1、并发容器概览
- ConcurrentHashMap 线程安全的HashMap
- CopyOnWriteArrayList 线程安全的List
- BlockingQueue 阻塞队列接口,非常适合数据共享的通道
- ConcurrentLinkedQueue 高效的非阻塞并发队列,可以看作线程安全的LinkedList
- ConcurrentSkipListMap 使用跳表的数据结构进行快速查找的map
2、集合类的历史
2.1、Vector和HashTable
方法syncronied修饰,并发性能差
Vector:public synchronized boolean add(E e) {modCount++;ensureCapacityHelper(elementCount + 1);elementData[elementCount++] = e;return true;}HashTable:public synchronized V put(K key, V value) {// Make sure the value is not nullif (value == null) {throw new NullPointerException();}// Makes sure the key is not already in the hashtable.Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")Entry<K,V> entry = (Entry<K,V>)tab[index];for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value;return old;}}addEntry(hash, key, value, index);return null;}
2.2、 Collections工具类同步HashMap和ArrayList
方法类代码块同步锁,并发性能差
List<String> syncList = Collections.synchronizedList(new ArrayList<String>());Map<String,String> hashMap = Collections.synchronizedMap(new HashMap<String,String>());List:public E get(int index) {synchronized (mutex) {return list.get(index);}}public E set(int index, E element) {synchronized (mutex) {return list.set(index, element);}}public void add(int index, E element) {synchronized (mutex) {list.add(index, element);}}public E remove(int index) {synchronized (mutex) {return list.remove(index);}}Map:public boolean containsKey(Object key) {synchronized (mutex) {return m.containsKey(key);}}public boolean containsValue(Object value) {synchronized (mutex) {return m.containsValue(value);}}public V get(Object key) {synchronized (mutex) {return m.get(key);}}public V put(K key, V value) {synchronized (mutex) {return m.put(key, value);}}public V remove(Object key) {synchronized (mutex) {return m.remove(key);}}public void putAll(Map<? extends K, ? extends V> map) {synchronized (mutex) {m.putAll(map);}}public void clear() {synchronized (mutex) {m.clear();}}
2.3、ConcurrentHashMap 和 CopyOnWriteArrayList
取代同步的ArrayList和HashMap
绝大多数情况下,ConcurrentHashMap 和 CopyOnWriteArrayList 性能优于同步的ArrayList和HashMap(如果一个List经常被修改,那么同步的ArrayList性能优于CopyOnWriteArrayList ,CopyOnWriteArrayList 适合读多写少的场景,每次写入都会复制完整的列表,比较消耗资源)
3、ConcurrentHashMap
3.1、Map简介
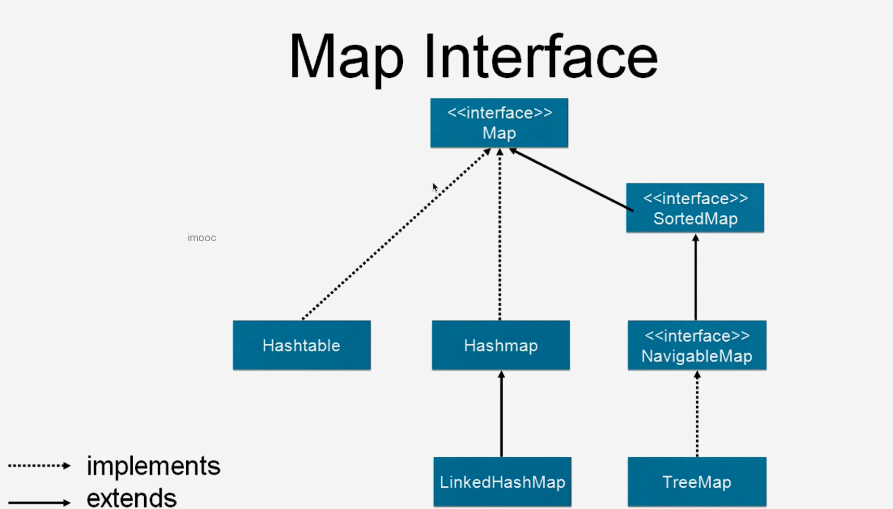
3.2、 为什么HashMap是线程不安全的?
