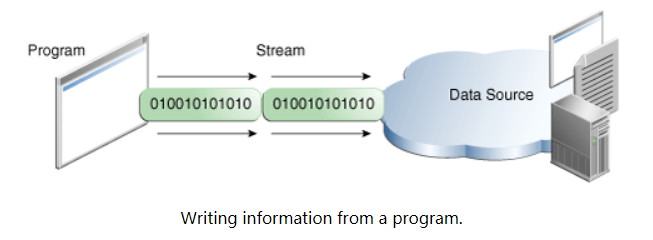
上面提到了Data Source 和 Destination可以是保存、生成或使用数据的任何事物。显然这包括磁盘文件,但源或目标也可以是另一个程序,外围设备,网络套接字或数组。
在下一部分,我们会使用最基本的流类型:字节流,来演示通用的I/O流操作。同时也会提供一个示例输入文件xanadu.txt,它的内容为:
In Xanadu did Kubla KhanA stately pleasure-dome decree:Where Alph, the sacred river, ranThrough caverns measureless to manDown to a sunless sea.
Byte Streams
程序使用字节流来执行字节的输入和输出,所有字节流类都继承自InputStream 和 OutputStream。
字节流类有很多。为了演示字节流的工作原理,我们将重点关注文件 I/O 字节流,FileInputStream 以及 FileOutputStream。其他种类的字节流的使用方式大致相同。它们的不同之处主要在于它们的构造方式。
使用字节流
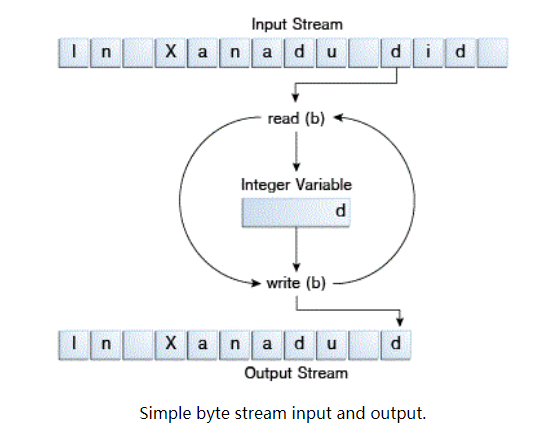
下面我们通过一个示例来学习FileInputStream 和 FileoutputStream,这个示例程序名为CopyBytes,用来读取文件xanadu.txt,one byte at a time.
import java.io.FileInputStream;import java.io.FileOutputStream;import java.io.IOException;public class CopyBytes {public static void main(String[] args) throws IOException {FileInputStream in = null;FileOutputStream out = null;try {in = new FileInputStream("xanadu.txt");out = new FileOutputStream("outagain.txt");int c;while ((c = in.read()) != -1) {out.write(c);}} finally {if (in != null) {in.close();}if (out != null) {out.close();}}}}
CopyBytes 大部分时间是在执行一个简单的循环:读输入流 和 写输出流,一次一个字节。如下图所示:
始终关闭流
当不再使用某个流时关闭它是非常重要的,CopyBytes使用finally块来保证即使发生错误也会关闭这两个流。这种做法可以有效避免资源泄露。
一个可能的错误是CopyBytes无法打开文件。发生这种情况时,对应于该文件的流变量永远不会从其初始值null更改。这就是CopyBytes在调用流的close方法之前确保每个流变量都不为null的原因。
何时不用字节流
CopyBytes 貌似是一个普通的程序,但是它仅仅代表了一种初级的I/O操作。由于xanadu.txt包含字符数据,所以最好的方法是使用字符流,它会在下一节中学习。还有用于更加复杂的数据类型的流。字节流仅用于最原始的I/O。
但是我们为什么要谈论字节流呢?因为其他所有的流类型都是基于字节流构建的。
Character Streams
Java平台使用Unicode约定存储字符值。字符流I/O自动将此内部格式转换为本地字符集。在西方,本地字符集通常是ASCII。
对于大多数应用程序,字符流I/O并不比字节流I/O复杂。使用流类完成的输入和输出会自动转换为本地字符集和从本地字符集转换。使用字符流代替字节流的程序会自动适应本地字符集,并且可以方便的进行国际化,不需要程序员做额外的努力。
假如国际化不是优先事项,你可以简单的用字符流类,而不必过多关注字符集问题。之后,如果国家化成为优先事项,您的程序可以进行调整而无需进行大量的重新编码。
使用字符流
所有的字符流类都继承自Reader 和 Writer。与字节流一样,有一些专门用于文件I/O的字符流类:FileReader 和 FileWriter。该CopyCharacters示例说明了这些类。
import java.io.FileReader;import java.io.FileWriter;import java.io.IOException;public class CopyCharacters {public static void main(String[] args) throws IOException {FileReader inputStream = null;FileWriter outputStream = null;try {inputStream = new FileReader("xanadu.txt");outputStream = new FileWriter("characteroutput.txt");int c;while ((c = inputStream.read()) != -1) {outputStream.write(c);}} finally {if (inputStream != null) {inputStream.close();}if (outputStream != null) {outputStream.close();}}}}
CopyCharacters 非常类似 CopyBates。最大的不同在于CopyCharacters 用 FileReader 和 FileWriter 来完成输入和输出操作,代替了 FileInputStream 和 FileOutputStream。请注意,CopyBytes 和 CopyCharacters 在完成读写操作的过程中都用到了int变量。但是,在CopyCharacters中,int变量在其最后16位中保存一个字符值;在CopyBytes中,int变量在其最后8位保存一个字符值。
