动作 policy 策略
动作是根据policy函数π随机抽样得到的
状态转移
环境根据状态转移函数p来抽样的
根据强化学习 学习策略函数 policy π
s a r
状态 动作 奖励
观测到小写字母表示 没观测到 大写字母表示 为随机变量
reward
return 回报 所有reward相加
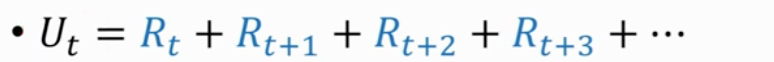
未来的奖励不值钱 折扣回报 折扣return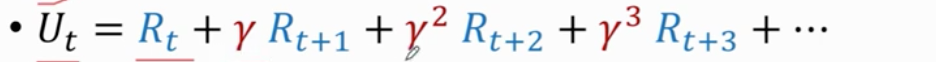
折扣率 是超参 需要自己调整

没有被观测到 大写字母R表示i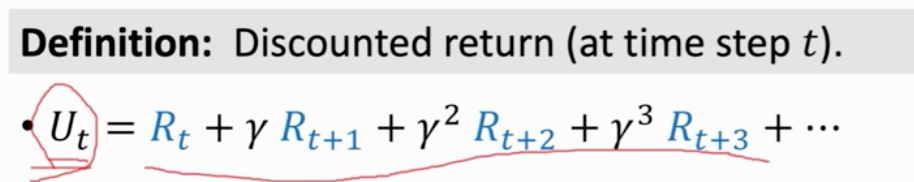
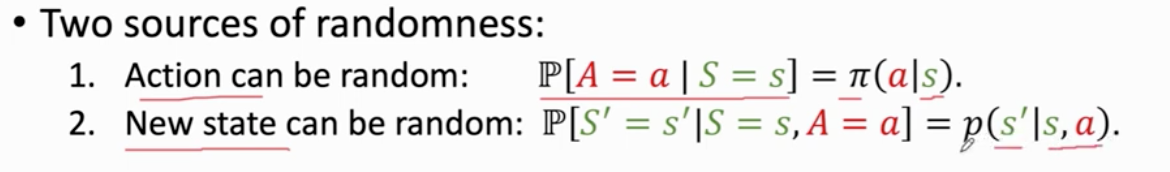
Ut与未来的动作At…和未来的状态St…相关
Ut是个随机变量 依赖于未来的动作 和 未来的状态
t时刻并不知道 Ut是什么
最优 消掉policy函数π 动作价值函数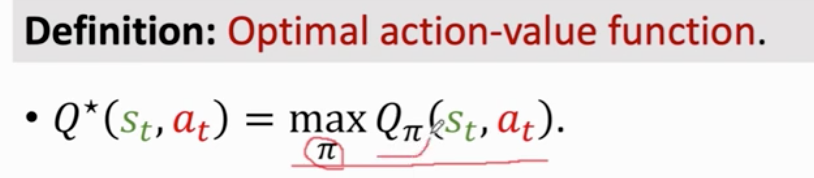
状态价值函数 告诉我们当前状态好不好

离散 和 连续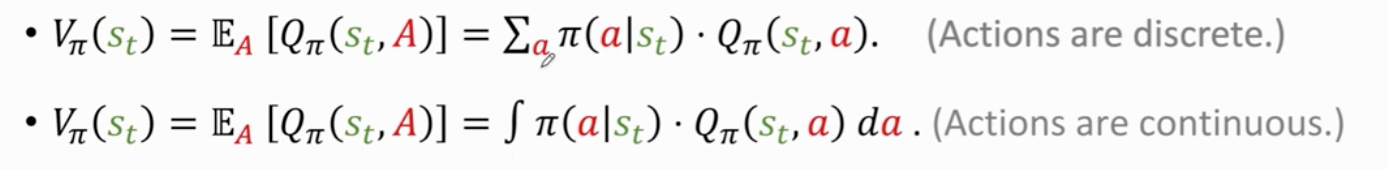