- 同时put碰撞导致数据丢失
- 同时put扩容导致数据丢失
- 死循环造成cpu100%(jdk7之前) 扩容的时候链表死循环
3.3、ConcurrentHashMap 结构
3.3.1、Jdk1.7中的ConcurrentHashMap 结构
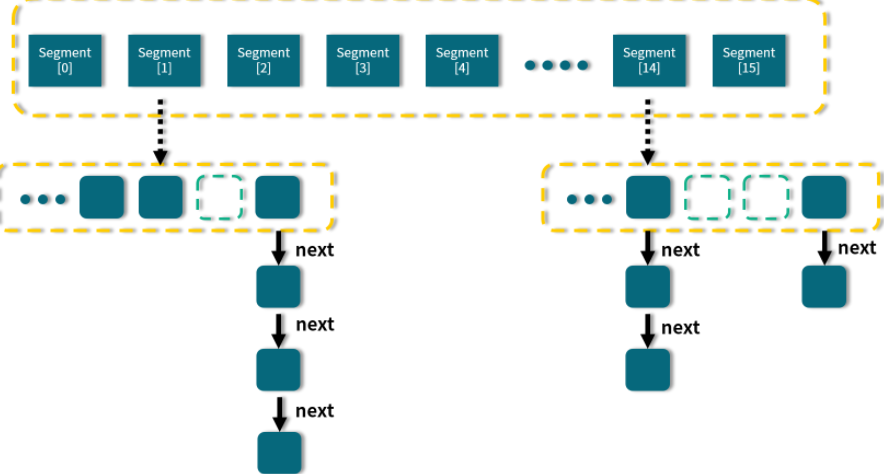
jdk1.7中的ConcurrentHashMap 最外层是多个segment,每个segment的底层数据结构于HashMap类似,仍然是数组和链表组成的拉链法。
每个segment设置了独立的ReentrantLock锁,每个segment之间互不影响,提高了并发效率
ConcurrentHashMap 默认有16个segment,所以最多可以支持16个线程并发写(操作分布在不同的segment上。默认值可以在初始化的时候设置,但是一旦初始化后,无法扩容
3.3.2、Jdk1.8中的ConcurrentHashMap 结构
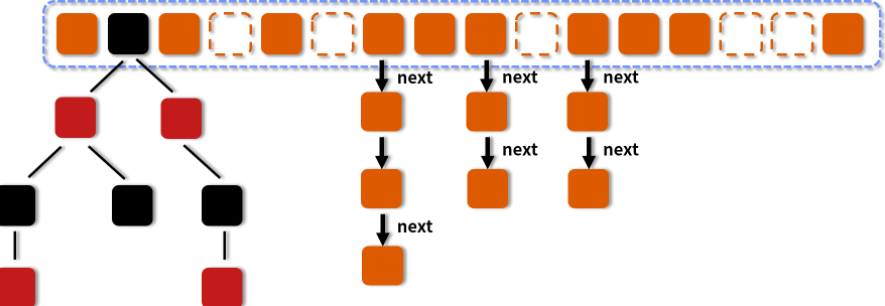
- 第一种是最简单的,空着的位置代表当前还没有元素来填充。
- 第二种就是和 HashMap 非常类似的拉链法结构,在每一个槽中会首先填入第一个节点,但是后续如果计算出相同的 Hash 值,就用链表的形式往后进行延伸。链表长度大于某一个阈值(默认为 8),且同时满足一定的容量要求的时候,ConcurrentHashMap 便会把这个链表从链表的形式转化为红黑树的形式,目的是进一步提高它的查找性能。
- 第三种结构就是红黑树结构
final V putVal(K key, V value, boolean onlyIfAbsent){if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode());int binCount = 0;for (Node<K,V>[] tab = table;;) {Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0)tab = initTable();else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);else {V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount);return null;}
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());if ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {if ((eh = e.hash) == h) {if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}else if (eh < 0)return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;}
3.3.3、为什么要把1.7的结构变为1.8的结构?
数据结构 : Java 7 采用 Segment 分段锁来实现,而 Java 8 中的 ConcurrentHashMap 使用数组 + 链表 + 红黑树
hash碰撞: 先使用拉链法,再转红黑树
保证并发安全:ava 7 采用 Segment 分段锁,而 Java 8采用CAS
查询复杂度:链表查询复杂度为O(n),但是java8中一旦转为红黑树,就变为O(logn)
为什么超过8转红黑树?
