二叉树:每个节点最多含有两个子树的树称为二叉树;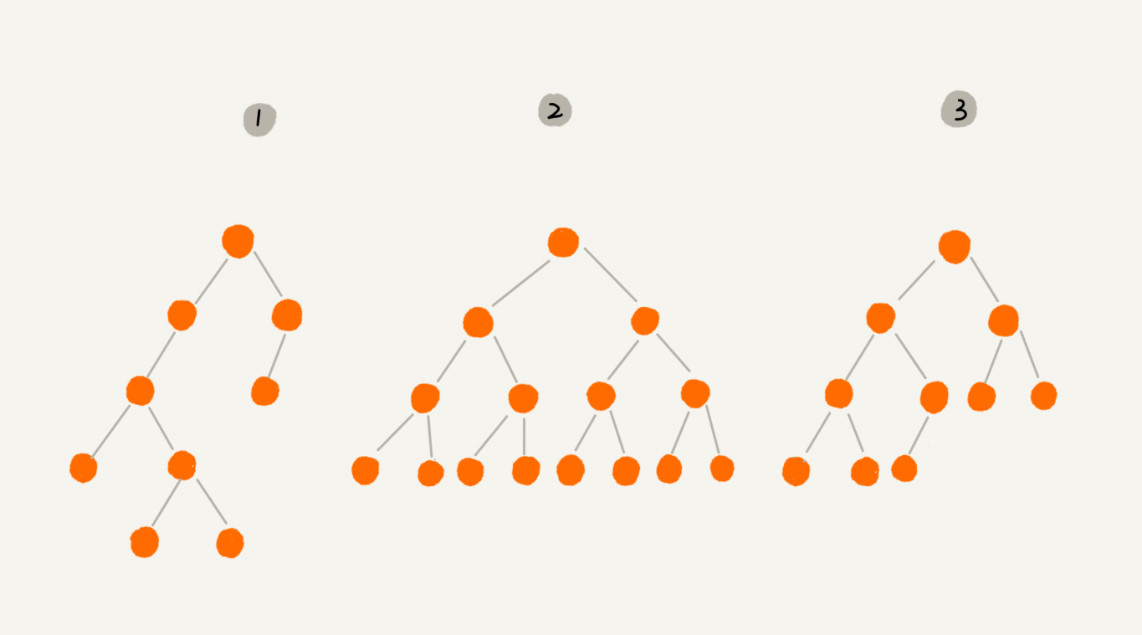
完全二叉树:(图3)叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层,其他层的节点个数都要达到最大,这种二叉树叫做完全二叉树。
满二叉树:(图2)叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点,这种二叉树就叫做满二叉树。
二叉树的遍历
深度优先 DFS (Depth First Search)
- 前序,中序,后序,指的是何时处理当前节点。
- 重要特性:中序遍历输出的结果是正序序列
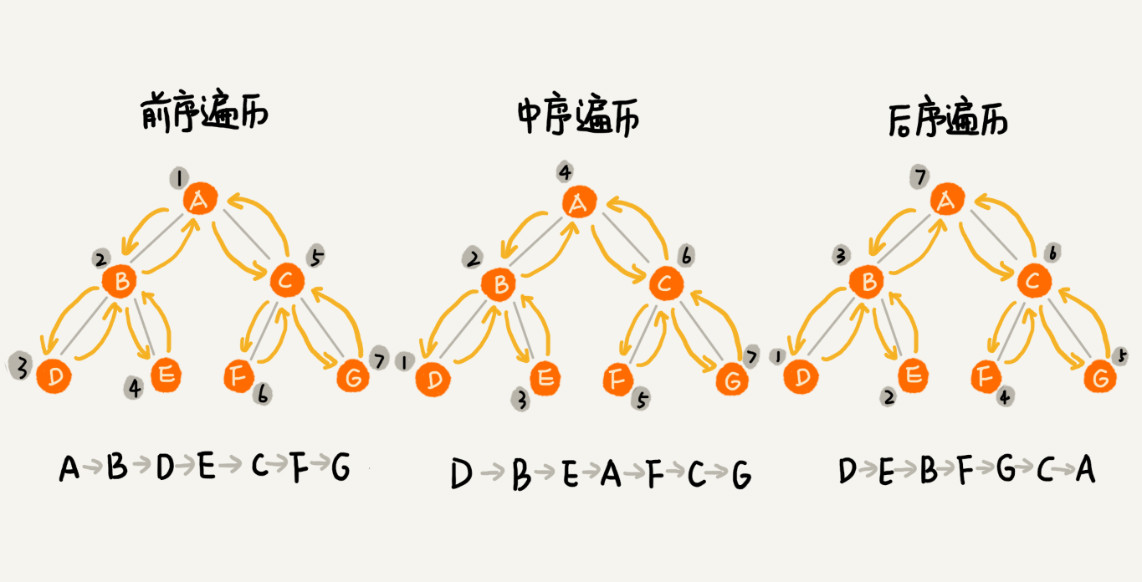
广度优先 BFS (Breadth FirstSearch)(层序遍历)
遍历当前层的队列,并将子节点加入下一层的队列中,直至队列为空
二叉搜索树 BST (Binary Search Tree)
要求:
- 在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值
-
基本操作:
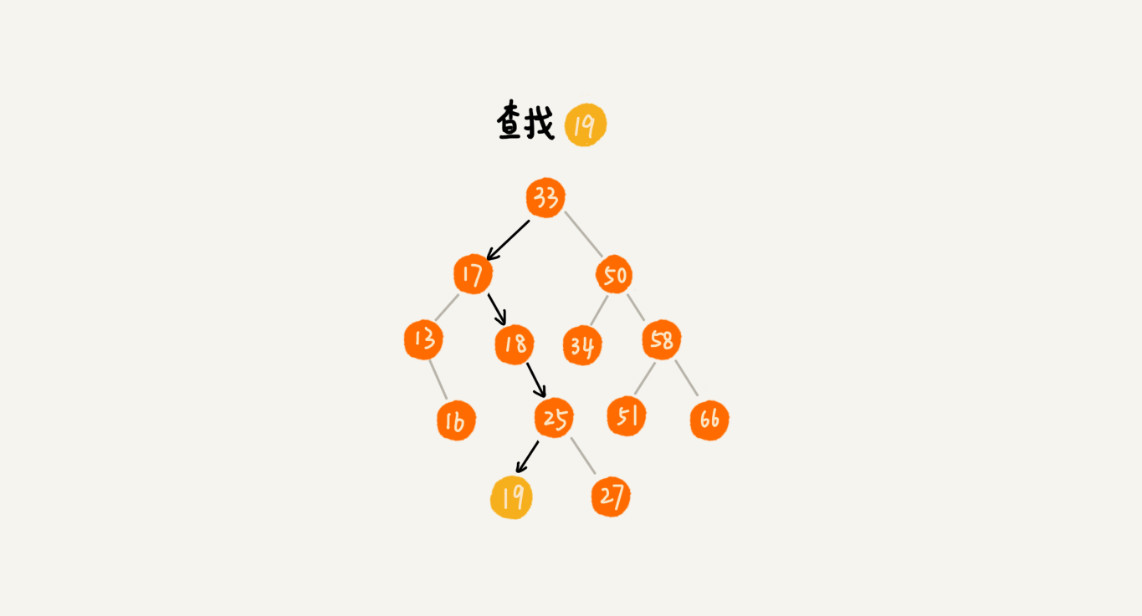
查找:
插入:
按照bst的查找规律遍历,有两种情况可以终止遍历,插入节点
val < node.Val && node.Left == nil
- val > node.Val && node.Right == nil
删除:
修改:
支持重复数据的二叉查找树
- 可以通过链表可以动态扩容的特性来处理,类似于hash表中解决hash冲突的做法
- 将相同的值,在插入的时候,判断为比原值大,插入到相同节点的右子树上
二叉查找树的时间复杂度分析
不同的二叉树结构,对应最大最小时间复杂度
如果恰好选择了最小或者最大的节点做root,则会退化为链表
增删查的最大最小时间复杂度为 O(n) 和 O(logn),分别对应退化为链表的情况,以及完全二叉树

平衡二叉查找树
