使用缓存可以更快的获取数据,避免频繁的与数据库交互,尤其是在查询越多、缓存命中率越高的情况下,使用缓存的效果就越明显。在Mybatis缓存分为一级缓存和二级缓存,Mybatis常提到的缓存是指二级缓存,一级缓存(也叫本地缓存)默认开启,并且不能控制,因此我们只需学习二级缓存即可。
1. 一级缓存
<!-- sql片段,用于元素复用 --><sql id="blogColumns">bid,title,`state`,content,`issUer`,createTime,readNum,tag</sql><select id="findBlogById" resultType="blog">select <include refid="blogColumns"/> from blog where bid=#{id}</select>
package com.fly.test;
import com.fly.entity.Blog;
import com.fly.mapper.BlogMapper;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.Test;
import java.io.InputStream;
/**
* Mybatis缓存测试类
*/
public class TestCache {
private static SqlSessionFactory sqlSessionFactory;
private static SqlSession sqlSession;
@Test
public void findBlog(){
SqlSession sqlSession=getSqlSession();
BlogMapper mapper1 = sqlSession.getMapper(BlogMapper.class);
Blog blog1 = mapper1.findBlogById(1);
System.out.println(blog1);
//获取一个新的SqlSession
sqlSession=getSqlSession();
BlogMapper mapper2 = sqlSession.getMapper(BlogMapper.class);
Blog blog2 = mapper1.findBlogById(1);
System.out.println(blog2);
}
@Test
public void findBlogCache(){
}
public static SqlSession getSqlSession() {
try {
InputStream stream = Resources.getResourceAsStream("mybatis.xml");
//SqlSessionFactoryBuilder通过获取配置文件信息得到SqlSessionFactory,看到build()就想到了建造者模式
sqlSessionFactory = new SqlSessionFactoryBuilder().build(stream);
sqlSession = sqlSessionFactory.openSession();
stream.close();
return sqlSession;
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
}
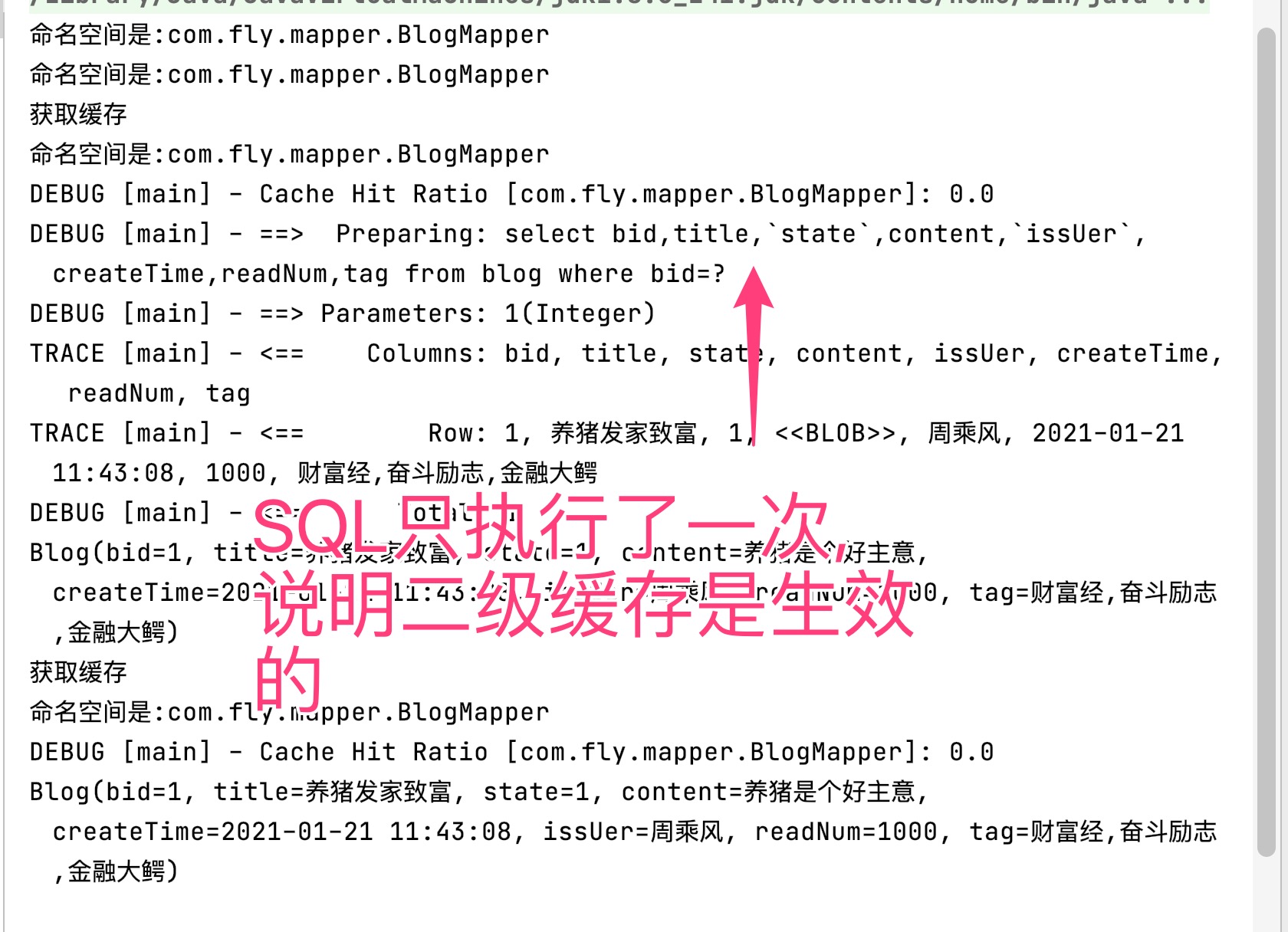
上面是一个很简单的根据博客id查询博客对象的例子,分别使用了两个SqlSession操作,从下图的SQL日志来看,虽然执行了两次查询,但第二次查询并没有执行数据库操作。
这是因为Mybatis的一级缓存存在于SqlSession的生命周期中,在同一个SqlSession中查询时,Mybatis会把执行的的方法名和参数通过算法生成缓存的键值,将键值的查询结果存入一个Map对象中。如果同一个SqlSession中执行的方法和参数完全一致,那么通过算法会生成相同的键值,当Map缓存对象中已经存在改键值时,则会返回缓存中的对象。
