id(s) #读取变量指定的值的内存地址
type(s) #查看变量或者值的类型
l=[‘a’,’b’,x] # l=[‘a’的内存地址,’b’的内存地址,10的内存地址]
age=input(“请输入您的账号:”) #接收用户输入
运算符
# print(10 / 3) # 结果带小数# print(10 // 3) # **只保留整数部分**# print(10 % 3) # **取模、取余数**# print(10 ** 3) # 次方age=input("请输入您的账号:") #接收用户输入
字符串格式化输出:
%
res="my name is %s,my age is %s" %('egon','18')res="my name is %s" %"egon"%s 可以接受任意类型(字典,元组等)print('my age is %d' %18) # %d只能接收intLOG_PATH = r'%s/log/user.log' %BASE_DIR #r'字符串'使用字符串源意
str.format
#兼容性好
res='我的名字是{} 我的年龄是{}'.format('egon',18)res='我的名字是 {0}{0}{0} 我的年龄是 {1}{1}'.format('egon',18)# 打破位置的限制,按照key=value传值res="我的名字是 {name} 我的年龄是 {age}".format(age=18,name='egon')
填充与格式化
2.4 填充与格式化# 先取到值,然后在冒号后设定填充格式:[填充字符][对齐方式][宽度]# *<10:左对齐,总共10个字符,不够的用*号填充print('{0:*<10}'.format('开始执行')) # 开始执行******# *>10:右对齐,总共10个字符,不够的用*号填充print('{0:*>10}'.format('开始执行')) # ******开始执行# *^10:居中显示,总共10个字符,不够的用*号填充print('{0:*^10}'.format('开始执行')) # ***开始执行***
精度与进制
print('{salary:.3f}'.format(salary=1232132.12351)) #精确到小数点后3位,四舍五入,结果为:1232132.124print('{0:b}'.format(123)) # 转成二进制,结果为:1111011print('{0:o}'.format(9)) # 转成八进制,结果为:11print('{0:x}'.format(15)) # 转成十六进制,结果为:fprint('{0:,}'.format(99812939393931)) # 千分位格式化,结果为:99,812,939,393,931
f
#f:python3.5以后才推出
x = input('your name: ')y = input('your age: ')res = f'我的名字是{x} 我的年龄是{y}'print(res)# 了解f的新用法:{}内的字符串可以被当做表达式运行# res=f'{10+3}'# print(res)
字符串转二进制
data = 'hello world'# 字符串转二进制data = bytes(data,encoding='utf-8')print(data)# 二进制转字符串data = str(data,encoding='utf-8')print(data)
解压赋值
# 引入*,可以帮助我们取两头的值,无法取中间的值# 取前三个值# x,y,z,*_=salaries=[111,222,333,444,555] # *会将没有对应关系的值存成列表然后赋值给紧跟其后的那个变量名,此处为_# print(x,y,z)# print(_)# 取后三个值# *_,x,y,z=salaries=[111,222,333,444,555]# print(x,y,z)# x,*_,y,z=salaries=[111,222,333,444,555]# print(x,y,z)# salaries=[111,222,333,444,555]# _,*middle,_=salaries# print(middle)# 解压字典默认解压出来的是字典的keyx,y,z=dic={'a':1,'b':2,'c':3}print(x,y,z)
深浅拷贝
浅拷贝
# 3.1 浅copy:是把原列表第一层的内存地址不加区分完全copy一份给新列表list1=['egon','lxx',[1,2]]list3=list1.copy()
深拷贝
import copylist1=['egon','lxx',[1,2]]list3=copy.deepcopy(list1)#深拷贝:递归将列表每一层指向的内存都创建新的
while循环
# 纯计算无io的死讯会导致致命的效率问题;无io会让cpu无等待# while True:# 1+1#退出循环的2种方式# 方式一:将条件改为False,等到下次循环判断条件时才会生效# tag=True# while tag:# inp_name=input('请输入您的账号:')# inp_pwd=input('请输入您的密码:')## if inp_name == username and inp_pwd == password:# print('登录成功')# tag = False # 之后的代码还会运行,下次循环判断条件时才生效# else:# print('账号名或密码错误')## # print('====end====')# 方式二:break,只要运行到break就会立刻终止本层循环# while True:# inp_name=input('请输入您的账号:')# inp_pwd=input('请输入您的密码:')## if inp_name == username and inp_pwd == password:# print('登录成功')# break # 立刻终止本层循环# else:# print('账号名或密码错误')## # print('====end====')# 7、while循环嵌套与结束'''tag=Truewhile tag:while tag:while tag:tag=False# 每一层都必须配一个breakwhile True:while True:while True:breakbreakbreak'''# 8、while +continue:结束本次循环,直接进入下一次# 强调:在continue之后添加同级代码毫无意义,因为永远无法运行# count=0# while count < 6:# if count == 4:# count+=1# continue# # count+=1 # 错误# print(count)# count+=1# 9、while +else:针对break# count=0# while count < 6:# if count == 4:# count+=1# continue# print(count)# count+=1# else:# print('else包含的代码会在while循环结束后,并且while循环是在没有被break打断的情况下正常结束的,才不会运行')# count=0# while count < 6:# if count == 4:# break# print(count)# count+=1# else:# print('======>')
应用案例
# 应用案列:# 版本1:# count=0# tag=True# while tag:# if count == 3:# print('输错三次退出')# break# inp_name=input('请输入您的账号:')# inp_pwd=input('请输入您的密码:')## if inp_name == username and inp_pwd == password:# print('登录成功')# while tag:# cmd=input("输入命令>: ")# if cmd == 'q':# tag=False# else:# print('命令{x}正在运行'.format(x=cmd))# else:# print('账号名或密码错误')# count+=1# 版本2:优化count=0while count < 3:inp_name=input('请输入您的账号:')inp_pwd=input('请输入您的密码:')if inp_name == username and inp_pwd == password:print('登录成功')while True:cmd=input("输入命令>: ")if cmd == 'q': # 整个程序结束,退出所有while循环breakelse:print('命令{x}正在运行'.format(x=cmd))breakelse:print('账号名或密码错误')count+=1else:print('输错3次,退出')
for循环
# 简单版# l = ['alex_dsb', 'lxx_dsb', 'egon_nb']# for x in l: # x='lxx_dsb'# print(x)# 复杂版:# l = ['alex_dsb', 'lxx_dsb', 'egon_nb']# i=0# while i < 3:# print(l[i])# i+=1# for i in range(30):# print('===>')# 五:for+continue# for i in range(6): # 0 1 2 3 4 5# if i == 4:# continue# print(i)# 六:for循环嵌套:外层循环循环一次,内层循环需要完整的循环完毕# for i in range(3):# print('外层循环-->', i)# for j in range(5):# print('内层-->', j)# 补充:终止for循环只有break一种方案
进制转换
bin(11) #10进制转2进制oct(11) #10进制转8进制hex(11) #10进制转16进制# 2.2.2 其他制转成其十进制# 二进制->10进制# print(int('0b1011',2)) # 11# 二进制->8进制# print(int('0o13',8)) # 11# 二进制->16进制# print(int('0xb',16)) # 11
字符串内置方法
# 4.1.2、切片:索引的拓展应用,从一个大字符串中拷贝出一个子字符串msg='hello world'# 顾头不顾尾# res=msg[0:5] #x# 步长# res=msg[0:5:2] # 0 2 4msg='hello world'# res=msg[:] # res=msg[0:11]# print(res)# res=msg[::-1] # 把字符串倒过来# print(res)# 4.1.3、长度len# msg='hello world'# print(len(msg))# 4.1.4、成员运算in和not in# 判断一个子字符串是否存在于一个大字符串中# print("alex" in "alex is sb")# print("alex" not in "alex is sb")# 4.1.5、移除字符串左右两侧的符号strip# 默认去掉的空格# msg=' egon '# res=msg.strip()# 默认去掉的空格# msg='****egon****'# print(msg.strip('*'))# msg='**/*=-**egon**-=()**'# print(msg.strip('*/-=()'))# 4.1.6、切分split:把一个字符串按照某种分隔符进行切分,得到一个列表# # 默认分隔符是空格# info='egon 18 male'# res=info.split()# print(res)# # 指定分隔符# info='egon:18:male'# res=info.split(':')# 指定分隔次数(了解)# info='egon:18:male'# res=info.split(':',1)# 4.1.7、循环# info='egon:18:male'# for x in info:# print(x)# 4.2 需要掌握#4.2.1、strip,lstrip,rstrip# msg='***egon****'# print(msg.strip('*'))# print(msg.lstrip('*'))# print(msg.rstrip('*'))#4.2.2、lower,upper# msg='AbbbCCCC'# print(msg.lower())# print(msg.upper())#4.2.3、startswith,endswith# print("alex is sb".startswith("alex"))# print("alex is sb".endswith('sb'))#4.2.4、format#4.2.5、split,rsplit:将字符串切成列表# info="egon:18:male"# print(info.split(':',1)) # ["egon","18:male"]# print(info.rsplit(':',1)) # ["egon:18","male"]#4.2.6、join: 把列表拼接成字符串# l=['egon', '18', 'male']# res=l[0]+":"+l[1]+":"+l[2]# res=":".join(l) # 按照某个分隔符号,把元素全为字符串的列表拼接成一个大字符串# print(res)# l=[1,"2",'aaa']# ":".join(l)#4.2.7、replace# msg="you can you up no can no bb"# print(msg.replace("you","YOU",))# print(msg.replace("you","YOU",1))#4.2.8、isdigit# 判断字符串是否由纯数字组成# print('123'.isdigit())# print('12.3'.isdigit())# age=input('请输入你的年龄:').strip()# if age.isdigit():# age=int(age) # int("abbab")# if age > 18:# print('猜大了')# elif age < 18:# print('猜小了')# else:# print('才最了')# else:# print('必须输入数字,傻子')# 4.3了解#4.3.1、find,rfind,index,rindex,countmsg='hello egon hahaha'# 找到返回起始索引# print(msg.find('e')) # 返回要查找的字符串在大字符串中的起始索引# print(msg.find('egon'))# print(msg.index('e'))# print(msg.index('egon'))# 找不到# print(msg.find('xxx')) # 返回-1,代表找不到# print(msg.index('xxx')) # 抛出异常# msg='hello egon hahaha egon、 egon'# print(msg.count('egon'))#4.3.2、center,ljust,rjust,zfill# print('egon'.center(50,'*'))# print('egon'.ljust(50,'*'))# print('egon'.rjust(50,'*'))# print('egon'.zfill(10))#4.3.3、expandtabs# msg='hello\tworld'# print(msg.expandtabs(2)) # 设置制表符代表的空格数为2#4.3.4、captalize,swapcase,title# print("hello world egon".capitalize())# print("Hello WorLd EGon".swapcase())# print("hello world egon".title())#4.3.5、is数字系列#4.3.6、is其他# print('abc'.islower())# print('ABC'.isupper())# print('Hello World'.istitle())# print('123123aadsf'.isalnum()) # 字符串由字母或数字组成结果为True# print('ad'.isalpha()) # 字符串由由字母组成结果为True# print(' '.isspace()) # 字符串由空格组成结果为True# print('print'.isidentifier())# print('age_of_egon'.isidentifier())# print('1age_of_egon'.isidentifier())num1=b'4' #bytesnum2=u'4' #unicode,python3中无需加u就是unicodenum3='四' #中文数字num4='Ⅳ' #罗马数字# isdigit只能识别:num1、num2# print(num1.isdigit()) # True# print(num2.isdigit()) # True# print(num3.isdigit()) # False# print(num4.isdigit()) # False# isnumberic可以识别:num2、num3、num4# print(num2.isnumeric()) # True# print(num3.isnumeric()) # True# print(num4.isnumeric()) # True# isdecimal只能识别:num2print(num2.isdecimal()) # Trueprint(num3.isdecimal()) # Falseprint(num4.isdecimal()) # False
列表内置方法
