
Netty提供了ByteBuf缓冲区组件来替代java NIO的ByteBuffer缓冲区组件,以便更加快捷和高效的操作内存缓冲区。
调试类:
private static void log(ByteBuf buffer) {int length = buffer.readableBytes();int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;StringBuilder buf = new StringBuilder(rows * 80 * 2).append("read index:").append(buffer.readerIndex()).append(" write index:").append(buffer.writerIndex()).append(" capacity:").append(buffer.capacity()).append(NEWLINE);appendPrettyHexDump(buf, buffer);System.out.println(buf.toString());}
1、ByteBuf的优势
- 自动扩容
- 复合缓冲区,支持堆内存和直接内存
- 池化 ,减少了内存复制和GC,提高了效率
- 读取和写入指针分开,不需要调用flip()方法区切换读/写模式
- 可扩展性好
- 方法的链式调用
- 可以进行引用计数,方便重复使用
扩容规则
- 如果写入后数据大小未超过 512,则选择下一个 16 的整数倍,例如写入后大小为 12 ,则扩容后 capacity 是 16
- 如果写入后数据大小超过 512,则选择下一个 2^n,例如写入后大小为 513,则扩容后 capacity 是 2^10=1024(2^9=512 已经不够了)
- 扩容不能超过 max capacity 会报错
直接内存 vs 堆内存
可以使用下面的代码来创建池化基于堆的 ByteBuf
ByteBufbuffer=ByteBufAllocator.DEFAULT.heapBuffer(10);
也可以使用下面的代码来创建池化基于直接内存的 ByteBuf
ByteBufbuffer=ByteBufAllocator.DEFAULT.directBuffer(10);
- 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用
直接内存对 GC 压力小,因为这部分内存不受 JVM 垃圾回收的管理,但也要注意及时主动释放
池化 vs 非池化
从Netty4.0开始,新增了ByteBuf池化机制,即创建一个缓冲区对象池,将没有被引用的ByteBuf对象放入对象缓存池中,需要时重新从对象缓存池中取出。
池化的最大意义在于可以重用 ByteBuf,优点有没有池化,则每次都得创建新的 ByteBuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 GC 压力
- 有了池化,则可以重用池中 ByteBuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置-Dio.netty.allocator.type={unpooled|pooled}
