时间:2020.11.21 - 2020.11.28
一,字符串类型
1. 理解字符串类型
(1)什么是字符串?
- 在Python中使用英文引号括住的都是字符串
- 引号有单引号’,双引号’’,三引号’’’,”””
引号可以包含其它类型的引号,但是相同引号里面不能包含相同的引号,python解释器会无法解释(当然使用转义字符的情况除外)。
(2)字符串是一种线性的序列结构。
字符与字符之间是直线的关系,字符按先后顺序进行排列,所有的字符空间对应着一块连续的内存,这种结构就叫做线性的序列结构。
2. 字符串的定义
(1)定义字符串有两种方法,一是对象定义法,一是直接定义法。
对象定义的语法:string = str(object=”)
-
3. 字符编码与字节解码
(1)编码,是指用数字来对字符进行表示
内置函数ord,可以获取字符的十进制数字码,通过chr函数将数字码转换为对应的字符
- ord函数的基本语法:ord(character)
-
(2)常用的字符编码
ASCII码,一种使用7个或8个二进制位进行字符编码的方案,最多可以包含256个字符。基本的 ASCII 字符集一共有128 个字符,包括常用的英文字母、数字、标点符号,转义字符等。
- 在UNICODE编码中,为每种语言中的每个字符设定了统一并且唯一的二进制编码, 每个字符对应一个唯一的UNICODE数字码,UNICODE编码的形式为:在十六进制数字码前面加上U+。例如:”爱”的UNICODE是U+7231。
- UTF-8,是一种针对UNICODE的可变长度字符编码, 不同于UNICODE编码采用固定长度的字节数来表示字符, UTF-8使用的字节数是可变的,比如ASCII字符,在UTF-8编码中仍使用一个字节来进行编码,对于汉字字符使用的是3个字节来进行编码
- GBK是针对汉字的编码规范,采用的是单双字节变长编码,英文字符使用单字节编码,中文部分采用双字节编码。
- Python中的字符串默认采用UNICODE进行编码,也就是说Python中的字符串是UNICODE字符串。
- 通过字符串类型的encode方法,可以获取字符串以特定编码方式编码后的字节码类型(字节码类型不是字节码)。字符串类型encode方法的基本语法:str.encode(encoding),参数encoding表示字符的编码方式, 返回值为bytes类型。注意:encoding编码方式要用引号括起来。
- 在字符串直接量中加一个b的前缀,表示定义了一个字节码类型的字符串,例如name = b”Lohan”
通过字节码类型的decode方法,可以将字节码类型转换为UNICODE字符串。使用decode函数的基本语法:bytes.decode(encoding),参数encoding表示字符的编码方式,返回值为str类型。
4. 转义字符
(1)转义字符的定义
转义字符是反斜杠符号’\’+字符构成的特殊字符
通常使用转义字符来表示字符集中定义的字符,如ASCll字符集里面的换行符
需要禁止对字符进行转义,通过在字符串前加上r(resource)前缀:file_path = r”D:\nosql\mongo”(注意这里的字符包含换行符,若不禁止转义,打印时则会出现换行的情况。)
| 转义字符 | 意义 | ASCII码值(十进制) |
|---|---|---|
| \a | 响铃(BEL) | 007 |
| \b | 退格(BS) ,将当前位置移到前一列 | 008 |
| \f | 换页(FF),将当前位置移到下页开头 | 012 |
| \n | 换行(LF) ,将当前位置移到下一行开头 | 010 |
| \r | 回车(CR) ,将当前位置移到本行开头 | 013 |
| \t | 水平制表(HT) (跳到下一个TAB位置) | 009 |
| \v | 垂直制表(VT) | 011 |
| \\ | 代表一个反斜线字符 | 092 |
| \‘ | 代表一个单引号(撇号)字符 | 039 |
| \“ | 代表一个双引号字符 | 034 |
| \? | 代表一个问号 | 063 |
| \0 | 空字符 | 000 |
5. 字符串常用操作符
(1)字符串常用操作符
- +,*,[],[:],in,not in,%
- ““ 操作符用来对字符串进行重复输出,返回一个新的字符串。(注意:操作符后面的必须为整型。)
-
(2)操作符:[]
索引分为正索引和负索引。正索引从0开始编号,负索引表示从末尾开始数起,从-1开始编号。
(3)分片操作符:[:]
索引区间遵循左闭右开原则,前索引的值默认为0,后索引的值默认为字符串长度
(4)操作符:in
-
6. 字符串常用操作方法
(1)获取字符串长度
(2)字符串的大小写操作
str.lower(),str.upper(): 返回值为一个包含全小写字母和全大写字母的字符串
str.islower(),str.isupper():返回布尔值True或False
(3)删除字符串的空白字符(疑难点:详细讲述下列方法?)