# 1、作用:按位置存放多个值# 2、定义# l=[1,1.2,'a'] # l=list([1,1.2,'a'])# print(type(l))# 3、类型转换: 但凡能够被for循环遍历的类型都可以当做参数传给list()转成列表# res=list('hello')# print(res)## res=list({'k1':111,'k2':222,'k3':3333})# print(res)# 4、内置方法# 优先掌握的操作:# 1、按索引存取值(正向存取+反向存取):即可以取也可以改# l=[111,'egon','hello']# 正向取# print(l[0])# 反向取# print(l[-1])# 可以取也可以改:索引存在则修改对应的值# l[0]=222# print(l)# 无论是取值操作还是赋值操作:索引不存在则报错# l[3]=333# 2、切片(顾头不顾尾,步长)l = [111, 'egon', 'hello', 'a', 'b', 'c', 'd', [1, 2, 3]]# print(l[0:3])# print(l[0:5:2]) # 0 2 4# print(l[0:len(l)])# print(l[:])# new_l=l[:] # 切片等同于拷贝行为,而且相当于浅copy# print(id(l))# print(id(new_l))# l[-1][0]=1111111# print(l)# print(new_l)# print(l[::-1])# msg1='hello:egon:<>:18[]==123'# msg2=msg1[:]# print(msg1,id(msg1))# print(msg2,id(msg2))# 3、长度# print(len([1, 2, 3]))# 4、成员运算in和not in# print('aaa' in ['aaa', 1, 2])# print(1 in ['aaa', 1, 2])# 5、往列表中添加值# 5.1 追加# l=[111,'egon','hello']# l.append(3333)# l.append(4444)# print(l)# 5.2、插入值# l=[111,'egon','hello']# l.insert(0,'alex')# print(l)# 5.3、extend添加值# new_l=[1,2,3]# l=[111,'egon','hello']# l.append(new_l)# print(l)# 代码实现# for item in new_l:# l.append(item)# print(l)# extend实现了上述代码# l.extend(new_l)# l.extend('abc')# print(l)# 7、删除# 方式一:通用的删除方法,只是单纯的删除、没有返回值# l = [111, 'egon', 'hello']# del l[1]# x =del l[1] # 抛出异常,不支持赋值语法# print(l)# 方式二:l.pop()根据索引删除,会返回删除的值# l = [111, 'egon', 'hello']# l.pop() # 不指定索引默认删除最后一个# l.pop()# print(l)# res=l.pop(1)# print(l)# print(res)# 方式三:l.remove()根据元素删除,返回None# l = [111, 'egon', [1,2,3],'hello']# l.remove([1,2,3])# print(l)# res=l.remove('egon')# print(res) # None# 8、循环# l=[1,'aaa','bbb']# for x in l:# l.pop(1)# print(x)# 需要掌握操作l = [1, 'aaa', 'bbb','aaa','aaa']# 1、l.count()# print(l.count('aaa'))# 2、l.index()# print(l.index('aaa'))# print(l.index('aaaaaaaaa')) # 找不到报错# 3、l.clear()# l.clear()# print(l)# 4、l.reverse():不是排序,就是将列表倒过来# l = [1, 'egon','alex','lxx']# l.reverse()# print(l)# 5、l.sort(): 列表内元素必须是同种类型才可以排序# l=[11,-3,9,2,3.1]# l.sort() # 默认从小到大排,称之为升序# l.sort(reverse=True) # 从大到小排,设置为降序# print(l)# l=[11,'a',12]# l.sort()# l=['c','e','a']# l.sort()# print(l)# 了解:字符串可以比大小,按照对应的位置的字符依次pk# 字符串的大小是按照ASCI码表的先后顺序加以区别,表中排在后面的字符大于前面的# print('a'>'b')# print('abz'>'abcdefg')# 了解:列表也可以比大小,原理同字符串一样,但是对应位置的元素必须是同种类型# l1=[1,'abc','zaa']# l2=[1,'abc','zb']## print(l1 < l2)# 补充# 1、队列:FIFO,先进先出# l=[]# # 入队操作# l.append('first')# l.append('second')# l.append('third')## print(l)# # 出队操作# print(l.pop(0))# print(l.pop(0))# print(l.pop(0))# 2、堆栈:LIFO,后进先出l=[]# 入栈操作l.append('first')l.append('second')l.append('third')print(l)# 出队操作print(l.pop())print(l.pop())print(l.pop())
元组内置方法
# 元组就是"一个不可变的列表"#1、作用:按照索引/位置存放多个值,只用于读不用于改#2、定义:()内用逗号分隔开多个任意类型的元素# t=(1,1.3,'aa') # t=tuple((1,1.3,'aa'))# print(t,type(t))# x=(10) # 单独一个括号代表包含的意思# print(x,type(x))# t=(10,) # 如果元组中只有一个元素,必须加逗号# print(t,type(t))# t=(1,1.3,'aa') # t=(0->值1的内存地址,1->值1.3的内存地址,2->值'aaa'的内存地址,)# t[0]=11111# t=(1,[11,22]) # t=(0->值1的内存地址,1->值[1,2]的内存地址,)# print(id(t[0]),id(t[1]))# # t[0]=111111111 # 不能改# # t[1]=222222222 # 不能改## t[1][0]=11111111111111111# # print(t)# print(id(t[0]),id(t[1]))#3、类型转换# print(tuple('hello'))# print(tuple([1,2,3]))# print(tuple({'a1':111,'a2':333}))#4、内置方法#优先掌握的操作:#1、按索引取值(正向取+反向取):只能取# t=('aa','bbb','cc')# print(t[0])# print(t[-1])#2、切片(顾头不顾尾,步长)# t=('aa','bbb','cc','dd','eee')# print(t[0:3])# print(t[::-1])#3、长度# t=('aa','bbb','cc','dd','eee')# print(len(t))#4、成员运算in和not in# print('aa' in t)#5、循环# for x in t:# print(x)#6、t=(2,3,111,111,111,111)# print(t.index(111))# print(t.index(1111111111))print(t.count(111))
字典内置方法
#1、作用#2、定义:{}内用逗号分隔开多个key:value,其中value可以使任意类型,但是# key必须是不可变类型,且不能重复# 造字典的方式一:# d={'k1':111,(1,2,3):222} # d=dict(...)# print(d['k1'])# print(d[(1,2,3)])# print(type(d))# d={} # 默认定义出来的是空字典# print(d,type(d))# 造字典的方式二:# d=dict(x=1,y=2,z=3)# print(d,type(d))#3、数据类型转换# info=[# ['name','egon'],# ('age',18),# ['gender','male']# ]# # d={}# # for k,v in info: # k,v=['name','egon'],# # d[k]=v# # print(d)## 造字典的方式三:# res=dict(info) # 一行代码搞定上述for循环的工作# print(res)# 造字典的方式四:快速初始化一个字典# keys=['name','age','gender']# # d={}# # for k in keys:# # d[k]=None# # print(d)# d={}.fromkeys(keys,None) # 一行代码搞定上述for循环的工作# print(d)#4、内置方法#优先掌握的操作:#1、按key存取值:可存可取# d={'k1':111}# 针对赋值操作:key存在,则修改# d['k1']=222# 针对赋值操作:key不存在,则创建新值# d['k2']=3333# print(d)#2、长度len# d={'k1':111,'k2':2222,'k1':3333,'k1':4444}# print(d)# print(len(d))#3、成员运算in和not in:根据key# d={'k1':111,'k2':2222}# print('k1' in d)# print(111 in d)#4、删除d={'k1':111,'k2':2222}# 4.1 通用删除# del d['k1']# print(d)# 4.2 pop删除:根据key删除元素,返回删除key对应的那个value值# res=d.pop('k2')# print(d)# print(res)# 4.3 popitem删除:随机删除,返回元组(删除的key,删除的value)# res=d.popitem()# print(d)# print(res)#5、键keys(),值values(),键值对items() =>在python3中得到的是老母鸡d={'k1':111,'k2':2222}'''在python2中>>> d={'k1':111,'k2':2222}>>>>>> d.keys()#6、循环['k2', 'k1']>>> d.values()[2222, 111]>>> d.items()[('k2', 2222), ('k1', 111)]>>> dict(d.items()){'k2': 2222, 'k1': 111}>>>'''#6、for循环# for k in d.keys():# print(k)## for k in d:# print(k)# for v in d.values():# print(v)# for k,v in d.items():# print(k,v)# print(list(d.keys()))# print(list(d.values()))# print(list(d.items()))#需要掌握的内置方法d={'k1':111}#1、d.clear()#2、d.update()# d.update({'k2':222,'k3':333,'k1':111111111111111})# print(d)#3、d.get() :根据key取值,容错性好# print(d['k2']) # key不存在则报错# print(d.get('k1')) # 111# print(d.get('k2')) # key不存在不报错,返回None#4、d.setdefault()# info={}# if 'name' in info:# ... # 等同于pass# else:# info['name']='egon'# print(info)# 4.1 如果key有则不添加,返回字典中key对应的值info={'name':'egon'}res=info.setdefault('name','egon')# print(info)print(res)# 4.2 如果key没有则添加,返回字典中key对应的值info={}res=info.setdefault('name','egon')# print(info)print(res)
集合内置方法
# 1、作用# 1.1 关系运算# friends1 = ["zero","kevin","jason","egon"]# friends2 = ["Jy","ricky","jason","egon"]# l=[]# for x in friends1:# if x in friends2:# l.append(x)# print(l)# 1.2、去重# 2、定义: 在{}内用逗号分隔开多个元素,多个元素满足以下三个条件# 1. 集合内元素必须为不可变类型# 2. 集合内元素无序# 3. 集合内元素没有重复# s={1,2} # s=set({1,2})# s={1,[1,2]} # 集合内元素必须为不可变类型# s={1,'a','z','b',4,7} # 集合内元素无序# s={1,1,1,1,1,1,'a','b'} # 集合内元素没有重复# print(s)# 了解# s={} # 默认是空字典# print(type(s))# 定义空集合# s=set()# print(s,type(s))# 3、类型转换# set({1,2,3})# res=set('hellolllll')# print(res)# print(set([1,1,1,1,1,1]))# print(set([1,1,1,1,1,1,[11,222]]) # 报错# print(set({'k1':1,'k2':2}))# 4、内置方法# =========================关系运算符=========================friends1 = {"zero","kevin","jason","egon"}friends2 = {"Jy","ricky","jason","egon"}# 4.1 取交集:两者共同的好友# res=friends1 & friends2# print(res)# print(friends1.intersection(friends2))# 4.2 取并集/合集:两者所有的好友# print(friends1 | friends2)# print(friends1.union(friends2))# 4.3 取差集:取friends1独有的好友# print(friends1 - friends2)# print(friends1.difference(friends2))# 取friends2独有的好友# print(friends2 - friends1)# print(friends2.difference(friends1))# 4.4 对称差集: 求两个用户独有的好友们(即去掉共有的好友)# print(friends1 ^ friends2)# print(friends1.symmetric_difference(friends2))# 4.5 父子集:包含的关系# s1={1,2,3}# s2={1,2,4}# 不存在包含关系,下面比较均为False# print(s1 > s2)# print(s1 < s2)# s1={1,2,3}# s2={1,2}# print(s1 > s2) # 当s1大于或等于s2时,才能说是s1是s2他爹# print(s1.issuperset(s2))# print(s2.issubset(s1)) # s2 < s2 =>True# s1={1,2,3}# s2={1,2,3}# print(s1 == s2) # s1与s2互为父子# print(s1.issuperset(s2))# print(s2.issuperset(s1))# =========================去重=========================# 1、只能针对不可变类型去重# print(set([1,1,1,1,2]))# 2、无法保证原来的顺序# l=[1,'a','b','z',1,1,1,2]# l=list(set(l))# print(l)l=[{'name':'lili','age':18,'sex':'male'},{'name':'jack','age':73,'sex':'male'},{'name':'tom','age':20,'sex':'female'},{'name':'lili','age':18,'sex':'male'},{'name':'lili','age':18,'sex':'male'},]new_l=[]for dic in l:if dic not in new_l:new_l.append(dic)# print(new_l)# 其他操作'''# 1.长度>>> s={'a','b','c'}>>> len(s)3# 2.成员运算>>> 'c' in sTrue# 3.循环>>> for item in s:... print(item)...cab'''# 其他内置方法s={1,2,3}# 需要掌握的内置方法1:discard# s.discard(4) # 删除元素不存在do nothing# print(s)# s.remove(4) # 删除元素不存在则报错# 需要掌握的内置方法2:update# 将s没有的元素# s.update({1,3,5})# print(s)# 需要掌握的内置方法3:pop# res=s.pop()# print(res)# 需要掌握的内置方法4:add# s.add(4)# print(s)# 其余方法全为了解res=s.isdisjoint({3,4,5,6}) # 两个集合完全独立、没有共同部分,返回Trueprint(res)# 了解# s.difference_update({3,4,5}) # s=s.difference({3,4,5})# print(s)
编码解码
# coding:utf-8x='上'res=x.encode('gbk') # unicode--->gbk# print(res,type(res))print(res.decode('gbk'))
FIFO/LIFO
1、用列表模拟队列的入队与出队操作,FIFO2、用列表模拟堆栈的入队与出队操作,LIFO
文件操作
x模式
x模式(控制文件操作的模式)-》了解x, 只写模式【不可读;不存在则创建,存在则报错】with open('d.txt', mode='x', encoding='utf-8') as f:f.write('哈哈哈\n')
t模式与b模式
控制文件读写内容的模式t:1、读写都是以字符串(unicode)为单位2、只能针对文本文件3、必须指定字符编码,即必须指定encoding参数b:binary模式1、读写都是以bytes为单位2、可以针对所有文件3、一定不能指定字符编码,即一定不能指定encoding参数总结:1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便2、针对非文本文件(如图片、视频、音频等)只能使用b模式# 错误演示:t模式只能读文本文件# with open(r'爱nmlgb的爱情.mp4',mode='rt') as f:# f.read() # 硬盘的二进制读入内存-》t模式会将读入内存的内容进行decode解码操作# with open(r'test.jpg',mode='rb',encoding='utf-8') as f: #二进制读取,不能写encoding# res=f.read() # 硬盘的二进制读入内存—>b模式下,不做任何转换,直接读入内存# print(res) # bytes类型—》当成二进制# print(type(res))# with open(r'd.txt',mode='rb') as f: #正确# res=f.read() # utf-8的二进制# print(res,type(res))## print(res.decode('utf-8'))# with open(r'd.txt',mode='rt',encoding='utf-8') as f: #正确# res=f.read() # utf-8的二进制->unicode# print(res)# with open(r'e.txt',mode='wb') as f: #正确# f.write('你好hello'.encode('gbk'))# with open(r'f.txt',mode='wb') as f: #正确,这种写入是覆盖写入# f.write('你好hello'.encode('utf-8'))# f.write('哈哈哈'.encode('gbk'))
a模式追加
with open('access.log', mode='at', encoding='utf-8') as f: #w是覆盖写,a是追加写入f.write('20200311111112 yyy转账200w\n')
文件拷贝工具
# 文件拷贝工具src_file=input('源文件路径>>: ').strip()dst_file=input('源文件路径>>: ').strip()with open(r'{}'.format(src_file),mode='rb') as f1,\open(r'{}'.format(dst_file),mode='wb') as f2:# res=f1.read() # 内存占用过大# f2.write(res)for line in f1:f2.write(line)# 循环读取文件# 方式一:自己控制每次读取的数据的数据量# with open(r'test.jpg',mode='rb') as f:# while True:# res=f.read(1024) # 1024# if len(res) == 0:# break# print(len(res))# 方式二:以行为单位读,当一行内容过长时会导致一次性读入内容的数据量过大# with open(r'g.txt',mode='rt',encoding='utf-8') as f:# for line in f:# print(len(line),line)# with open(r'g.txt',mode='rb') as f:# for line in f:# print(line)# with open(r'test.jpg',mode='rb') as f:# for line in f:# print(line)
文件操作其他方法