总结 两种价值函数
- 动作价值函数 与 policy 函数 π 状态 st 动作 at 有关
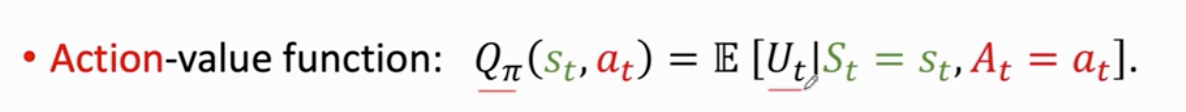
告诉我们 agent 处于 状态s时做出的动作a是否明智
状态价值函数 与policy函数 π 和 动作a 状态s 有关 与a 无关
评价当前状态是好是坏 是快赢了还是快输了
还可以评价policy函数 π的好坏 π越好 Vπ平均值越大
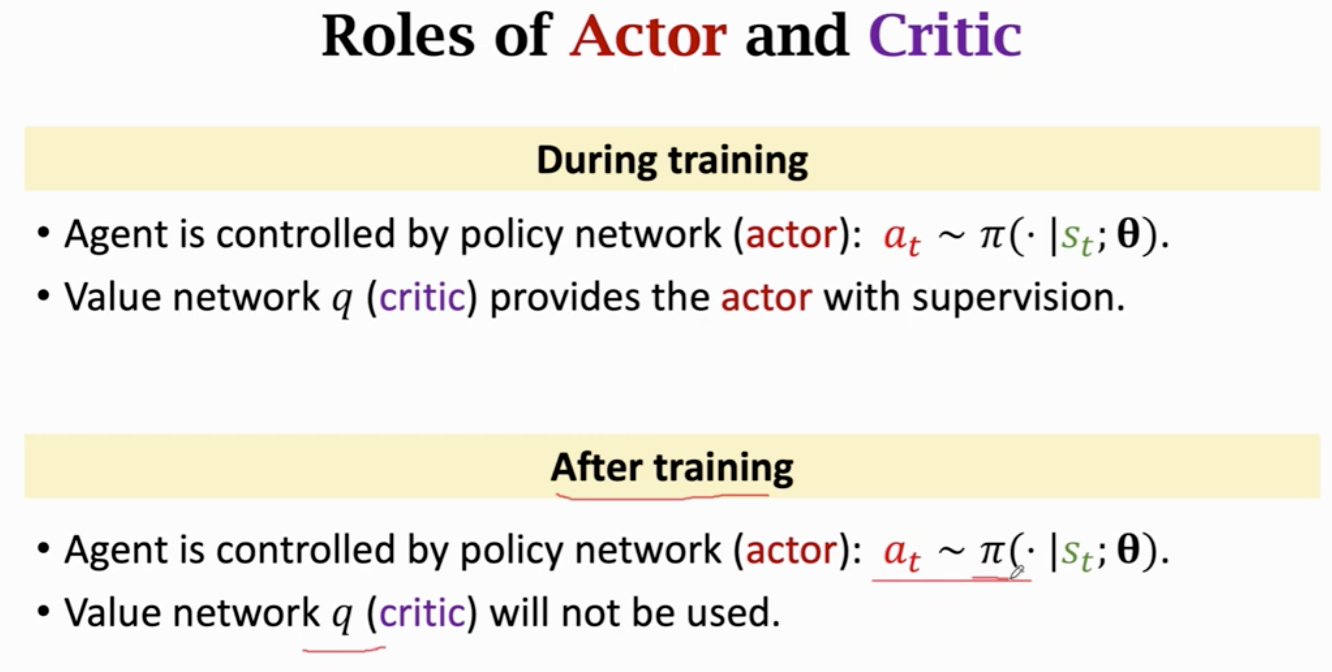
