数据结构基本知识
B树

- 第一次磁盘IO:在内存中定位(与17、35比较),比17小,左子树;
- 第二次磁盘IO:在内存中定位(与8、12比较),比8小,左子树;
- 第三次磁盘IO:在内存中定位(与3、5比较),找到5,终止。
B+树

B+树和B树的不同在于,B树的数据在每个节点,但B+树的数据只在叶子节点,叶子节点按从小到大排序,有利于顺序查找,因为为了减少磁盘IO,所以不用平衡二叉树,要让树变的矮胖,B+树比B树更加矮胖,所以mysql使用B+树来做索引
B+树一个节点的大小为一页或一页的倍数最合适
索引物理结构
非叶子节点
- mysql是以页为基本单位(16k),所以B+数头结点是一页也就是16k
- 先找到根页,通过二分法找到id对应的子节点页的指针
假设一条数据是1K,ID是bigint类型,长度为8个字节,指针在InnoDB 中是6个字节,这样一共14个字节,一页能放16384/14=1170个指针,那么B+树三层就可以放1170117016=21902400条数据
叶子节点
页与页之间用头部都有两个关键段串联,页里面的数据用单向链表串联
参考:
https://zhuanlan.zhihu.com/p/86137284
https://blog.csdn.net/qq_41999455/article/details/106138619
explain字段
- id:执行顺序
- select_type:查询的类型,主要区别普通查询、联合查询、子查询等复杂查询
- table:属于哪张表
- type:访问类型,从优到劣:system>const>eq_ref>ref>range(尽量保证)>index>ALL
- system:表只有一行数据
- eq_ref:标识通过索引一次就找到了,用于pk、uk,只匹配一行数据
- ref:非唯一索引,返回匹配某个单独值的所有行,本质上也是一种索引访问
- range:只检索给定范围的行,使用一个索引来选择行
- index:遍历索引树
- All:遍历全表
- possible_keys:显示可能应用在这张表上的索引,一个或多个
- key:实际使用的索引
- key_len:索引中使用的字节数
- ref:显示索引的哪一列被使用
- rows:显示mysql认为它执行查询时必须检查的行数(越少越好)
- extra:额外信息
具体解释:https://www.cnblogs.com/116970u/p/10984012.html
覆盖索引
就是索引中已经包含要查询的信息,就不用回表再次查询
联合索引
两个字段联合建立索引,如果有高频请求查询,可以建立覆盖索引,联合索引要符合最左匹配原则
索引下推
在mysql5.6之前,’敖%’,联合索引中只能找到id,再回表去查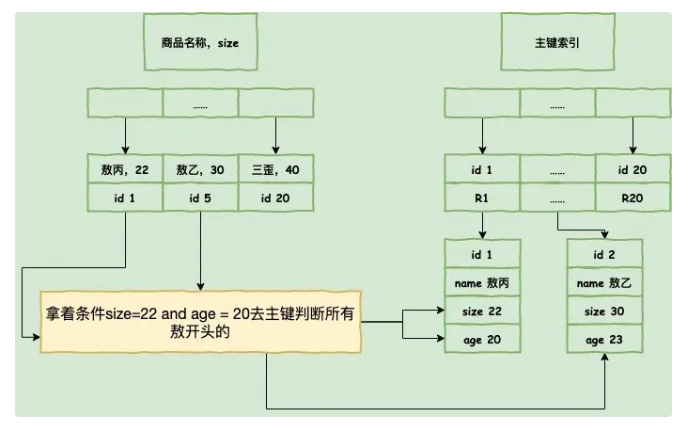
在mysql5.6之后引入索引下推优化,可以对索引中包含的字段先做判断,减少回表次数
唯一索引和普通索引
如果要更新一个数据,这个数据在内存中的话唯一索引和普通索引没有什么区别,但如果数据不在内存中,唯一索引会把数据加载到内存比较是否违反唯一性,再进行更新,但普通索引会引入一个叫change buffer的东西
change buffer
更新时就将更新数据缓存时放到change buffer中,这样就不用把把数据加载到内存够中,减少一次IO操作
change buffer会在访问这个数据页时meger,系统后台也会定期merge,在数据库正常关闭时也会merge,
这样更新可以减少IO操作,也可以少占用buffer pool空间,提高内存利用率
change buffer使用场景
因为merge的时候是真正进行数据更新的时刻,而change buffer的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做merge之前,change buffer记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。
因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好,这种业务模型常见的就是账单类、日志类的系统。
反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在change buffer,但之后由于马上要访问这个数据页,会立即触发merge过程。这样随机访问IO的次数不会减少,反而增加了change buffer的维护代价,所以,对于这种业务模式来说,change buffer反而起到了副作用。
前缀索引
在字符串很长的情况下,有些字符没有区分度,比如邮箱的www.,这时就可以采用前缀索引去优化索引空间
条件字段函数操作
如果索引字段用到函数,就不会走索引,如果id字段是字符串,但查询时按数字查询,mysql会隐式类型转换,这时也是无法用到索引的。
聚簇索引
只有主键索引才是聚簇索引,聚簇索引就是把数据也放到索引中
优点:
1.数据访问更快,因为聚簇索引将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索 引更快
2.聚簇索引对于主键的排序查找和范围查找速度非常快
缺点:
1.插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性 能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键
2.更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更 新。
参考:
https://mp.weixin.qq.com/s/e0CqJG2-PCDgKLjQfh02tw
Mysql延迟关联,解决深分页
延迟关联优化涉及到了 SQL 优化的两个重要概念:覆盖索引和回表。
select * from t_order tinner join (select id from t_orderwhere create_time between '2019-10-17' and '2019-10-25'limit 1000000, 10) eon t.id = e.id;

若有收获,就点个赞吧
0 人点赞