**
如果想禁止一级缓存也很简单,只需设置select元素的flushCache属性为true即可,配置flushCache属性为true后,会在查询数据前清空当前的一级缓存,因此该方法每次都会重新从数据库中查询数据。除了设置flushCache属性为true可以清除一级缓存外,任何的insert、update、delete操作也会清空一级缓存。
<!-- flushCache为true表示清除一级缓存,任何的insert、update、delete操作也会清空一级缓存-->
<select id="findBlogById" resultType="blog" flushCache="true">
select <include refid="blogColumns"/> from blog where bid=#{id}
</select>
2. 二级缓存
使用Mybatis二级缓存前,必须在Mybatis全局配置文件开启二级缓存的全局开关,如果没有启用二级缓存全局配置,即使后面有二级缓存的配置也是无效的。启用二级缓存全局配置很简单,settings中有一个参数cacheEnabled,此属性用于设置是否开启全局二级缓存,默认值为true,初始状态为启用状态。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
</configuration>
Mybatis的二级缓存是和命名空间绑定的,即二级缓存需要配置在Mapper.xml映射文件中,或者配置在Mapper java接口中。在映射文件中,命名空间就是XML根节点mapper的namespace属性。在Mapper接口中,命名空间就是接口的全限定名称。
2.1 在Mapper.xml中配置缓存
在保证二级缓存全局配置开启的情况下,只需在Mapper映射文件使用
(1).Mapper映射文件所有SELECT语句将会被缓存。
(2).Mapper映射文件中所有INSERT、UPDATE、DELETE语句将会刷新缓存。
(3).缓存会使用Least Recently Used(LRU,最近最小使用)算法来收回。
(4).根据时间表(如no Flush Interval,没有刷新间隔时间),缓存不会以任何时间顺序来刷新。
(5).缓存会存储集合或对象(无论查询方法返回什么类型的值)的1024个引用。
(6).缓存会被视为read/write(可读/可写)的,意味着对象检索不是共享的,而且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。
默认二级缓存配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.fly.mapper.BlogMapper">
<cache/>
</mapper>
注意:缓存只作用于 cache 标签所在的映射文件中的语句。如果你混合使用 Java API 和 XML 映射文件,在共用接口中的语句将不会被默认缓存。你需要使用 @CacheNamespaceRef 注解指定缓存作用域。
cache元素的属性如下:
type:type指定自定义缓存的全类名,自定义缓存需要实现Mybatis提供的Cache接口。
eviction:缓存的回收策略,有如下4种,默认LRU。
- LRU:最近最少使用,移除最长时间不被使用的对象
- FIFO - 先进先出,按对象进入缓存的顺序来移除它们
- SOFT - 软引用,移除基于垃圾回收器状态和软引用规则的对象
- WEAK - 弱引用,更积极地移除基于垃圾收集器和弱引用规则的对象
flushInterval:缓存刷新间隔。此属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size:引用数目。此属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
cache高级配置例子,下面例子表示创建了一个 FIFO 缓存,每隔 60 秒刷新,最多可以存储结果对象或列表的 512 个引用,而且返回的对象被认为是只读的,因此对它们进行修改可能会在不同线程中的调用者产生冲突。
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
注意:二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。
2.2 使用注解配置二级缓存
