题目
查壳
先查壳(PKiD等),有壳脱壳,没壳用AndroidKiller等反编译工具打开查看JAVA代码
无壳APK
Java Decompiler - MainActivity-onCreate

答案
Writeup
解题
运行

解题思路
JNI
Java调用C/C++在Java语言里面本来就有的,并非Android自创的,即JNI。JNI就是Java调用C++的规范。
JNI,全称为Java Native Interface,即Java本地接口,JNI是Java调用Native 语言的一种特性。
通过JNI可以使得Java与C/C++机型交互。即可以在Java代码中调用C/C++等语言的代码或者在C/C++代码中调用Java代码。
由于JNI是JVM规范的一部分,因此可以将我们写的JNI的程序在任何实现了JNI规范的Java虚拟机中运行。同时,这个特性使我们可以复用以前用C/C++写的大量代码JNI是一种在Java虚拟机机制下的执行代码的标准机制。代码被编写成汇编程序或者C/C++程序,并组装为动态库。也就允许非静态绑定用法。这提供了一个在Java平台上调用C/C++的一种途径,反之亦然。
搜索字符串
使用反编译工具的字符串搜索功能,搜索运行后失败的提示字符串“You are wrong”:
在Java Decompiler中,找到该class文件:
MainActivity
搜不出来或者没有思路时,应该先看Android程序的入口——也就是MainActivity函数。
代码逻辑
MainActivity
主要代码为一个if判断,条件中调用了MainActivity.a处理输入的数据:
if (MainActivity.a(MainActivity.this, paramAnonymousView.getText().toString())){Toast.makeText(jdField_this, "You are right!", 1).show();}
a函数
查看MainActivity的a函数,有效代码为:
try
{
a locala = new com/a/easyjni/a;
locala.<init>();
bool = ncheck(locala.a(paramString.getBytes()));
return bool;
}
在代码中调用了2️⃣ncheck处理了1️⃣“com/a/easyjni/a”类的返回值:
1️⃣a类
根据64个值的码表,特殊值“3”,“63 / 64”,运算操作“& 0xFF ) >>> ( 2+2j )”,还有以前多个Base64换表的题,很容易得出结论这是一个Base64编码的函数,只不过和标准的Base64编码不同的是,使用的码表char[] a的数值不是标准的码表“ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/”:
public class a
{
private static final char[] a = { 105, 53, 106, 76, 87, 55, 83, 48, 71, 88, 54, 117, 102, 49, 99, 118, 51, 110, 121, 52, 113, 56, 101, 115, 50, 81, 43, 98, 100, 107, 89, 103, 75, 79, 73, 84, 47, 116, 65, 120, 85, 114, 70, 108, 86, 80, 122, 104, 109, 111, 119, 57, 66, 72, 67, 77, 68, 112, 69, 97, 74, 82, 90, 78 };
public String a(byte[] paramArrayOfByte)
{
StringBuilder localStringBuilder = new StringBuilder();
for (int i = 0; i <= paramArrayOfByte.length - 1; i += 3)
{
byte[] arrayOfByte = new byte[4];
int j = 0;
int k = 0;
if (j <= 2)
{
if (i + j <= paramArrayOfByte.length - 1)
{
arrayOfByte[j] = ((byte)(byte)(k | (paramArrayOfByte[(i + j)] & 0xFF) >>> j * 2 + 2));
}
for (k = (byte)(((paramArrayOfByte[(i + j)] & 0xFF) << (2 - j) * 2 + 2 & 0xFF) >>> 2);; k = 64)
{
j++;
break;
arrayOfByte[j] = ((byte)k);
}
}
arrayOfByte[3] = ((byte)k);
k = 0;
if (k <= 3)
{
if (arrayOfByte[k] <= 63)
{