使用字节流的字符流
字符流通常是字节流的包装器。字符流使用字节流来执行物理I/O,而字符流处理字符和字节之间的转换。例如,在使用FileReader时,它调用了FileInputStream;在使用FileWriter时,它调用了FileOutputStream。
有两个多功能的流类:InputStreamReader 和 OutputStreamWriter,可以作为字节流和字符流相互转换的桥。
面向行的I/O
字符I/O通常以比单个字符更大的单位出现。一个常见的单位是行:一串字符,末尾有一个行终止符。行终止符可以是回车/换行序列(“\r\n”),单个回车(“\r”),或者单个换行(“\n”)。支持所有可能的行终止符,允许程序读取在任何广泛使用的操作系统上创建的文本文件。
让我们修改CopyCharacters示例以使用面向行的I/O。要做到这一点,我们必须使用之前未见过的两个类:BufferedReader 和 PrintWriter。我们将在缓冲I/O和格式化中更深入地探索这些类。这里不做过多解释。
该CopyLine示例调用BufferedReader.readLine 和 PrintWriter.println一次输入和输出一行:
import java.io.FileReader;import java.io.FileWriter;import java.io.BufferedReader;import java.io.PrintWriter;import java.io.IOException;public class CopyLines {public static void main(String[] args) throws IOException {BufferedReader inputStream = null;PrintWriter outputStream = null;try {inputStream = new BufferedReader(new FileReader("xanadu.txt"));outputStream = new PrintWriter(new FileWriter("characteroutput.txt"));String l;while ((l = inputStream.readLine()) != null) {outputStream.println(l);}} finally {if (inputStream != null) {inputStream.close();}if (outputStream != null) {outputStream.close();}}}}
调用readLine返回文件中的一行。调用printLine输出每一行,并添加一个当前操作系统的行终止符。这可能与输入文本中使用的行终止符不同。
除了字符和行之外,还有很多方式可以构造文本的输入和输出。更多信息,请查看Scanning 和 Formatting。
Buffered Streams
到目前为止,我们看到的大部分示例都是使用无缓冲的I/O。这意味着每个读或写请求都由底层操作系统直接处理。这使得程序低效,因为每个这样的请求经常会触发磁盘访问、网络活动或一些相对昂贵的其他操作。
为了减少这种开销,Java平台实现了带缓冲的I/O流。缓冲输入流从称为缓冲区的存储区取数据;仅当缓冲区为空时才调用本机的输入API。类似的,缓冲输出流将数据写入缓冲区,并且仅在缓冲区已满时才调用本机的输出API。
程序可以使用我们现在多次使用的包装用法将无缓冲的流转换为缓冲流,其中无缓冲的流对象被传递给缓冲流类的构造函数。以下是你可以修改CopyCharacters示例中的构造函数调用以使用缓冲I/O的方法:
inputStream = new BufferedReader(new FileReader("xanadu.txt"));outputStream = new BufferedWriter(new FileWriter("characteroutput.txt"));
还有4个缓冲流类用于包装无缓冲流:BufferedInputStream 和 BufferedOutputStream 用于创建缓冲字节流,而BufferedReader 和 BufferedWriter 用于创建缓冲字符流。
刷新缓冲流
在关键点写出缓冲区通常是有意义的,而无需等待它填满。这称为刷新缓冲区。
一些缓冲的输入类支持autoflush,由可选的构造函数参数指定。启用autoflush时,某些键事件会导致缓冲刷新。例如,PrintWriter在每次调用println 和 format时自动刷新。
如果想要手动刷新,则需要调用它的flush方法。该flush方法在任何带缓冲的输出流上都有效。
扫描和格式化
编码 I/O 通常涉及到转义和格式化。为了帮助你完成这些杂务,Java平台提供了两个API:scanner 和 formatting。
截取输入标记
为了展示scanning是如何工作的,我们来看一下示例ScanXan,它可以读单个的单词并打印它,每个单词占一行:
import java.io.*;import java.util.Scanner;public class ScanXan {public static void main(String[] args) throws IOException {Scanner s = null;try {s = new Scanner(new BufferedReader(new FileReader("xanadu.txt")));while (s.hasNext()) {System.out.println(s.next());}} finally {if (s != null) {s.close();}}}}
注意,当完成扫描对象后,ScanXan 调用了 Scanner的close方法。尽管scanner 不是一个流,你也需要关闭它,表示你已经扫描完这个流了。输出的结果为:
InXanadudidKublaKhanAstatelypleasure-dome...