- 4.1 以后,非 Android 平台默认启用池化实现,Android 平台启用非池化实现
- 4.1 之前,池化功能还不成熟,默认是非池化实现
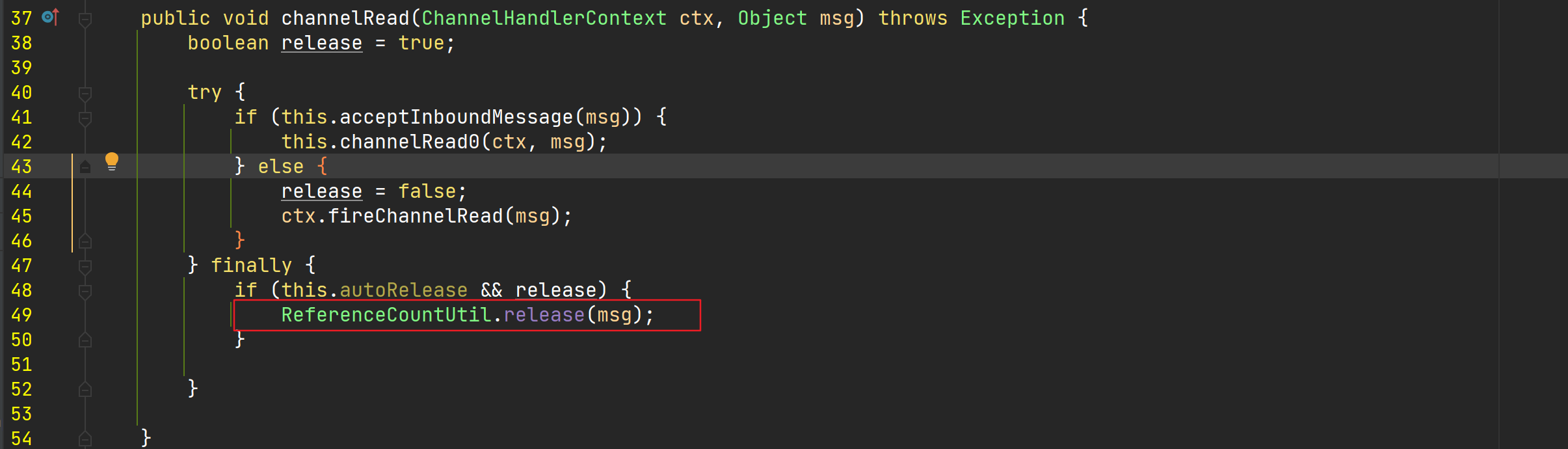
2、Bytebuf重要属性和组成部分
重要属性(AbstractByteBuf中定义)
- readerIndex(读指针):表示读取的起始位置,每读取一个字节,读指针自动加一,一旦读指针和写指针相等,则表示ByteBuf不可读了
- writerIndex(写指针):表示写入的起始位置,每写一个字节,写指针自动加一,一旦写指针和capacity()相等,则表示ByteBuf不可写了。
capacity()为成员方法,表示ByteBuf可写入的容量,它的值不一定是最大容量值。
- maxCapacity(最大容量):表示ByteBuf可扩容的最大容量
3、ByteBuf方法
3.1、写入方法
方法列表,省略一些不重要的方法
| 方法签名 | 含义 | 备注 |
|---|---|---|
| writeBoolean(boolean value) | 写入 boolean 值 | 用一字节 01|00 代表 true|false |
| writeByte(int value) | 写入 byte 值 | |
| writeShort(int value) | 写入 short 值 | |
| writeInt(int value) | 写入 int 值 | Big Endian,即 0x250,写入后 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | Little Endian,即 0x250,写入后 50 02 00 00 |
| writeLong(long value) | 写入 long 值 | |
| writeChar(int value) | 写入 char 值 | |
| writeFloat(float value) | 写入 float 值 | |
| writeDouble(double value) | 写入 double 值 | |
| writeBytes(ByteBuf src) | 写入 netty 的 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 nio 的 ByteBuffer | |
| int writeCharSequence(CharSequence sequence, Charset charset) | 写入字符串 |
注意
- 这些方法的未指明返回值的,其返回值都是 ByteBuf,意味着可以链式调用
- 网络传输,默认习惯是 Big Endian
3.2、读取方法
| 方法签名 | 含义 | 备注 |
|---|---|---|
| isReadable() | 返回ByteBuf是否可读,写指针大于读指针则表示可读 | |
