中级提升班1


考点:后序建立二叉树,查找优化(root节点的过程,N-> log2N)


考点:滑动窗口、固定长度(和目标串长度一致),所有字符都存在的统计

初始思路:滑窗长度L 


先尝试拿最多的8,然后剩余部分拿6,一旦剩余部分大于8,6的最小公倍数24,结束尝试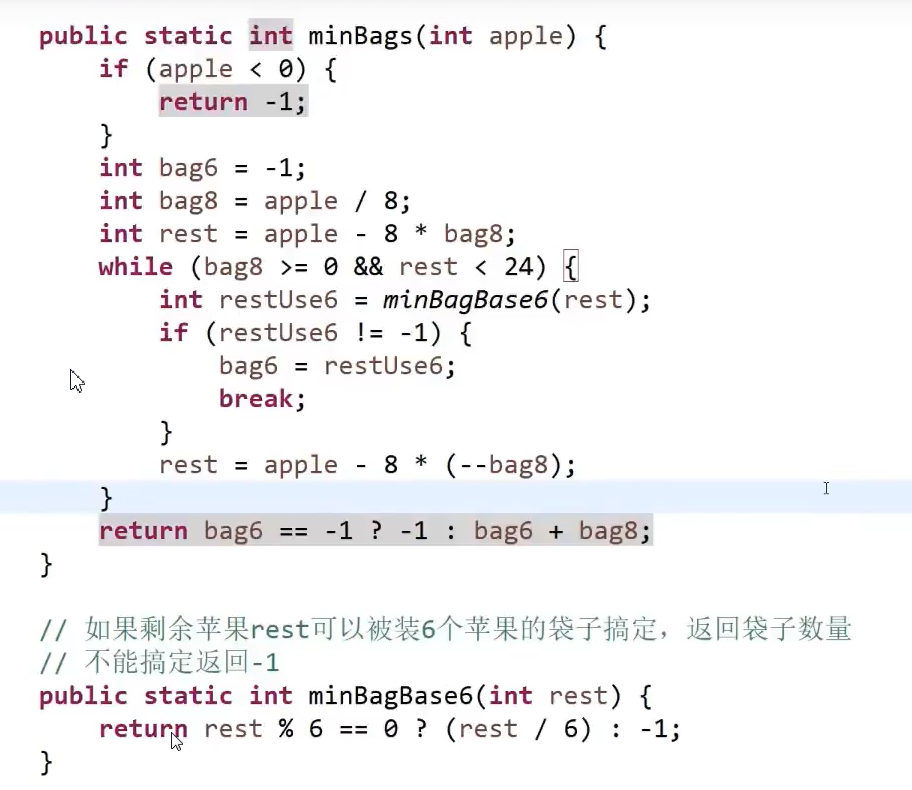



优化:
辅助数组从左往右统计记录 0~i范围上有多少个R
辅助数组从右往左统计记录 j~Len-1范围上有多少个G

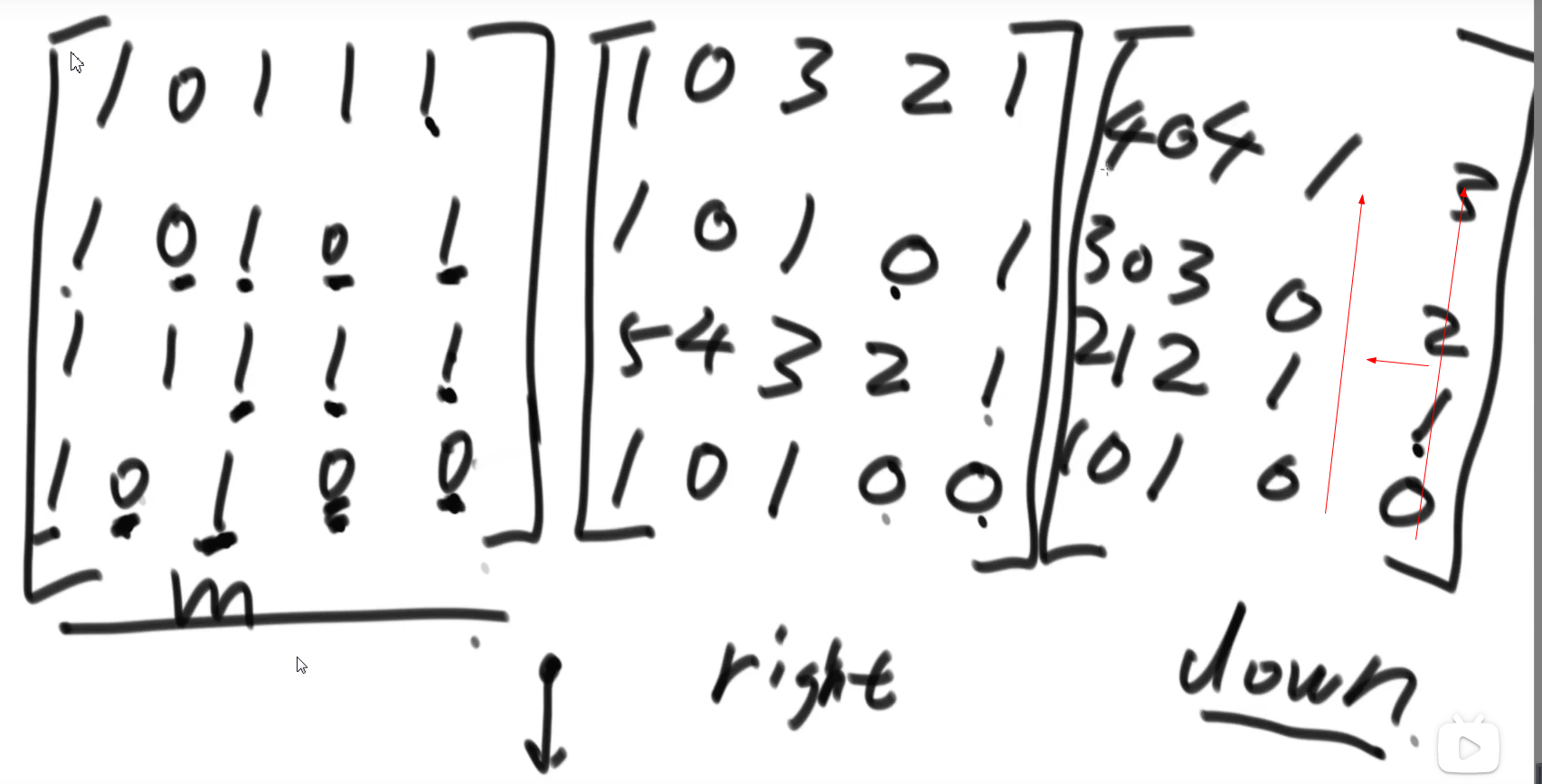
初始思路:暴力法,尝试矩阵上的每个点O(nn),再尝试正方形边长O(n),最终复杂度O(nnn)
推荐思路:辅助存储
right[i][j]: 对应原始矩阵arr[i][j]位置 右侧(包含自己)有多少个连续的1
down[i][j]: 对应原始矩阵arr[i][j]位置 下方(包含自己)有多少个*连续的1

推荐思路:现将f(1~5),还原成一个0,1等概率发生器即:01发生器 random01(),然后利用所有数字都可以用二进制表示,利用01发生器生成2进制串即可,
例如:1~7,等价于0~6的随机数,最多有3位二进制数,将超出的部分7舍弃掉重做即可,
例如:5~13,等价于0~8的随机数,需要4位二进制数,如果生成9~15部分则重做即可
p概率产生0,1-p产生1,利用生成01的概率p(1-p)和生成10的概率(1-p)p相等,生成返回0,1。其他情况00,11舍弃重做

先穷举,再动态规划,假设左子树有i个节点,那么右子树就有n-i-1个节点
eg:
n=0, f(0)=1
n=1, f(1)=1
n=2, f(2)=f(0)f(1)+f(1)f(0)
n=3, f(3)=f(0)f(2)+f(1)f(1)+f(2)f(0)
n=5, f(5)=f(0)f(4)+f(1)f(4)+f(2)f(2)+f(3)f(1)+f(4)f(0)