要使用其他标记分隔符,请调用useDelimiter(),指定正则表达式。假如你想要用逗号作为分隔符,后面的空格可选。你应该调用:s.useDelimiter(",\\s*");
独立转换标记
ScanXan示例将所有输入标记视为简单String值。Scanner还支持所有Java语言的基本类型(除了char)以及BigInteger 和 BigDecimal。另外,值类型用千位数分隔,因此,在US本地,Scanner 常常读一个字符串“32,767”作为一个整型数。
我们必须提到语言环境,因为千位分隔符和小数符号是特定于语言环境的。因此,如果我们没有指定扫描程序应该使用US语言环境,则以下示例将无法再所有语言环境中正常运行。这通常不用担心,因为你的输入数据通常来自使用相同语言环境的源。但这个例子是Java Tutorial的一部分,并且分布在全世界。
该ScanSum示例读取double值列表并将其相加,代码如下:
import java.io.FileReader;import java.io.BufferedReader;import java.io.IOException;import java.util.Scanner;import java.util.Locale;public class ScanSum {public static void main(String[] args) throws IOException {Scanner s = null;double sum = 0;try {s = new Scanner(new BufferedReader(new FileReader("usnumbers.txt")));s.useLocale(Locale.US);while (s.hasNext()) {if (s.hasNextDouble()) {sum += s.nextDouble();} else {s.next();}}} finally {s.close();}System.out.println(sum);}}
And here’s the sample input file,usnumbers.txt
8.532,7673.141591,000,000.1
输出的结果是”1032778.74159”. 在某些语言环境中,句点是不同的,因为System.out 是一个 PrintStream对象,并且该类没有提供覆盖默认语言环境的方法。这里我们可以使用formatting来完成,它会在下一节学习。
格式化
实现了格式化的类有PrintWriter(字符流类)和PrintStream(字节流类)。
PrintStream的唯一使用场景是System.out和System.err。当你需要创建格式化输出流时,请使用PrintWriter。
对于所有的字节流和字符流对象,简单的字节和字符输出,PrintStream和PrintWriter都实现了一个标准的write方法集。另外,PrintStream和PrintWriter用于相同的方法集将内部数据格式化输出。提供了两个级别的格式化:
- print 和 println 以标准的方式格式化单个值。
- format 可以格式化基于字符串的任意数据的值,具有许多拥有精确格式化的选项。
print 和 println
使用print 或 println 输出某个值的toString结果。代码如下:
public class Root {public static void main(String[] args) {int i = 2;double r = Math.sqrt(i);System.out.print("The square root of ");System.out.print(i);System.out.print(" is ");System.out.print(r);System.out.println(".");i = 5;r = Math.sqrt(i);System.out.println("The square root of " + i + " is " + r + ".");}}
输出结果为:
The square root of 2 is 1.4142135623730951.The square root of 5 is 2.23606797749979.
你可以使用这种方法格式化任何值,但是无法控制结果。
format方法
format方法可以格式化基于字符串的多个参数。
public class Root2 {public static void main(String[] args) {int i = 2;double r = Math.sqrt(i);System.out.format("The square root of %d is %f.%n", i, r);}}
输出结果为:The square root of 2 is 1.414214.