# 一:读相关操作# 1、readline:一次读一行# 注意readline与readlines区别# with open(r'g.txt',mode='rt',encoding='utf-8') as f:# # res1=f.readline()# # res2=f.readline()# # print(res2)## while True:# line=f.readline()# if len(line) == 0:# break# print(line)# 2、readlines:# with open(r'g.txt',mode='rt',encoding='utf-8') as f:# res=f.readlines()# print(res)# 强调:# f.read()与f.readlines()都是将内容一次性读入内存,如果内容过大会导致内存溢出,若还想将内容全读入内存,# 二:写相关操作# f.writelines():# with open('h.txt',mode='wt',encoding='utf-8') as f:# # f.write('1111\n222\n3333\n')## # l=['11111\n','2222','3333',4444]# l=['11111\n','2222','3333']# # for line in l:# # f.write(line)# f.writelines(l) #一次写多行# with open('h.txt', mode='wb') as f:# # l = [# # '1111aaa1\n'.encode('utf-8'),# # '222bb2'.encode('utf-8'),# # '33eee33'.encode('utf-8')# # ]## # 补充1:如果是纯英文字符,可以直接加前缀b得到bytes类型# # l = [# # b'1111aaa1\n',# # b'222bb2',# # b'33eee33'# # ]## # 补充2:'上'.encode('utf-8') 等同于bytes('上',encoding='utf-8')# l = [# bytes('上啊',encoding='utf-8'),# bytes('冲呀',encoding='utf-8'),# bytes('小垃圾们',encoding='utf-8'),# ]# f.writelines(l)# 3、flush:# with open('h.txt', mode='wt',encoding='utf-8') as f:# f.write('哈')# # f.flush()#flush() 方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。# 4、了解with open('h.txt', mode='wt', encoding='utf-8') as f:print(f.readable())print(f.writable())print(f.encoding)print(f.name)print(f.closed)
f.seek,控制文件指针移动
强调:只有0模式可以在t下使用,1、2必须在b模式下用
# 指针移动的单位都是以bytes/字节为单位# 只有一种情况特殊:# t模式下的read(n),n代表的是字符个数# with open('aaa.txt',mode='rt',encoding='utf-8') as f:# res=f.read(4)# print(res)# f.seek(n,模式):n指的是移动的字节个数# 模式:# 模式0:参照物是文件开头位置# f.seek(9,0)# f.seek(3,0) # 3# 模式1:参照物是当前指针所在位置# f.seek(9,1)# f.seek(3,1) # 12# 模式2:参照物是文件末尾位置,应该倒着移动# f.seek(-9,2) # 3# f.seek(-3,2) # 9# 强调:只有0模式可以在t下使用,1、2必须在b模式下用# f.tell() # 获取文件指针当前位置# 示范# with open('aaa.txt',mode='rb') as f:# f.seek(9,0)# f.seek(3,0) # 3# # print(f.tell())# f.seek(4,0)# res=f.read()# print(res.decode('utf-8'))# with open('aaa.txt',mode='rb') as f:# f.seek(9,1)# f.seek(3,1) # 12# print(f.tell())# with open('aaa.txt',mode='rb') as f:# f.seek(-9,2)# # print(f.tell())# f.seek(-3,2)# # print(f.tell())# print(f.read().decode('utf-8'))
f.seek的应用
import timewith open('access.log', mode='rb') as f:# 1、将指针跳到文件末尾# f.read() # 错误f.seek(0,2) #后面会执行失败while True:line=f.readline()if len(line) == 0:time.sleep(0.3)else:print(line.decode('utf-8'),end='')
文件修改的两种方式
# 文件修改的两种方式# 方式一:文本编辑采用的就是这种方式# 实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件# 优点: 在文件修改过程中同一份数据只有一份# 缺点: 会过多地占用内存# with open('c.txt',mode='rt',encoding='utf-8') as f:# res=f.read()# data=res.replace('alex','dsb')# print(data)## with open('c.txt',mode='wt',encoding='utf-8') as f1:# f1.write(data)# 方式二:import os# 实现思路:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容,修改完后写入临时文件...,删掉原文件,将临时文件重命名原文件名# 优点: 不会占用过多的内存# 缺点: 在文件修改过程中同一份数据存了两份with open('c.txt', mode='rt', encoding='utf-8') as f, \open('.c.txt.swap', mode='wt', encoding='utf-8') as f1:for line in f:f1.write(line.replace('alex', 'dsb'))os.remove('c.txt')os.rename('.c.txt.swap', 'c.txt')f = open('a.txt')res = f.read()print(res)
函数的基本使用
语法:def 函数名(参数1,参数2,...):"""文档描述"""函数体return 值# 定义函数发生的事情# 1、申请内存空间保存函数体代码# 2、将上述内存地址绑定函数名# 3、定义函数不会执行函数体代码,但是会检测函数体语法# 调用函数发生的事情# 1、通过函数名找到函数的内存地址# 2、然后加口号就是在触发函数体代码的执行# print(func)# func()
无参函数
# 形式一:无参函数# def func():# # x# 示范1# def bar(): # bar=函数的内存地址# print('from bar')
有参函数、空函数
# 形式二:有参函数# def func(x,y): # x=1 y=2# print(x,y)# func(1,2)# 形式三:空函数,函数体代码为passdef func(x, y):pass
应用场景
# 三种定义方式各用在何处# 1、无参函数的应用场景# def interactive():# name=input('username>>: ')# age=input('age>>: ')# gender=input('gender>>: ')# msg='名字:{} 年龄:{} 性别'.format(name,age,gender)# print(msg)## interactive()# 2、有参函数的应用场景# def add(x,y): # 参数-》原材料# # x=20# # y=30# res=x + y# # print(res)# return res # 返回值-》产品## # add(10,2)# res=add(20,30)# print(res)# 3、空函数的应用场景# def auth_user():# """user authentication function"""# pass
调用场景
# 二、调用函数# 1、语句的形式:只加括号调用函数# interactive()# add(1,2)# 2、表达式形式:# def add(x,y): # 参数-》原材料# res=x + y# return res # 返回值-》产品# 赋值表达式# res=add(1,2)# print(res)# 数学表达式# res=add(1,2)*10# print(res)# 3、函数调用可以当做参数# res=add(add(1,2),10)# print(res)
函数返回值
# 三、函数返回值# return是函数结束的标志,即函数体代码一旦运行到return会立刻# 终止函数的运行,并且会将return后的值当做本次运行的结果返回:# 1、返回None:函数体内没有return# return# return None## 2、返回一个值:return 值# def func():# return 10## res=func()# print(res)# 3、返回多个值:用逗号分隔开多个值,会被return返回成元组def func():return 10, 'aa', [1, 2]res = func()print(res, type(res))
函数参数
形参与实参
# 一 形参与实参介绍# 形参:在定义函数阶段定义的参数称之为形式参数,简称形参,相当于变量名def func(x, y): # x=1,y=2print(x, y)# 实参:在调用函数阶段传入的值称之为实际参数,简称实参,相当于变量值# func(1,2)# 形参与实参的关系:# 1、在调用阶段,实参(变量值)会绑定给形参(变量名)# 2、这种绑定关系只能在函数体内使用# 3、实参与形参的绑定关系在函数调用时生效,函数调用结束后解除绑定关系# 实参是传入的值,但值可以是以下形式# 形式一:# func(1,2)# 形式二:# a=1# b=2# func(a,b)# 形式三:# func(int('1'),2)# func(func1(1,2,),func2(2,3),333)
位置参数
# 2.1 位置参数:按照从左到右的顺序依次定义的参数称之为位置参数# 位置形参:在函数定义阶段,按照从左到右的顺序直接定义的"变量名"# 特点:必须被传值,多一个不行少一个也不行# def func(x,y):# print(x,y)# func(1,2,3)# func(1,)# 位置实参:在函数调用阶段, 按照从左到有的顺序依次传入的值# 特点:按照顺序与形参一一对应# func(1,2)# func(2,1)
关键字参数
# 2.2 关键字参数# 关键字实参:在函数调用阶段,按照key=value的形式传入的值# 特点:指名道姓给某个形参传值,可以完全不参照顺序# def func(x,y):# print(x,y)# func(y=2,x=1)# func(1,2)# 混合使用,强调# 1、位置实参必须放在关键字实参前# func(1,y=2)# func(y=2,1)# 2、不能能为同一个形参重复传值# func(1,y=2,x=3)# func(1,2,x=3,y=4)
默认参数
# 2.3 默认参数# 默认形参:在定义函数阶段,就已经被赋值的形参,称之为默认参数# 特点:在定义阶段就已经被赋值,意味着在调用阶段可以不用为其赋值# def func(x,y=3):# print(x,y)## # func(x=1)# func(x=1,y=44444)# def register(name,age,gender='男'):# print(name,age,gender)## register('三炮',18)# register('没炮',19,'女')强调:# 位置形参与默认形参混用,强调:# 1、位置形参必须在默认形参的左边# def func(y=2,x): #错误# pass# 2、默认参数的值是在函数定义阶段被赋值的,准确地说被赋予的是值的内存地址# 示范1:# m=2# def func(x,y=m): # y=>2的内存地址# print(x,y# m=3333333333333333333# func(1)# 示范2:# m = [111111, ]# def func(x, y=m): # y=>[111111, ]的内存地址# print(x, y)# m.append(3333333)# func(1)# 3、虽然默认值可以被指定为任意数据类型,但是不推荐使用可变类型# 函数最理想的状态:函数的调用只跟函数本身有关系,不外界代码的影响m = [111111, ]def func(x, y=m):print(x, y)m.append(3333333)m.append(444444)m.append(5555)func(1)func(2)func(3)
可变长度的位置参数*
# 2.4 可变长度的参数(*与**的用法)# 可变长度指的是在调用函数时,传入的值(实参)的个数不固定# 而实参是用来为形参赋值的,所以对应着,针对溢出的实参必须有对应的形参来接收# 2.4.1 可变长度的位置参数# I:*形参名:用来接收溢出的位置实参,溢出的位置实参会被*保存成元组的格式然后赋值紧跟其后的形参名# *后跟的可以是任意名字,但是约定俗成应该是args# def func(x,y,*z): # z =(3,4,5,6)# print(x,y,z)# func(1,2,3,4,5,6)# def my_sum(*args):# res=0# for item in args:# res+=item# return res## res=my_sum(1,2,3,4,)# print(res)# II: *可以用在实参中,实参中带*,先*后的值打散成位置实参# def func(x,y,z):# print(x,y,z)## # func(*[11,22,33]) # func(11,22,33)# # func(*[11,22]) # func(11,22)## l=[11,22,33]# func(*l)# III: 形参与实参中都带*# def func(x,y,*args): # args=(3,4,5,6)# print(x,y,args)# func(1,2,[3,4,5,6])# func(1,2,*[3,4,5,6]) # func(1,2,3,4,5,6)# func(*'hello') # func('h','e','l','l','o')
可变长度的关键字参数**
# 2.4.2 可变长度的关键字参数# I:**形参名:用来接收溢出的关键字实参,**会将溢出的关键字实参保存成字典格式,然后赋值给紧跟其后的形参名# **后跟的可以是任意名字,但是约定俗成应该是kwargs# def func(x,y,**kwargs):# print(x,y,kwargs)## func(1,y=2,a=1,b=2,c=3)# II: **可以用在实参中(**后跟的只能是字典),实参中带**,先**后的值打散成关键字实参# def func(x,y,z):# print(x,y,z)# func(*{'x':1,'y':2,'z':3}) # func('x','y','z')# func(**{'x':1,'y':2,'z':3}) # func(x=1,y=2,z=3)# 错误# func(**{'x':1,'y':2,}) # func(x=1,y=2)# func(**{'x':1,'a':2,'z':3}) # func(x=1,a=2,z=3)# III: 形参与实参中都带**# def func(x,y,**kwargs):# print(x,y,kwargs)# func(y=222,x=111,a=333,b=444)# func(**{'y':222,'x':111,'a':333,'b':4444})
混用与*
# 混用*与**:*args必须在**kwargs之前# def func(x,*args,**kwargs):# print(args)# print(kwargs)## func(1,2,3,4,5,6,7,8,x=1,y=2,z=3)例子:def index(x,y,z):print('index=>>> ',x,y,z)def wrapper(*args,**kwargs): #args=(1,) kwargs={'z':3,'y':2}index(*args,**kwargs)index(*(1,),**{'z':3,'y':2})index(1,z=3,y=2)wrapper(1,z=3,y=2) # 为wrapper传递的参数是给index用的# 原格式---》汇总-----》打回原形wrapper(1,z=3,y=2)====>args=(1,) kwargs={'z':3,'y':2}===>index(1,z=3,y=2)wrapper(*args,**kwargs) index(*args,**kwargs)
命名关键字参数
# 1. 命名关键字参数(了解)# 命名关键字参数:在定义函数时,*后定义的参数,如下所示,称之为命名关键字参数# 特点:# 1、命名关键字实参必须按照key=value的形式为其传值# def func(x,y,*,a,b): # 其中,a和b称之为命名关键字参数# print(x,y)# print(a,b)## # func(1,2,b=222,a=111)# 示例# def func(x,y,*,a=11111,b):# print(x,y)# print(a,b)## func(1,2,b=22222)
组合使用
# 2. 组合使用(了解)# 形参混用的顺序:位置新参,默认形参,*args,命名关键字形参,**kwargs# def func(x,y=111,*args,z,**kwargs):# print(x)# print(y)# print(args)# print(z)# print(kwargs)# 实参混用的顺序:def func(x,y,z,a,b,c):print(x)print(y)print(z)print(a)print(b)print(c)# func(111,y=222,*[333,444],**{'b':555,'c':666})# func(111,y=222,333,444,b=555,c=666)# func(111,*[333,444],a=222,**{'b':555,'c':666})# func(111,333,444,a=222,b=555,c=66)# func(111,*[333,444],**{'b':555,'c':666},a=222,)func(111,3333,4444,b=555,c=666,a=222)# func(1)# func(x=1)# func(1,x=1)# func(*'hello')# func(**{})# func(*'hell',**{})
函数名称空间与作用域
# 有了名称空间之后,就可以在栈区中存放相同的名字,详细的,名称空间
三种名称空间
# 1.1 内置名称空间# 存放的名字:存放的python解释器内置的名字'''<built-in function print>>>> input<built-in function input>'''# 存活周期:python解释器启动则产生,python解释器关闭则销毁# 1.2 全局名称空间# 存放的名字:只要不是函数内定义、也不是内置的,剩下的都是全局名称空间的名字# 存活周期:python文件执行则产生,python文件运行完毕后销毁# import os## x=10# if 13 > 3:# y=20# if 3 == 3:# z=30## # func=函数的内存地址# def func():# a=111# b=222# class Foo:# pass# 1.3 局部名称空间# 存放的名字:在调用函数时,运行函数体代码过程中产生的函数内的名字# 存活周期:在调用函数时存活,函数调用完毕后则销毁# def func(a,b):# pass## func(10,1)# func(11,12)
名称空间查找顺序