暂无思路,后续再看
中级提升班2

初始思路:先排序,然后滑窗计算
[3,2,5,7,0,0],k=2
推挤思路:哈希表,类似两数之和的题,遍历一遍生成哈希表,第二次遍历第一个数3时,查找有没有1或者5存在即可


初始思路:类似于走楼梯,每次可以走一步或者两步,
f(n)=f(n-1)+f(n-2)
递归版本:
动归版:

动归:dp[i]=以i结尾的最长匹配
d[i]=d[i-1]+2+dp[i-d[i-1-2]]



推荐思路:递归尝试
另解,找规律

初始思路:先序遍历,累加路径,直到叶节点,比较左右子树最大值
中级提升班3

初始思路:先排序从大到小,右边大的-1,左边小的+1
推荐思路:
对于第i个机器单独考虑,
左边应得多少件,实际有多少件,差多少件
右边应得多少件,实际有多少件,差多少件


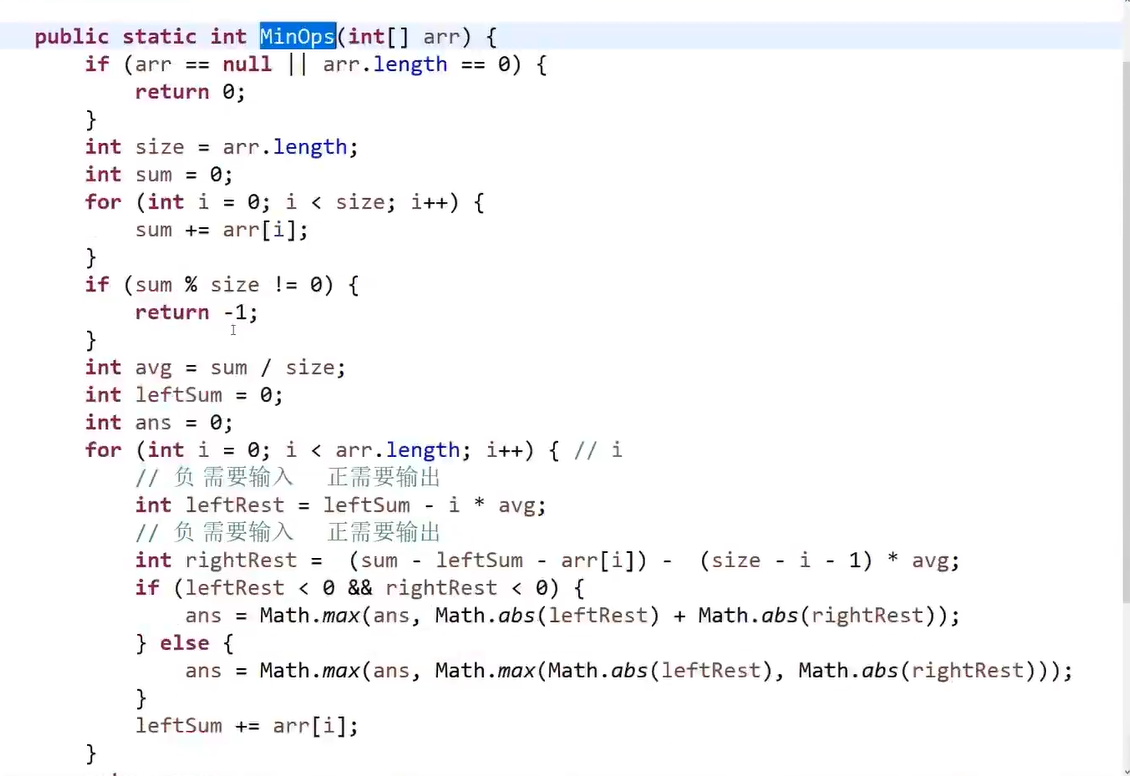
return ans;

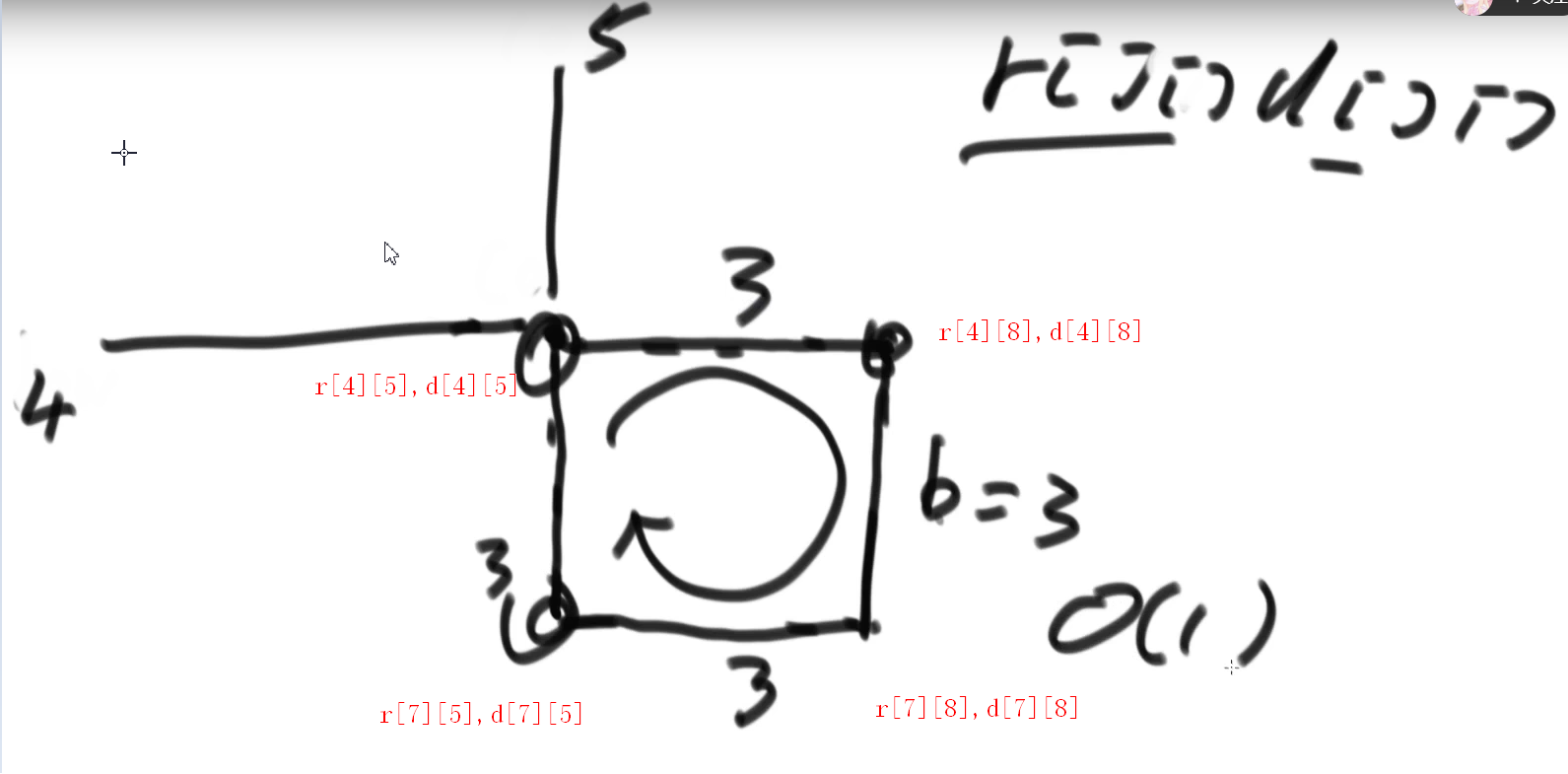
推荐思路:定义两个点,a,b初始均为(0,0),a往下走,b往右走,每各走一步,输出打印a-b斜线上的数据,通过boolean变量取反交替控制打印a->b的上的数据和b->a的数据,a走到头往右,b走到头下,直到再次走到头结束



初始思路:按 右下左上 ,4种变相方式进行变换,每遇到边界或者已经访问过的(记录访问矩阵)变换一次相位
推荐思路:
设计一个基础函数,给定两个点打印这两个点组成的长方形边框
初始两个点(0,0)(m,n),打印完成后各沿对角线移动一位(1,1)(m-1,n-1)
继续打印边框,直到长方形边界重合






