稳定的排序是值两个相等的数的先后顺序在排序前后不会改变。
稳定的排序算法:冒泡,插入,归并
十大排序时间复杂度:
| 排序方法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 | 复杂性 |
|---|---|---|---|---|---|---|
| 直接插入排序 | O(n) | O(n) | O(n) | O(1) | 稳定 | 简单 |
| 希尔排序 | O(nlogn) | O(n) | O(n) | O(1) | 不稳定 | 较复杂 |
| 直接选择排序 | O(n) | O(n) | O(n) | O(1) | 不稳定 | 简单 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 | 较复杂 |
| 冒泡排序 | O(n) | O(n) | O(n) | O(1) | 稳定 | 简单 |
| 快速排序 | O(nlogn) | O(n) | O(nlogn) | O(nlogn) | 不稳定 | 较复杂 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 | 较复杂 |
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O(n+r) | 稳定 | 较复杂 |
1.二分查找法
二分查找法的前提是1.有序数组;2.无重复元素
要注意区间的划分:结束循环的条件是left<=right 还是left<right,这两种区间的划分跟middle的赋值相关联。
public int binarySearch(int[] arr,int target){int left = 0;int right = arr.length - 1;while(left <= right){int middle = (left+right)/2; //找到中点位置if(arr[middle] > target){ //目标值在下半区间right = middle - 1;}else if(arr[middle]<target){ //目标值在上半区间left = middle + 1;}else{return middle;}}return -1;}
总结:整个算法的基本思想是找整个有序数组的中点值,判断该中点值是不是目标值,如果不是,就再到相应的上半区间/下半区间寻找。
2.插入排序
排序的经典算法
我再之前以为要新建一个一样长度大小的数组,然后从旧数组一个一个的提取,结果不是。
时间复杂度最坏情况O(N^2) 最好情况O(N) ,空间复杂度O(1)
思路:把一个数组分成两个序列,一个是已经排好的序列,一个是等待插入的值。通常开始i=1是等待插入的值,而j=i-1则是排好的序列。判断arr[j]是不是大于value=arr[i],如果大于的话,则向后移一位arr[j+1]=arr[j],j—,直到arr[j]
public void addSort(int[] arr){for(int i = 1; i < arr.length; ++i){int value = arr[i]; //待插入元素int j = i-1;while(j >=0 && arr[j] >value){arr[j+1] = arr[j];j--;}arr[j+1] = value;}}
总结:开始有个误区,没意识到前面的序列是已经排好了的,所以移位的时候再想怎么移。代码很经典值得多多品味。时间复杂度O(n^2),最好情况为O(n),适合数据量不大,对算法稳定性有要求,且数据整体有序的情况。
3.希尔排序
先说下插入排序,插入排序的应用场景是在数列基本有序的情况下使用,基本有序的话移动的次数就少。
思路:希尔排序就是插入排序的增强版,先把数列中分成若干个小的分组(这个分组是逻辑上的分组),然后对小的分组进行插入排序,最后变成大的分组之后数组就基本有序了,再使用插入排序就很高效了。
先看看图
第一步,先把大的数组分成一个最小的分组,gap = n/2 = 4,就是小分组数据之间的间隔。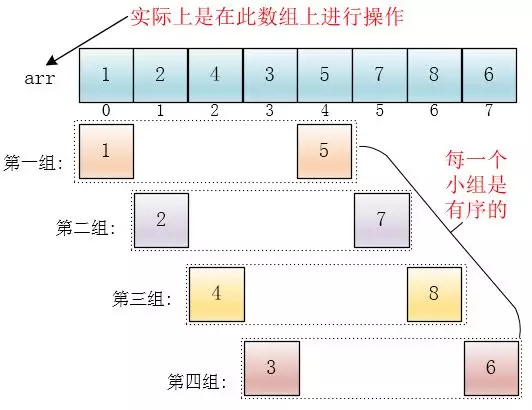
第二次分组的gap = n / 4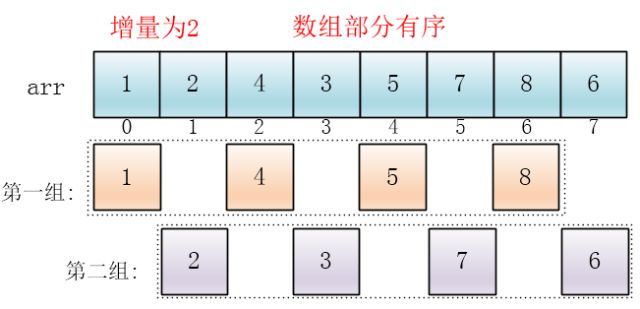
第三次分组 gap = n/4 = 1, 这个时候再排一次序就就有序了。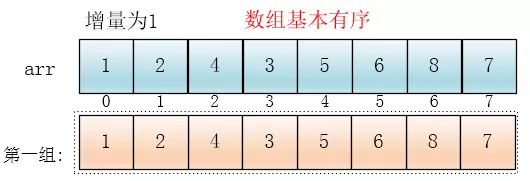
时间复杂度记住就行,最坏O(n^2),最好O(n^1.3),平均O(nlogn)
4.快速排序
思想:先从数组中选取一个基数,然后把小于该基数的值放在左边,大于该基数的值放在右边,放完之后这个数在整个数组中就是有序的。然后把数组分割成两部分,按照递归的方式进行同样的操作。