# 1.4 名称空间的加载顺序# 内置名称空间>全局名称空间>局部名称空间# 1.5 销毁顺序# 局部名称空间>全局名空间>内置名称空间# 1.6 名字的查找优先级:当前所在的位置向上一层一层查找# 内置名称空间# 全局名称空间# 局部名称空间# 如果当前在局部名称空间:# 局部名称空间—>全局名称空间->内置名称空间# # input=333# def func():# # input=444# print(input)## func()# 如果当前在全局名称空间# 全局名称空间->内置名称空间# input=333# def func():# input=444# func()# print(input)
作用域
# 二:作用域-》作用范围# 全局作用域:内置名称空间、全局名称空间# 1、全局存活# 2、全局有效:被所有函数共享# 局部作用域: 局部名称空间的名字# 1、临时存活# 2、局部有效:函数内有效# def foo(x):# def f1():# def f2():# print(x)
global与nonlocal
# 示范2:如果再局部想要修改全局的名字对应的值(不可变类型),需要用global# x=111## def func():# global x # 声明x这个名字是全局的名字,不要再造新的名字了# x=222## func()# print(x) #x=222# nonlocal(了解): 修改函数外层函数包含的名字对应的值(不可变类型)# x=0# def f1():# x=11# def f2():# nonlocal x #修改了f1下的x# x=22# f2()# print('f1内的x:',x)## f1()
函数对象
# 精髓:可以把函数当成变量去用# func=内存地址def func():print('from func')# 1、可以赋值# f=func# print(f,func)# f()# 2、可以当做函数当做参数传给另外一个函数# def foo(x): # x = func的内存地址# # print(x)# x()## foo(func) # foo(func的内存地址)# 3、可以当做函数当做另外一个函数的返回值# def foo(x): # x=func的内存地址# return x # return func的内存地址## res=foo(func) # foo(func的内存地址)# print(res) # res=func的内存地址## res()# 4、可以当做容器类型的一个元素# l=[func,]# # print(l)# l[0]()
函数对象应用
def login():print('登录功能')def transfer():print('转账功能')def check_banlance():print('查询余额')def withdraw():print('提现')def register():print('注册')func_dic = {'0': ['退出', None],'1': ['登录', login],'2': ['转账', transfer],'3': ['查询余额', check_banlance],'4': ['提现', withdraw],'5': ['注册', register]}# func_dic['1']()while True:for k in func_dic:print(k, func_dic[k][0])choice = input('请输入命令编号:').strip()if not choice.isdigit():print('必须输入编号,傻叉')continueif choice == '0':break# choice='1'if choice in func_dic:func_dic[choice][1]()else:print('输入的指令不存在')
函数嵌套
# 函数嵌套# 1、函数的嵌套调用:在调用一个函数的过程中又调用其他函数# def max2(x,y):# if x > y:# return x# else:# return y### def max4(a,b,c,d):# # 第一步:比较a,b得到res1# res1=max2(a,b)# # 第二步:比较res1,c得到res2# res2=max2(res1,c)# # 第三步:比较res2,d得到res3# res3=max2(res2,d)# return res3## res=max4(1,2,3,4)# print(res)# 2、函数的嵌套定义:在函数内定义其他函数# def f1():# def f2():# pass# 圆形# 求圆形的求周长:2*pi*radiusdef circle(radius,action=0):from math import pidef perimiter(radius):return 2*pi*radius# 求圆形的求面积:pi*(radius**2)def area(radius):return pi*(radius**2)if action == 0:return 2*pi*radiuselif action == 1:return area(radius)circle(33,action=0)
闭包函数
# 一:大前提:# 闭包函数=名称空间与作用域+函数嵌套+函数对象# 核心点:名字的查找关系是以函数定义阶段为准# 二:什么是闭包函数# "闭"函数指的该函数是内嵌函数# "包"函数指的该函数包含对外层函数作用域名字的引用(不是对全局作用域)# 闭包函数:名称空间与作用域的应用+函数嵌套# def f1():# x = 33333333333333333333# def f2():# print(x)# f2()# 闭包函数:函数对象# def f1():# x = 33333333333333333333# def f2():# print('函数f2:',x)# return f2# f=f1()# # print(f)
闭包应用
import requests# 传参的方案一:# def get(url):# response=requests.get(url)# print(len(response.text))## get('https://www.baidu.com')# get('https://www.cnblogs.com/linhaifeng')# get('https://zhuanlan.zhihu.com/p/109056932')# 传参的方案二:# 一次传参,多次调用不用再次传参def outter(url):# url='https://www.baidu.com'def get():response=requests.get(url)print(len(response.text))return getbaidu=outter('https://www.baidu.com')baidu()cnblogs=outter('https://www.cnblogs.com/linhaifeng')cnblogs()zhihu=outter('https://zhuanlan.zhihu.com/p/109056932')zhihu()
无参装饰器
装饰器准备知识
# 一:储备知识#1、 *args, **kwargsdef index(x,y):print(x,y)def wrapper(*args,**kwargs):index(*args,**kwargs) ## index(y=222,x=111)wrapper(y=222,x=111)# 2、名称空间与作用域:名称空间的的"嵌套"关系是在函数定义阶段,即检测语法的时候确定的# 3、函数对象:# 可以把函数当做参数传入# 可以把函数当做返回值返回def index():return 123def foo(func):return funcfoo(index)#4、函数的嵌套定义:def outter(func):def wrapper():passreturn wrapper# 闭包函数def outter():x=111def wrapper():xreturn wrapperf=outter()# 传参的方式一:通过参数的形式为函数体传值def wrapper(x):print(1)print(2)print(3)xwrapper(1)wrapper(2)wrapper(3)#传参的方式二:通过闭包的方式为函数体传值def outter(x):# x=1def wrapper():print(1)print(2)print(3)xreturn wrapper # return outter内的wrapper那个函数的内地址# f1=outter(1)# f2=outter(2)# f3=outter(3)wrapper=outter(1)
装饰器理论
"""1、什么是装饰器器指的是工具,可以定义成成函数装饰指的是为其他事物添加额外的东西点缀合到一起的解释:装饰器指的定义一个函数,该函数是用来为其他函数添加额外的功能2、为何要用装饰器开放封闭原则开放:指的是对拓展功能是开放的封闭:指的是对修改源代码是封闭的装饰器就是在不修改被装饰器对象源代码以及调用方式的前提下为被装饰对象添加新功能
装饰器创造过程
3、如何用"""# 需求:在不修改index函数的源代码以及调用方式的前提下为其添加统计运行时间的功能def index(x,y):time.sleep(3)print('index %s %s' %(x,y))index(111,222)# index(y=111,x=222)# index(111,y=222)#解决方案一:失败#问题:没有修改被装饰对象的调用方式,但是修改了其源代码import timedef index(x,y):start=time.time()time.sleep(3)print('index %s %s' %(x,y))stop = time.time()print(stop - start)index(111,222)# 解决方案二:失败# 问题:没有修改被装饰对象的调用方式,也没有修改了其源代码,并且加上了新功能# 但是代码冗余import timedef index(x,y):time.sleep(3)print('index %s %s' %(x,y))start=time.time()index(111,222)stop=time.time()print(stop - start)# 解决方案三:失败# 问题:解决了方案二代码冗余问题,但带来一个新问题即函数的调用方式改变了import timedef index(x,y):time.sleep(3)print('index %s %s' %(x,y))def wrapper():start=time.time()index(111,222)stop=time.time()print(stop - start)wrapper()# 方案三的优化一:将index的参数写活了import timedef index(x,y,z):time.sleep(3)print('index %s %s %s' %(x,y,z))def wrapper(*args,**kwargs):start=time.time()index(*args,**kwargs) # index(3333,z=5555,y=44444)stop=time.time()print(stop - start)# wrapper(3333,4444,5555)# 方案三的优化二:在优化一的基础上把被装饰对象写活了,原来只能装饰index(增加了装饰任意函数)import timedef index(x,y,z):time.sleep(3)print('index %s %s %s' %(x,y,z))def home(name):time.sleep(2)print('welcome %s to home page' %name)def outter(func): # func = index的内存地址def wrapper(*args,**kwargs):start=time.time()func(*args,**kwargs) # index的内存地址()stop=time.time()print(stop - start)return wrapper #增加了这一句,能够根据返回值函数来调用index=outter(index) # index=wrapper的内存地址home=outter(home) # home=wrapper的内存地址home('egon')# home(name='egon')# 方案三的优化三:将wrapper做的跟被装饰对象一模一样,以假乱真import timedef index(x,y,z):time.sleep(3)print('index %s %s %s' %(x,y,z))def home(name):time.sleep(2)print('welcome %s to home page' %name)def outter(func):def wrapper(*args,**kwargs):start=time.time()res=func(*args,**kwargs) #res=接受了被装饰函数的返回值stop=time.time()print(stop - start)return res #return res,将接受的返回值通过wrapper函数返回去return wrapper# # 偷梁换柱:home这个名字指向的wrapper函数的内存地址home=outter(home)res=home('egon') # res=wrapper('egon')print('返回值--》',res)#大方向:如何在方案三的基础上不改变函数的调用方式
装饰器语法糖
# 语法糖:让你开心的语法import time# 装饰器先定义好def timmer(func):def wrapper(*args,**kwargs):start=time.time()res=func(*args,**kwargs)stop=time.time()print(stop - start)return resreturn wrapper# 在被装饰对象正上方的单独一行写@装饰器名字# @timmer # index=timmer(index)def index(x,y,z):time.sleep(3)print('index %s %s %s' %(x,y,z))# @timmer # home=timmer(ome)def home(name):time.sleep(2)print('welcome %s to home page' %name)# index(x=1,y=2,z=3)# home('egon')# 思考题(选做),叠加多个装饰器,加载顺序与运行顺序。----》加载顺序是从上到下# @deco1 # index=deco1(deco2.wrapper的内存地址)# @deco2 # deco2.wrapper的内存地址=deco2(deco3.wrapper的内存地址)# @deco3 # deco3.wrapper的内存地址=deco3(index)# def index():# pass# 总结无参装饰器模板def outter(func):def wrapper(*args,**kwargs):# 1、调用原函数# 2、为其增加新功能res=func(*args,**kwargs)return resreturn wrapper
装饰器应用
#为其他函数添加输入密码验证功能def auth(func):def wrapper(*args,**kwargs):# 1、调用原函数# 2、为其增加新功能name=input('your name>>: ').strip()pwd=input('your password>>: ').strip()if name == 'egon' and pwd == '123':res=func(*args,**kwargs)return reselse:print('账号密码错误')return wrapper@authdef index():print('from index')index()
装饰器wraps模块
#偷梁换柱,即将原函数名指向的内存地址偷梁换柱成wrapper函数# 所以应该将wrapper做的跟原函数一样才行from functools import wrapsdef outter(func):@wraps(func) #打印后面index的摘要或者函数名称,将打印的是index的摘要或者函数名称,不是wrapper的摘要、名称def wrapper(*args, **kwargs):"""这个是主页功能"""res = func(*args, **kwargs) # res=index(1,2)return res# 手动将原函数的属性赋值给wrapper函数# 1、函数wrapper.__name__ = 原函数.__name__# 2、函数wrapper.__doc__ = 原函数.__doc__# wrapper.__name__ = func.__name__# wrapper.__doc__ = func.__doc__return wrapper@outter # index=outter(index)def index(x,y):"""这个是主页功能"""print(x,y)print(index.__name__)print(index.__doc__) #help(index)
有参装饰器
知识准备
# 一:知识储备# 由于语法糖@的限制,outter函数只能有一个参数,并且该才是只用来接收# 被装饰对象的内存地址def outter(func):# func = 函数的内存地址def wrapper(*args,**kwargs):res=func(*args,**kwargs)return resreturn wrapper# @outter # index=outter(index) # index=>wrapper@outter # outter(index)def index(x,y):print(x,y)# 偷梁换柱之后# index的参数什么样子,wrapper的参数就应该什么样子# index的返回值什么样子,wrapper的返回值就应该什么样子# index的属性什么样子,wrapper的属性就应该什么样子==》from functools import wraps
有参装饰器创造过程