初始思路:递归走迷宫穷举所有可能
取巧思路:
变种:01矩阵中,每一行0横在1左边,求1最多的行索引
初始思想:二分取列,看列中是否有1,如果有就在[0~left]中继续二分
取巧思路:

和质数有关的题,先跳过,直接记结论:所有质数因子(不含1)的和 - 因子的个数

初始思路:堆排序
推荐思路:hash+小根堆+map
另外:PriorityQueue类实现了优先队列,默认是一个小根堆的形式,如果要定义大根堆,需要在初始化的时候加入一个自定义的比较器。
PriorityQueue 实现heap
minHeap:PriorityQueue默认实现小根堆,待 PriorityQueue 实战演练
待重听记录笔记
小根堆
PriorityQueue类实现了优先队列,默认是一个小根堆的形式,如果要定义大根堆,需要在初始化的时候加入一个自定义的比较器。
https://blog.csdn.net/Awt_FuDongLai/article/details/115492987?utm_medium=distribute.pc_relevant.none-task-blog-2~default~baidujs_title~default-1.no_search_link&spm=1001.2101.3001.4242.2
java集合类TreeMap和TreeSet及红黑树
中级提升班4

两个队列,每条数据加上时间戳就行
推荐思路:维护两个栈,一个存放数据data栈,一个存放最小值min栈,
push操作时,判断待push元素和min栈顶元素哪个小,谁小min栈压入谁
pop时,data弹出一个,min就弹出一个
扩展min队列,最小值队列
https://blog.csdn.net/qiwoo_weekly/article/details/96416070
推荐思路:数据队列data,最小值队列min,队尾进,队首出
入队x元素:
data:x元素队尾进
min:如果x小于min队尾,min队尾弹出,直到x大于等于min队尾,x队尾进入
出队:
data:队首y元素出队
min:如果y==min的队首,min队首弹出,否则min不作操作
特殊情况:重复值
data:1,1,3,3,2,2
min:1,1,2,2


两个栈实现队列:
入队列时:进push栈,
出队列时:如果pop栈无数据,将push栈中的数据全部倒出入pop栈
如果pop有数据时,不能push->pop迁移数据操作
两个队列实现栈:
入栈时:先进队列1,
出栈时:队列1中留一个元素,其余全进入队列2,弹出队列1中的最后一个元素,此时队列1空了,
再次弹出时,队列2留一个元素其余全进队列1,弹出队列2的最后一个元素,此时队列2空了,继续下去



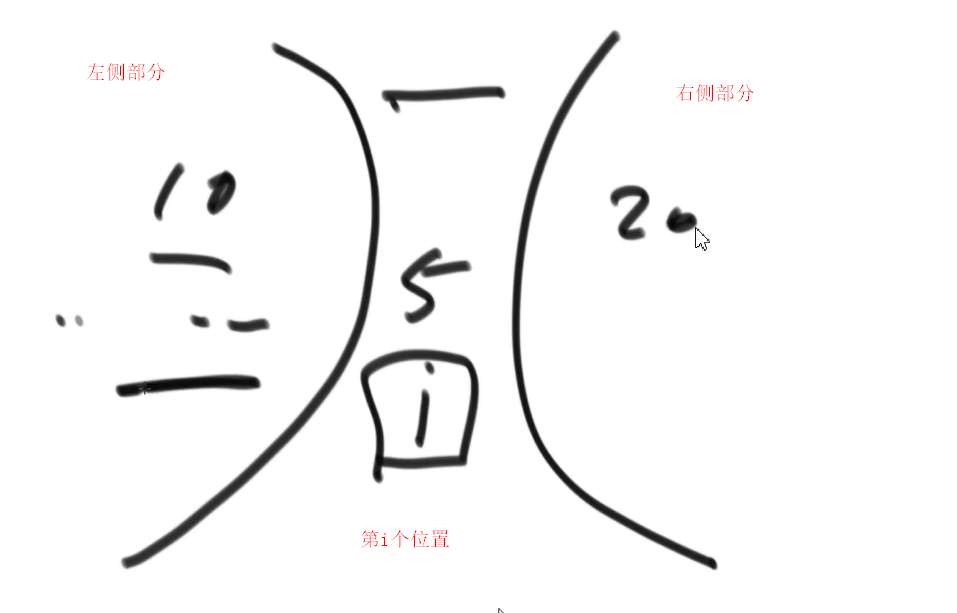

推荐思路:
此问题变成了求数组每个元素左侧部分的最大值,以及右侧部分的最大值的题目
速记方法:两个辅助数组求两侧最大值
扫描数组从左到右,辅助数组leftMax依次求出记录第i个位置的左侧最大值
扫描数组从右到左,辅助数组rightMax依次求出记录第i个位置的右侧最大值

优化思路:无需辅助数组,降低空间占用,单调栈(不一定行)
双指针:

初始思路:预处理,辅助数组
两个辅助数组求两侧最大值
扫描数组从左到右,辅助数组leftMax依次求出记录第i个位置的左侧最大值
扫描数组从右到左,辅助数组rightMax依次求出记录第i个位置的右侧最大值
推荐思路:没听懂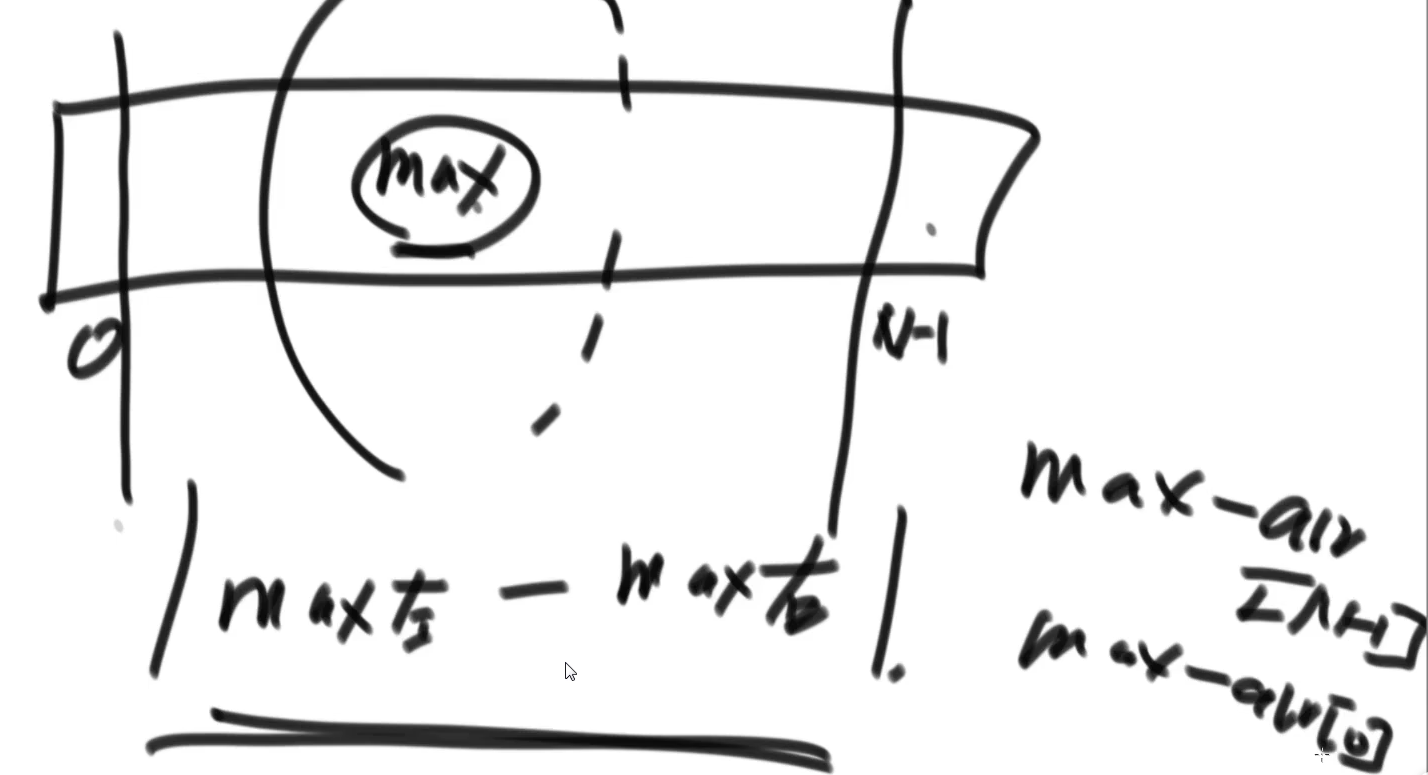