//快速排序public void quickSort(int[] arr, int start, int end){if(start < end){int middleIndex = getIndex(arr,start,end);quickSort(arr,start,middleIndex);quickSort(arr,middleIndex+1,end);}}public int getIndex(int[] arr, int start, int end){int middle = arr[start];while(start < end){while(start < end && arr[end] >= middle){end--;}arr[start] = arr[end];while(start < end && arr[start] <= middle){start++;}arr[end] = arr[start];}arr[start] = middle;return start;}
总结:时间复杂度O(nlogn),空间复杂度O(longn),最坏O(n^2),因为递归用到栈,所以空间复杂度不为O(1)。
5.TopK问题
找出一个数组最大的K个元素
比如:arr=[4,7,12,45,1,5],k=3 输出:[7,12,45] 最大的三个,可以不按顺序来。
思路:如果先将数组进行排序然后选择最大的k个,这样导致做了许多无用功,如果数组很大,时间复杂度O(N^2)。
用基于选择排序的方法做:思想就是选择排序,时间复杂度也很高O(N*K)。
用基于快速排序的思想做:选择一个基数,大于基数的都在右边,小于技术的都在左边,如果K=length-middle的话,右边都是大于middle的K个数,说明找到了K个数。如果K>length-middle的话就说明中轴数没找到,从左边继续找。同样的道理K<length-middle的话就从右边找。
public int getIndex(int[] arr, int start, int end){int middle = arr[start];while(start < end){while(start < end && arr[end] >= middle){end--;}arr[start] = arr[end];while(start < end && arr[start] <= middle){start++;}arr[end] = arr[start];}arr[start] = middle;return start;}//TOP K:查找最大的K个元素,基于快速排序的,如果length-middle-1 = K 的话,最右边就是K个最大元素// 如果length-middle < K 的话就继续从前半部分找。// 如果length-middle > K 的话最大的K个值肯定在后面,就从后面继续找public void topK(int[] arr,int[] result,int k,int start,int end){if(start<end){int middle = getIndex(arr,start,end);if(arr.length - middle == k){for(int i = 0; i < k; ++i){result[i] = arr[middle + i];}return;}else if(end - middle < k){topK(arr,result,k,start,middle);}else if(end - middle > k){topK(arr,result,k,middle,end);}}}
总结:时间复杂度O(n)+O(n/2)+…. < O(2n)
6.优化的冒泡排序
简单的冒泡已经熟烂于心的,做个优化的吧
思路:优化就是在一次比较后没有发生交换就说后面都是有序的,不用再遍历了。
public int[] bubbleSort(int[] arr){for(int i = 0; i < arr.length; ++i){int flag = true;for(int j = 0; j < arr.length - i - 1; ++j){if(arr[j] > arr[j+1]){int temp = arr[j];arr[j] = arr[j+1];arr[j+1] = temp}if(flag){return arr;}}}}
总结:对于未优化的冒泡,时间复杂度O(n^2),最好O(n),时间复杂度高,适合数据量不大,对稳定性有要求且数组基本有序的情况。
7.归并排序