# 山炮玩法:def auth(func,db_type):def wrapper(*args, **kwargs):name=input('your name>>>: ').strip()pwd=input('your password>>>: ').strip()if db_type == 'file':print('基于文件的验证')if name == 'egon' and pwd == '123':res = func(*args, **kwargs)return reselse:print('user or password error')elif db_type == 'mysql':print('基于mysql的验证')elif db_type == 'ldap':print('基于ldap的验证')else:print('不支持该db_type')return wrapper## @auth # 账号密码的来源是文件def index(x,y):print('index->>%s:%s' %(x,y))# @auth # 账号密码的来源是数据库def home(name):print('home->>%s' %name)# @auth # 账号密码的来源是ldapdef transfer():print('transfer')index=auth(index,'file') #给装饰器函数添加了第二个参数home=auth(home,'mysql')transfer=auth(transfer,'ldap')# index(1,2)# home('egon')# transfer()#======================================================# 山炮二def auth(db_type):def deco(func):def wrapper(*args, **kwargs):name=input('your name>>>: ').strip()pwd=input('your password>>>: ').strip()if db_type == 'file':print('基于文件的验证')if name == 'egon' and pwd == '123':res = func(*args, **kwargs)return reselse:print('user or password error')elif db_type == 'mysql':print('基于mysql的验证')elif db_type == 'ldap':print('基于ldap的验证')else:print('不支持该db_type')return wrapperreturn decodeco=auth(db_type='file')@deco # 账号密码的来源是文件def index(x,y):print('index->>%s:%s' %(x,y))deco=auth(db_type='mysql')@deco # 账号密码的来源是数据库def home(name):print('home->>%s' %name)deco=auth(db_type='ldap')@deco # 账号密码的来源是ldapdef transfer():print('transfer')index(1,2)home('egon')transfer()
有参装饰器语法糖
# 语法糖def auth(db_type):def deco(func):def wrapper(*args, **kwargs):name = input('your name>>>: ').strip()pwd = input('your password>>>: ').strip()if db_type == 'file':print('基于文件的验证')if name == 'egon' and pwd == '123':res = func(*args, **kwargs) # index(1,2)return reselse:print('user or password error')elif db_type == 'mysql':print('基于mysql的验证')elif db_type == 'ldap':print('基于ldap的验证')else:print('不支持该db_type')return wrapperreturn deco@auth(db_type='file') # @deco # index=deco(index) # index=wrapperdef index(x, y):print('index->>%s:%s' % (x, y))@auth(db_type='mysql') # @deco # home=deco(home) # home=wrapperdef home(name):print('home->>%s' % name)@auth(db_type='ldap') # 账号密码的来源是ldapdef transfer():print('transfer')# index(1, 2)# home('egon')# transfer()
有参装饰器模板
# 有参装饰器模板def 有参装饰器(x,y,z):def outter(func):def wrapper(*args, **kwargs):res = func(*args, **kwargs)return resreturn wrapperreturn outter@有参装饰器(1,y=2,z=3)def 被装饰对象():pass
叠加多个装饰器分析
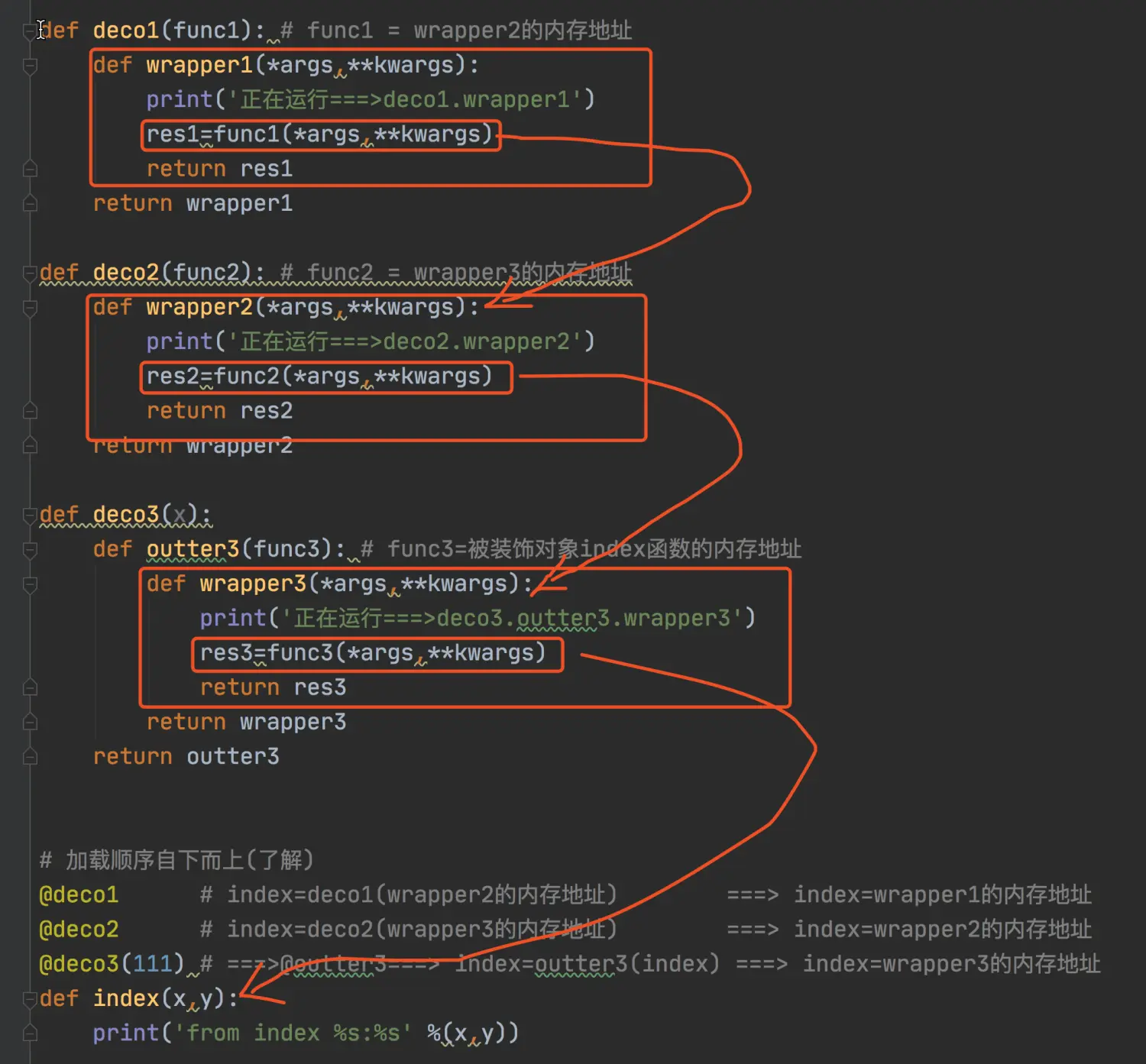
# 一、叠加多个装饰器的加载、运行分析(了解***)def deco1(func1): # func1 = wrapper2的内存地址def wrapper1(*args,**kwargs):print('正在运行===>deco1.wrapper1')res1=func1(*args,**kwargs)return res1return wrapper1def deco2(func2): # func2 = wrapper3的内存地址def wrapper2(*args,**kwargs):print('正在运行===>deco2.wrapper2')res2=func2(*args,**kwargs)return res2return wrapper2def deco3(x):def outter3(func3): # func3=被装饰对象index函数的内存地址def wrapper3(*args,**kwargs):print('正在运行===>deco3.outter3.wrapper3')res3=func3(*args,**kwargs)return res3return wrapper3return outter3# 加载顺序自下而上(了解)@deco1 # index=deco1(wrapper2的内存地址) ===> index=wrapper1的内存地址@deco2 # index=deco2(wrapper3的内存地址) ===> index=wrapper2的内存地址@deco3(111) # ===>@outter3===> index=outter3(index) ===> index=wrapper3的内存地址def index(x,y):print('from index %s:%s' %(x,y))# 执行顺序自上而下的,即wraper1-》wrapper2-》wrapper3index(1,2) # wrapper1(1,2)
迭代器
1、什么是迭代器迭代器指的是迭代取值的工具,迭代是一个重复的过程,每次重复都是基于上一次的结果而继续的,单纯的重复并不是迭代2、为何要有迭代器迭代器是用来迭代取值的工具,而涉及到把多个值循环取出来的类型有:列表、字符串、元组、字典、集合、打开文件l=['egon','liu','alex']i=0while i < len(l):print(l[i])i+=1上述迭代取值的方式只适用于有索引的数据类型:列表、字符串、元组为了解决基于索引迭代器取值的局限性python必须提供一种能够不依赖于索引的取值方式,这就是迭代器
可迭代对象
# 1、可迭代的对象:但凡内置有__iter__方法的都称之为可迭代的对象# s1=''# # s1.__iter__()# l=[]# # l.__iter__()# t=(1,)# # t.__iter__()# d={'a':1}# # d.__iter__()# set1={1,2,3}# # set1.__iter__()# with open('a.txt',mode='w') as f:# # f.__iter__()# pass
迭代器对象
# 2、调用可迭代对象下的__iter__方法会将其转换成迭代器对象,迭代器对象具有__next__方法d={'a':1,'b':2,'c':3}d_iterator=d.__iter__()# print(d_iterator)# print(d_iterator.__next__())# print(d_iterator.__next__())# print(d_iterator.__next__())# print(d_iterator.__next__()) # 取完之后会抛出异常StopIteration# l=[1,2,3,4,5]# l_iterator=l.__iter__()## while True:# try:# print(l_iterator.__next__())# except StopIteration:# break# 3、可迭代对象与迭代器对象详解# 3.1 可迭代对象("可以转换成迭代器的对象"):内置有__iter__方法对象# 可迭代对象.__iter__(): 得到迭代器对象# 3.2 迭代器对象:内置有__next__方法并且内置有__iter__方法的对象# 迭代器对象.__next__():得到迭代器的下一个值# 迭代器对象.__iter__():得到迭代器的本身,说白了调了跟没调一个样子# dic={'a':1,'b':2,'c':3}## dic_iterator=dic.__iter__()# print(dic_iterator is dic_iterator.__iter__().__iter__().__iter__())# 4、可迭代对象:字符串、列表、元组、字典、集合、文件对象# 迭代器对象:文件对象# s1=''# s1.__iter__()## l=[]# l.__iter__()## t=(1,)# t.__iter__()### d={'a':1}# d.__iter__()## set1={1,2,3}# set1.__iter__()### with open('a.txt',mode='w') as f:# f.__iter__()# f.__next__()# 5、for循环的工作原理:for循环可以称之为叫迭代器循环d={'a':1,'b':2,'c':3}# 1、d.__iter__()得到一个迭代器对象# 2、迭代器对象.__next__()拿到一个返回值,然后将该返回值赋值给k# 3、循环往复步骤2,直到抛出StopIteration异常for循环会捕捉异常然后结束循环# for k in d:# print(k)
迭代器优缺点
# 6、迭代器优缺点总结# 6.1 缺点:# I、为序列和非序列类型提供了一种统一的迭代取值方式。# II、惰性计算:迭代器对象表示的是一个数据流,可以只在需要时才去调用next来计算出一个值,就迭代器本身来说,同一时刻在内存中只有一个值,因而可以存放无限大的数据流,而对于其他容器类型,如列表,需要把所有的元素都存放于内存中,受内存大小的限制,可以存放的值的个数是有限的。# 6.2 缺点:# I、除非取尽,否则无法获取迭代器的长度## II、只能取下一个值,不能回到开始,更像是‘一次性的’,迭代器产生后的唯一目标就是重复执行next方法直到值取尽,否则就会停留在某个位置,等待下一次调用next;若是要再次迭代同个对象,你只能重新调用iter方法去创建一个新的迭代器对象,如果有两个或者多个循环使用同一个迭代器,必然只会有一个循环能取到值。
生成器
生成器即自定义的迭代器—->函数+yield
生成器yield
# 如何得到自定义的迭代器:# 在函数内一旦存在yield关键字,调用函数并不会执行函数体代码# 会返回一个生成器对象,生成器即自定义的迭代器def func():print('第一次')yield 1print('第二次')yield 2print('第三次')yield 3print('第四次')# g=func()# print(g)# 生成器就是迭代器# g.__iter__()# g.__next__()# 会触发函数体代码的运行,然后遇到yield停下来,将yield后的值# 当做本次调用的结果返回# res1=g.__next__() 返回1# print(res1)### res2=g.__next__() 返回2# print(res2)## res3=g.__next__()# print(res3)## res4=g.__next__()# len('aaa') # 'aaa'.__len__()# next(g) # g.__next__()# iter(可迭代对象) # 可迭代对象.__iter__()
生成器应用案例
# 应用案列def my_range(start,stop,step=1):# print('start...')while start < stop:yield startstart+=step# print('end....')# g=my_range(1,5,2) # 1 3# print(next(g))# print(next(g))# print(next(g))for n in my_range(1,7,2): #将生成器函数对象用作for循环遍历print(n)# 总结yield:# 有了yield关键字,我们就有了一种自定义迭代器的实现方式。yield可以用于返回值,但不同于return,函数一旦遇到return就结束了,而yield可以保存函数的运行状态挂起函数,用来返回多次值
yield表达式
def func():print('start.....')x=yield 1111 # x='xxxxx' #第一次运行到yield右边暂定,并返回1111.第二次从yield左边开始print(f'哈哈哈啊哈{x}') #哈哈哈啊哈xxxxxprint('哈哈哈啊哈')print('哈哈哈啊哈')print('哈哈哈啊哈')yield 22222 #第二次运行完停在yield右边,返回22222g=func()res=next(g) #返回的永远是yield右边的值,左边的值是send传进去的#print(res) #1111res=g.send('xxxxx') #send会把参数传给yield左边的变量# print(res) #22222#二:def dog(name):food_list=[]print('道哥%s准备吃东西啦...' %name)while True:# x拿到的是yield接收到的值x = yield food_list # x = '肉包子'print('道哥%s吃了 %s' %(name,x))food_list.append(x) # ['一根骨头','肉包子']#g=dog('alex')res=g.send(None) # next(g)print(res)res=g.send('一根骨头')print(res)res=g.send('肉包子')print(res)# g.send('一同泔水')
三元表达式
# 针对以下需求# def func(x,y):# if x > y:# return x# else:# return y## res=func(1,2)# print(res)# 三元表达式# 语法格式: 条件成立时要返回的值 if 条件 else 条件不成立时要返回的值x=1y=2# res=x if x > y else y# print(res)res=111111 if 'egon' == 'egon' else 2222222222print(res)# 应用举例def func():# if 1 > 3:# x=1# else:# x=3x = 1 if 1 > 3 else 3
生成式表达式
生成式表达式一次生成列表出所有值[]
生成器表达式是可迭代对象,使用遍历依次取值()
4、生成式l=[表达式 for x in 可迭代对象 if 条件]g=(表达式 for x in 可迭代对象 if 条件)next(g)sum(表达式 for x in 可迭代对象 if 条件)list(表达式 for x in 可迭代对象 if 条件)dic={键:值 for k in 可迭代对象 if 条件}set1={元素 for k in 可迭代对象 if 条件}
# 1、列表生成式# 左边写name元素的处理函数,右边写if判断是否满足条件l = ['alex_dsb', 'lxx_dsb', 'wxx_dsb', "xxq_dsb", 'egon']# new_l=[]# for name in l:# if name.endswith('dsb'):# new_l.append(name)new_l=[name for name in l if name.endswith('x')]new_l=[name for name in l if name.endswith('dsb')]new_l=[name for name in l]# print(new_l)# 把所有小写字母全变成大写# new_l=[name.upper() for name in l]# print(new_l)# 把所有的名字去掉后缀_dsb# new_l=[name.replace('_dsb','') for name in l]# print(new_l)# 2、字典生成式# keys=['name','age','gender']# dic={key:None for key in keys}# print(dic)# items=[('name','egon'),('age',18),('gender','male')]# res={k:v for k,v in items if k != 'gender'}# print(res)# 3、集合生成式# keys=['name','age','gender']# set1={key for key in keys}# print(set1,type(set1))# 4、生成器表达式# g=(i for i in range(10) if i > 3)# !!!!!!!!!!!强调!!!!!!!!!!!!!!!# 此刻g内部一个值也没有# print(g,type(g))# print(g)# print(next(g))# print(next(g))# print(next(g))# print(next(g))# print(next(g))# print(next(g))# print(next(g))with open('笔记.txt', mode='rt', encoding='utf-8') as f:# 方式一:# res=0# for line in f:# res+=len(line)# print(res)# 方式二:# res=sum([len(line) for line in f])# print(res)# 方式三 :效率最高# res = sum((len(line) for line in f))# 上述可以简写为如下形式res = sum(len(line) for line in f)print(res)
函数的递归
# 一段代码的循环运行的方案有两种# 方式一:while、for循环# while True:# print(1111)# print(2222)# print(3333)# 方式二:递归的本质就是循环:# def f1():# print(1111)# print(2222)# print(3333)# f1()# f1()# 二:需要强调的的一点是:# 递归调用不应该无限地调用下去,必须在满足某种条件下结束递归调用# n=0# while n < 10:# print(n)# n+=1# def f1(n):# if n == 10:# return# print(n)# n+=1# f1(n)## f1(0)# 三:递归的两个阶段# 回溯:一层一层调用下去# 递推:满足某种结束条件,结束递归调用,然后一层一层返回# def age(n):# if n == 1:# return 18# return age(n-1) + 10### res=age(5)# print(res)# age(5) = age(4) + 10# age(4) = age(3) + 10# age(3) = age(2) + 10# age(2) = age(1) + 10# age(1) = 18# 四:递归的应用l=[1,2,[3,[4,[5,[6,[7,[8,[9,10,11,[12,[13,]]]]]]]]]]def f1(list1):for x in list1:if type(x) is list:# 如果是列表,应该再循环、再判断,即重新运行本身的代码f1(x)else:print(x)f1(l)
递归二分法
