JAVA概述
1.正则表达式的用途?
答:在处理字符串的时候,通常会匹配复合某些规则的字符串,而正则表达式就是用来编写这个规则。比如查找邮箱,就编写邮箱所遵守的规则。
2.JRE、JDK、JVM的关系?
答:JVM是java虚拟机,java运行在JVM中。
JRE是java运行环境,包含了JVM和一些核心类库。
JDK是java的开发工具包,包含JRE和一些开发工具,比如编译器和java运行工具。
3.你知道哪些JDK里面的工具?
答:
4.什么是跨平台性?原理是什么?
答:因为java是在java虚拟机里面运行的,所以不同的平台只要安装了java虚拟机就可以实现跨平台运行。
5.什么是字节码?使用字节码的好处?
答:字节码是java程序经过编译的到的文件,后缀为.class
字节码文件解决了解释性语言效率低的问题,还保留了解释性语言的可移植性,因为字节码文件只用面向java虚拟机,然后虚拟机内部再讲字节码解释为机器可执行的二进制文件。所以到了不同平台不用重新编译。
6.java和c++的区别?
答:1)都是面向对象的语言。
2)c++用到指针,可以直接访问内存,而java不行。
3)java单继承,而c++多继承。
4)java都自动内存管理。c++的内存需要程序员手动释放。
7.什么是OOP?
答:一个项目是由很多类组成,需要分析类中有哪些属性,哪些方法,类与类之间都是什么关系,这些类的实现是对象形式存在的。用对象来构建出这些项目。
8.六大设计原则有哪些?
答:
单一职责原则(S):让类的职责更单一,让各个类各司其职。
开闭原则(O):一个模块应该对扩展开放,对修改关闭。
里式替换原则(L):这个原则的意思是在一个父类对象替换成它的子类对象之后,程序能够正常运行。
迪米特原则(L):这个原则的意思大致是一个类对其他类应该尽少的对外提供接口。
接口隔离原则(I):这个原则表示一个接口的功能要尽量的少,能拆开尽量拆开。
依赖倒置原则(D):这个原则就是上层模块应该是抽象的,下层模块实现具体细节,就像面向接口编程。
9.知道JIT吗?
答:
10.你知道jdk有哪些工具可以使用?
答:
**
基础语法
数据类型
1.java的数据类型有哪些?
答:总体可以分为两类:分别是基本数据类型和引用类型,基本数据类型有数值型byte,int,float等,字符型char,布尔型boolean。引用类型有类,接口,数组等。
2.swith能否作用到byte上,long上,String上?
答:在jdk1.7后swtich可以作用在String上,但是还不能作用在long上。
3.以左右效率的方法计算2*8?
答:8是2的三次方,所以左移三位相当于计算了28。这涉及到机器上的寄存器,有一个移位寄存机,所以操作很快,如果直接相乘的话用法程序相关的寄存器,比较复杂。
4.Math.round(11.5)等于多少?Math.round(-11.5)呢?
答:java的四舍五入算法是数值+0.5后向下取整。所以前者为12,后者为-11。
5.float f = 3.5是否正确?
答:不正确,在java里面由小数点的数默认为double类型的,float的取值范围更小,用double类型的直接转为float会报错,。这里应该在数字后面应该加个F或者进行强制类型转换。
6.short s1 = 1; s1 = s1 + 1 对吗?short s1 = 1; s1 += 1;对吗?
答:前者不对,因为1为整型,所以s1+1也是整型,直接赋给short类型会编译报错。
后者对,因为+= 这句话里面已经隐藏了强制类型转换。
7.Integer和int的区别?
答:Integer是int的包装类,Integer变量是对一个Integer对象的引用,而int变量则是直接存储的变量。
Integer与int比较的时候会自动拆箱,所以比较的是数值。Integer i = 1;这种非new出来的对象是常量池中的对象,两个非new出来的Integer对象若范围在-128-127之间则比较的话相等,否则不相等,因为Integer i = 100 会翻译成 Integer i = Integer.valueOf(100);这个方法中对于-128-127之间的值会缓存,下次再用到这个值会直接从缓存中拿。
*8、int类型能转为byte类型吗?byte的取值范围是多少?
答:不能,需要强制类型转换,并且会丢弃高24位。byte是有符号的,范围是-128-127
访问修饰符
1.public,protected,private和默认的权限修饰符的区别?
答:权限修饰符是用来对变量,方法等进行访问保护的一种方式。
private修饰的变量方法只能在本类中访问。
default的变量和方法只能在本类中和同一包中的类访问。
protected修饰的变量方法只能本类,子类和同一包中的类访问。
public修饰的变量方法对所有类放开访问。
2.可以通过反射获得私有变量那为什么设置为私有的呢?