强化学习 学的是 policy 函数π 或最优动作价值函数
知道 π s输入 得到动作a
知道Q 就可以评价所用动作的好坏

DQN
Q star 函数给所有动作打分 与策略函数 π无关
价值学习方法
w 是参数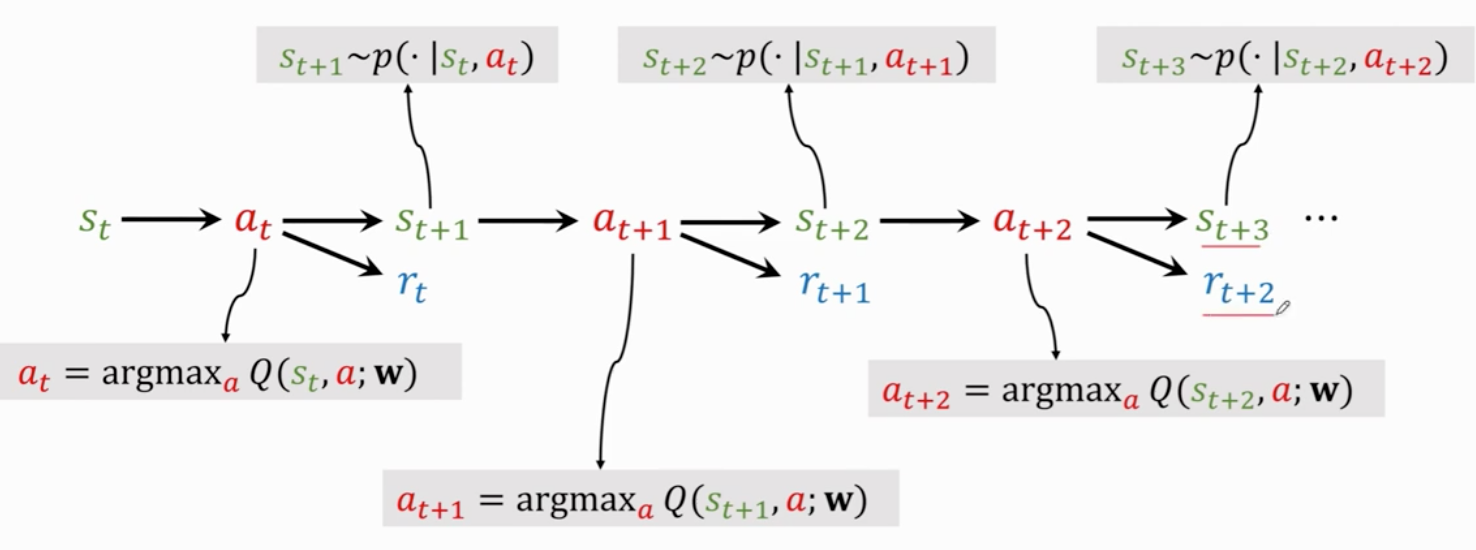
TD算法

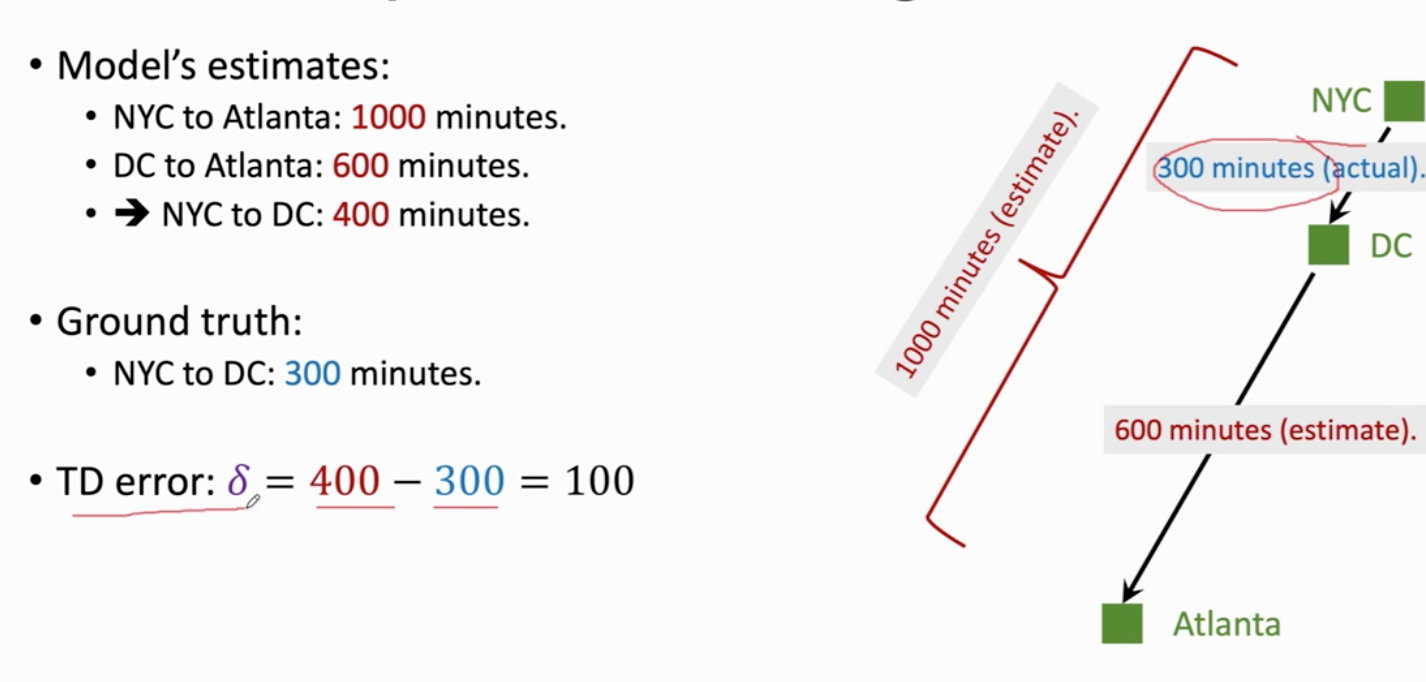

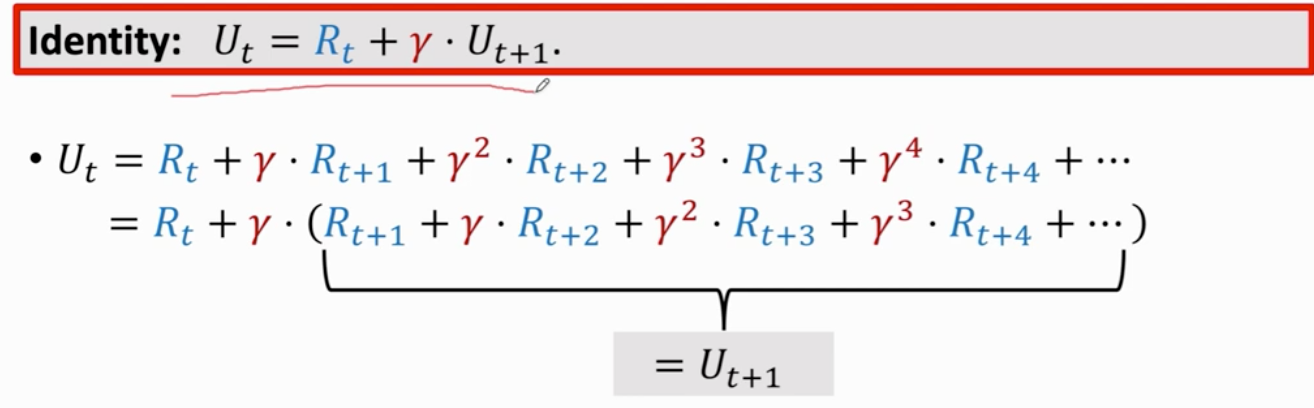

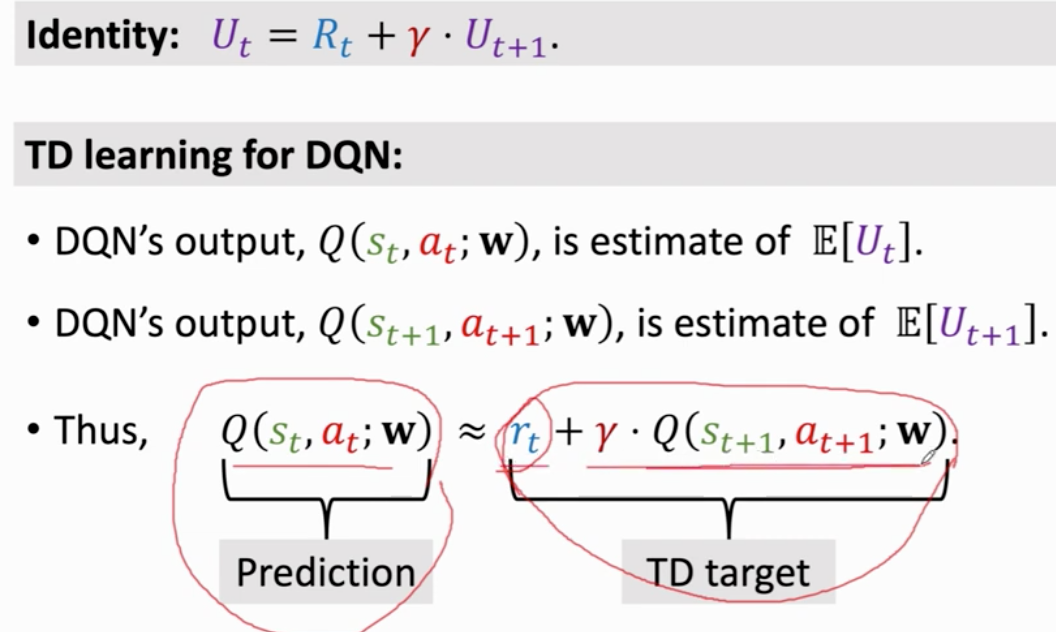