初始思路:遍历所有可能
推荐思路:扩充a两倍,搜索a+a串中是否包含b,KMP算法
扩充题:
有一个数据arr[3,2,7],数组长度表示咖啡机的数量,数组值表示每个咖啡机研磨出一杯咖啡的时间,
有N个人排队用咖啡机,有一台洗咖啡杯的机器,每洗一个咖啡杯用时a,如果咖啡杯不洗自动挥发干净用时b,
求所有人排队喝到咖啡,且最后所有杯子都干净后的总耗时最短的方式





玩堆排序必会的数据结构:



数学题:
三种数:奇数a个,偶数且只有一个2因子b个,偶数且有多个2因子c个
结论,当b=0,c>=a-1,当b!=0,c>=a
中级提升班6
斐波拉契递推式转通用公式:F(n)=F(n-1)+F(n-2),时间复杂度由O(n)->O(logN)
线性代数:行列式转换
通过带入F(3),F(2),F(4),F(3)求出a.b.c.d
得到公式:
所以问题就变成了求 行列式的n次方问题,利用75中有多少个1即可算出,所以斐波拉契求解时间复杂度就变成了O(logN)



记规律,题意转化成:N个数中有多少个斐波拉契数

略
参见 小根堆
github 搜索:algorithmzuo

推荐思路:dp[i][j]:前i个零食任意装,组成j个体积容量
dp[i][j]= 当第i个零食不装入背包时dp[i-1][j] +当第i个零食装入背包时dp[i-1][j-v[i]]
所以不超过背包容量w的可能装发=dp[i][0]+dp[i][1]+dp[i][2]+dp[i][w]

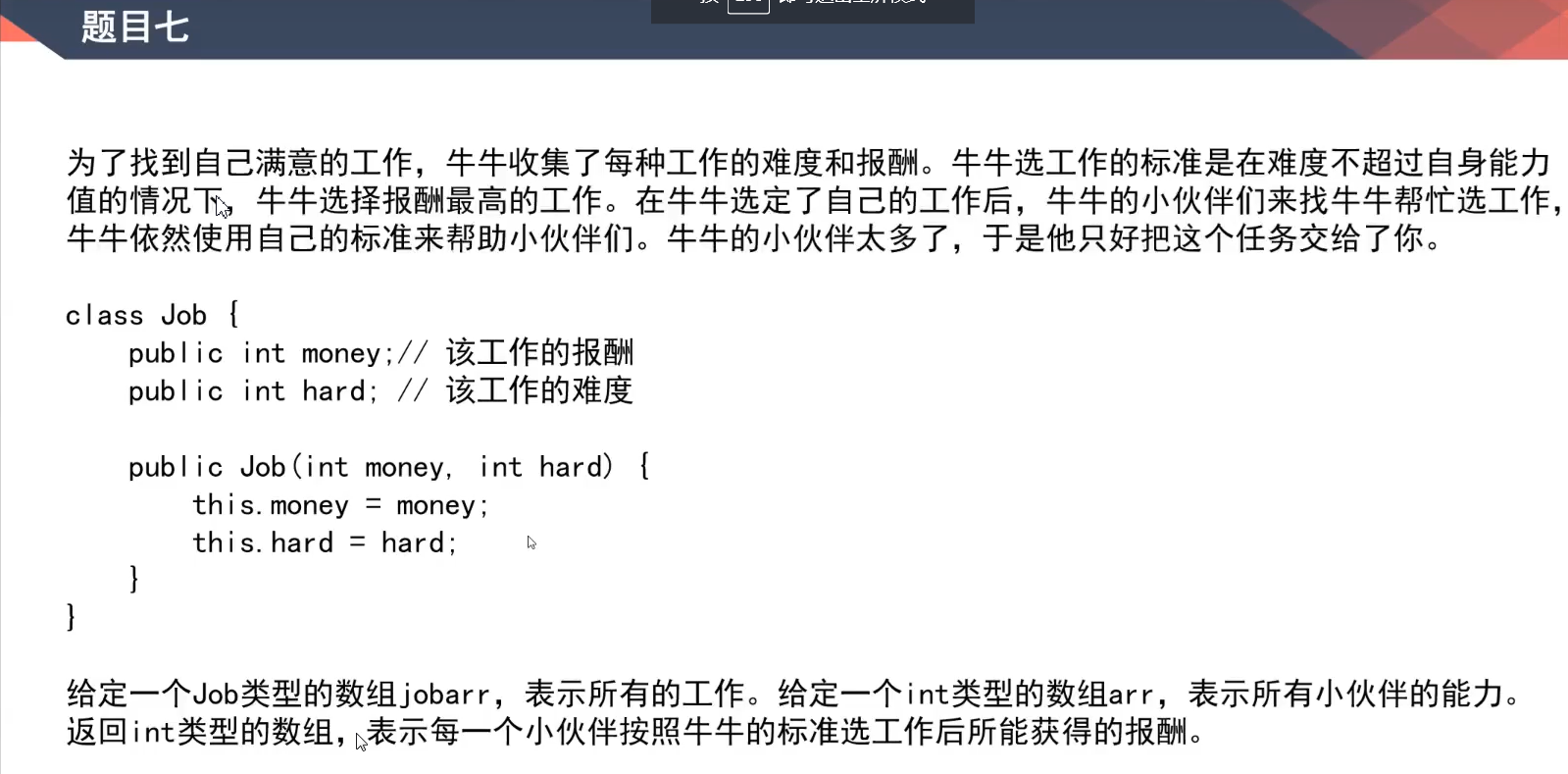
推荐思路:
有序表:
先按工作难度排序,然后同一工作难度的按报酬排序
然后没一组工作难度中最保留报酬最高的一个组长
最后,遍历组长移除组长中难度增加报酬未增加的组长,if job[i+1].hard>job[i+1].hard ,but job[i+1].money
中级提升班7

初始目录:排序,合并相同前缀,繁琐
推荐思路:建立前缀树,然后深度优先遍历+排序,深度+1则空格+2
注意数据结构:用树路径存储内容 TreeMap
建前缀树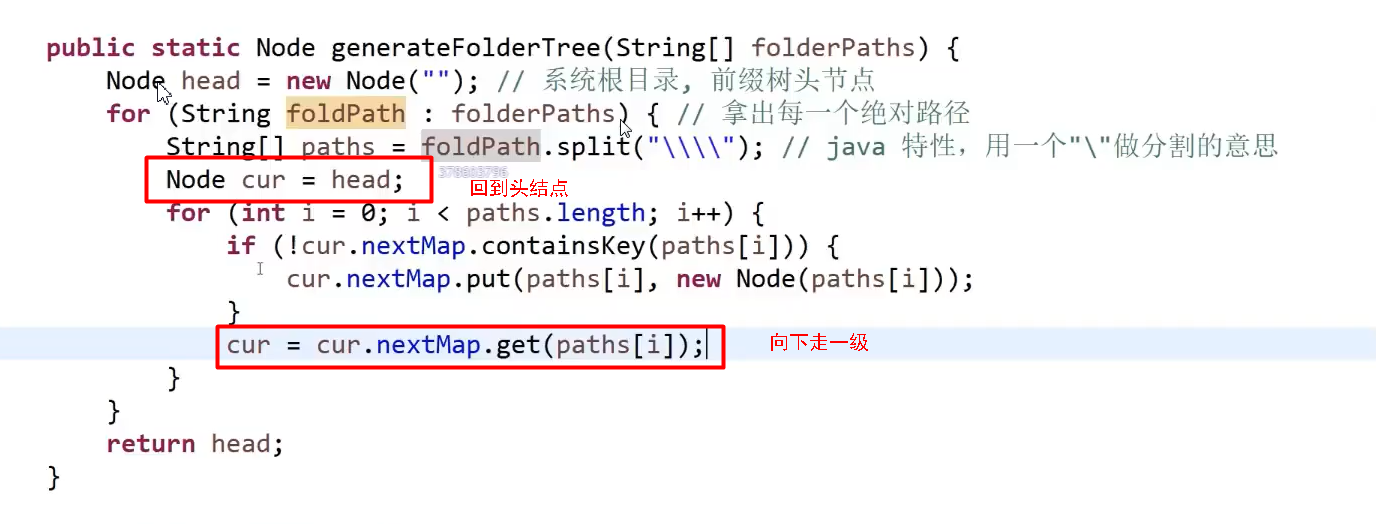
深度优先遍历:








贪心算法:
如果当前i位置是点号,且下个位置i+1是点号,一定在i+1位置放灯

子数组的最大累加和,变种:如果有多个累加和最大的子数组,返回“最长”的子数组




子矩阵最大累加和

压缩数组:
如求3x4矩阵的最大子矩阵累加和,
等价于=max{matrixSum(0,0), matrixSum(0,1), matrixSum(0,2), matrixSum(1,1), matrixSum(1,2), matrixSum(2,2)}
其中matrixSum(i,j)表示必须同时包含第i~j行的最大子矩阵
如何求matrixSum(i,j),
eg:求matrixSum(0,1)
将第0行(-5,3,6,4)和第1行-(-7,9,-5,3)的数据合并,得到(-12,12,1,7)
所以求matrixSum(0,1)最大矩阵和即(-12,12,1,7)问题变成求单维数组的子数组最大累加和,使用问题6的解法即可
matrixSum(0,0):求第0行的子数组最大累加和
matrixSum(0,1):压缩合并数组第0,1行,求子数组最大累加和
matrixSum(0,2):压缩合并数组第0,2行,求子数组最大累加和
matrixSum(1,1):第1行,求子数组最大累加和
matrixSum(1,2):压缩合并数组第1,2行,求子数组最大累加和
matrixSum(2,2):第2行,求子数组最大累加和
最后结果,即取max{matrixSum(0,0), matrixSum(0,1), matrixSum(0,2), matrixSum(1,1), matrixSum(1,2), matrixSum(2,2)}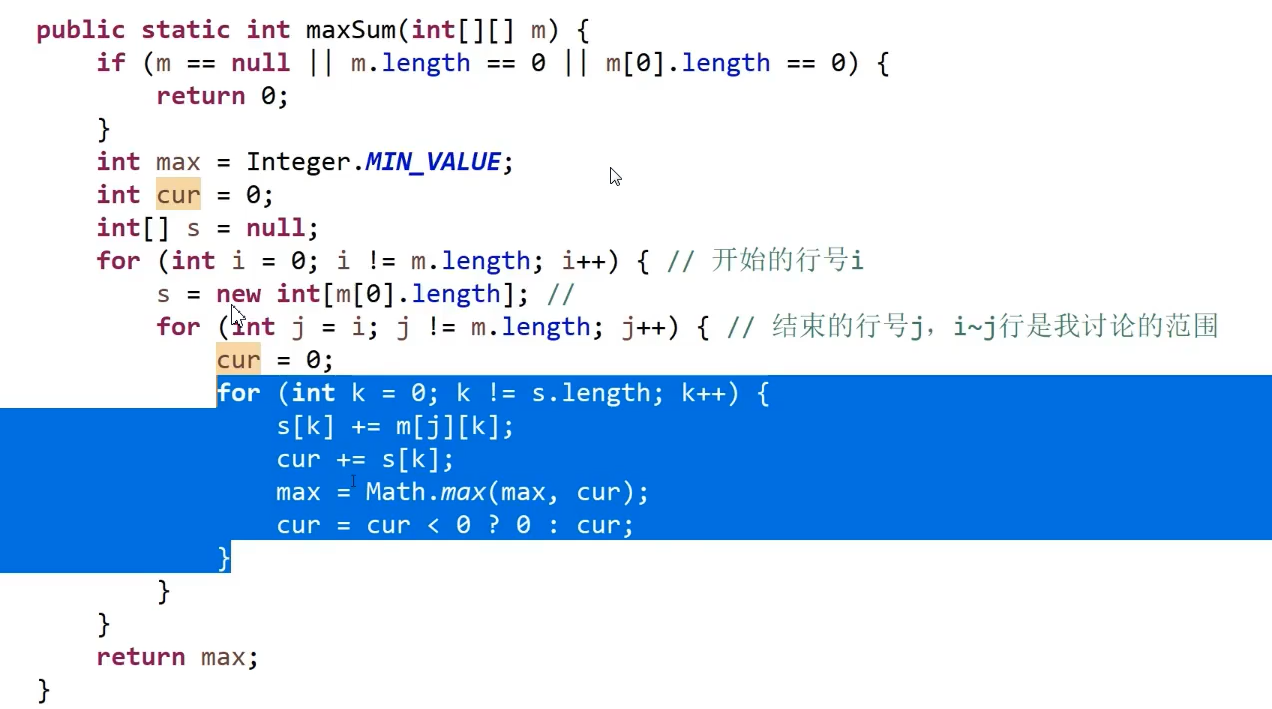
中级提升班8