str.strip(),str.lstrip(),str.rstrip():返回删除空白字符后的字符串
- str.strip():删除字符串首尾的空白字符
- str.lstrip()????
-
(4)字符串的子串查找
str.find(sub_str): 从左到右查找子串第一次出现的位置,如果查找成功,返回子串在主串中的开始位置的索引,否则返回值为-1。
(5)字符串的子串统计
str.count(sub_str):在字符串str中统计子串sub_str出现的数量,返回一个整型值。如果没有相应的子串,那么返回的值为0。
(6)字符串的子串替换
str.replace(sub_str, dst_str):将字符串中子串替换为新的子串,返回一个新的字符串。将参数sub_str表示的子串替换为新的字符串dst_str。
(7)字符串的拆分函数
str.split(sep=None, maxsplit=-1):使用 sep作为分隔字符串,返回由sep字符串分隔后的字符串列表。 如果给出了 maxsplit,则最多进行 maxsplit 次拆分。 如果 maxsplit 未指定或为 -1,则不限制拆分次数。sep 参数可能由多个字符组成 (例如’1@@2@@3’.split(‘@@’) 将返回 [‘1’, ‘2’, ‘3’])。
(8)字符串的前缀与后缀
str.startswith(prefix),str.endswith(suffix):判断字符串是否以prefix子串作为前缀,是否以suffix子串作为后缀,返回值为布尔类型
7.字符串格式化
(1)字符串格式化的定义
字符串的格式化是指按照特定的格式对字符串进行输出。
- 使用操作符%来对字符串进行格式化的语法:str % (argument,…),字符串str中包含相应的格式化符号,括号里面的格式化参数须与格式化符号一一对应。格式化语法中的括号()不是必须的。
- 格式化时如果类型不一致,那么必须通过隐式转换的方式来进行类型匹配。例如%d符号表示格式化整型类型,那么传递的参数为浮点类型或布尔类型时,参数会自动地转换为整型。
- 使用%f进行字符串格式化时,可以指定浮点小数的精度。格式化写法:%m.n f
- m指的是显示的最少总宽度,总宽度包含后面的小数点,
- 如果格式化内容的宽度不足m位,则会在格式化输出中补空格。
- n指的是小数点后面显示的位数,小数点后的位数大于n时会进行四舍五入。
- 如果格式化符号为%s,那么不论格式化参数是什么数据类型,都会格式化为字符串类型 | 常用的格式化符号 | 描述 | | —- | —- | | %d | 格式化为整数 | | %f | 格式化为浮点数,可指定小数点后面的精度 | | %s | 格式化为字符串 | | %e | 以科学计数法格式化为浮点数 | | %g | 根据值的大小来采用%e或%f来进行格式化 |
(2)用字符串类型的format方法进行格式化
- 主要有以下两种方法:位置占位符,关键词占位符
- 位置占位符是指通过位置编号来指定格式化参数的输出位置,位置以{索引}的形式来进行指定,
{}中不传递索引时,自动从0开始编号,在{}中不指定位置时,与format方法中的参数的顺序(从左到右的顺序)一一对应。
二,列表类型
1. 列表类型与定义
(1)列表类型的定义
列表类型是一种数据集合,将集合中的元素按先后顺序进行排列。(这说明列表是有序的。)
- 列表进行定义主要有对象定义法和直接定义法。
- list(iterable=() )的形式就是列表的对象定义法。参数iterable表示可迭代对象,默认值为(),()表示空元组。
- 直接定义法,是直接通过[]符号来定义列表。
-
(2)列表是一种序列结构
-
(3)可迭代对象与不可迭代对象
Python中的简单数据类型,都是不可迭代的对象。迄今学过的简单数据类型有整型,浮点类型,布尔类型。
-
2. 列表的常用操作符
(1)列表操作符
+,*,[],[:],in,not in,>, ==等关系运算符
- *:重复输出列表元素
-
(2)操作符*
““ 操作符用来对列表进行重复输出,返回一个新的列表 。操作语法:list int(number)
girls = [“小花”,”小朵”] * 0 ——>girls指向的列表为[]