像示例中的三个一样,所有的格式符都以 % 开始,以1-2个字符结束,生成指定格式的输出类型。示例中的三个格式符用法为:
d将整数值格式化为十进制值。f将浮点值格式化为十进制值。n输出特定于平台的线路终结器。
以下是其它一些转换:
x将整数格式化为十六进制值。s将任何值格式化为字符串。tB将整数格式化为特定于语言环境的月份名称。
还有很多其它转换。
注意:
除了 %% 和 %n,所有格式符都必须匹配一个参数,否则会抛出异常。
在Java语言中, \n 表示换行符。除非特别的需求,否则应该一直使用跨平台的 %n 来代替 \n .
除了转换之外,格式符还可以包含一些附加元素,以进一步自定义格式化输出。
public class Format {public static void main(String[] args) {System.out.format("%f, %1$+020.10f %n", Math.PI);}}
结果是:3.141593, +00000003.1415926536
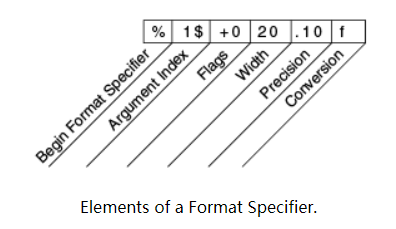
元素必须按照图示的顺序出现,从右侧开始,可选元素为:
Precision(精度):对于浮点值,这是格式化值的数学精度。对于字符串 和 其他常规的转换,这是格式化值的最大宽度。如有必要,这个值的右边会被截断。
Width:要格式化值的最大宽度。如有必要,该值会被扩展。默认情况下,左边会使用空白填充。
Flags:指定其他格式选项。在示例中,+ 标志指定该数字应始终使用符号格式化,0为填充字符。其他标志 包括 -(右填充)and ,(千位符)。请注意,某些标志不能与某些其他标志一起使用或与某些转换一起使用。
Argument Index:它允许你匹配指定的参数。你还可以指定 < 匹配与前一个说明符相同的参数。因此,这个例子还可以写成:System.out.format(“%f, %<+020.10f %n”, Math.PI);
Command Line I/O
程序通常从命令行运行,并在命令行中与用户交互。Java平台以两种方式支持这种交互:通过标准流和控制台。
标准流
标准流是许多操作系统的一个特性。默认情况下,它们从键盘读取输入并将输出写入显示器。它们还支持文件和程序之间的I/O,但是这个特性是由命令行解释器来控制的,不是程序。
Java平台支持三种标准流:标准输入,通过访问 System.in ; 标准输出,通过访问System.out; 标准错误,通过访问 System.err 。标准输出和标准错误都用于输出。不过,标准错误允许用户将输出转移到文件并且仍然能够读取错误消息。有关更多信息,请参阅命令行解释程序文档。
你可能希望标准流是字符流,但是,由于历史原因,它们都是字节流。System.out 和 System.err 都被定义为 PrintStream 对象。虽然它在定义上是一个字节流,但PrintStream利用了内部的一个字符流对象来模拟了许多字符流的特性。
相比之下,System.in 是一个没有字符流功能的字节流。为了使标准输入作为一个字符流,我们可以使用InputStreamReader来包裹System.in.