# 算法:是高效解决问题的办法# 算法之二分法# 需求:有一个按照从小到大顺序排列的数字列表# 需要从该数字列表中找到我们想要的那个一个数字# 如何做更高效???nums=[-3,4,7,10,13,21,43,77,89]find_num=10nums=[-3,4,13,10,-2,7,89]nums.sort()print(nums)# 方案一:整体遍历效率太低# for num in nums:# if num == find_num:# print('find it')# break# 方案二:二分法def binary_search(find_num,列表):mid_val='找列表中间的值'if find_num > mid_val:# 接下来的查找应该是在列表的右半部分#列表=列表切片右半部分binary_search(find_num,列表)elif find_num < mid_val:# 接下来的查找应该是在列表的左半部分#列表=列表切片左半部分binary_search(find_num,列表)else:print('find it')nums=[-3,4,7,10,13,21,43,77,89]find_num=8def binary_search(find_num,l):print(l)if len(l) == 0:print('找的值不存在')returnmid_index=len(l) // 2 #//只保留整数部分if find_num > l[mid_index]:# 接下来的查找应该是在列表的右半部分l=l[mid_index+1:]binary_search(find_num,l)elif find_num < l[mid_index]:# 接下来的查找应该是在列表的左半部分l=l[:mid_index]binary_search(find_num,l)else:print('find it')binary_search(find_num,nums)
面向过程编程
# 面向过程的编程思想:# 核心是"过程"二字,过程即流程,指的是做事的步骤:先什么、再什么、后干什么# 基于该思想编写程序就好比在设计一条流水线# 优点:复杂的问题流程化、进而简单化# 缺点:扩展性非常差# 面向过程的编程思想应用场景解析:# 1、不是所有的软件都需要频繁更迭:比如编写脚本# 2、即便是一个软件需要频繁更迭,也不并不代表这个软件所有的组成部分都需要一起更迭
匿名函数
匿名函数准备
匿名函数就是没有名字的函数;
lambda 参数:表达式
# 1、def用于定义有名函数# func=函数的内存地址# def func(x,y):# return x+y# print(func)# 2、lamdab用于定义匿名函数# print(lambda x,y:x+y)# 3、调用匿名函数# 方式一:# res=(lambda x,y:x+y)(1,2)# print(res)# 方式二:# func=lambda x,y:x+y# res=func(1,2)# print(res)#4、匿名用于临时调用一次的场景:更多的是将匿名与其他函数配合使用
匿名函数应用
max、min、map、filter、reduce、sorted
salaries={'siry':3000,'tom':7000,'lili':10000,'jack':2000}# 需求1:找出薪资最高的那个人=》lili# res=max([3,200,11,300,399])# print(res)# res=max(salaries)# print(res)salaries={'siry':3000,'tom':7000,'lili':10000,'jack':2000}# 迭代出的内容 比较的值# 'siry' 3000# 'tom' 7000# 'lili' 10000# 'jack' 2000# def func(k):# return salaries[k]# ========================max的应用# res=max(salaries,key=func) # 返回值=func('siry')# print(res)# res=max(salaries,key=lambda k:salaries[k])## res=max([3,200,11,300,399]);max比较的是salaries[k],返回的是k名字# print(res)# ========================min的应用# res=min(salaries,key=lambda k:salaries[k])# print(res)# ========================sorted排序# salaries={# 'siry':3000,# 'tom':7000,# 'lili':10000,# 'jack':2000# }res=sorted(salaries,key=lambda k:salaries[k],reverse=True)# print(res)# ========================map的应用(了解)# l=['alex','lxx','wxx','薛贤妻']# new_l=(name+'_dsb' for name in l)# print(new_l)---2个作用相同# res=map(lambda name:name+'_dsb',l)# print(res) # 生成器# ========================filter的应用(了解)# l=['alex_sb','lxx_sb','wxx','薛贤妻']# res=(name for name in l if name.endswith('sb'))# print(res)# res=filter(lambda name:name.endswith('sb'),l)# print(res)# ========================reduce的应用(了解)from functools import reduceres=reduce(lambda x,y:x+y,[1,2,3],10) # 返回16print(res)res=reduce(lambda x,y:x+y,['a','b','c'])print(res) #返回abc
函数的提示类型
def register(name:"必须传入名字傻叉",age:1111111,hobbbies:"必须传入爱好元组")->"返回的是整型":print(name)print(age)print(hobbbies)return 111# register(1,'aaa',[1,])res=register('egon',18,('play','music'))# res=register('egon',19,(1,2,3))print(register.__annotations__) #打印函数的传参提示
制作进度条
print('[%-50s]' %'#')print('[%-50s]' %'##')print('[%-50s]' %'###')import timedef progress(percent):if percent > 1:percent = 1res = int(50 * percent) * '#'print('\r[%-50s] %d%%' % (res, int(100 * percent)), end='')recv_size=0total_size=1025011while recv_size < total_size:time.sleep(0.01) # 下载了1024个字节的数据recv_size+=1024 # recv_size=2048# 打印进度条# print(recv_size)percent = recv_size / total_size # 1024 / 333333progress(percent)
模块导入、包的使用
模块导入基础
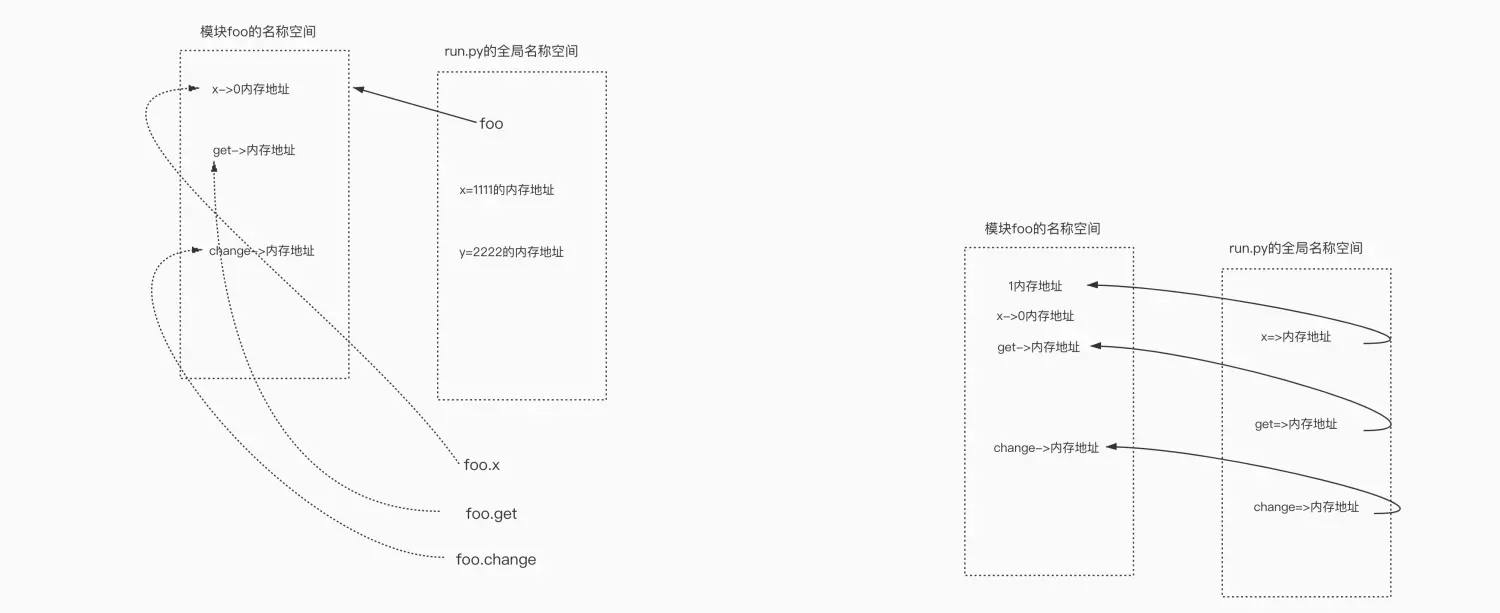
一、绝对导入# 绝对导入,以包的文件夹作为起始来进行导入import sysprint('==========>这是在被导入的__init__.py中查看到的sys.path')print(sys.path) #该路径是一个列表,包含乐init文件所在的path,可以根据该相对path导入包# from foo.bbb.m4 import f4 # foo内有了一个f4# # import foo.bbb.m4.f4 # 语法错误,点的左侧必须是一个包 #foo,bbb是目录=包;m4是文件,f4是函数二、相对导入# 相对导入:仅限于包内使用,不能跨出包(包内模块之间的导入,推荐使用相对导入,绝对导入没有限制)# .:代表当前文件夹# ..:代表上一层文件夹from .m1 import f1from .m2 import f2from .m3 import f3from .bbb.m4 import f4三、导入所有*from 文件 import *print('模块foo==>')__all__=['x',] # 控制*代表的名字有哪些;当在其他文件导入模块foo文件时,会将foo文件中__all__列表中的所有变量导入过去,则可以更改__all__变量来控制其他文件导入四、内置变量__name__print(__name__) ##1、当foo.py被运行时,__name__的值为'__main__'#1、当foo.py被当做模块导入时,__name__的值为'foo'if __name__ == '__main__':print('文件被执行')get()change()else:# 被当做模块导入时做的事情print('文件被导入')pass五、模块导入名称冲突# impot导入模块在使用时必须加前缀"模块."# 优点:肯定不会与当前名称空间中的名字冲突# 缺点:加前缀显得麻烦# from...impot...导入模块在使用时不用加前缀# 优点:代码更精简# 缺点:容易与当前名称空间混淆# from ... import ...导入也发生了三件事# 1、产一个模块的名称空间# 2、运行foo.py将运行过程中产生的名字都丢到模块的名称空间去# 3、在当前名称空间拿到一个名字,该名字与模块名称空间中的某一个内存地址# from foo import x # x=模块foo中值0的内存地址# from foo import get# from foo import change六、起别名# 起别名from foo import get as gprint(g)
模块的搜索路径优先级
# 无论是import还是from...import在导入模块时都涉及到查找问题
# 优先级:
# 1、内存(内置模块)
# 2、硬盘:按照sys.path中存放的文件的顺序依次查找要导入的模块
import sys
# 找foo.py就把foo.py的文件夹添加到环境变量中
sys.path.append(r'/Users/linhaifeng/PycharmProjects/s14/day21/aa')
# import foo
# foo.say()
from foo import say
# 了解:sys.modules查看已经加载到内存中的模块,已经加载到内存中的优先使用内存中的
import sys
# import foo # foo=模块的内存地址
# del foo
# def func():
# import foo # foo=模块的内存地址
#
# func()
#
# # print('foo' in sys.modules)
# print(sys.modules)
模块导入强调
# 强调:
# 1.关于包相关的导入语句也分为import和from ... import ...
# 两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:
# 凡是在导入时带点的,点的左边都必须是一个包,否则非法。
# 可以带有一连串的点,如import 顶级包.子包.子模块,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,
模块,函数,类(它们都可以用点的方式调用自己的属性)。
# 例如:
# from a.b.c.d.e.f import xxx
# import a.b.c.d.e.f
# 其中a、b、c、d、e 都必须是包
# 2、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
#
# 3、import导入文件时,产生名称空间中的名字来源于文件,
# import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
两种导入方式画图
时间模块
# 时间模块优先掌握的操作
#一:time
import time
# 时间分为三种格式:
# 1、时间戳:从1970年到现在经过的秒数
# 作用:用于时间间隔的计算
# print(time.time()) #1606976950.1573133
# 2、按照某种格式显示的时间:2020-03-30 11:11:11
# 作用:用于展示时间
# print(time.strftime('%Y-%m-%d %H:%M:%S %p')) #2020-12-03 14:29:35 PM
# print(time.strftime('%Y-%m-%d %X')) #2020-12-03 14:29:35
# 3、结构化的时间
# 作用:用于单独获取时间的某一部分
# res=time.localtime()
# res为格式time.struct_time(tm_year=2020, tm_mon=12, tm_mday=3, tm_hour=14, tm_min=30, tm_sec=59, tm_wday=3, tm_yday=338, tm_isdst=0)
# print(res)
# print(res.tm_year) #2020
# print(res.tm_mon) #12月
#二:datetime
import datetime
# print(datetime.datetime.now()) #2020-12-03 14:33:02.103541
# print(datetime.datetime.now() + datetime.timedelta(days=3)) #2020-12-06 14:33:02.103541
# print(datetime.datetime.now() + datetime.timedelta(weeks=1)) #2020-12-10 14:33:02.103541
# 时间模块需要掌握的操作
# 1、时间格式的转换
# struct_time->时间戳
import time
s_time=time.localtime()
print(time.mktime(s_time)) #mktime将结构时间转换成时间戳
#时间戳->struct_time
tp_time=time.time() #1606976950.1573133
print(time.localtime(tp_time)) #转换成结构时间
#补充:世界标准时间与本地时间
print(time.localtime())
print(time.gmtime()) # 世界标准时间,了解
print(time.localtime(333333333)) #转换成结构时间
print(time.gmtime(333333333)) #转换成结构时间
#struct_time->格式化的字符串形式的时间
s_time=time.localtime() #结构时间
print(time.strftime('%Y-%m-%d %H:%M:%S',s_time)) #重点2020-12-03 14:37:57,不传参代表显示now时间
print(time.strptime('1988-03-03 11:11:11','%Y-%m-%d %H:%M:%S')) #转换成结构时间
# !!!真正需要掌握的只有一条:format string<------>timestamp time.strftime('%Y-%m-%d %H:%M:%S',s_time)
# '1988-03-03 11:11:11'+7
# format string--->struct_time--->timestamp
# struct_time=time.strptime('1988-03-03 11:11:11','%Y-%m-%d %H:%M:%S')
# timestamp=time.mktime(struct_time)+7*86400 #mktime结构时间转时间戳
# print(timestamp)
# format string<---struct_time<---timestamp
# res=time.strftime('%Y-%m-%d %X',time.localtime(timestamp)) #timestamp是时间戳,localtime转成结构时间,strftime人类可读
# print(res)
# time.sleep(3)
# 了解知识
# import time
# print(time.asctime()) #Thu Dec 3 14:42:03 2020
import datetime
# print(datetime.datetime.now()) #2020-12-03 14:42:29.035382
# print(datetime.datetime.utcnow()) #2020-12-03 06:42:29.035382
print(datetime.datetime.fromtimestamp(333333)) #1970-01-05 04:35:33
random模块
import random
# print(random.random()) #(0,1)----float 大于0且小于1之间的小数
# print(random.uniform(1, 3)) # 大于1小于3的小数,如1.927109612082716
# print(random.randint(1, 3)) # [1,3] 大于等于1且小于等于3之间的整数
# print(random.randrange(1, 3)) # [1,3) 大于等于1且小于3之间的整数
# print(random.choice([111, 'aaa', [4, 5]])) # 1或者23或者[4,5]
# print(random.sample([111, 'aaa', 'ccc','ddd'],2)) # 列表元素任意2个组合
# item = [1, 3, 5, 7, 9]
# random.shuffle(item) # 打乱item的顺序,相当于"洗牌"
# print(item)
应用:随机验证码
# import random
#
# res=''
# for i in range(6):
# 从26大写字母中随机取出一个=chr(random.randint(65,90)) #chr将数字转成字母
# 从10个数字中随机取出一个=str(random.randint(0,9))
#
# 随机字符=random.choice([从26大写字母中随机取出一个,从10个数字中随机取出一个])
# res+=随机字符
import random
def make_code(size=4):
res=''
for i in range(size):
s1=chr(random.randint(65,90))
s2=str(random.randint(0,9))
res+=random.choice([s1,s2])
return res
print(make_code(6))
os模块
import os
# 获取某一个文件夹下所有的子文件以及子文件夹的名字
res=os.listdir('.') #获取当前目录下所有子文件及子文件夹名字
print(res)
# 获取当前计算机CPU个数
os.cpu_count()
# 获取文件大小
size=os.path.getsize(r'/Users/linhaifeng/PycharmProjects/s14/day22/01 时间模块.py')
print(size)
# 删除一个文件
# os.remove()
# 重命名文件/目录
# os.rename("oldname","newname")
# 在终端执行命令
# os.system("ls /")
#给系统添加环境变量
os.environ['aaaaaaaaaa']='111' #给环境变量列表增加值,# 规定:key与value必须都为字符串
print(os.environ)
# 取目录,文件名
print(os.path.dirname(r'/a/b/c/d.txt')) #取/a/b/c
print(os.path.basename(r'/a/b/c/d.txt')) #取d.txt
# 判断是文件还是目录
print(os.path.isfile(r'笔记.txt'))
print(os.path.isfile(r'aaa'))
print(os.path.isdir(r'aaa'))
# 拼接目录
print(os.path.join('a','/','b','c','d'))