(3)操作符:>,<,==,!=
列表的关系运算是按序进行比较的,这里的按序比较是从列表的第一个元素开始,逐元素进行比较。
只有在元素值相同,顺序也相同的情况下,两个列表才相等,否则以元素先后的大小关系来确定列表的大小关系。返回值为布尔类型。
3. 列表常用操作方法
(1)四种常用操作方法类型
-
(2)列表的添加
空列表无法通过索引来进行元素的添加。
- list.insert(index, object):参数index表示索引值,insert方法用来在index的前一个位置来插入元素。如果index的值大于列表中的最大索引,那么等同于执行append方法。
list.extend(iterable):在列表的末尾添加一个可迭代对象,无返回值。extend方法只接受可迭代的对象,会将可迭代对象中的元素**逐一添加**到列表中。
(3)列表的查找
list.index(value, [start, [stop]]): 在列表中查找元素是否存在,如果存在会返回该元素的索引,如果不存在会抛出异常。start表示查找的起始位置,stop表示查找的结束位置(闭区间,不包括stop)。start的默认值为0,stop的默认值为列表的长度。
list.count(value): 查找元素值value在列表中出现的次数,元素值value不存在时,返回0。
(4)列表的修改
可以通过[]操作符对列表的元素值进行修改。要注意的是[]中的索引必须在有效的范围之内,否则会抛出访问越界的错误异常。
(5)列表的删除(疑难点)
list.pop([index]): 删除索引index对应的元素值,index的值默认为列表的最大索引值,也就是说,pop方法默认删除尾部的元素。返回值为被删除的列表元素,index的值必须在列表有效的索引范围内,否则会抛出异常。
- list.remove(value): 执行remove方法来直接删除列表中的元素,无返回值。按从左到右的顺序删除第一个元素。
list.clear(): 无参数,无返回值,一键清空列表中的所有元素。
(6)与列表有关的其它操作方法
list.sort(key=None, reverse=False): 对列表进行原地排序,只使用 < 操作符来进行元素值的比较。参数key的默认值为None, 传递带一个参数的函数对象。参数reverse为False时表示升序排序,为True时表示降序排序。
- 举例:
numbers = [[1,2,3],[4,5],[6,7,8,9]]
# key传递的是len,sort方法会先计算列表元素的len值,然后进行降序排序
numbers.sort(key=len, reverse=True)
# numbers的输出为[[6,7,8,9],[1,2,3],[4,5]]
4. 列表推导式
(1)列表推导式(列表解析式)的基本结构
- [element for element in iterable]:element表示从可迭代对象iterable中遍历出的元素,从其基本结构可看出,列表推导式本质是一个for循环,在for循环中每迭代一次,就会在列表中插入一个新的元素。
列表推导式的基本结构很简单,通过嵌套的for循环和条件控制结构可以对列表推导式的基本结构进行扩展。
(2)包含嵌套for循环的列表推导式
[element for x in iterable for y in iterable]:element表示由元素x和元素y所生成的一个新的元素,iterable表示可迭代对象。
- 同学们在理解列表推导式时,可以将它们转换为普通的循环结构。
- 举例:
numbers = [x+y for x in [1,2,3] for y in [1,2,3]]
print(numbers)
# numbers的输出为:[2, 3, 4, 3, 4, 5, 4, 5, 6]
(3)包含条件控制的列表推导式
[element for element in iterable if element…]:element是从可迭代对象iterable中遍历出的元素,然后通过if语句对该元素进行逻辑判断,如果元素符合条件,就添加到列表中。
(4)同时包含for循环和条件控制的列表推导式
-
三,元组类型
1. 元组类型与定义
(1)对元组进行定义