| readableBytes() | 返回表示ByteBuf当前可读取的字节数,其值等于写指针减读指针 | |
| readBytes(byte[] dst) | 将数据从ByteBuf读取到dst目标字节数组中 | |
| readTYPE() | 读取数据基本类型 | |
| getTYPE() | 读取数据基本类型,并且不改变读指针 | |
| markReaderIndex() | 把当前读指针保存到markReaderIndex属性中 | |
| resetReaderIndex() | 把保存到markReaderIndex属性的值恢复到读指针 | |
| markWriterIndex() | 把当前写指针保存到markedWriterIndex属性中 | |
| resetWriterIndex() | 把保存到markedWriterIndex属性的值恢复到写指针 |
4、ByteBuf引用计数及内存回收
:::info
在通信程序的数据传输过程中,Buffer缓冲区实例会被频繁的创建、使用、释放,从而频繁的创建对象、内存分配、释放内存,这样会导致系统开销大,性能低。
于是从Netty4.0开始,新增了ByteBuf池化机制,即创建一个缓冲区对象池,将没有被引用的ByteBuf对象放入对象缓存池中,需要时重新从对象缓存池中取出。
:::
Netty中ByteBuf的内存回收工作是通过引用计数方式来管理的。
除了ByteBuf成员方法 retain()和release(),Netty还提供了一组用于增加和减少引用计数的静态方法: ReferenceCountUtil.retain() 和 ReferenceCountUtil.release()
ByteBuf引用计数规则:
默认情况下,当创建一个ByteBuf时,引用计数为1,每次调用retain()方法,引用计数加1,每次调用release()方法,引用计数减1。如果引用计数为0,再次访问这个ByteBuf对象时,将会抛出异常,如果引用为0,则表示该ByteBuf没有哪个进程引用,其占用内存需要回收。
ByteBuf回收:
当ByteBuf引用计数为0时,Netty会对其进行回收,分为以下场景:
- 如果属于池化的ByteBuf,回收方法是放入可以重新分配的ByteBuf池,等待下一次分配
- 如果属于未池化的ByteBuf,则需细分为两种情况:如果是堆内存缓冲区,会被JVM的垃圾回收机制回收,如果是直接内存缓冲区,则需要调用本地方法释放内存(unsafe.freeMemory)
5、ByteBuf的分配器
5.1、两种ByteBuf的分配器
Netty通过ByteBufAllocator分配器来创建缓冲区和分配内存空间。Netty提供了两种分配器实现:
- PooledByteBufAllocator
- 池化的ByteBuf分配器,将ByteBuf实例放入池中,提高了性能,将内存碎片减少到最小,池化分配器采用了jemalloc高效内存分配策略,该策略被好几种现代操作系统使用
- UnpooledByteBufAllocator