关键点:
1.找到平凡解,归纳递归限制
2.递归改动态规划:进阶版4个小时

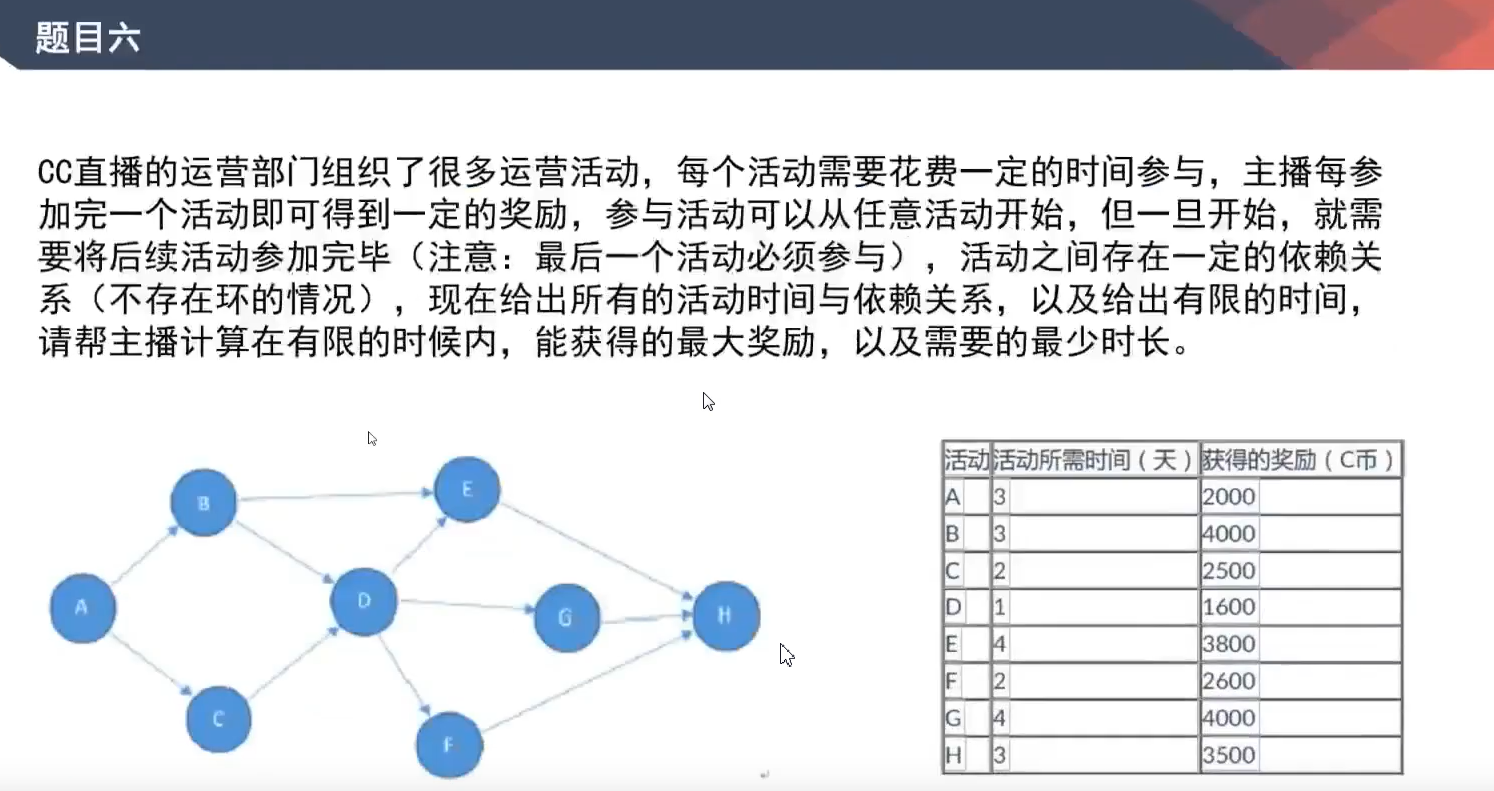
注意题意:可以从任意节点开始,但必须是H结束
推荐思路:反向倒推图广度遍历,合并代价表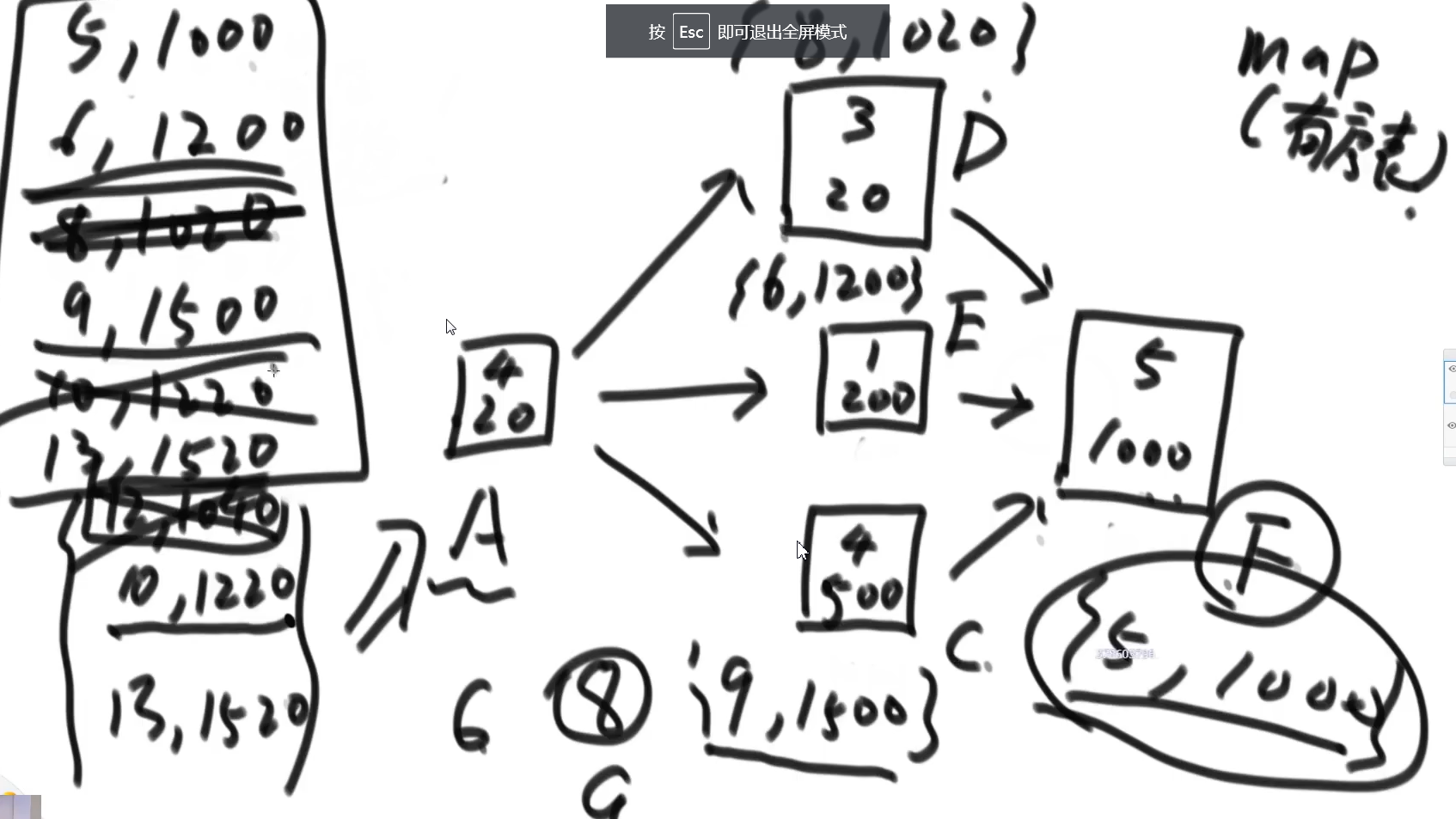


子序列可以不连续

最长递增子序列
设dp[i]表示以i结尾的最长递增子序列
dp[i]=for(j: 0~ i-1 ) if(arr[j]<arr[i]) dp[i]=max{ dp[j] } +1
中级提升班9

子数组最大异或和
暴力思路:枚举所有子数据,求所有子数组的异或值,选出最大
初步优化:利用 arr[i~j]的异或和 = arr[0~i-1]的异或和 ^ arr[0~j]的异或和
先加工出任意arr[0~k]的异或和,然后求出任意 arr[i~j]子数组的最大异或和
高级版的 字典树讲解