对元组进行定义主要有对象定义法和直接定义法。元组与列表有着相同的数据结构,区别在于,元组是静态的数据类型,而列表是动态的数据类型。
- 元组的对象定义法:tuple(iterable=() )的形式就是元组的对象定义法。参数iterable表示可迭代对象,默认值为(),()表示空元祖。
- 所谓的直接定义法,是直接通过()符号来定义元组。
通过()符号来直接定义元组,只存在一个元素时,后面必须带一个逗号。numbers = (1,),# 也可以省略括号:numbers = 1,
(2)元组的自动解包
将元组赋值给其它变量时,Python会自动对元组执行解包。
- 元组解包就是将元组进行拆解,将元组中的元素按序进行赋值。
- 将元组进行解包赋值时,赋值操作符左边的变量个数必须与元组中的元素个数一致,否则会抛出异常信息。
- 元组中只存在一个元素时,如何解包?>>>a = (2,) >>>b, = a

2. 元组的常用操作符
(1)元组操作符
(2)操作符:*
““ 操作符用来对元组进行重复输出,返回一个新的元组。操作语法:tuple int(number),number为0时返回一个空元组。
(3)操作符:>,<,==,!=
元组的关系运算是按序进行比较的,这里的按序比较是从列表的第一个元素开始,逐元素进行比较。
- 只有在元素值相同,顺序也相同的情况下,两个元组才相等,否则以元素先后的大小关系来确定元组的大小关系。返回值为布尔类型。
3. 元组常用操作方法
(1)静态,只读的元组
-
(2)元组的查找
tuple.index(value, start=0, stop=2147483647):查找元素在元组中的索引,元素不存在时会抛出异常。
- tuple.count(value):查找元素值value在列表中的数目,元素值value不存在时,返回0。
4. 元组与列表的区别
(1)元组与列表的核心区别在于,元组是不可变的,列表是可变的。
(2)根据数据对象定义变量:如果该数据对象具备静态,只读的属性,应当使用元组,否则应当使用列表。
四,字典类型
1. 字典类型与定义
(1)对字典进行定义
- 对字典进行定义主要有对象定义法和直接定义法。
- 字典定义的四种对象定义法:
- dict():
- dict(mapping):使用mapping对象中的(key, value)键值对来构造一个有值的字典对象。Python中的字典类型就是一种标准的mapping(映射)对象,我们可以在dict方法中传递一个字典对象来进行字典的构造。
- old_book = dict( [ [“第十二章-彻底掌握Python的字典类型”, 20] ] )——>括号内的第一个中括号表示其是一个可迭代对象。
- dict(iterable):这里的iterable表示的是可迭代对象,可迭代对象存储了每一个**键值对,键值对以列表或元组的形式**存储于这个可迭代对象中。(注意这里,键值对也是以列表或元组的形式存储。)
- book = dict( ( (“第十二章-彻底掌握Python的字典类型”, 20), ) ),(因为元组只有一个元素时,要加逗号。)
- 为了清晰地表示可迭代对象的特性,所以用括号括起来。就好比,函数的参数要用括号括起来一样。
- dict(**kwargs):这种构造方式是直接采用name=value的键值对形式来对字典进行构造,name表示键名,value表示键值。参数name必须符合变量名的规则, value必须是Python中的合法数据类型。
- book = dict(title=”108节课彻底学通Python”)
字典的直接定义法:直接定义法是指直接通过字典的别名符号{}来进行定义。在{}中,键值对以英文逗号进行分隔。
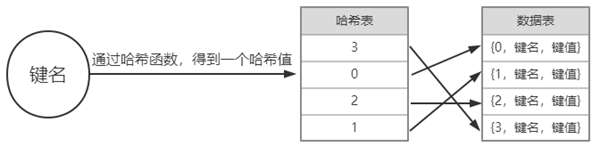
- 静态的数据类型有:简单数据类型,字符串,元组。
- 如果键名的数据类型是不可变的,那么就能保证通过哈希函数计算时,得到的都是相同的哈希值。如果键名是动态的数据类型,意味着在这个数据类型的生命周期内,它的值是变化的,不能保证计算得到的是相同的哈希值,所以键名必须是静态的数据类型,以保证其哈希值的唯一性。
3. 字典的常用操作方法
(1)字典的四种常用类型操作方法
-
(2)字典的查找
查找键所对应的键值:
- dict[key]:key表示字典的键名,如果键名存在,会返回键值,如果键名不存在,则抛出异常
- dict.get(key, default=None):key表示字典的键名,如果键名存在,会返回键值,如果键名不存在,则返回在参数default中指定的值。
- 查找字典中的所有键名:
- dict.keys():字典对象的keys方法返回的是一个dict_keys类型,dict_keys是一个可迭代对象,我们可以在for循环中进行遍历。也可以直接通过for key_name in dict的语法来遍历所有键名
- 遍历字典的键名
- for name in book.keys():
- for name in book:
- 查找字典中的所有键值:
- dict.values():字典对象的values方法返回的是一个dict_values类型,dict_values是一个可迭代对象,我们可以在for循环中进行遍历。
- 遍历字典的键值
- for value in book.values():
- 返回字典中的键值对(疑难点)
- dict.items:字典类型的items方法返回的是一个dict_items类型。dict_items是一个可迭代对象。(**这里可迭代对象中的元素是元组。)**
- 在for循环中同时获取键名和键值:
book = {“title”: “Python零基础入门指南”, “author”: “薯条老师”}
for pair in book.items():
print(pair[0], pair[1])
for name, value in book.items():
(3)字典的修改:[]操作符
操作语法:dict[key] = value,键名不存在时,会插入新的键值对(在末尾中插入)。
(4)字典的添加:[]操作符
-
(5)字典的添加:dict.setdefault(疑难点:)
操作语法:dict.setdefault(key, default=None),参数key表示键名,如果键存在,会返回键所对应的键值,否则添加一个新的键值对。通过参数default来指定新键的键值,返回值为键名所对应的键值,如果未指定键值,则返回值为None。
-
(6)字典的添加:dict.update
操作语法:dict.update(iterable):iterable表示可迭代对象,传递的参数主要为字典类型,列表类型,元组类型,无返回值。通过字典对象来更新字典时,如果键名存在,则字典对象中键名的键值被更新为新的键值,如果键名不存在,添加新的键值对。
通过列表或元组来更新字典时,列表与元组是一个二维的结构。# Python会将元组中的第一个元素作为键名,第二个元素作为键值,元组中只存在一个数据项时,不要遗漏逗号,
(7)字典的删除:dict.pop
操作语法:dict.pop(key):pop方法用来删除指定的键,待删除的键必须存在于字典对象中,否则会抛出键名不存在的错误异常,返回值为键名对应的键值。
-
(8)字典的删除:dict.popitem(),随机删除
popitem方法用来随机删除字典中的键,返回值为一个元组,元组的第一个元素为键名,第二个元素为键值。

4. 使用字典进行格式化
(1)使用字典进行格式化操作时,主要是通过关键字占位符的方式来进行格式化。
- 这里的关键字占位符对应于字典中的键名,键名出现在待格式化的字符串中,在对字符串进行格式化时,Python解释器自动将字符串中的关键字占位符替换为对应的键值。
- 格式化语法:”%(key)s” % (dict):key表示字典中的键名,s表示将关键字占位符格式化为字符串类型,同样可以将s换成其它的格式化类型。
字符串中的关键字占位符,必须能在字典中匹配出对应的键名,否则Python会抛出键名不存在的错误异常
(2)使用format方法进行格式化(疑难点:重点讲解一下这里)
在format方法中以关键字参数的形式传递字典对象,格式化语法:”{param[key]}”.format(param=dict)
格式化语法:”{key}”.format(dict):{}中的key表示字典中的键名,在format方法中使用对dict进行解包时,在format中会展开为name=value的关键字参数传递的形式。