默认链表,占用内存更少,红黑树占用
达到冲突8次概率只有千万分之一,转红黑树可以确保极端情况下的查询效率
3.3.4、错误操作ConcurrentHashMap 不保证线程安全
读和写两个独立操作组合到一起就不是线程安全的,可以采用cas实现
public class ConcurrenthashMapDemo {private static ConcurrentHashMap<String,Integer> map = new ConcurrentHashMap();public static void main(String[] args) throws InterruptedException {int threadCount = 50;long start = System.currentTimeMillis();map.put("count", 0);Runnable r = () -> {IntStream.range(0, 100000).forEach(e -> {//可以实现但是并发效率低synchronized (ConcurrenthashMapDemo.class){Integer count = map.get("count");count ++;map.put("count",count);}});};Thread[] threads = new Thread[threadCount];IntStream.range(0, threadCount).forEach(e -> {threads[e] = new Thread(r);});IntStream.range(0, threadCount).forEach(e -> {threads[e].start();try {threads[e].join();} catch (InterruptedException interruptedException) {interruptedException.printStackTrace();}});long end = System.currentTimeMillis();System.out.println("syncnized方式 count结果:" + map.get("count") + " 耗时:" + (end - start));long start2 = System.currentTimeMillis();map.put("count", 0);Runnable r2 = () -> {IntStream.range(0, 100000).forEach(e -> {//并发效率高while(true){Integer count = map.get("count");Integer newCount = count + 1;boolean result = map.replace("count", count, newCount);if(result){break;}}});};Thread[] otherThreads = new Thread[threadCount];IntStream.range(0, threadCount).forEach(e -> {otherThreads[e] = new Thread(r2);});IntStream.range(0, threadCount).forEach(e -> {otherThreads[e].start();try {otherThreads[e].join();} catch (InterruptedException interruptedException) {interruptedException.printStackTrace();}});long end2 = System.currentTimeMillis();System.out.println("CAS方式 count结果:" + map.get("count") + " 耗时:" + (end2 - start2));}}
4、CopyOnWriteArrayList
4.1、作用与适合场景
CopyOnWrite 的意思是说,当容器需要被修改的时候,不直接修改当前容器,而是先将当前容器进行 Copy,复制出一个新的容器,然后修改新的容器,完成修改之后,再将原容器的引用指向新的容器。
CopyOnWriteArrayList 的所有修改操作(add,set等)都是通过创建底层数组的新副本来实现的,所以 CopyOnWrite 容器也是一种读写分离的思想体现,读和写使用不同的容器。
作用
代替Vector和SynchronizedList,Vector和SynchronizedList锁粒度太大,并发效率比较低,并且迭代时无法编辑。
适合场景
读操作尽可能的块,而写操作慢一些也没有太大关系。
例如:黑名单
4.2、读写规则
读取完全不用加锁,写入不会阻塞读取操作,只有写入和写入之间需要同步等待。
4.3、实例
ArrayList迭代时无法编辑,CopyOnWriteArrayList迭代时可以修改,但是修改对迭代没有影响,还是会迭代修改之前的数据
public class CopyOnWriteArrayListDemo {public static void main(String[] args) {//异常ConcurrentModificationException 不能再迭代时修改// List<String> list = new ArrayList<>();List<String> list = new CopyOnWriteArrayList<>();IntStream.range(1,6).forEach(e -> list.add(e + ""));Iterator<String> iterator = list.iterator();while (iterator.hasNext()) {String next = iterator.next();if("2".equals(next)){list.remove("5");}if("3".equals(next)){list.add("6");}System.out.println("list: " + list);System.out.println(next);}}}