Mybatis除了支持在Mapper映射文件中配置二级缓存,也提供了注解形式的方式配置二级缓存,通过@CacheNamespace注解配置二级缓存。
@CacheNamespace(
eviction = LruCache.class,
flushInterval = 60000,
size = 1024,
readWrite = true
)
public interface BlogMapper {
}
注意:如果Mapper映射文件配置了二级缓存并且Mapper接口也使用@CacheNamespace配置了二级缓存,那么会出现如下错误:
Cause: org.apache.ibatis.builder.BuilderException: Error parsing SQL Mapper Configuration. Cause: java.lang.IllegalArgumentException: Caches collection already contains value for com.fly.mapper.BlogMapper
这是因为Mapper接口和对应映射文件的命名空间是相同的,两种方式只能使用其中一种,解决方法如下:
(1).使用cache元素配置二级缓存,使用@CacheNamespaceRef引用对应命名空间的二级缓存。例子如下:
/*引用命名空间为com.fly.mapper.BlogMapper二级缓存*/
@CacheNamespaceRef(BlogMapper.class)
public interface BlogMapper {}
(2).使用@CacheNamespace注解配置二级缓存,删除映射文件的二级缓存即可
2.3 cache-ref
如果想要在多个命名空间中共享相同的缓存配置和实例。要实现这种需求,你可以使用 cache-ref 元素来引用另一个缓存。
<cache-ref namespace="com.fly.mapper.BlogMapper"/>
也可以使用@CacheNamespaceRef注解引入其他缓存,作用跟cache-ref元素是一样的。
/*引用命名空间为com.fly.mapper.BlogMapper二级缓存*/
@CacheNamespaceRef(BlogMapper.class)
public interface BlogMapper {}
3.自定义缓存
在Mybatis自定义缓存只需实现Mybatis提供的Cache接口即可,通过Cache接口提供几个方法即可实现缓存功能,例子如下:
package com.fly.cache;
import org.apache.ibatis.cache.Cache;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class MyCache implements Cache {
private String id;
//定义一个缓存容器
private final ConcurrentHashMap<Object,Object> cacheMap=new ConcurrentHashMap<>();
//声明可重入读写锁
private ReadWriteLock lock = new ReentrantReadWriteLock();
public MyCache(String id){
this.id=id;
}
/**
* getId用于获取关联的命名空间
* @return
*/
@Override
public String getId() {
System.out.println("命名空间是:"+this.id);
return id;
}
/**
* 添加缓存
* @param key
* @param value
*/
@Override
public void putObject(Object key, Object value) {
System.out.println("key:"+key);
System.out.println("value:"+value);
cacheMap.put(key,value);
}
/**
* 根据缓存键获取对应的值
* @param key
* @return
*/
@Override
public Object getObject(Object key) {