localStringBuilder.append(a[arrayOfByte[k]]);
}
for (;;)
{
k++;
break;
localStringBuilder.append('=');
}
}
}
return localStringBuilder.toString();
}
}
Base64
此时需要对Base64算法有一个基础的了解。
数据特点
- 出现64个字节的字符串(其实应该叫做表)作为数组取值,并且(经常,不是一定)出现“/”和“+”符号
-
Base64算法特征
Base64表格
位移
等号补位
代码
def base(string:str)->str: oldstr = '' newstr = [] base = '' base64_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/'] #原始字符串转换为二进制,用bin转换后是0b开头的,所以把b替换了,首位补0补齐8位 for i in string: oldstr += '{:08}'.format(int(str(bin(ord(i))).replace('0b', ''))) #转换好的二进制按照6位一组分好,最后一组不足6位的后面补0 for j in range(0, len(oldstr), 6): newstr.append('{:<06}'.format(oldstr[j:j + 6])) #在base_list中找到对应的字符,拼接 for l in range(len(newstr)): base += base64_list[int(newstr[l], 2)] #判断base字符结尾补几个‘=’ if len(string) % 3 == 1: base += '==' elif len(string) % 3 == 2: base += '=' return base结论
Base64变体 - 换表
新码表 = { 105, 53, 106, 76, 87, 55, 83, 48, 71, 88, 54, 117, 102, 49, 99, 118, 51, 110, 121, 52, 113, 56, 101, 115, 50, 81, 43, 98, 100, 107, 89, 103, 75, 79, 73, 84, 47, 116, 65, 120, 85, 114, 70, 108, 86, 80, 122, 104, 109, 111, 119, 57, 66, 72, 67, 77, 68, 112, 69, 97, 74, 82, 90, 78 } 码表ASCII字符串化 = "i5jLW7S0GX6uf1cv3ny4q8es2Q+bdkYgKOIT/tAxUrFlVPzhmow9BHCMDpEaJRZN"Base64New函数
把原本Base64使用的码表“
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/”换成“i5jLW7S0GX6uf1cv3ny4q8es2Q+bdkYgKOIT/tAxUrFlVPzhmow9BHCMDpEaJRZN后进行Base64编码处理”。Base64变体 - 题外话
标准的Base64并不适合直接放在URL里传输,因为URL编码器会把标准Base64中的“/”和“+”字符变为形如“%XX”的形式,而这些“%”号在存入数据库时还需要再进行转换,因为ANSI SQL中已将“%”号用作通配符。
为解决此问题,可采用一种用于URL的改进Base64编码,它在末尾填充’=’号,并将标准Base64中的“+”和“/”分别改成了“-”和“”,这样就免去了在URL编解码和数据库存储时所要作的转换,避免了编码信息长度在此过程中的增加,并统一了数据库、表单等处对象标识符的格式。 另有一种用于正则表达式的改进Base64变种,它将“+”和“/”改成了“!”和“-”,因为“+”,“*”以及前面在IRCu中用到的“[”和“]”在正则表达式中都可能具有特殊含义。 此外还有一些变种,它们将“+/”改为“-”或“.”(用作编程语言中的标识符名称)或“.-”(用于XML中的Nmtoken)甚至“:”(用于XML中的Name)。
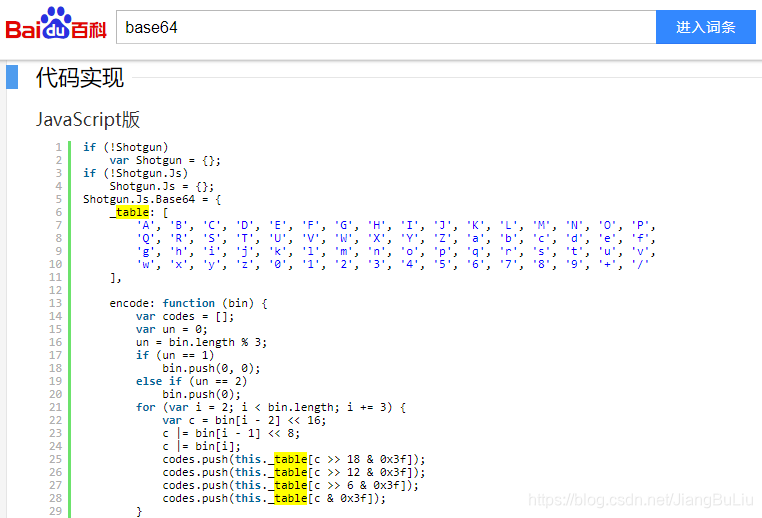
2️⃣ncheck方法
System.loadLibrary动态加载库文件
System.loadLibrary(String libname)则只会从指定lib目录下查找,并加上lib前缀和.so后缀
System.loadLibrary("native");
……省略……
private native boolean ncheck(String paramString);
传进来的“native”,处理后返回的是libnative.so:
IDA+.so库文件
将.so库文件拖入IDA中反编译,查看ncheck函数,代码逻辑为将传入的字符串,先前后互换,再将互换后的字符串两两按个对换:
⚠⚠⚠危险危险危险⚠⚠⚠