答:private不是用来解决安全问题的,反射破坏类的访问规则会带来安全隐患。
运算符
1.&和&&的区别?
答:一个是按位与,一个是逻辑与。前者对于整型数字的二进制形式按每位进行与,1&1等于1,其他情况都为0。
后者是逻辑与,要求符号两边的逻辑表达式都位真即为真。
关键字
1.final有什么用?
答:final关键字用来修饰类,变量和方法。
被final修饰的类不能被继承。
被final修饰的变量的引用不能变。
被final修饰的方法不能重写。
2.finally和finalize的区别?
答:fianlly一般作用于trycathch块中,不管try块中是否有异常发生,都会执行finally块里面的内容,一般用存放来关闭资源的代码。
finalize是Object类的一个方法,由垃圾回收器来执行来回收垃圾。
3.this关键字的作用?
答:this代表类自身的一个对象。
在如果成员变量与方法的形参名相同,可以用this来进行区分。
也可以通过this关键字调用构造函数。
4.super关键字的作用?
答:super是指示调用父类变量方法的关键字。
作用于this关键字类似。
5.this和super的区别?
答:this是代表类自身的对象,而super是用来指示父类变量方法构造函数的一个关键字。
当用来作为构造函数的时候,this和super在其他构造函数中都必须是第一行。
6.static的主要作用?
答:1.被static修饰的变量或者方法会优先于对象的存在,会在内存共享区开辟一块内存用于存放变量,所有对象共享被static修饰的变量或方法。
2.static还可以用在类中的静态代码块,当类第一次被加载的时候就会访问静态代码块的内容,并且只会访问一次,可以存放一些初始化的一些代码提升效率。
7.transient关键字的作用?
答:与序列化有关,在已经序列化的类中,用transient修饰的变量不能被序列化。
流程控制语句
1.break,continue和return的区别?
答:break结束当前循环;
continue跳过本次循环。
return结束当前方法。
2.如何跳出多重循环。
答:可以在循环体外面定义一个标号,在循环体内用带有标号的break语句结束循环。
但这样不太好,这样使得程序的逻辑结构混乱,对于一个双层循环我一般用一个标志状态,当在内层循环满足条件,将标志状态设为true,然后在外层循环也加上判断该标志状态的语句,符合条件就break跳出外层循环。**
面向对象
面向对象概述
1.面向对象和面向过程的区别?
答:面向过程分析出解决问题的步骤,更关注的是解决这个问题的步骤过程。
而面向对象是对现实世界的抽象提取,把一个事务分解成多个对象,关注的是解决这个问题需要哪些对象。
面向对象底层还是面向过程,把过程抽象成类,进行封装。
面向对象三大特性
1.什么是封装?
答:隐藏类的变量和实现细节,仅对外提供访问方法。封装好处就是减少了耦合性,提高了代码复用性和安全性。
2.什么是继承?
答:继承是基于已经存在的类新建类,新的类可以复用被继承的类的非private修饰的变量和方法,也可以扩展新的功能。增加了代码的复用性。
3.什么是多态?
答:父类引用指向子类对象。可以通过继承类和实现接口实现。
4.编译时多态和运行时多态?
答:重载编译时多态,重写是运行时多态,编译时多态会在编译时期检查方法的参数类型,个数是否匹配,根据不同参数类型个数会调用方法。重写会在运行时期从底向上查找调用的方法。
5.多态遵守的机制?
答:被引用对象的类型决定了对象调用的是什么方法,但这个方法必须是被子类覆盖的父类的方法。
6.创建对象的过程?
答:父类静态成员变量初始化,子类静态成员变量初始化->执行父类和子类的静态代码块->为父类的普通成员变量分配空间并完成赋值->调用父类的构造方法->为子类的普通成员变量分配空间并完成赋值->调用子类的构造方法
7.深拷贝和浅拷贝的区别,怎么实现?
答:浅拷贝:对对象的基本数据类型进行值传递,对引用变量会传递一个地址,也就是说克隆前后的引用类型成员变量仍然指向的是同一个对象。实现方法:可以通过对象类的构造方法创建一个对象,然后把被克隆对象的值赋给新对象。
深拷贝:不仅会将基本数据类型进行值传递,还会为引用类型变量开辟内存,并复制引用类型变量指向的变量,会一直这样深度复制下去,把所有引用变量复制完。实现方法:将对象序列化,默认会将对象的整个对象图进行序列化,再通过反序列化完成深拷贝。
8.为什么java是单继承?