ArrayList输出
list: [1, 2, 3, 4, 5]1list: [1, 2, 3, 4]2Exception in thread "main" java.util.ConcurrentModificationExceptionat java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)at java.util.ArrayList$Itr.next(ArrayList.java:859)at com.imooc.thread_demo.collection.CopyOnWriteArrayListDemo.main(CopyOnWriteArrayListDemo.java:26)
CopyOnWriteArrayList输出
list: [1, 2, 3, 4, 5]1list: [1, 2, 3, 4]2list: [1, 2, 3, 4, 6]3list: [1, 2, 3, 4, 6]4list: [1, 2, 3, 4, 6]5
4.4、缺点
数据一致性问题:只能保证数据最终一致,不能保证数据实时一致。
内存占用问题:CopyOnWriteArrayList时创建副本实现写,内存占用大
4.5、源码分析
数据结构
/** The lock protecting all mutators */final transient ReentrantLock lock = new ReentrantLock();/** The array, accessed only via getArray/setArray. */private transient volatile Object[] array;
public boolean add(E e) {final ReentrantLock lock = this.lock;lock.lock();try {Object[] elements = getArray();int len = elements.length;Object[] newElements = Arrays.copyOf(elements, len + 1);newElements[len] = e;setArray(newElements);return true;} finally {lock.unlock();}}public E get(int index) {return get(getArray(), index);}
5、并发队列
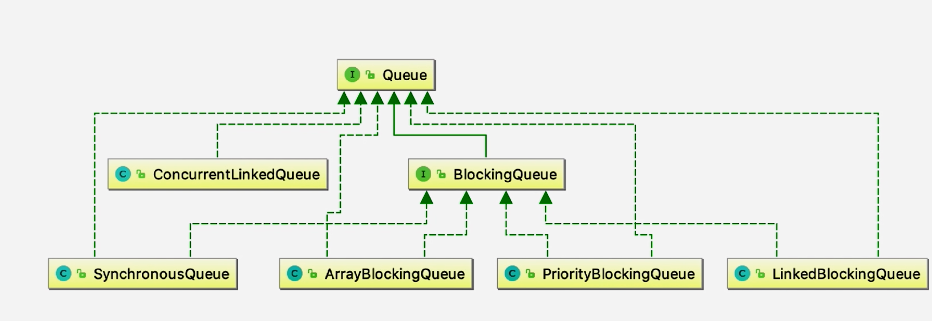
5.1、阻塞队列
从队列取数据,队列里无数据,则阻塞,往队列放数据,如果队列已满,那么就无法继续插入,则阻塞
5.1.1、阻塞队列的常用方法
- 抛出异常:add、remove、element
- add 方法是往队列里添加一个元素,如果队列满了,就会抛出异常来提示队列已满
- remove 方法的作用是删除元素,如果我们删除的队列是空的,那么 remove 方法就会抛出异常。
- element 方法是返回队列的头部节点,但是并不删除,如果队列是空的,抛出异常。
- 返回结果但不抛出异常:offer、poll、peek
- offer 方法用来插入一个元素,并用返回值来提示插入是否成功,如果添加成功会返回 true,如果队列满了,无法插入,返回false
- 移除并返回队列的头节点,如果队列是空的,返回 null 作为提示
- 返回队列的头元素但并不删除,如果队列里面是空的,它便会返回 null 作为提示
3.阻塞:put、take
- put 队列已满,那么就无法继续插入,则阻塞
- take 从队列取数据,队列里无数据,则阻塞
5.1.2、ArrayBlockingQueue
有界
指定容量
公平:可以指定是否需要保证公平,如果想保证公平,等待最长的线程会被优先处理,不过同时会带来一定的性能损耗
5.1.3、LinkedBlockingQueue
无界
容量 Integer.MAX_VALUE
内部结构:node,两把锁
5.1.4、PriorityBlockingQueue
支持优先级的无界阻塞队列
public static void main(String[] args) {PriorityBlockingQueue priorityBlockingQueue = new PriorityBlockingQueue(10,Comparator.comparingInt(o -> ((Student)o).getAge()));priorityBlockingQueue.add(new Student(13,"张三"));priorityBlockingQueue.add(new Student(17,"李四"));priorityBlockingQueue.add(new Student(12,"王五"));Student take = null;do{take = (Student)priorityBlockingQueue.poll();if(take != null){System.out.println(take.getName());}}while(take != null);}
5.1.5、SynchronousQueue
SynchronousQueue 最大的不同之处在于,它的容量为 0,所以没有一个地方来暂存元素,导致每次取数据都要先阻塞,直到有数据被放入;同理,每次放数据的时候也会阻塞,直到有消费者来取
5.1.6、DelayQueue
延迟队列,根据延迟时间排序
5.2、非阻塞并发队列
ConcurrentLinkedQueue
非阻塞队列 ConcurrentLinkedQueue 使用 CAS 非阻塞算法 + 不停重试,来实现线程安全,适合用在不需要阻塞功能,且并发不是特别剧烈的场景

若有收获,就点个赞吧
0 人点赞