- 普通的未池化ByteBuf分配器,每次调用时返回一个新的ByteBuf实例,使用完成后,通过java的内存回收机制或者本地方法释放内存(取决于为堆内存缓冲区还是直接内存缓冲区)
不同Netty版本中默认的ByteBuf分配器不同: Netty4.0中默认的ByteBuf分配器为UnpooledByteBufAllocator Netty4.1中默认的ByteBuf分配器为PooledByteBufAllocator 默认的ByteBuf分配器可以使用系统参数
io.netty.allocator.type配置,配置值为”unpooled” 或者”pooled”
ByteBufUtil 中有关ByteBuf分配器部分代码: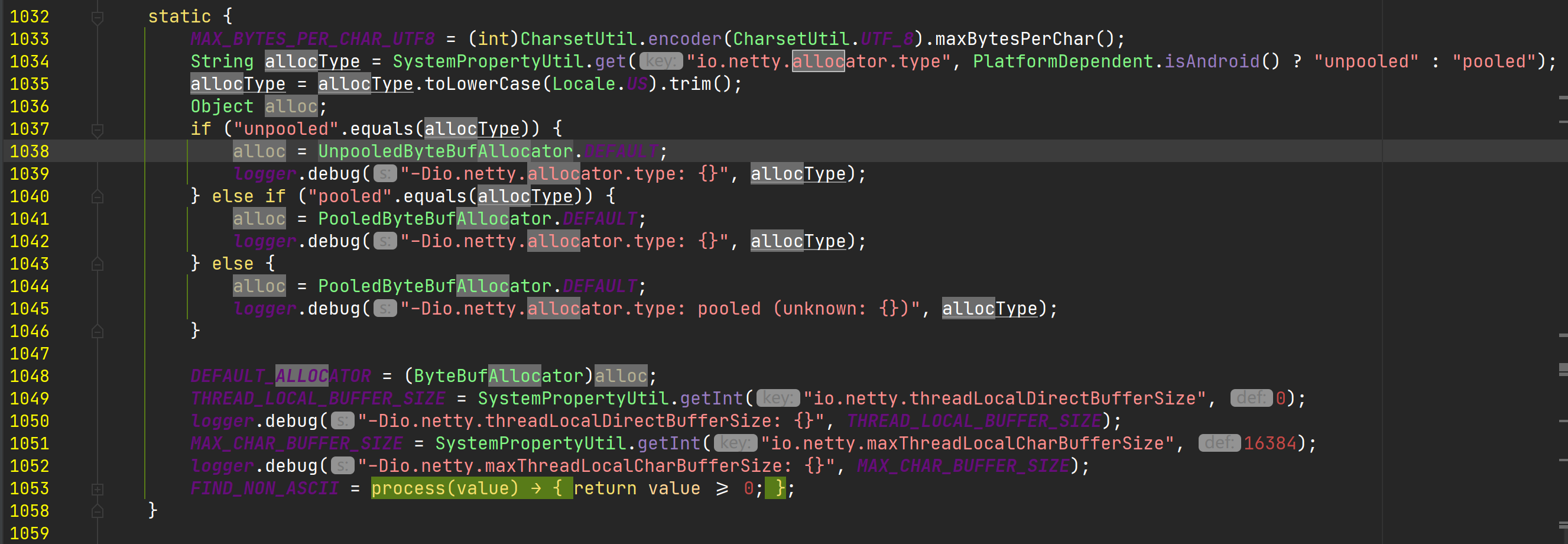
5.2、ByteBuf分配器使用
Netty4.1 默认使用池化分配器,默认使用直接内存
public static void main(String[] args) {//1、通过默认分配器分配(netty4.1 默认使用池化分配器)//默认使用直接内存 初始容量为1,最大容量为100 和ByteBufAllocator.DEFAULT.directBuffer(1,100);等价ByteBuf buffer1 = ByteBufAllocator.DEFAULT.buffer(1,100);//2、通过默认分配器分配(netty4.1 默认使用池化分配器)//使用堆内存 初识容量为256,最大容量为Integer.MAX_VALUEByteBuf buffer2 = ByteBufAllocator.DEFAULT.heapBuffer();//3、通过非池化分配器分配//使用堆内存ByteBuf buffer3 = UnpooledByteBufAllocator.DEFAULT.heapBuffer();//4、通过非池化分配器分配//使用直接内存ByteBuf buffer4 = UnpooledByteBufAllocator.DEFAULT.buffer();}
6、ByteBuf的自动创建与释放
6.1、入站处理
6.1.1、自动创建
入站时,Netty的Reactor线程会通过底层的Java NIO通道读取数据,发送NIO读取的方法为:AbstractNioByteChannel.NioByteUnsafe.read()
分配缓冲区时需要计算大小,从通道读取数据时是不知道数据的具体大小的,申请缓冲区过大浪费内存,太小需要扩容影响性能。 Netty设计了一个用于缓冲区大小计算和推测的辅助接口RecvByteBufAllocator及一系列的实现类,默认的缓冲区大小推测实现类为
AdaptiveRecvByteBufAllocator,其特点是能够根据上次接收数据的大小自动调整下一次缓冲区创建时分配空间的大小,从而避免空间浪费。