在打草稿的时候,我设置原字符串为1234,前后一半对换后为:3412,再按个前后对换为:4321,我这时得出的结论是字符串逆序(Python用reverse),结果一直不对。
再设置原字符串为01234567,前后一半对换后为:45670123,再按个前后对换为:54761032——很明显并不是逆序😥
我还是强行计算了一下规律:
| 下标从0开始 | 下标<一半(half = len(str)/2 = 4) | 下标=>一半(half = len(str)/2 = 4) | ||
|---|---|---|---|---|
| 偶数下标 | 原下标+half+1 | [0] = 0+4+1 = 5 | 原下标-half+1 | [4] = 4-4+1 = 1 |
| 奇数下标 | 原下标+half-1 | [1] = 1+4-1 = 4 | 原下标-half-1 | [5] = 5-4-1 = 0 |
#字符串处理
def ArraySwap(str2Change):
time = 0
half = int(len(str2Change)/2)
arrBefore = list(str2Change)
arrAfter = list(str2Change)
# 0 < 下标 < 一半
while time < half :
arrAfter[time] = arrBefore[time + half + 1]
arrAfter[time + 1] = arrBefore[time + half]
time += 2
else:
# 一半 < 下标 < 总长
while half <= time < len(str2Change) :
arrAfter[time] = arrBefore[time - half + 1]
arrAfter[time + 1] = arrBefore[time - half]
time += 2
return "".join(arrAfter)
str2Change = "01234567"
strChanged = ArraySwap(str2Change)
print("原字符串:", str2Change)
print("转换后:", strChanged)

结果,危险再次出现!😡😡😡
如果字符串设置为len(str) = 10,也就是half = 5,此时上述代码会出现超出范围的报错。因为字长不是4的整数倍,也就是half是奇数,步长为2会造成溢出的问题: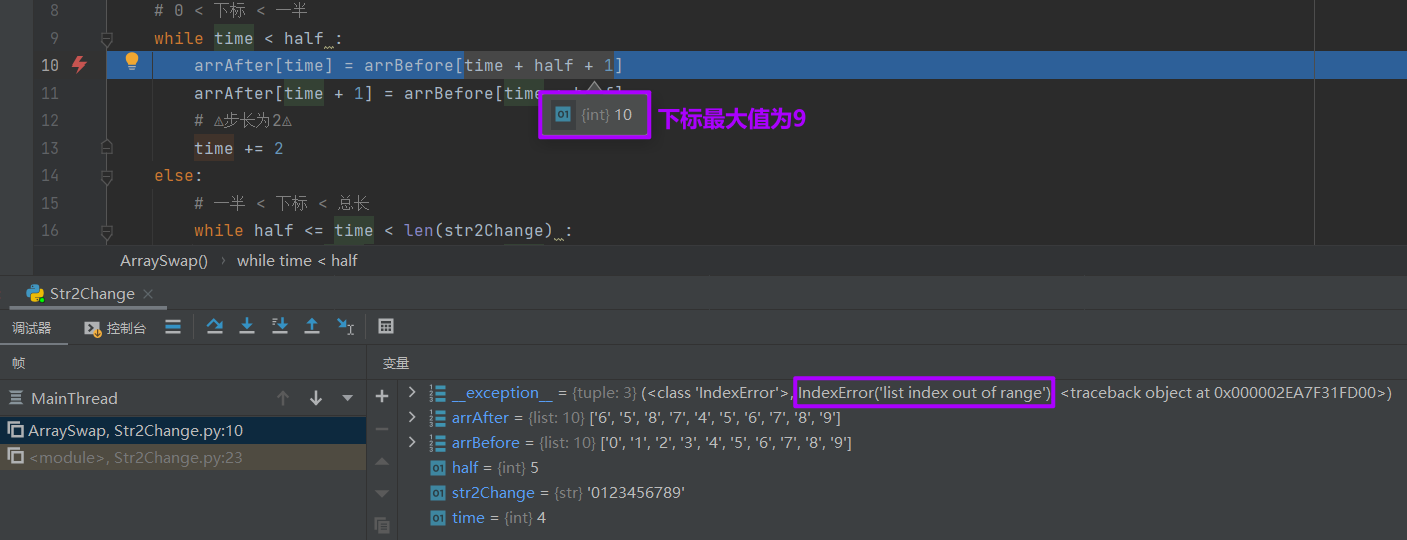
还是建议老老实实按照代码还原,安全一点😵
解法
【👩💻练Python推荐⌨】Python脚本
Python - 切片
Python - decode()方法
import base64
str2Swap = "MbT3sQgX039i3g==AQOoMQFPskB1Bsc7"
tableBase64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
tableNew = "i5jLW7S0GX6uf1cv3ny4q8es2Q+bdkYgKOIT/tAxUrFlVPzhmow9BHCMDpEaJRZN"
#1. 字符串处理
def ArraySwap(str2Swap):
time = 0
half = int(len(str2Swap)/2)
#1.1 前后两半互换
str2Swap = str2Swap[half:] + str2Swap[:half]
arr = list(str2Swap)
#1.2 前后两个互换
while ( time < len(str2Swap) ):
arr[time],arr[time+1] = arr[time+1],arr[time]
time += 2
return "".join(arr)
str2NewDeBase64 = ArraySwap(str2Swap)
print("用来DeBase64的字符串:", str2NewDeBase64)
#2. Base64换表
'''
maketrans():用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标;
translate():法根据参数table给出的表(包含 256 个字符)转换字符串的字符, 要过滤掉的字符放到 del 参数中;
decode():以encoding指定的编码格式解码字符串。
'''
def BaseChangeTable(str,table):
return base64.b64decode(str2NewDeBase64.translate(str.maketrans(table,tableBase64)))
flag = BaseChangeTable(str2NewDeBase64,tableNew).decode("utf-8")
print("Flag:" + flag)
💯You are right!💯


若有收获,就点个赞吧
0 人点赞