- 使用字典类型进行格式化操作时,不会进行类型检查,仅进行文本替换,同时与格式化操作相比,可读性更强。

五,集合类型
1. 集合类型与定义
(1)字典中的元素为键值对,集合中的元素仅为键名。
(2)对象定义法和直接定义法。
- 字典的对象定义法:
- (1)set():可以构建一个空集合。
- (2)set(iterable):可迭代对象中的元素必须是静态的数据类型,否则会抛出类型错误的异常信息。
直接定义法是指直接通过{}符号来直接定义,但是不能使用{}来构造一个空的集合,Python解释器会将其解析为字典类型。在{}中,键名以英文逗号进行分隔。
(3)集合是可迭代对象。
在3.6以后,字典的键的输出顺序与元素的插入顺序一致。
- 集合的键的输出顺序仍是无序的。
2. 集合的键类型
(1)集合的底层实现基于哈希表,键名的数据类型必须是静态的,可哈希的数据类型。
- 集合中的键是唯一的,集合天然具备排重的功能。
3. 集合的常用操作方法
(1)字典的三种常用操作方法类型:集合的查找,集合的添加,集合的删除
(2)集合的添加:
- set.add,操作语法:set.add(key),将键名key添加至集合中,无返回值。key必须是静态的数据类型,否则Python解释器会抛出类型错误的异常信息。
set.update(iterable),操作语法:参数iterable表示可迭代对象,执行update方法时,会将可迭代对象中的元素逐一添加到集合中。迄今为止学过的可迭代对象:字符串,列表,元组,字典,集合。
set.pop,操作语法:set.pop(),执行pop方法来随机删除集合中的元素,集合必须是一个非空集合,否则会抛出异常信息。返回值为被删除的元素。
- set.remove,操作语法:set.remove(key),执行remove方法来删除集合中指定的键,键不存在时会抛出异常信息,无返回值。
- set.clear,操作语法:set.clear(),执行clear方法来清空集合中的元素。
4. 集合类型的集合运算
(1)实现数学上的交集,并集,差集运算
- 在Python中使用‘&’操作符来实现交集运算。
- 在Python中使用‘|’操作符来实现并集运算。
- 差集指的是对两个集合作减法运算,假设有集合A与集合B,那么集合A与集合B的差集表示属于A但不属于B的元素的集合,直接用算数运算符‘-‘来实现差集运算。
六,字典集合的快速查找
1. 当数据量很大时,使用列表等序列结构来进行元素查找,效率十分低下。
2. 字典类型采用哈希表进行实现,在理想情况下,只需计算一次键名的哈希值,就可以快速地查找元素是否存在于数据集合中。
七,字典集合的快速查找
1. Python中的数据类型
(1)简单数据类型,复合数据类型
(2)显式类型转换,隐式类型转换
常说的“取整”,就暗含类型转换的意思,即,将浮点小数转换为整数。
2. 显式类型转换
(1)字符串类型转换为数值类型
字符串中的内容必须是连续的合法的数(十进制数,二进制数,十六进制数等),可以存在空格字符和正负号,不可以出现其它的非数字字符(比如小数点)。
(2)显式类型转换:复合类型之间的转换
Python中的复合类型均为可迭代对象,直接通过对象定义法来传递可迭代对象,以构造一个新的对象:
3. 隐式类型转换
(1)在使用数值类型进行数值运算时,范围小的数据类型会自动转换为范围大的数据类型
-
4. 与布尔类型的转换
(1)凡是表示假值的转换后的布尔类型都为False,其它的则为True。
整型中的假值是0,浮点类型的假值是0.0,字符串的假值是空字符串””,列表的假值是空列表[],元组的假值是空元祖(), 字典类型的假值是空字典{},集合类型的假值是空集合set(), None类型表示空类型,空类型转换后的布尔类型恒为False。
八,我的思考与总结
1. 本周的知识点比较琐碎,学习的时候要注意归纳和总结。
2. 本周字符串、列表、元组、字典、集合的操作方法只需要学会在查找时候多用即可。
3. 复习本周的知识点时,要注意多从操作层面上练习以增加自己的熟练度。
4. 应该清晰地知道本周所讲的数据类型的四种常用方法:添加,查找,修改,删除。
5. 本周重点在字符串、列表、元组、字典、集合这些数据类型的底层数据结构、优缺点、应用场景。

若有收获,就点个赞吧
0 人点赞