public final void read() {ChannelConfig config = AbstractNioByteChannel.this.config();if (AbstractNioByteChannel.this.shouldBreakReadReady(config)) {AbstractNioByteChannel.this.clearReadPending();} else {ChannelPipeline pipeline = AbstractNioByteChannel.this.pipeline();//获取通道的缓冲区分配器ByteBufAllocator allocator = config.getAllocator();//缓冲区分配时的大小推测与计算组件Handle allocHandle = this.recvBufAllocHandle();allocHandle.reset(config);ByteBuf byteBuf = null;boolean close = false;try {do {//由分配器按照计算好的大小分配一个缓冲区byteBuf = allocHandle.allocate(allocator);//读取数据到缓冲区allocHandle.lastBytesRead(AbstractNioByteChannel.this.doReadBytes(byteBuf));if (allocHandle.lastBytesRead() <= 0) {byteBuf.release();byteBuf = null;close = allocHandle.lastBytesRead() < 0;if (close) {AbstractNioByteChannel.this.readPending = false;}break;}allocHandle.incMessagesRead(1);AbstractNioByteChannel.this.readPending = false;//发送数据到流水线,进行入站处理pipeline.fireChannelRead(byteBuf);byteBuf = null;} while(allocHandle.continueReading());allocHandle.readComplete();pipeline.fireChannelReadComplete();if (close) {this.closeOnRead(pipeline);}} catch (Throwable var11) {this.handleReadException(pipeline, byteBuf, var11, close, allocHandle);} finally {if (!AbstractNioByteChannel.this.readPending && !config.isAutoRead()) {this.removeReadOp();}}}}
6.1.2、自动释放
(1) TailContext自动释放
最后一个入站处理器上下文TailContext中的处理器实现了默认的入站处理方法,这些方法会帮助完成ByteBuf内存释放工作
TailContext.channelRead
DefaultChannelPipeline.onUnhandledInboundMessage()
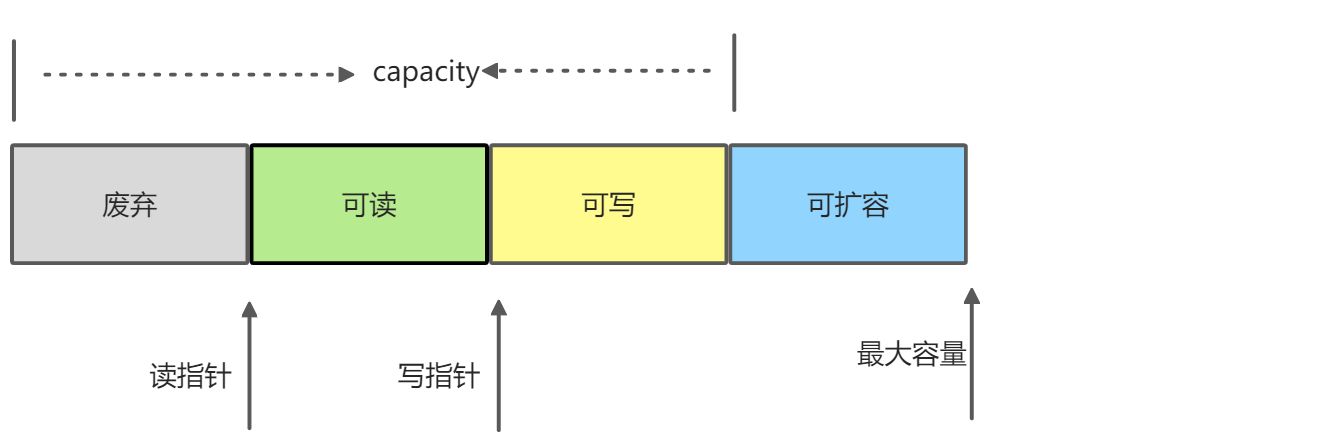