答:
类与接口
1.抽象类和接口的区别?
答:1)抽象类必须有构造函数,而接口没有构造函数。
2)抽象类可以有普通的成员变量,而接口的成员变量都是用public static final修饰的。
3)抽象类可以有普通的方法,而接口都是抽象方法。
4)抽象类主要是事务的共同特征进行提取,减少代码的复用性。而接口主要用来对类进行规范。
5)一个类最多继承一个抽象类,而可以实现多个接口。
2.普通类和抽象类的区别?
答:普通类不能有抽象方法,抽象类不能实例化。
3.抽象类必能实例化为什么还要有构造函数?
答:可以用来初始化抽象类的普通成员变量;还有原因是抽象类的子类一定有构造方法,而子类的构造函数一定要调用父类的构造函数。
4.JDK1.8中接口可以实现方法吗?
答:用default修饰方法,可以有默认实现,并且不必强制重写。实现类的实例对象可以调用该方法。
5.项目中什么情况用抽象类,什么时候用接口?
答:某个事物的基本特征可以定义为抽象类,比如一个动物都有眼睛,鼻子嘴巴。而一些动物的特有行为呢,可以定义为接口,比如鱼会游泳,兔子会跳。
6.静态类和普通类的区别?静态类可以实例化对象吗?
答:类被声明为static只有一种情况,那就是内部类。
静态内部类跟静态方法一样只能访问外部类的静态变量和静态方法。
静态内部类可以声明普通的成员变量,而普通成员变量不能声明static成员变量和方法。
静态内部类可以实例化对象。
7.枚举类和类的区别?
答:枚举是一种特殊的类,用来存储一组的常量。
枚举类默认继承的是Enum类,而普通类继承的是Object类
枚举类不能实例化。
8.Object类有哪些方法,都说一下有什么用?
答:hashcode、equals、toString、notify、wait、clone、finalize
变量与方法
1.成员变量和局部变量的区别?
答:位置上:成员变量在类中,方法体外;局部变量在方法或者语句体内。
内存上:成员变量随着对象的创建而创建,存放在堆内存中;局部变量存放在栈区中。
作用域:成员变量作用域整个类中;局部变量作用与代码块中,如方法中,循环体中。
2.一个类的构造方法有什么用?无参的构造方法有什么用?
答:主要完成类对象的初始化工作。
在子类的构造函数中,如果没有用super方法调用父类的构造方法,就会默认调用无参数的父类的构造函数,但是如果父类只定义了有参的构造函数,那么就会报错,所以系统会自动生成无参数的构造函数。
3.为什么静态方法访问非静态变量是非法的?
答:因为静态方法的调用无需通过对象调用,当通过类名调用静态方法的时候,对象还没创建,成员变量都还没初始化。
内部类
1.匿名内部类的特性?
答:1)匿名内部类的必须继承一个抽象类或者实现接口。
2)匿名内部类的不能定义任何静态变量和静态方法。
3)定义在方法内的匿名内部类如果调用了方法中的变量,这个被调用的变量必须用final来进行修饰。因为不修饰的话方法执行完局部变量就销毁了,而这个对象还在引用中,就会出错。
重写和重载
1.重写和重载是什么?
答:重载:同一个类中,不同方法有不同的参数类型,参数个数,与返回值和权限修饰符无关。
重写:子类方法对父类方法的覆盖。需要相同的方法名参数列表,权限修饰符要大于父类,返回值要小于父类,抛出的异常也要小于父类。
2.子类可以重写父类的静态方法吗?
答:
3.静态方法可以重载吗?
答:
对象相等判断
1.==和equal的区别?
答:==比较两个对象是否是同一个对象,比较的是两个对象的地址。如果是基本数据类型则比较的是值。
equal在未重写的情况下跟==的作用相同,如果重写了就按重写的规则来比较。
2.为什么是hashcode?为什么重写equals方法要重写hashcode?
答:hashcode是根据对象地址转换来的一种散列码。如果两个对象equals是相等的,但是hashcode不同的话,就会在hashset或者hashmap中进行存储。
3.hashset的原理?
答:hashcode相等,equals不一定相等;equals相等,hashcode一定相等。首选根据hashcode与数组长度的关系来确定对象存放的索引位置,如果该位置没有元素就直接存储,如果有元素,就用equals方法来判断,如果为false就存储,否则就不存储。
按值调用
1.值传递和引用传递的区别?