System.out.println("获取缓存");
if(cacheMap.get(key)!=null){
return cacheMap.get(key);
}
return null;
}
/**
* 根据缓存键删除对应的值
* @param key
* @return
*/
@Override
public Object removeObject(Object key) {
return cacheMap.remove(key);
}
/**
* 清空缓存
*/
@Override
public void clear() {
cacheMap.clear();
}
/**
* 获取缓存的长度
* @return
*/
@Override
public int getSize() {
return cacheMap.size();
}
/**
* 获取读写锁
* @return
*/
@Override
public ReadWriteLock getReadWriteLock() {
return lock;
}
}
然后指定Mapper映射文件的cache元素的type属性为我们自定义缓存类的类全限定名。
<cache type="com.fly.cache.MyCache"/>
测试代码:
/**
* 测试二级缓存和自定义二级缓存
*/
@Test
public void findBlogCache(){
SqlSession sqlSession=getSqlSession();
BlogMapper mapper1 = sqlSession.getMapper(BlogMapper.class);
System.out.println(mapper1.findBlogById(1));
System.out.println(mapper1.findBlogById(1));
}
4.集成第三方缓存
4.1 Mybatis集成EhCache缓存
EhCache是一个纯粹的Java进程内的缓存框架,具有快速、简洁等特点,Ehcache特征如下:
- 快速、简单、多种缓存策略。
- 缓存数据有内存和磁盘两级,无须担心容量问题,缓存数据会在虚拟机重启过程中写入磁盘。
- 可以通过RMI(远程方法通信)、可插入API等方式进行分布式缓存。
- 具有缓存和缓存管理器的侦听接口。
- 支持多缓存管理器实例以及一个实例的多个缓存区域。
Mybatis也整合了Ehcache依赖包,pom.xml文件如下:
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-ehcache</artifactId>
<version>1.2.1</version>
</dependency>
配置EhCache,在项目文件的src/main/resources下新建EhCache配置文件,名为ehcache.xml。
5.使用二级缓存产生的问题
使用二级缓存也会存在一些弊端,在连表查询情况二级缓存可能会造成脏数据。例如下面的例子:
sql语句
CREATE table userRole(
id int not null primary key auto_increment,
roleName varchar(25) not null comment '角色名称',
isAdmin tinyint not null comment '是否是超级管理员,0是1不是',
powerLevel int not null comment '权限级别'
)engine=innodb CHARACTER set=utf8mb4 collate=utf8mb4_general_ci row_format=dynamic comment '角色表';
create table `user`(
id int not null primary key auto_increment,
roleId int not null comment '角色id',
userName varchar(25) not null comment '用户名',
sex tinyint not null comment '性别',
age tinyint not null comment '年龄',
address VARCHAR(255) comment '地址' ,