(2)SimpleChannelInboundHandler自动释放
入站处理时,Handler业务处理器可以继承自SimpleChannelInboundHandler,此时业务代码必须移动到channelRead0(ctx,msg)方法中
SimpleChannelInboundHandler 读方法:
6.2、出站处理
6.2.1、自动释放
出站缓冲区由HeadContext自动释放。在所有出站处理器处理完成后,数据包会来到出站处理的最后一棒HeadContext,在将数据写入到Java 底层nio 通道后,ByteBuf会减少计数,如果引用计数为0,就将会被释放掉。
HeadContext.write()方法
AbstractChannel.AbstractUnsafe.write()方法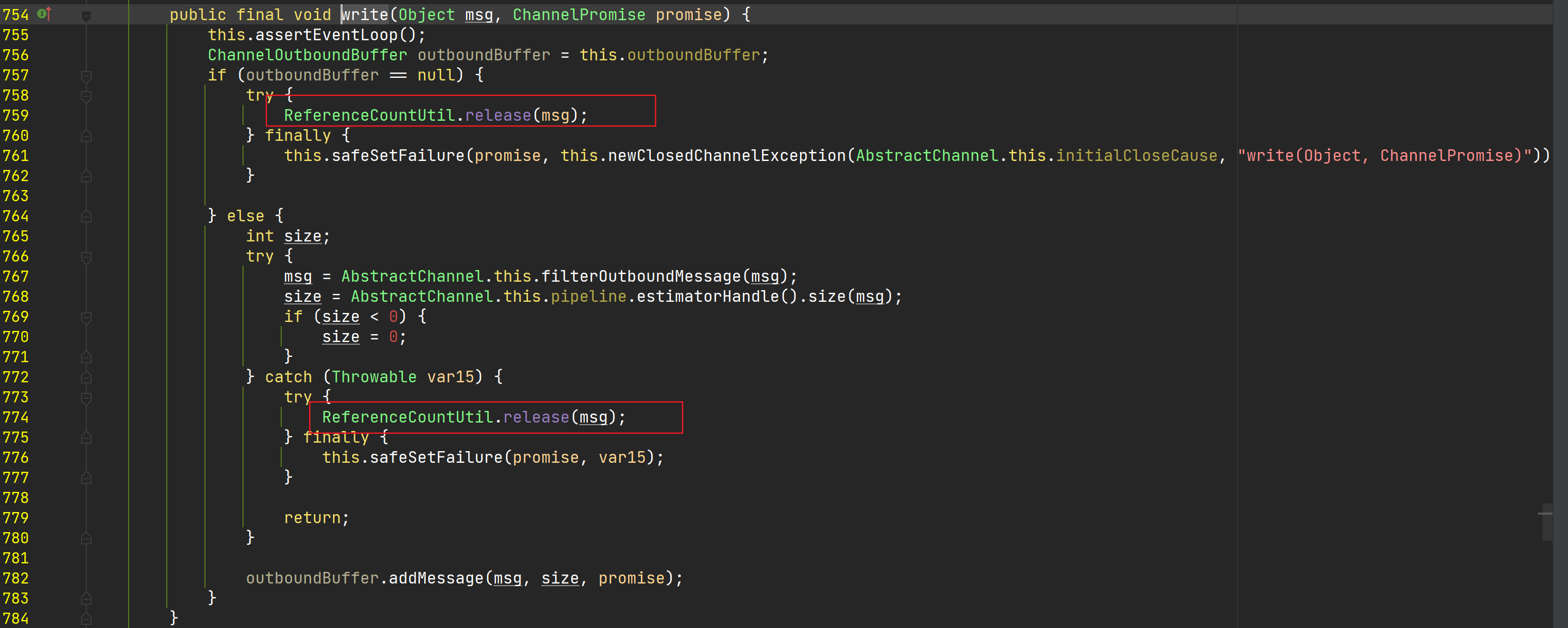
7、开发中release的正确姿势
上文中提到需要手动调用release()方法减少计数,以便ByteBuf内存回收,那么应该什么时候调用release方法呢?
7.1、一般情况下
ByteBuf buf = ...try {...} finally {buf.release();}
7.2、Pipeline中
因为 pipeline 的存在,一般需要将 ByteBuf 传递给下一个 ChannelHandler,如果在 finally 中 release 了,就失去了传递性(当然,如果在这个 ChannelHandler 内这个 ByteBuf 已完成了它的使命,那么便无须再传递)
基本规则是,谁是最后使用者,谁负责 release,详细分析如下
- 起点,对于 NIO 实现来讲,在 io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read 方法中首次创建 ByteBuf 放入 pipeline(line 163 pipeline.fireChannelRead(byteBuf))
- 入站 ByteBuf 处理原则
- 对原始 ByteBuf 不做处理,调用 ctx.fireChannelRead(msg) 向后传递,这时无须 release
- 将原始 ByteBuf 转换为其它类型的 Java 对象,这时 ByteBuf 就没用了,必须 release
- 如果不调用 ctx.fireChannelRead(msg) 向后传递,那么也必须 release
- 注意各种异常,如果 ByteBuf 没有成功传递到下一个 ChannelHandler,必须 release
- 假设消息一直向后传,那么 TailContext 会负责释放未处理消息(原始的 ByteBuf)
- 出站 ByteBuf 处理原则
- 出站消息最终都会转为 ByteBuf 输出,一直向前传,由 HeadContext flush 后 release
- 异常处理原则
- 有时候不清楚 ByteBuf 被引用了多少次,但又必须彻底释放,可以循环调用 release 直到返回 true

若有收获,就点个赞吧
0 人点赞