极度不平衡的二叉查找树,它的查找性能肯定不能满足我们的需求,我们需要构建一种不管怎么删除、插入数据,在任何时候,都能保持任意节点左右子树都比较平衡的二叉查找树
发明平衡二叉查找树这类数据结构的初衷是,解决普通二叉查找树在频繁的插入、删除等动态更新的情况下,出现时间复杂度退化的问题。
所以,平衡二叉查找树中“平衡”的意思,其实就是让整棵树左右看起来比较“对称”、比较“平衡”,不要出现左子树很高、右子树很矮的情况。这样就能让整棵树的高度相对来说低一些,相应的插入、删除、查找等操作的效率高一些。
所以,如果我们现在设计一个新的平衡二叉查找树,只要树的高度不比 log2n 大很多(比如树的高度仍然是对数量级的),尽管它不符合我们前面讲的严格的平衡二叉查找树的定义,但我们仍然可以说,这是一个合格的平衡二叉查找树。
平衡二叉查找树的高度接近 logn,所以插入、删除、查找操作的时间复杂度也比较稳定,是 O(logn)。
常见二叉树的应用场景
- AVL树:平衡二叉树之一,应用相对其他数据结构比较少,windows对进程地址空间的管理用到了AVL
- 红黑树:平衡二叉树,广泛应用在C++STL中,比如map和set,Java的TreeMap
- B和B+树:主要用在文件系统以及数据库中做索引等
- Trie 树:用在统计和排序大量字符串中,一个典型应用是前缀匹配,比如下面这个很常见的场景,在我们输入时,搜索引擎会给予提示。还有比如IP选路,也是前缀匹配
-
问题 & 思考
散列 VS 二叉查找树,为什么很多结构要是用二叉树而不是hash散列?
- bst 中序遍历可以直接输出有序列表,hash不支持查询有序列表
- 散列表扩容耗时比平衡二叉树高,且遇到hash冲突时性能不稳定,平衡二叉树性能相对稳定
- hash冲突时以及hash操作本身耗时,导致并不一定比logn快
- 散列表的构造比二叉查找树要复杂,需要考虑散列函数的设计、冲突解决办法、扩容、缩容等。平衡二叉查找树只需要考虑平衡性这一个问题,而且这个问题的解决方案比较成熟、固定。
- 为了避免过多的散列冲突,散列表装载因子不能太大,特别是基于开放寻址法解决冲突的散列表,不然会浪费一定的存储空间。

若有收获,就点个赞吧
0 人点赞