FOREIGN key(roleId) references userRole(id)
);
insert into userRole(roleName,isAdmin,powerLevel) values('管理员',0,1),('教师',1,2);
insert into `user`(roleId,userName,sex,age,address) values(1,'z乘风',0,22,'中国'),(2,'老王',0,32,'上海'),
(2,'周依婷',1,25,'东莞');
User.class
package com.fly.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true) //开启链式调用
public class User implements Serializable {
private Integer id;
private String userName;
private Integer roleId;
private Integer age;
private Integer sex;
private String address;
private UserRole userRole;
}
UserRole.class
package com.fly.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.io.Serializable;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true) //开启链式调用
public class UserRole implements Serializable {
private Integer id;
private String roleName;
private Integer isAdmin;
private Integer powerLevel;
}
UserMapper.class
package com.fly.mapper;
import com.fly.entity.User;
import java.util.List;
public interface UserMapper {
List<User> findUserByRoleId(int roleId);
}
UserRoleMapper.class
package com.fly.mapper;
import com.fly.entity.UserRole;
public interface UserRoleMapper {
int updateUserRole(UserRole userRole);
UserRole findUserRoleById(int id);
}
UserMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.fly.mapper.UserMapper">
<resultMap id="userMapper" type="user">
<id property="id" column="id"/>
<result property="userName" column="userName"/>
<result property="age" column="age"/>
<result property="sex" column="sex"/>
<result property="roleId" column="roleId"/>
<result property="address" column="address"/>
<!-- 一对一关系映射 -->
<association property="userRole" javaType="userRole">
<id property="id" column="id"/>
<result property="roleName" column="roleName"/>
<result property="isAdmin" column="isAdmin"/>
<result property="powerLevel" column="powerLevel"/>
</association>