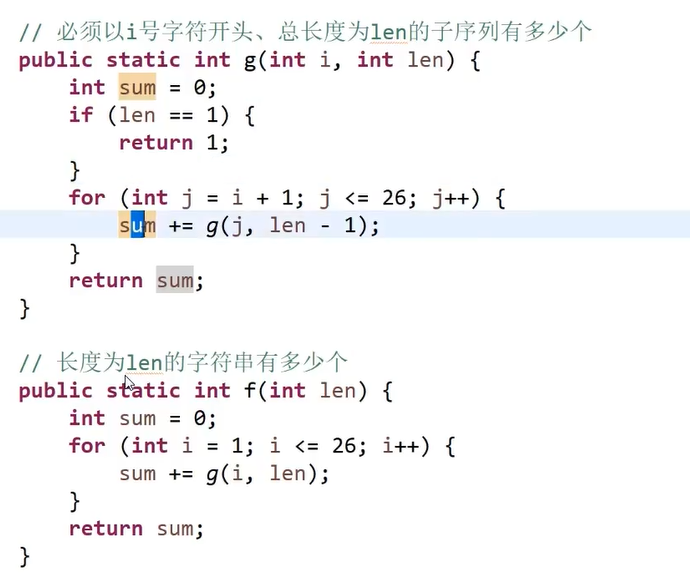
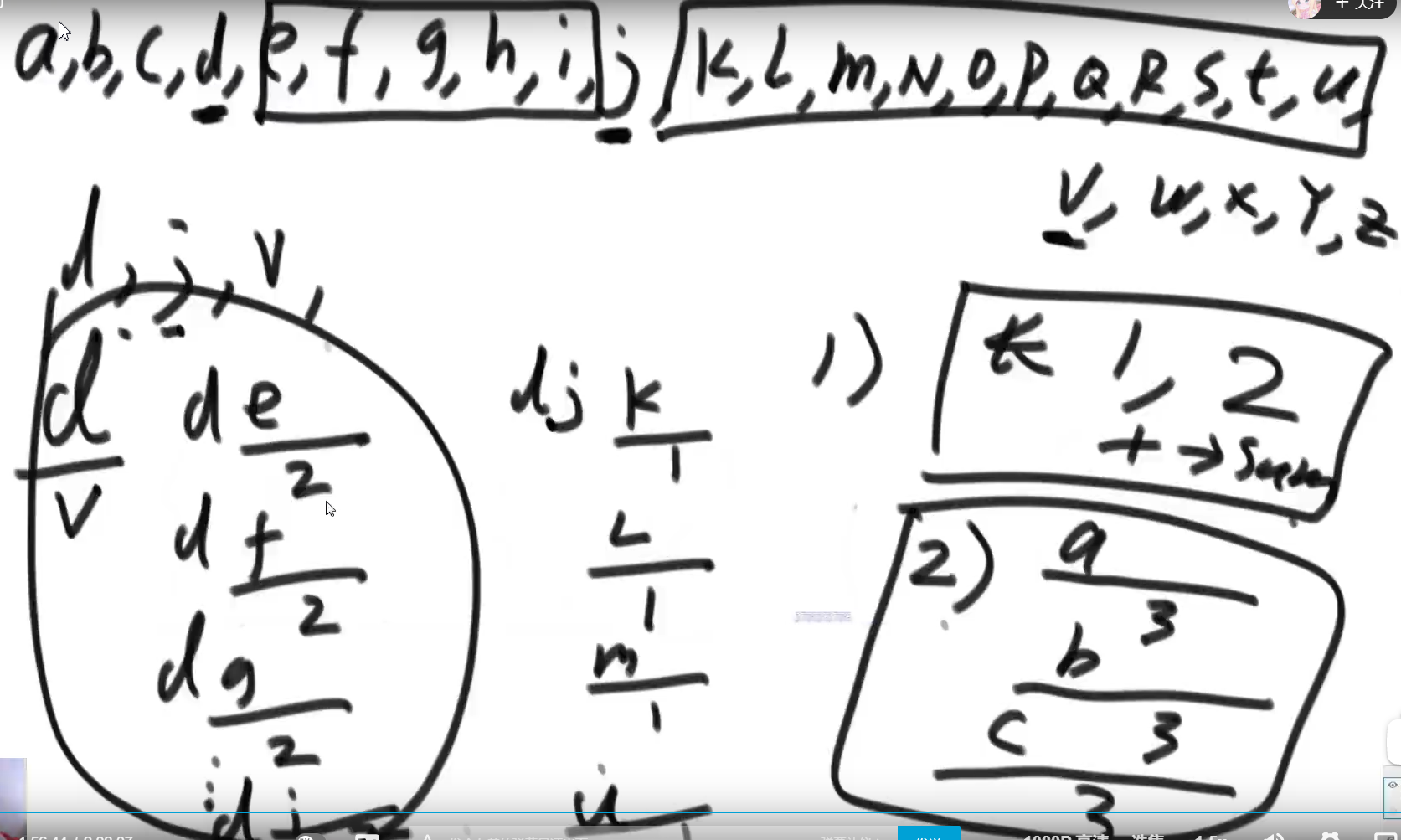
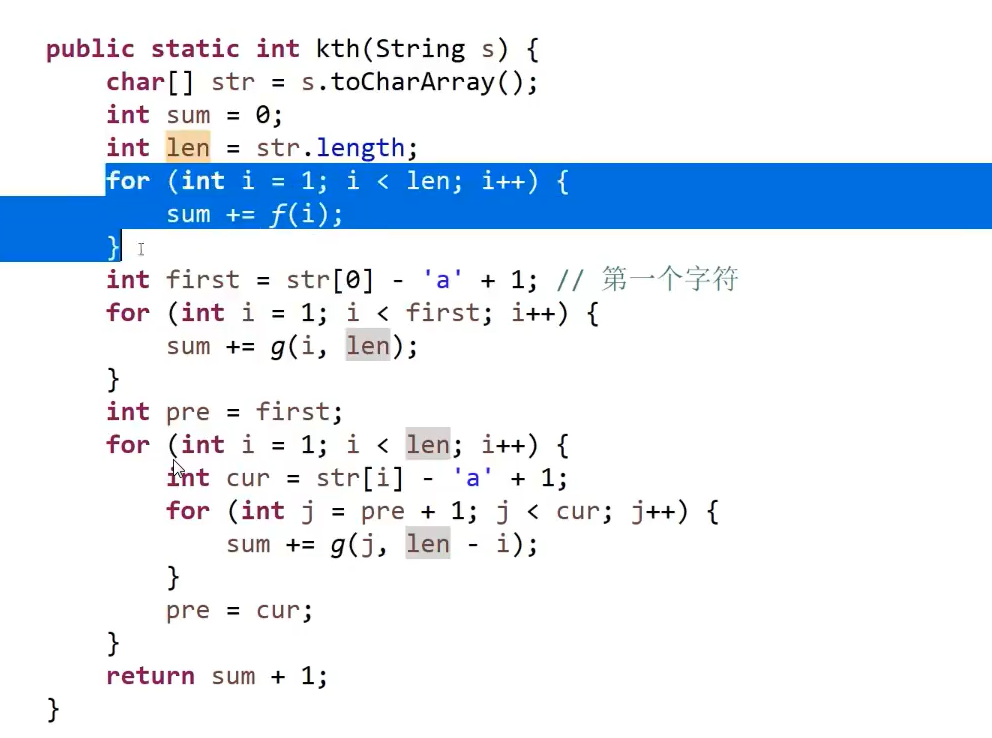

初始思路:滑窗 + hash
推荐思路:动态规划
左神反复强调:看到子串、子数组、子序列的问题,就想每个位置结尾情况下会怎么怎么样,以某个字符结尾会怎么怎么样
以第i位置的结尾的最长无重复子串
= 从 max{ 上次出现元素i的位置,以第i-1位置的结尾的最长无重复子串 左边界 } 到 位置i的字符串

pre存储的始终是以上一个元素结尾的最长无重复子串的 左边界

经典的编辑距离问题:
推荐思路:和最长公共子序列,最长公共子串 是一种解题模型
dp[i][j]表示:str1的前i个字符,变换成str2的前j个字符所需要的代价
注意str1第i个字符是str1[i-1]