InputStreamReader cin = new InputStreamReader(System.in);
控制台
控制台是标准流的一个更高级替代方案。这是一个预定义的单例对象,Console具有标准流提供的大部分功能,以及其他功能。控制台对于安全密码输入特别有用。控制台也提供了真实的输入流和输出流,是通过reader 和 writer方法来实现的。
在程序使用Console之前,必须调用System.console来尝试获取Console对象。假如Console对象可用,这个方法会返回它。假如返回 NULL,则不允许控制台操作,因为操作系统不支持它们,或者因为程序是在非交互式环境中启动的。
控制台对象支持通过其readPassword方法保证密码输入的安全。这个方法用两种方式来保证密码的输入安全。首先,它抑制回显,因此密码在用户屏幕上不可见。其次,readPassword返回一个字符数组,不是一个字符串。所以密码可以被覆盖,一旦不再需要就将其从内存中删除。
Data Streams
数据流支持基本数据类型(boolean、char、byte、short、int、long、float和double)和字符串的二进制I/O 。
所有数据流都实现了DataInput 或 DataOutput。这里我们只谈论最广泛使用的两个实现类:DataInputStream 和 DataOutputStream 。
该示例通过写出一组数据记录,然后再次读取它们来展示数据流。数据如下表所示:
| 订单记录 | 数据类型 | 数据描述 | 输出方法 | 输入法 | 样本价值 |
|---|---|---|---|---|---|
| 1 | double | 商品价格 | DataOutputStream.writeDouble | DataInputStream.readDouble | 19.99 |
| 2 | int | 单位数 | DataOutputStream.writeInt | DataInputStream.readInt | 12 |
| 3 | String | 商品描述 | DataOutputStream.writeUTF | DataInputStream.readUTF | “Java T-Shirt” |
让我们来看看关键代码吧,首先,程序定义了一些常量,包含数据文件名称和将写入的数据。
static final String dataFile = "invoicedata";static final double[] prices = { 19.99, 9.99, 15.99, 3.99, 4.99 };static final int[] units = { 12, 8, 13, 29, 50 };static final String[] descs = {"Java T-shirt","Java Mug","Duke Juggling Dolls","Java Pin","Java Key Chain"};
数据流打开一个输出流,由于 DataOutputStream 只能作为现有字节流的包装器来创建,因此DataStream提供了一个缓冲文字节流。
out = new DataOutputStream(new BufferedOutputStream(new FileOutputStream(dataFile)));
数据流 写出记录并且关闭输出流。
for (int i = 0; i < prices.length; i ++) {out.writeDouble(prices[i]);out.writeInt(units[i]);out.writeUTF(descs[i]);}
writeUTF方法将String以UTF-8的格式输出。
现在数据流再次读回数据。首先,它必须提供一个输入流 和 一个用来保存输入值的变量。与DataOutputStream类似,DataInputStream 必须构造为字节流的包装器。
in = new DataInputStream(newBufferedInputStream(new FileInputStream(dataFile)));double price;int unit;String desc;double total = 0.0;
现在数据流可以读取流中的每条数据,并打印读到的数据。
try {while (true) {price = in.readDouble();unit = in.readInt();desc = in.readUTF();System.out.format("You ordered %d" + " units of %s at $%.2f%n",unit, desc, price);total += unit * price;}} catch (EOFException e) {}
请注意,数据流 通过捕获EOFException而不是测试无效的返回值来检测文件的结束条件。DataInput方法的所有实现都使用EOFException而不是返回值。
数据流中,每一个write 和read 是相匹配的。程序员必须保证输出类型和输入类型以这种方式匹配:输入流由简单的二进制数据组成,没有任何内容可以指示单个值的类型。也不是它们在流中开始的位置。
数据流使用一种非常糟糕的编程技术:它使用浮点数来表示货币值。通常,浮点对于精确值是不利的。
用于货币值的正确类型是java.math.BigDecimal。不幸的是,BigDecimal是一种对象类型,因此它不适用与数据流。
但是,BigDecimal可以使用对象流。这将在下一节介绍。
Object Streams
正如数据流支持基本数据类型I/O一样,对象流也支持对象的I/O。大部分,但不是所有,支持实现了Serializable的标准类对象。
对象流类是ObjectInputStream 和 ObjectOutputStream。它们实现了ObjectInput 和 ObjectOutput。而ObjectInput和ObjectOutput是DataInput和DataOutput的子类。这意味着所有的数据流方法,也在对象流中可用。所有,对象流可以包含原始值和对象值的混合。价格可以是BigDecimal对象,发票日期可以是Calendar。
假如 readObject() 没有返回预期的对象类型,强制将其转换为指定的类型可能会抛出一个ClassNotFoundException。
复杂对象的输出和输入
writeObject 和 readObject 方法使用起来非常简单,但是它们包含了非常复杂的对象管理逻辑。这对像Calendar这样的类来说并不重要,它只封装了原始值。但是一些对象包含了其他对象的引用。
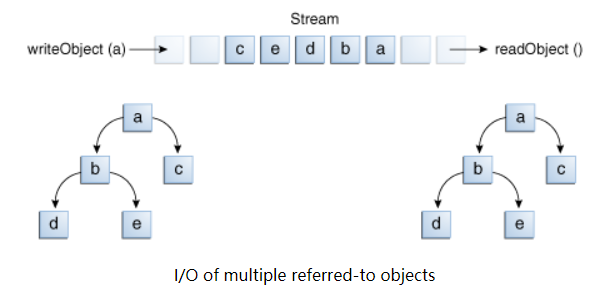
如上图所示,展示了复杂对象的输入和输出过程。

若有收获,就点个赞吧
0 人点赞