答:值传递:在方法调用的时候,变量参数传递的是变量的值,是变量值的拷贝。
引用传递:在方法调用的时候,变量传递的时候传递的是变量的内存地址, 传递前和传递后变量指向同一块引用。
异常
1.异常的体系结构?
答:Throwable分为Error和EXCEPTION,Error是程序无法处理的,一般跟虚拟机有关。
exception又分为编译时异常和运行时异常,编译时异常是程序必须要捕获的异常,比如IO异常;
运行时异常一般是程序逻辑错误造成的,可以通过编译,比如空指针异常。
2.thow和throws的区别?
答:throw和throws所处位置不同,后者放在方法参数列表后面,用于声明方法中不能处理的各种类,而throw用与抛出具体的某个类。
3.**OOM会让虚拟机停止工作吗?**
答:
反射
1.什么是反射?
答:反射就是运行时动态获取类的信息,属性和方法。
2.获取类的对象?
答:对象.getClass() ; Class.forName(); ClassLoader.loadClass()。
3.Class.forName和ClassLoader.loadClass的区别?
答:1)Class.forName会对对象初始化,会对类中的静态成员进行初始化工作,也会执行类中的静态代码块;ClassLoader.loadClass则只是连接到对象而没有进行初始化。
2)类加载器不同,Class.forName的类加载器是用当前类的类加载器来进行装载。而ClassLoader则需要指定类加载器。
4.反射的应用场景
答:可以获取对象的私有成员变量值。
框架中使用较多,比如spring中配置文件中bean中信息根据类信息创建对象。
注解
1.注解的原理?
答:一个注解的本质是一个类,这个是实现了Annotation接口;
2.注解有什么用?
答:
3.注解的分类?
答:
- 元注解
- @Target:注解的作用目标(用来修饰类还是方法的)。@Retention:注解的生命周期(保留在编译时期还是永久保留等);@Documented:注解是否应该被包含在JavaDoc文档中;@Inherited:是否允许子类继承该注解。
- 自定义注解
I/O流
1.Java中有哪些IO流?
答:按数据的流向可以分为输入流和输出流。
按传输的数据类型可以分为字节流和字符流。
按是否可以直接向某个设备直连可以分为节点流和处理流。
2.节点流和处理流的区别?
答:节点流是看是否与某个地方直连,比如磁盘,内存。有FileInputStream等
处理流则是已经存在的流的连接和封装,一个流对象经过其他流的对此包装,称为流的连接。处理流的构造方法总有一个带有其他的流的对象作为参数。
3.BIO和NIO和AIO的区别?
答:BIO(Block I/O)是同步阻塞模式:服务器会为每一个客户端请求开创一个线程,如果如果该线程什么也不做,就会导致线程不必要开销。适用于连接数比较小的框架。
NIO是(New I/O) 同步非阻塞模式:实现一个线程处理客户端的多个请求,客户端发送的请求会被注册到多路复用器上,多路复用器对请求轮番查询到有I/O请求就进行处理。减少了线程切换的开销。
AIO(Asynchronous I/O):有效的请求才启动线程,特点是先由操作系统完成后才通知服务端启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
1)BIO是以流的方式处理数据,而NIO以块的方式处理数据。
2)BIO是阻塞的,NIO是非阻塞的。
3)BIO字节流或者字符流进行操作,而NIO基于Channel和Buffer进行操作,数据总是从通道读取到缓冲区中,或者从缓冲区写入到通道中,selector用于监听通道时间(连接请求,数据到达)。
4.同步和异步和阻塞和非阻塞的区别?
答:同步和异步是执行者的执行方式,同步表示执行者主动去查询,异步表示被动等待消息通知。
阻塞和非阻塞是执行者的状态,阻塞表示执行者等待,非阻塞表示执行者不等待去做其他事。反射
1.什么是反射技术?
答:在程序运行状态中,动态的获取对象的属性或者方法的技术。对于任意一个对象,都可以获取他的属性和方法。
2.什么是静态编译和动态编译?
答:静态编译:在编译时期就对类进行了编译。
动态编译:在运行时期才编译对象。例子:如果一个阅读器需要支持有mp3和txt和mp4,如果只看txt,启动程序会同时加载这三个功能,造成资源的浪费。动态编译就只加载txt功能。
3.反射的底层原理?
答:常用API
String
1.字符常量和字符串常量的区别?
答:1)字符常量是单引号括起来的一个字符,字符串常量是双引号括起来的若干个字符。
2)字符常量是一个整型值,asc-II码,可以参与表达式运算,而字符串常量是一个地址,是存放该字符串的地址。
2.什么是字符串常量池?