# 推荐用这种
BASE_DIR=os.path.dirname(os.path.dirname(__file__)) #获取当前文件上上级目录名称
# print(BASE_DIR)
# __file__ 当前文件绝对路径
# 在python3.5之后,推出了一个新的模块pathlib
from pathlib import Path
# res = Path(__file__).parent.parent #更简单
# print(res)
# res=Path('/a/b/c') / 'd/e.txt' #\a\b\c\d\e.txt
# print(res)
# print(res.resolve()) #D:\a\b\c\d\e.txt
# BASE_DIR=os.path.normpath(os.path.join(
# __file__,
# '..',
# '..'
# ))
# print(BASE_DIR)
sys模块
# python3.8 run.py 1 2 3
# sys.argv获取的是解释器后参数值
# print(sys.argv)
# src_file=sys.argv[1] #获取第一个参数
# dst_file=sys.argv[2] #获取第二个参数
import sys
sys.exit() #退出代码,类似shell的exit
sys.exit(0)
sys.exit(1)
json与pickle模块
序列化&反序列化
# 1、什么是序列化&反序列化
# 内存中的数据类型---->序列化---->特定的格式(json格式或者pickle格式)
# 内存中的数据类型<----反序列化<----特定的格式(json格式或者pickle格式)
# 土办法:
# {'aaa':111}--->序列化str({'aaa':111})----->"{'aaa':111}"
# {'aaa':111}<---反序列化eval("{'aaa':111}")<-----"{'aaa':111}"
# 2、为何要序列化
# 序列化得到结果=>特定的格式的内容有两种用途
# 1、可用于存储=》用于存档
# 2、传输给其他平台使用=》跨平台数据交互
# python java
# 列表 特定的格式 数组
# 强调:
# 针对用途1的特定一格式:可是一种专用的格式=》pickle只有python可以识别
# 针对用途2的特定一格式:应该是一种通用、能够被所有语言识别的格式=》json
# 3、如何序列化与反序列化
# 示范1
import json
# 序列化
json_res=json.dumps([1,'aaa',True,False])
# print(json_res,type(json_res)) # "[1, "aaa", true, false]"
# 反序列化
l=json.loads(json_res)
print(l,type(l))
序列化应用
json.dumps(列表) #序列化列表为字符串列表,除了列表,字典都可以
json.dump(列表,f) #将列表序列化到f文件
json.loads(文件中字符串列表) #返回值为列表
json.load(包含字符串列表的文件) #返回值为列表
# 示范2:
import json
dumps
# 序列化的结果写入文件的复杂方法
json_res=json.dumps([1,'aaa',True,False]) #将列表序列化可以写入文件(列表转为字符串,并且‘’变"")
# print(json_res,type(json_res)) # "[1, "aaa", true, false]"
with open('test.json',mode='wt',encoding='utf-8') as f:
f.write(json_res)
dump
# 将序列化的结果写入文件的简单方法
with open('test.json',mode='wt',encoding='utf-8') as f:
json.dump([1,'aaa',True,False],f) #第二个参数写f文件对象
loads
# 从文件读取json格式的字符串进行反序列化操作的复杂方法
with open('test.json',mode='rt',encoding='utf-8') as f:
json_res=f.read()
l=json.loads(json_res) #将json格式的字符串列表反序列化之后接收到的就是列表了。
print(l,type(l))
load
# 从文件读取json格式的字符串进行反序列化操作的简单方法
with open('test.json',mode='rt',encoding='utf-8') as f:
l=json.load(f)
print(l,type(l))
# json验证: json格式兼容的是所有语言通用的数据类型,不能识别某一语言的所独有的类型
json.dumps({1,2,3,4,5})
# json强调:一定要搞清楚json格式,不要与python混淆
l=json.loads('[1, "aaa", true, false]')
l=json.loads("[1,1.3,true,'aaa', true, false]")
print(l[0])
# 了解
l = json.loads(b'[1, "aaa", true, false]')
print(l, type(l))
with open('test.json',mode='rb') as f:
l=json.load(f)
res=json.dumps({'name':'哈哈哈'})
print(res,type(res))
res=json.loads('{"name": "\u54c8\u54c8\u54c8"}')
print(res,type(res))
# 5.pickle模块 #二进制序列化格式,不可读,只适用于python速度快
import pickle
# res=pickle.dumps({1,2,3,4,5})
# print(res,type(res))
# s=pickle.loads(res)
# print(s,type(s))
pickle协议和JSON(JavaScript Object Notation)的区别 :
JSON是一种文本序列化格式(它输出unicode文本,虽然大部分时间它被编码
utf-8),而pickle是二进制序列化格式;JSON是人类可读的,而pickle则不是;
JSON是可互操作的,并且在Python生态系统之外广泛使用,而pickle是特定于Python的;
猴子补丁
# 4、猴子补丁
# 在入口处打猴子补丁,使用新版ujson代替json
import json
import ujson
def monkey_patch_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json() # 在入口文件处运行
# import ujson as json # 不行
# 后续代码中的应用
# json.dumps()
configparser模块
import configparser
config=configparser.ConfigParser()
config.read('test.ini')
# 1、获取sections
print(config.sections()) #获取ini文件中几个[section+数字]
# 2、获取某一section下的所有options
print(config.options('section1')) #获取sections下对应的参数的key
# 3、获取items
print(config.items('section1')) #获取对应sections下的key-value
# 4、
res=config.get('section1','user') #根据key获取value
print(res,type(res))
res=config.getint('section1','age') #根据key获取value,并将value转成int类型
print(res,type(res))
res=config.getboolean('section1','is_admin') #根据key获取值,并转成boolean类型
print(res,type(res))
res=config.getfloat('section1','salary')
print(res,type(res))
##测试文件test.ini
# 注释1
; 注释2
[section1]
k1 = v1
k2:v2
user=egon
age=18
is_admin=true
salary=31
[section2]
k1 = v1
hashlib模块
# 1、什么是哈希hash
# hash一类算法,该算法接受传入的内容,经过运算得到一串hash值
# hash值的特点:
#I 只要传入的内容一样,得到的hash值必然一样
#II 不能由hash值返解成内容
#III 不管传入的内容有多大,只要使用的hash算法不变,得到的hash值长度是一定
# 2、hash的用途
# 用途1:特点II用于密码密文传输与验证
# 用途2:特点I、III用于文件完整性校验
# 3、如何用
import hashlib
m=hashlib.md5() #创建一个md5对象
m.update('hello'.encode('utf-8')) #再往对象添加加密字符串
m.update('world'.encode('utf-8'))
res=m.hexdigest() # 'helloworld' #res是helloworld的has字符串
print(res)
m1=hashlib.md5('he'.encode('utf-8'))
m1.update('llo'.encode('utf-8'))
m1.update('w'.encode('utf-8'))
m1.update('orld'.encode('utf-8'))
res=m1.hexdigest()# 'helloworld'
print(res)
# 模拟撞库
cryptograph='aee949757a2e698417463d47acac93df'
import hashlib
# 制作密码字段
passwds=[
'alex3714',
'alex1313',
'alex94139413',
'alex123456',
'123456alex',
'a123lex',
]
dic={}
for p in passwds:
res=hashlib.md5(p.encode('utf-8')) #简单写法
dic[p]=res.hexdigest()
# 模拟撞库得到密码
for k,v in dic.items():
if v == cryptograph:
print('撞库成功,明文密码是:%s' %k)
break
# 提升撞库的成本=>密码加盐
import hashlib
m=hashlib.md5()
m.update('天王'.encode('utf-8')) #md5对象update加盐
m.update('alex3714'.encode('utf-8'))
m.update('盖地虎'.encode('utf-8'))
print(m.hexdigest())
# 先创建对象hashlib.md5(《文件所有内容》)
m.update(文件所有的内容)
m.hexdigest() #返回值是hash字符串
f=open('a.txt',mode='rb')
f.seek() #移动光标
f.read(2000) # 巨琳
m1.update(文见的一行)
#
m1.hexdigest()
subproccess模块
import subprocess #k开启一个进程执行命令,使用stdout与stderr接受命令执行返回信息
obj=subprocess.Popen('echo 123 ; ls / ; ls /root',shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
)
# print(obj)
# res=obj.stdout.read()
# print(res.decode('utf-8'))
err_res=obj.stderr.read()
print(err_res.decode('utf-8'))
re模块
import re
print(re.findall('\w','aAbc123_*()-='))
print(re.findall('\W','aAbc123_*()-= '))
print(re.findall('\s','aA\rbc\t\n12\f3_*()-= '))
print(re.findall('\S','aA\rbc\t\n12\f3_*()-= '))
print(re.findall('\d','aA\rbc\t\n12\f3_*()-= '))
print(re.findall('\D','aA\rbc\t\n12\f3_*()-= '))
print(re.findall('\D','aA\rbc\t\n12\f3_*()-= '))
print(re.findall('\Aalex',' alexis alex sb'))
alex
print(re.findall('sb\Z',' alexis alexsb sb'))
sb\Z
print(re.findall('sb\Z',"""alex
alexis
alex
sb
"""))
print(re.findall('^alex','alexis alex sb'))
print(re.findall('sb$','alexis alex sb'))
print(re.findall('sb$',"""alex
alexis
alex
sb
"""))
print(re.findall('^alex$','alexis alex sb'))
print(re.findall('^alex$','al ex'))
print(re.findall('^alex$','alex'))
重复匹配:| . | * | ? | .* | .*? | + | {n,m} |
1、.:匹配除了\n之外任意一个字符,指定re.DOTALL之后才能匹配换行符
print(re.findall('a.b','a1b a2b a b abbbb a\nb a\tb a*b'))
a.b
['a1b','a2b','a b','abb','a\tb','a*b']
print(re.findall('a.b','a1b a2b a b abbbb a\nb a\tb a*b',re.DOTALL))
2、*:左侧字符重复0次或无穷次,性格贪婪
print(re.findall('ab*','a ab abb abbbbbbbb bbbbbbbb'))
ab*