</resultMap>
<cache/>
<select id="findUserByRoleId" resultMap="userMapper">
select u.*,role.* from `user` as u left join
userRole as role on u.roleId=role.id
<where>
<if test="roleId !=null">u.roleId=#{roleId}</if>
</where>
</select>
</mapper>
UserRoleMapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.fly.mapper.UserRoleMapper">
<cache/>
<update id="updateUserRole">
update userRole <set>
<if test="roleName!=null">roleName=#{roleName}</if>
<if test="isAdmin!=null">isAdmin=#{isAdmin}</if>
<if test="powerLevel!=null">powerLevel=#{powerLevel}</if>
</set>
<where>
<if test="id!=null">id=#{id}</if>
</where>
</update>
<select id="findUserRoleById" resultType="userRole">
select * from userRole where id =#{id}
</select>
</mapper>
测试代码:
@Test
public void findUserByRoleId(){
SqlSession sqlSession=getSqlSession();
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
System.out.println("userList1:"+userMapper.findUserByRoleId(2));
UserRoleMapper userRoleMapper = sqlSession.getMapper(UserRoleMapper.class);
UserRole userRole=new UserRole().setRoleName("销售经理").setId(2);
int row=userRoleMapper.updateUserRole(userRole);
System.out.println(row>0?"修改成功":"修改失败");
sqlSession.commit();
System.out.println("userList2:"+userMapper.findUserByRoleId(2));
}
测试结果如下: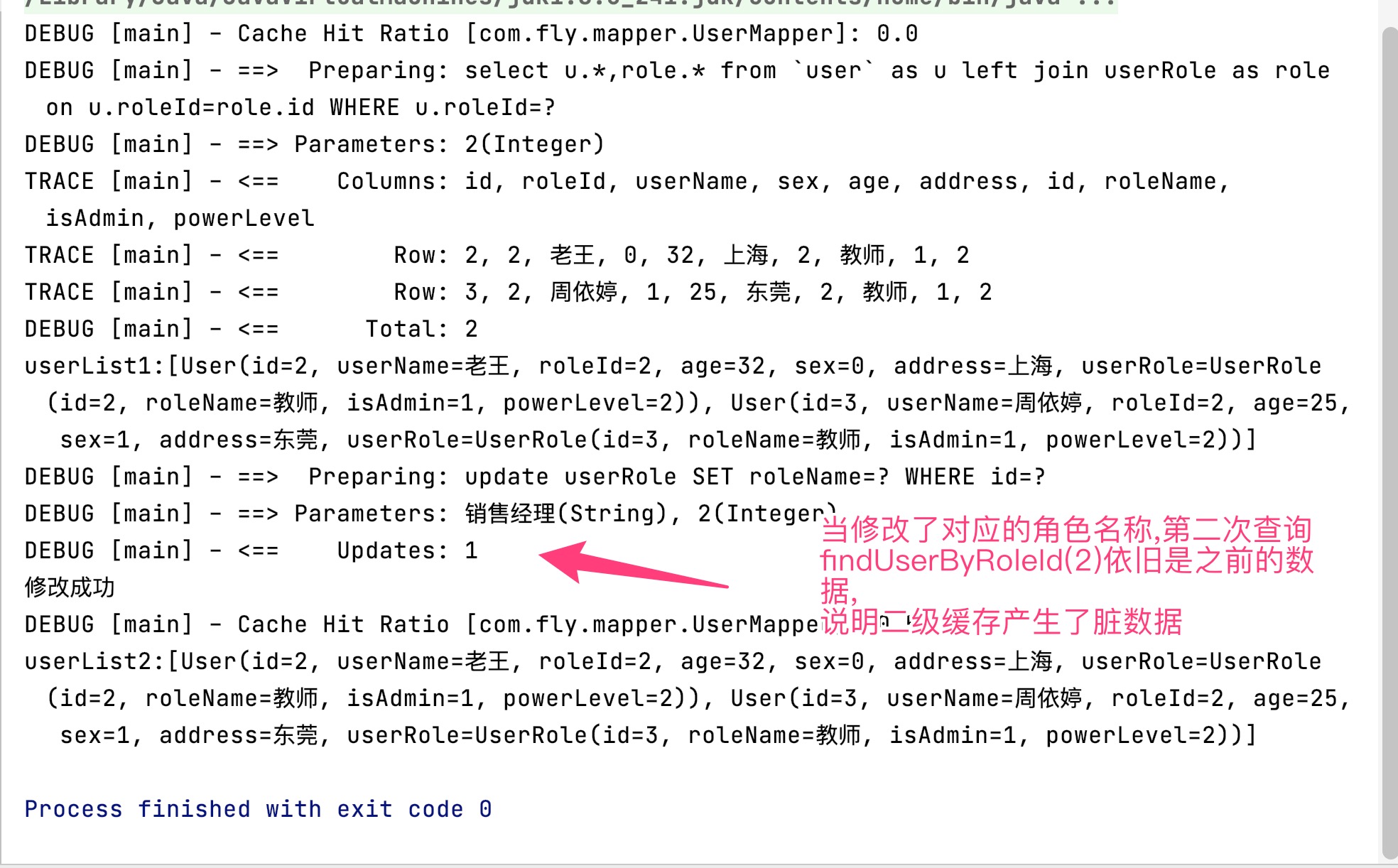
上面测试代码执行了两次findUserByRoleId(2),中间修改了对应的角色名称,但第二次查询的结果跟第一次是一模一样的,说明第二次查询使用了二级缓存,二级缓存在连表情况下产生了脏数据。使用参照缓存即可解决连表情况下产生脏数据,参照缓存即
<!-- UserMapper.xml使用cache-ref引入UserRoleMapper的缓存 -->
<cache-ref namespace="com.fly.mapper.UserRoleMapper"/>
再次测试效果如下:
从上面效果图来看,第二次调用findUserByRoleId(2)并没有使用二级缓存,而是重新从数据库获取了数据,虽然参照缓存可以解决脏数据的问题,但并不是所有的关联查询都可以这样解决,如果有几十张表甚至所有表都以不同的关联关系存在于各自的映射文件中,使用参照缓存的显然没有意义。
二级缓存的应用场景:
(1).适用于查询多,增、删、改少的情况下
(2).适用于单表查询,多表查询会出现脏数据,单表可以避免脏数据。
(3).多表查询情况下可设置select元素的flushCache属性为true,每次查询都会刷新二级缓存。
(4).在控制层添加缓存,访问缓存的顺序为控制层缓存->Mybatis缓存。

若有收获,就点个赞吧
0 人点赞