答:字符串常量池是在堆内存中开辟的内存专门用来存放字符串常量,为了避免多块空间存储同样的字符串,提高内存的使用率。在创建字符串的时候,会首先检查字符串常量池中是否存在字符串,如果存在就直接返回引用,如果不存在就在字符串中创建并返回引用。
3.String有哪些特性?
答:1)不变性:String是只读字符串,对String的任何操作都是创建新的字符串。
2)常量池优化:新建字符串变量的时候会优先检查常量池是否存在该字符串,如果有,会直接返回。
3)final:String类是被final修饰的,不能被继承,提高了安全性。
4.为什么String类是不可变的?
答:因为String类底层维护的数组使用final修饰的。为什么要设置不可变:提高效率,a=”abc”,b=”abc”,这样就不会复制字符串“abc”,而是多个引用指向那个常量池中的“abc”字符串;String不可变量那么它的hashcode就不会改变,不用每次计算。安全性,如果一个字符串路径被多个引用指向,一个引用改变了其路径会造成安全问题。
5.String s = new String(“xyz”);创建了几个字符串对象?
答:如果字符串常量池中不存在xyz这一个字符串,就先在字符串常量池中创建,new String()这句话会在堆内存中创建一个字符串对象。
6.String和StringBuilder和StringBuffer的区别?
答:StringBuilder和StringBuffer都是继承了抽象类AbstactStringBuilder,在这个抽象类中底层维护的数组是可变的。StringBuffer对方法都加了同步锁,是线程安全的,而StringBuilder是线程不安全的,StringBuffer的效率不如StringBuilder
7.连接字符串的+的实现原理是怎么样的?
答:底层维护了一个StringBuilder容器,用StringBuilder的append方法来实现。Resultful接口
1.什么是resultful接口?
答:Stream流水线
1.什么是流水线?
答:集合
1.Comparable接口和Comparator接口的区别?
答:可以用Comparable接口和Comparator接口来实现方法的自定义排序。
一个类实现了Comparable接口,说明该类支持排序,它的方法compareTo(Object o)用来定义排序规则,返回负数,0,正数表示this对象小于,等于和大于传入对象。
而实现Comparator接口的对象是一个比较器对象,一个不支持排序的类可以传入该对象进行排序,它的方法compare(Object o1, Object o2)返回负数,0,正数表示第一个参数对象小于等于大于第二个参数对象。通过定义比较器对象实现更多的比较规则。
2.为什么集合内要使用迭代器?
答:如果用for循环来遍历集合的话需要知道集合数据结构和类型,(比如说遍历数组和遍历链表的写法是不一样的),当换了一个集合进行遍历又是另外一种写法,用遍历器的优点:1.可以在不了解集合内部数据结构的情况下进行遍历,对所有集合遍历都采用一种遍历逻辑。
3.Hashmap和hashtable的区别?
答:1)hashtable的方法是同步的,hashmap的方法是非同步的
2)hashtable的key-value不能存储null值,而hashmap可以存储
4.hashmap的key和value都是用什么存储结构存储的?
答:hashmap存储一个单元是键值对的方式存在的,叫做Node,hashmap底层根据键值的hash值来决定存放在数组的某个位置,如果该数组位置有存储值,就用链表的方式存储在后面,如果链表长度大于8就转换为红黑树结构。
4.集合的继承图?
答: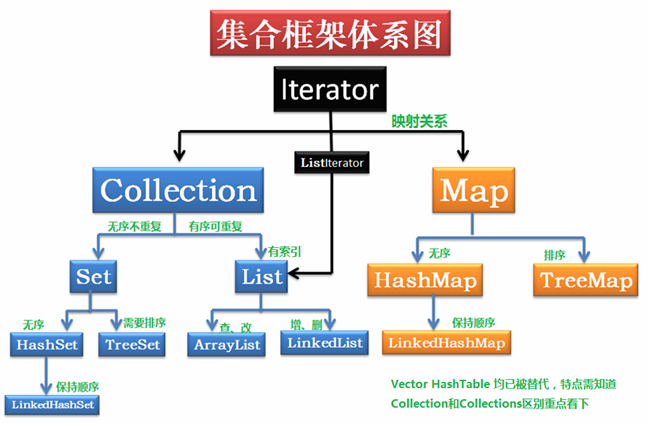
泛型
1.泛型的好处?
答:反应保证了java的类型安全,可以在编译时期检查类型安全;消除强制类型转换。设计模式
1.单例模式有哪些实现(还有枚举)?
答:

若有收获,就点个赞吧
0 人点赞