代码超短:填完数组即完成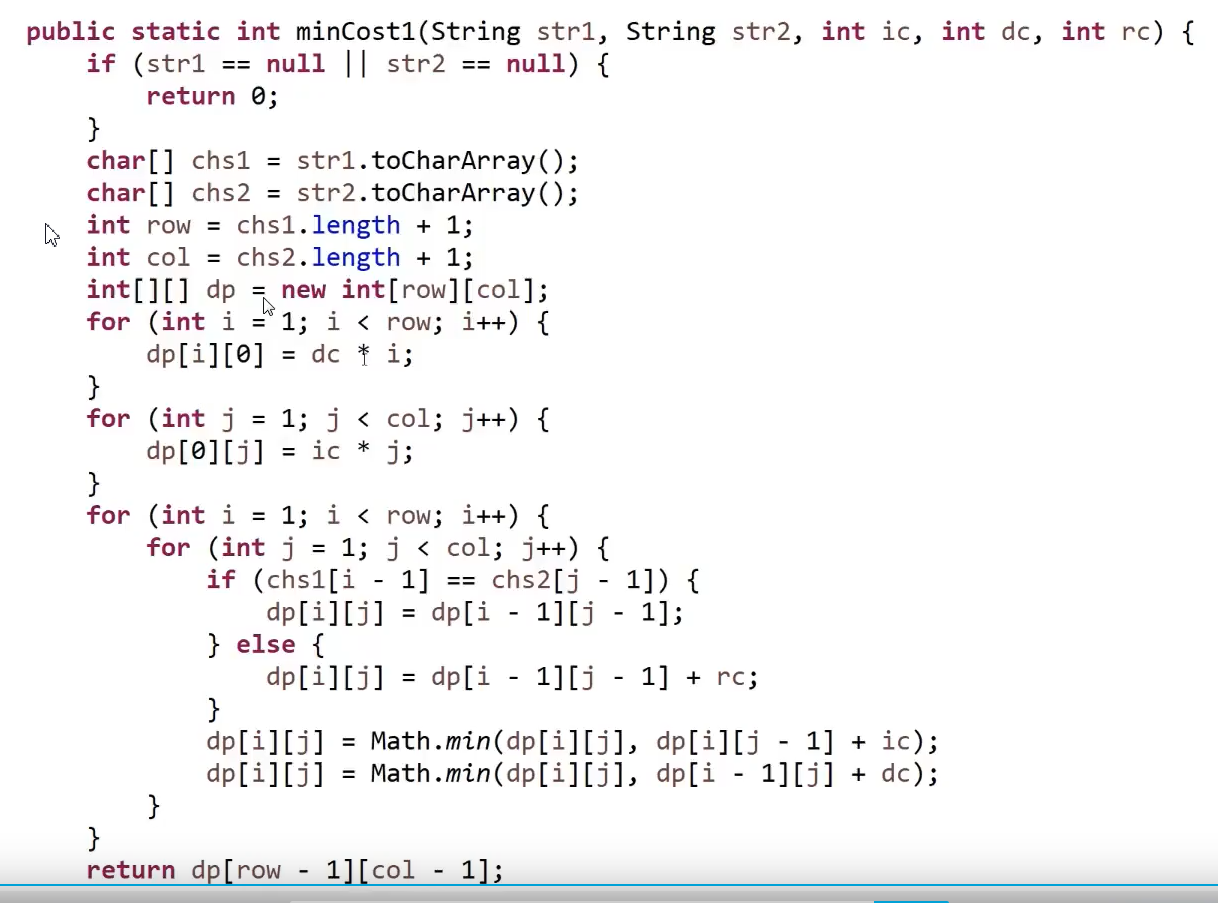

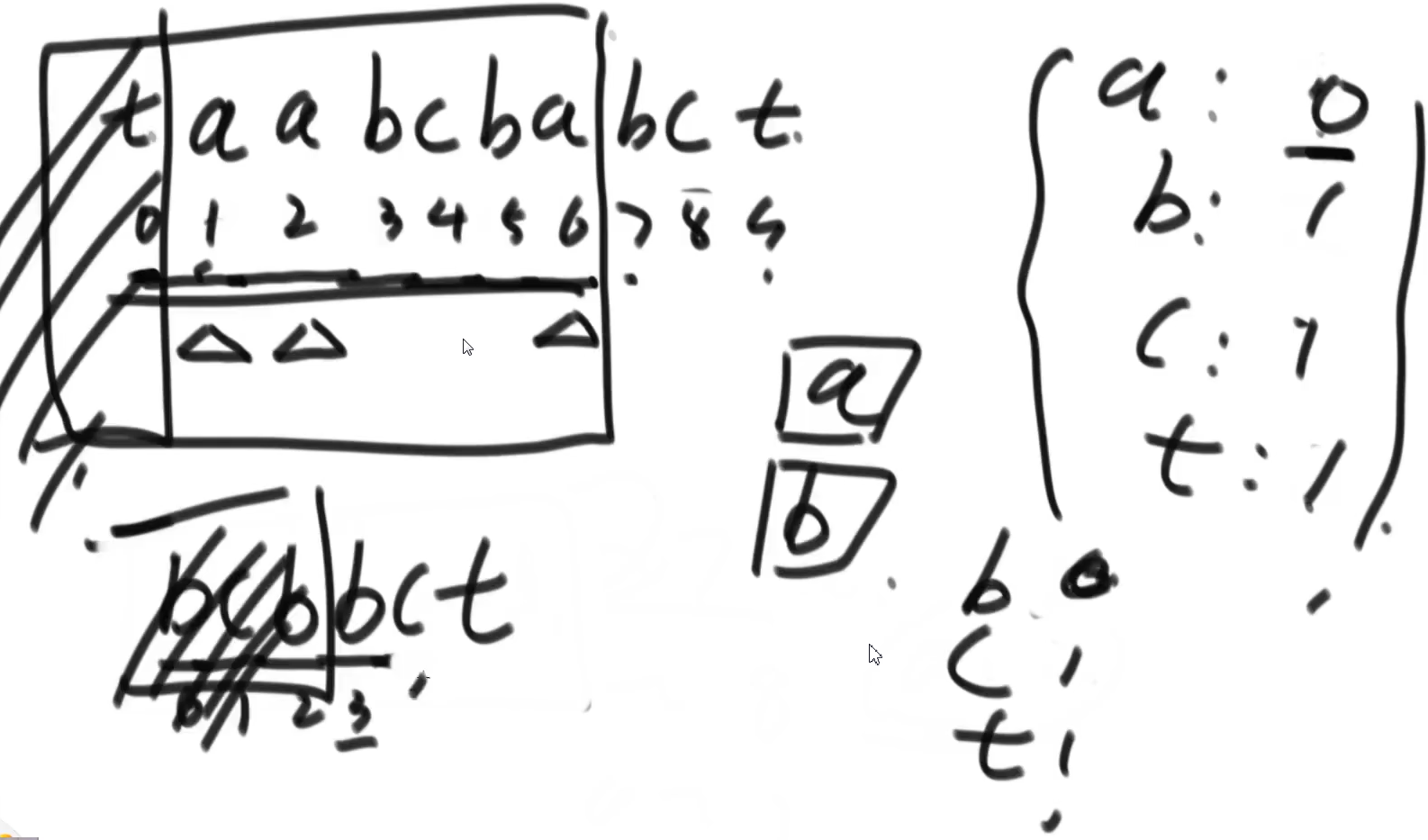
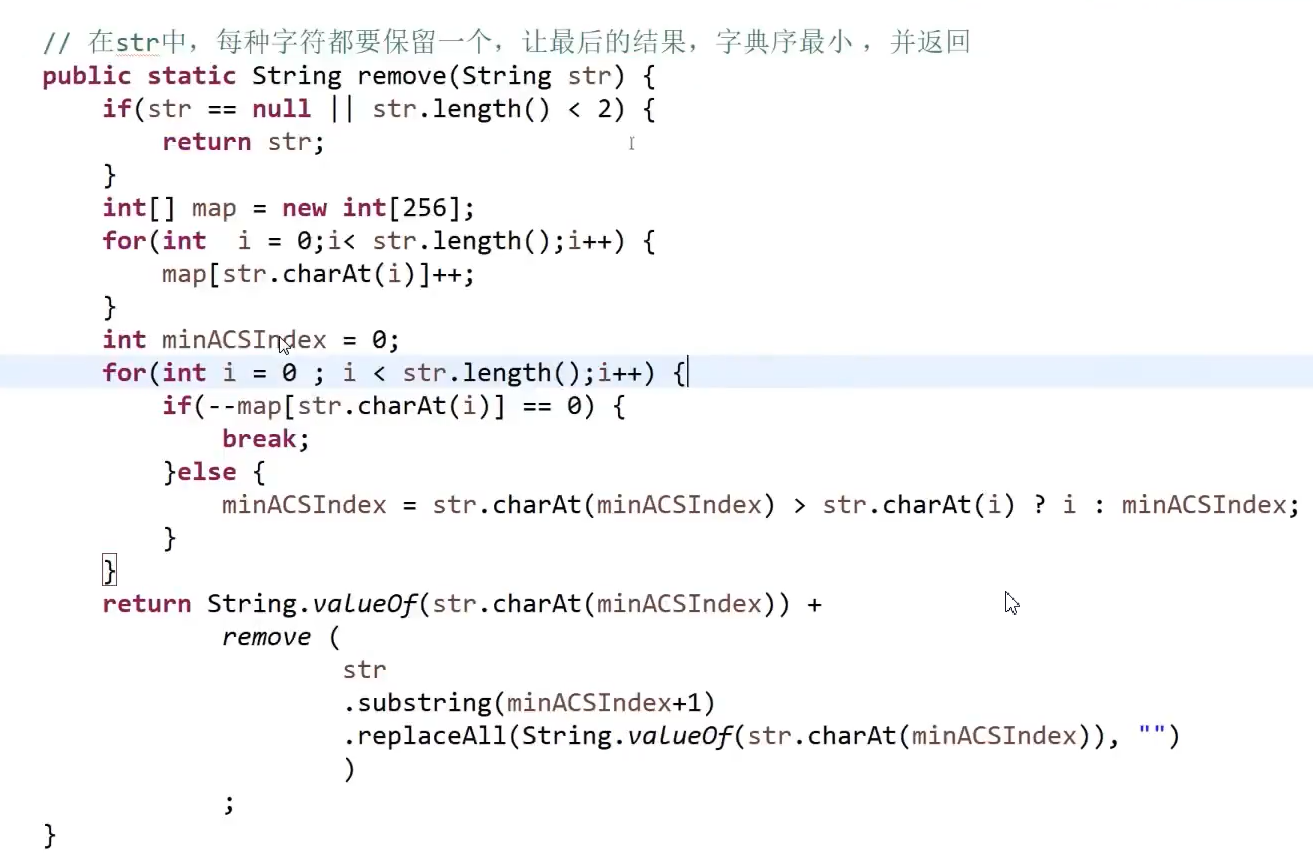

没有讲
中级提升班10

排序界的天花板
TimSort,和pfdrt

若有收获,就点个赞吧
0 人点赞