思想:归并排序是分而治之的思想,把大的数组分成两部分,然后一直分割,直到小数组的大小为1,这样这个小数组是有序的,然后逐渐合并成大数组,合并后是有序的,合并有序数组是很快的。
不过这个过程中需要一个辅助数组来帮助合并。
public void mergeSort(int[] arr, int[] temp,int left,int right){if(left < right){//分int center = (left+right)/2;//治mergeSort(arr,temp,left,center);mergeSort(arr,temp,center+1,right);//并merge(arr,temp,left,center,right);}}public void merge(int[] arr, int[] temp, int left, int center, int right){//i为第一个小数组的起点int i = left;//j为第二个小数组的起点int j = center + 1;for(int k = left; k <= right; ++k){//如果第一个小数组遍历完了,就将第二个小数组放进去,否则相反if(i > center){temp[k] = arr[j++];}else if(j > right){temp[k] = arr[i++];}//如果第一个小数组的这个值大于第二个小数组的这个值就放第二个小数组的值else if(arr[i] > arr[j]){temp[k] = arr[j++];}else{temp[k] = arr[i++];}}//把临时数组放回去for(int k = left; k <= right; ++k){arr[k] = temp[k];}}
总结:时间复杂度O(nlogn),花费时间T(N) = 2*T(N/2)+N,等于处理两个N/2的子数组加上合并花费的时间,有初值T(1) = 1,用递推公式推出来就是nlogn,空间复杂度O(n),一个temp,还有种非递归的方式,有空再看。对稳定性要求高和时间要求高,但是对空间复杂度要求不高的情况。
8.堆排序
要知道堆排序,我们必须知道二叉堆是什么,二叉堆有完全二叉树的性质,还有一条特性是,每个父节点是孩子节点的最大值或者最小值,依据这个特性分为最大堆和最小堆,最大堆的根节点是所有节点中的最大值,而最小堆相反,见下图是最小堆: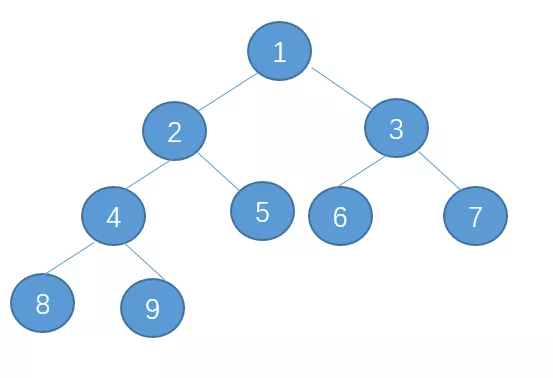
如果要插入元素,让其再最后一层,然后与上层进行比较,依次上浮,如果是删除元素,就将最后一个节点补到被删除元素那个位置,然后下沉。
对于一颗无序的完全二叉树,要构建成一个二叉堆,让每个非叶子节点依次下沉。
现在先实现由一颗完全二叉树构建成一颗二叉堆,根据完全二叉树的特点,加入一个节点的下标是n,它的左孩子下标是2n+1,右孩子是2n+2。
要找到最后一个非叶子节点,只要找到最后一个叶子节点,然后反推——(length-2)/2
将每个非叶子节点进行下沉就先构建了一颗二叉树了,然后需要做的是排序,每次将根节点与最后一个节点交换,然后将根节点下沉,操作。
//堆排序public void heapSort(int[] arr){int length = arr.length;//先构建二叉堆,从最后一个非叶子节点中依次下沉for(int i = (length-2)/2; i >= 0; --i){downAdjust(arr,i,length);}//现在开始堆排序for(int j = length - 1; j >= 1; --j){int temp = arr[j];arr[j] = arr[0];arr[0] = temp;//不要将被交换的那个节点给交换了downAdjust(arr,0,j);}}public void downAdjust(int[] arr, int parent, int length){int child = parent*2+1;//先取出父节点的值int temp = arr[parent];while(child < length){//先定位到孩子节点中更大的那个if(child + 1 < length && arr[child] < arr[child+1]){child++;}//如果父节点已经大于孩子节点就结束if(temp >= arr[child]){break;}//然后向下继续遍历arr[parent] = arr[child];parent = child;child = parent*2+1;}arr[parent] = temp;}
总结:堆排序的最好和最差时间复杂度都是O(logn)

若有收获,就点个赞吧
0 人点赞