['a','ab','abb','abbbbbbbb']
3、+:左侧字符重复1次或无穷次,性格贪婪
print(re.findall('ab+','a ab abb abbbbbbbb bbbbbbbb'))
ab+
4、?:左侧字符重复0次或1次,性格贪婪
print(re.findall('ab?','a ab abb abbbbbbbb bbbbbbbb'))
ab?
['a','ab','ab','ab']
5、{n,m}:左侧字符重复n次到m次,性格贪婪
{0,} => *
{1,} => +
{0,1} => ?
{n}单独一个n代表只出现n次,多一次不行少一次也不行
print(re.findall('ab{2,5}','a ab abb abbb abbbb abbbbbbbb bbbbbbbb'))
ab{2,5}
['abb','abbb','abbbb','abbbbb]
print(re.findall('\d+\.?\d*',"asdfasdf123as1111111.123dfa12adsf1asdf3"))
\d+\.?\d* \d+\.?\d+
[]匹配指定字符一个
print(re.findall('a\db','a1111111b a3b a4b a9b aXb a b a\nb',re.DOTALL))
print(re.findall('a[501234]b','a1111111b a3b a4b a9b aXb a b a\nb',re.DOTALL))
print(re.findall('a[0-5]b','a1111111b a3b a1b a0b a4b a9b aXb a b a\nb',re.DOTALL))
print(re.findall('a[0-9a-zA-Z]b','a1111111b axb a3b a1b a0b a4b a9b aXb a b a\nb',re.DOTALL))
print(re.findall('a[^0-9a-zA-Z]b','a1111111b axb a3b a1b a0b a4b a9b aXb a b a\nb',re.DOTALL))
print(re.findall('a-b','a-b aXb a b a\nb',re.DOTALL))
print(re.findall('a[-0-9\n]b','a-b a0b a1b a8b aXb a b a\nb',re.DOTALL))
logging模块
直接使用
import logging
logging.basicConfig(
# 1、日志输出位置:1、终端 2、文件
filename='access.log', # 不指定,默认打印到终端
# 2、日志格式
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
# 3、时间格式
datefmt='%Y-%m-%d %H:%M:%S %p',
# 4、日志级别
# critical => 50
# error => 40
# warning => 30
# info => 20
# debug => 10
level=10,
)
logging.debug('调试debug') # 10
logging.info('消息info') # 20
logging.warning('警告warn')# 30
logging.error('egon提现失败') # 40
logging.critical('严重critical') # 50
配置LOGGING_DIC使用
"""
日志配置字典LOGGING_DIC
"""
# 1、定义三种日志输出格式,日志中可能用到的格式化串如下
# %(name)s Logger的名字
# %(levelno)s 数字形式的日志级别
# %(levelname)s 文本形式的日志级别
# %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
# %(filename)s 调用日志输出函数的模块的文件名
# %(module)s 调用日志输出函数的模块名
# %(funcName)s 调用日志输出函数的函数名
# %(lineno)d 调用日志输出函数的语句所在的代码行
# %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
# %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
# %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
# %(thread)d 线程ID。可能没有
# %(threadName)s 线程名。可能没有
# %(process)d 进程ID。可能没有
# %(message)s用户输出的消息
# 2、强调:其中的%(name)s为getlogger时指定的名字
standard_format = '%(asctime)s - %(threadName)s:%(thread)d - 日志名字:%(name)s - %(filename)s:%(lineno)d -' \
'%(levelname)s - %(message)s'
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
test_format = '%(asctime)s] %(message)s'
# 3、日志配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
'test': {
'format': test_format
},
},
'filters': {},
# handlers是日志的接收者,不同的handler会将日志输出到不同的位置
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
# 'maxBytes': 1024*1024*5, # 日志大小 5M
'maxBytes': 1000,
'backupCount': 5,
'filename': 'a1.log', # os.path.join(os.path.dirname(os.path.dirname(__file__)),'log','a2.log')
'encoding': 'utf-8',
'formatter': 'standard',
},
#打印到文件的日志,收集info及以上的日志
'other': {
'level': 'DEBUG',
'class': 'logging.FileHandler', # 保存到文件
'filename': 'a2.log', # os.path.join(os.path.dirname(os.path.dirname(__file__)),'log','a2.log')
'encoding': 'utf-8',
'formatter': 'test',
},
},
# loggers是日志的产生者,产生的日志会传递给handler然后控制输出
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'kkk': {
'handlers': ['console','other'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'终端提示': {
'handlers': ['console',], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
'': {
'handlers': ['default', ], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制)
'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递
},
},
}
src调用上面的settings.py配置
# 课后了解性质——》闲着没事自己研究下
# import logging.config
#
# logging.config.dictConfig(settings.LOGGING_DIC) #将配置settings传入
# print(logging.getLogger) #打印的是函数对象内存地址
# 接下来要做的是:拿到日志的产生者即loggers来产生日志
# 第一个日志的产生者:kkk
# 第二个日志的产生者:bbb
# 但是需要先导入日志配置字典LOGGING_DIC
import settings
from logging import config,getLogger
config.dictConfig(settings.LOGGING_DIC)
# logger1=getLogger('kkk')
# logger1.info('这是一条info日志')
# logger2=getLogger('终端提示')
# logger2.info('logger2产生的info日志')
# logger3=getLogger('用户交易')
# logger3.info('logger3产生的info日志') #info方法代表日志级别
logger4=getLogger('用户常规')
logger4.info('logger4产生的info日志')
# 补充两个重要额知识
# 1、日志名的命名
# 日志名是区别日志业务归属的一种非常重要的标识
# 2、日志轮转
# 日志记录着程序员运行过程中的关键信息
ATM项目
项目架构图
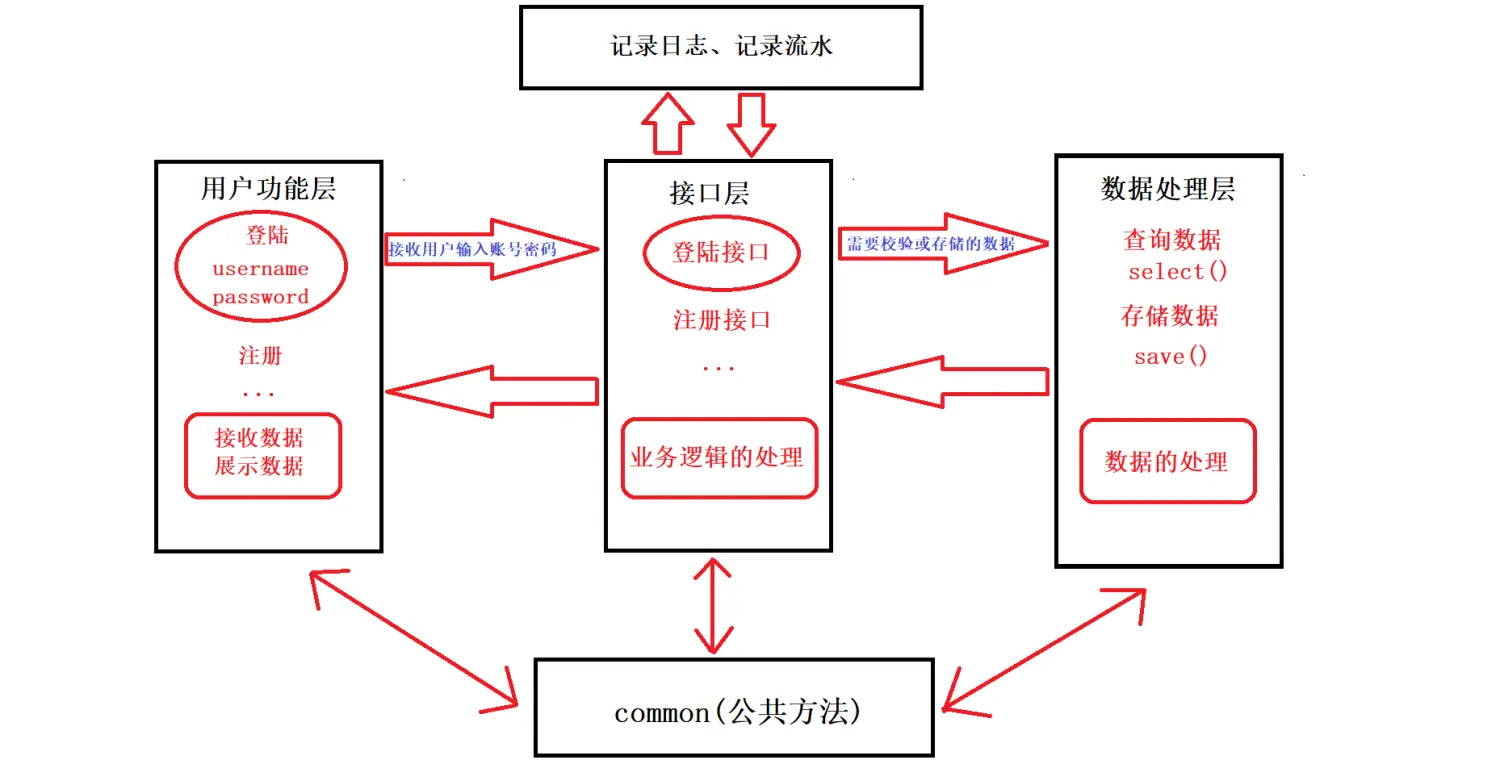
项目搭建流程
一 一个项目是如何从到有的
- 1、需求分析(提取功能)
- 2、程序的架构设计(核心)
- 3、分任务开发
- 4、项目测试
- 5、项目上线
二 程序的架构设计
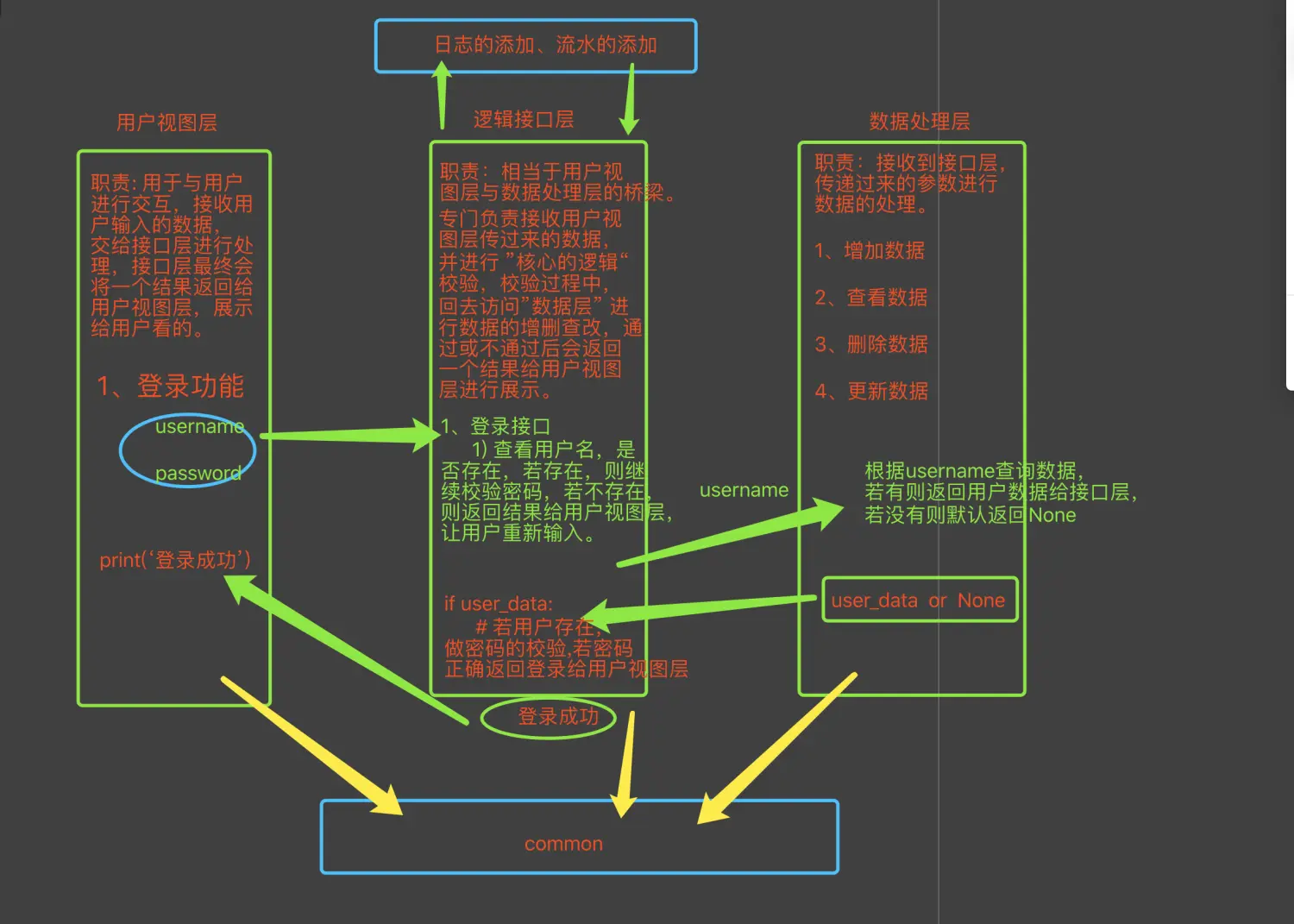
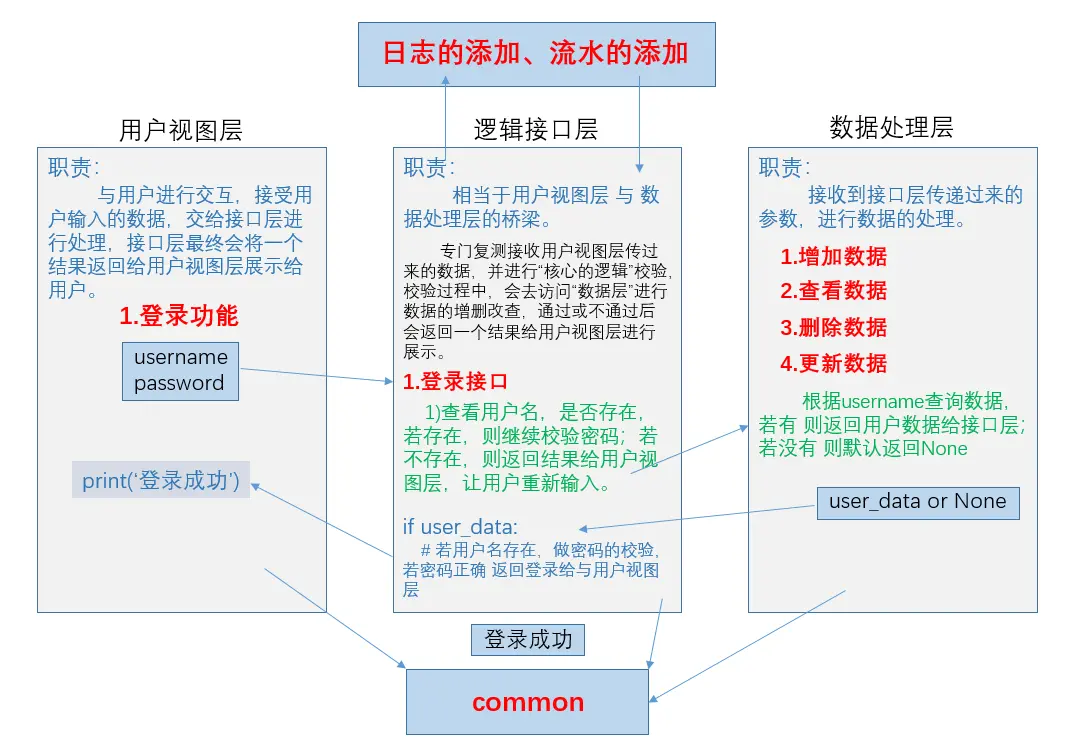
- 三层架构
- 用户视图层
- 用于与用户进行交互
- 接收用户输入的内容
- 打印输出内容给用户
- 逻辑接口层
- 核心业务逻辑,相当于用户视图与数据处理层的桥梁
- 接收视图层传递过来的参数进行逻辑处理
- 返回结果给视图层
- 数据处理层
- 做数据的
- 增
- 删
- 查
- 改
- 分层设计的好处
- 思路清晰
- 不会推翻重写
- 扩展性强
- 便于维护
三 搭建项目的目录规范
- ATM 项目根目录
- readme.md 项目的说明书
- start.py 项目启动文件
- conf 配置文件
- settings.py
- lib 公共方法文件
- common.py
# 密码md5加密,
# 登录认证装饰器,
# 添加日志功能: (日志功能在接口层 使用)
- core(用户视图层) 存放用户视图层代码文件
- src.py
- interface(逻辑接口层) 存放核心业务逻辑代码
- admin_interface.py 管理员相关的接口
# 修改额度接口,# 冻结账户接口
- bank_interface.py 银行相关的接口
# 根据不同的接口类型传入不同的日志对象log_type=
bank_logger = common.get_logger(log_type='bank')
# 提现接口(手续费5%),# 还款接口,# 转账接口,# 查看流水接口,# 支付接口
- shop_interface.py 购物相关的接口
# 根据不同的接口类型传入不同的日志对象log_type=
shop_logger = common.get_logger(log_type='shop')
msg = f'用户:[{login_user}]支付 [{cost}$] 成功, 准备发货!'
shop_logger.info(msg)
# 商品准备结算接口
# 购物车添加接口
# 查看购物车接口
- user_interface.py 用户登录接口
# 注册接口
# 登录接口
# 查看余额接口
- db(数据处理层) 存放数据与数据处理层代码
- db_handler.py 数据处理层代码,保存查看数据
- user_data 用户数据表
- log 存放日志文件
项目结构
# 项目的说明书
## 项目:ATM + 购物车
# 项目需求:
1.额度15000或自定义 --> 注册功能
2.实现购物商城,买东西加入购物车,调用信用卡接口结账 --> 购物功能、支付功能
3.可以提现,手续费5% --> 提现功能
4.支持多账户登录 --> 登录功能
5.支持账户间转账 --> 转账功能
6.记录日常消费 --> 记录流水功能
7.提供还款接口 --> 还款功能
8.ATM记录操作日志 --> 记录日志功能
9.提供管理接口,包括添加账户、用户额度,冻结账户等。。。 ---> 管理员功能
10.用户认证用装饰器 --> 登录认证装饰器
## "用户视图层" 展示给用户选择的功能
1、注册功能
2、登录功能
3、查看余额
4、提现功能
5、还款功能
6、转账功能
7、查看流水
8、购物功能
9、查看购物车
10、管理员功能
# 一个项目是如何从无到有
## 一 需求分析
1.拿到项目,会先在客户那里一起讨论需求,
商量项目的功能是否能实现,周期与价格,得到一个需求文档。
2.最后在公司内部需要开一次会议,最终得到一个开发文档,
交给不同岗位的程序员进行开发。
- Python: 后端,爬虫
- 不同的岗位:
- UI界面设计:
- 设计软件的布局,会分局软件的外观切成一张张图片。
- 前端:
- 拿到UI交给他的图片,然后去搭建网页面。
- 设计一些页面中,哪些位置需要接收数据,需要进行数据交互。
- 后端:
- 直接核心的业务逻辑,调度数据库进行数据的增删查改。
- 测试:
- 会给代码进行全面测试,比如压力测试,界面测试(CF卡箱子)。
- 运维:
- 部署项目。
## 二 程序的架构设计
### 1、程序设计的好处
1)思路清晰
2)不会出现写一半代码时推翻重写
3)方便自己或以后的同事更好维护
### 2、三层架构设计的好处
1)把每个功能都分层三部分,逻辑清晰
2)如果用户更换不同的用户界面或不同,
的数据储存机制都不会影响接口层的核心
逻辑代码,扩展性强。
3)可以在接口层,准确的记录日志与流水。
### 3、三层架构
#### 一 用户视图层
用于与用户交互的,可以接受用户的输入,打印接口返回的数据。
#### 二 逻辑接口层
接受 用户视图层 传递过来的参数,根据逻辑判断调用数据层加以处理,
并返回一个结果给 用户视图层。
#### 三 数据处理层
接受接口层传递过来的参数,做数据的
- 保存数据 save()
- 查看数据 select()
- 更新数据
- 删除数据
## 三 分任务开发
## 四 测试
## 五 上线
# 统计代码
file ---> settings ---> Plugins --->

若有收获,就点个赞吧
0 人点赞