价值学习 动作价值函数 最优 与π无关
输入 观测状态s 输出 对每个动作的打分
通过奖励更新模型参数 TD 算法
首先观测状态st和已经执行的动作 at
用dqn做一次计算 输入状态st 输出对动作at的打分 qt
用反向传播对dqn求导 得到参数dt
agent执行动作at 环境给出st+1 和奖励rt
计算td target yt
做梯度下降更新参数 w
策略学习
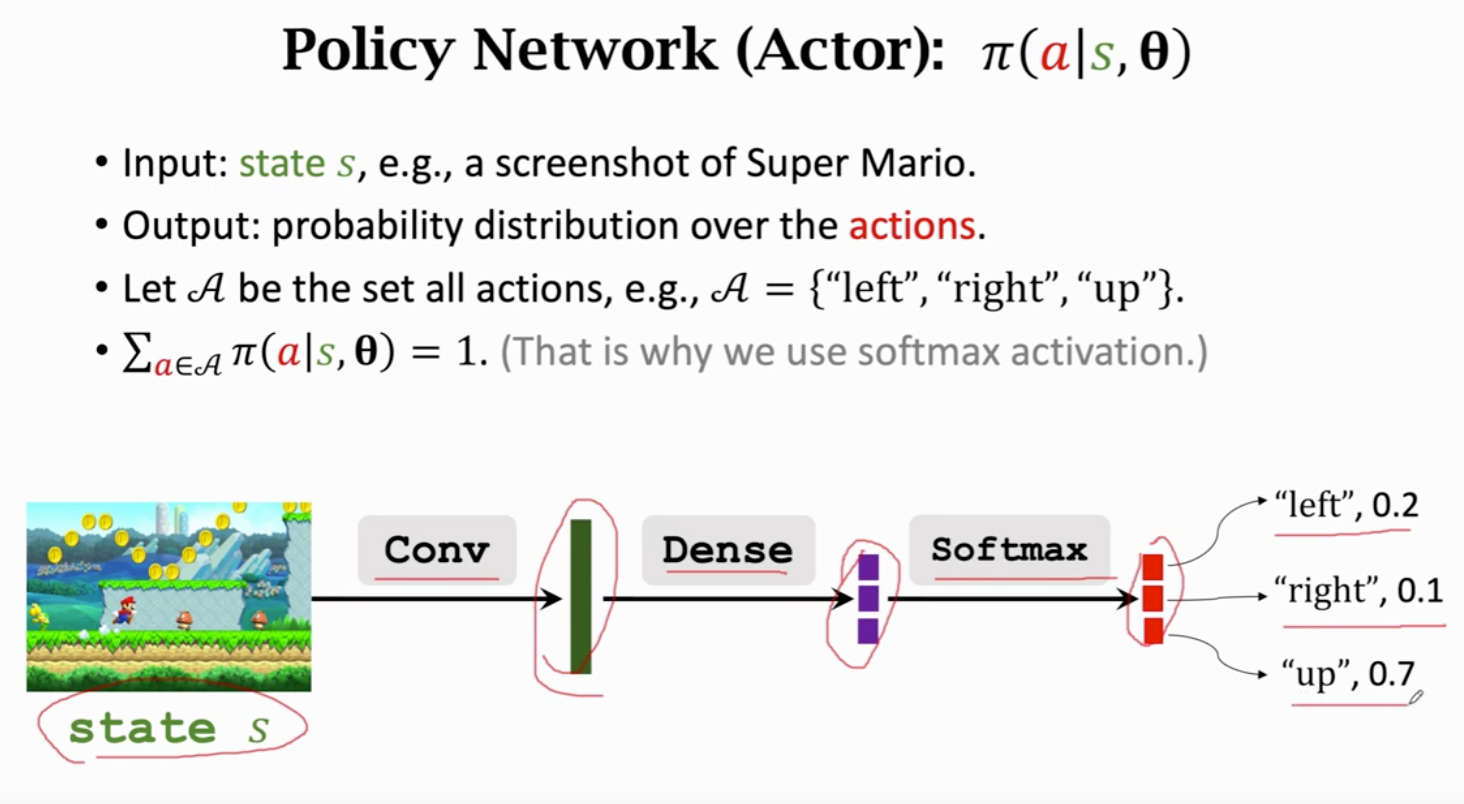
策略函数
概率密度函数 做随机抽样
seita 初始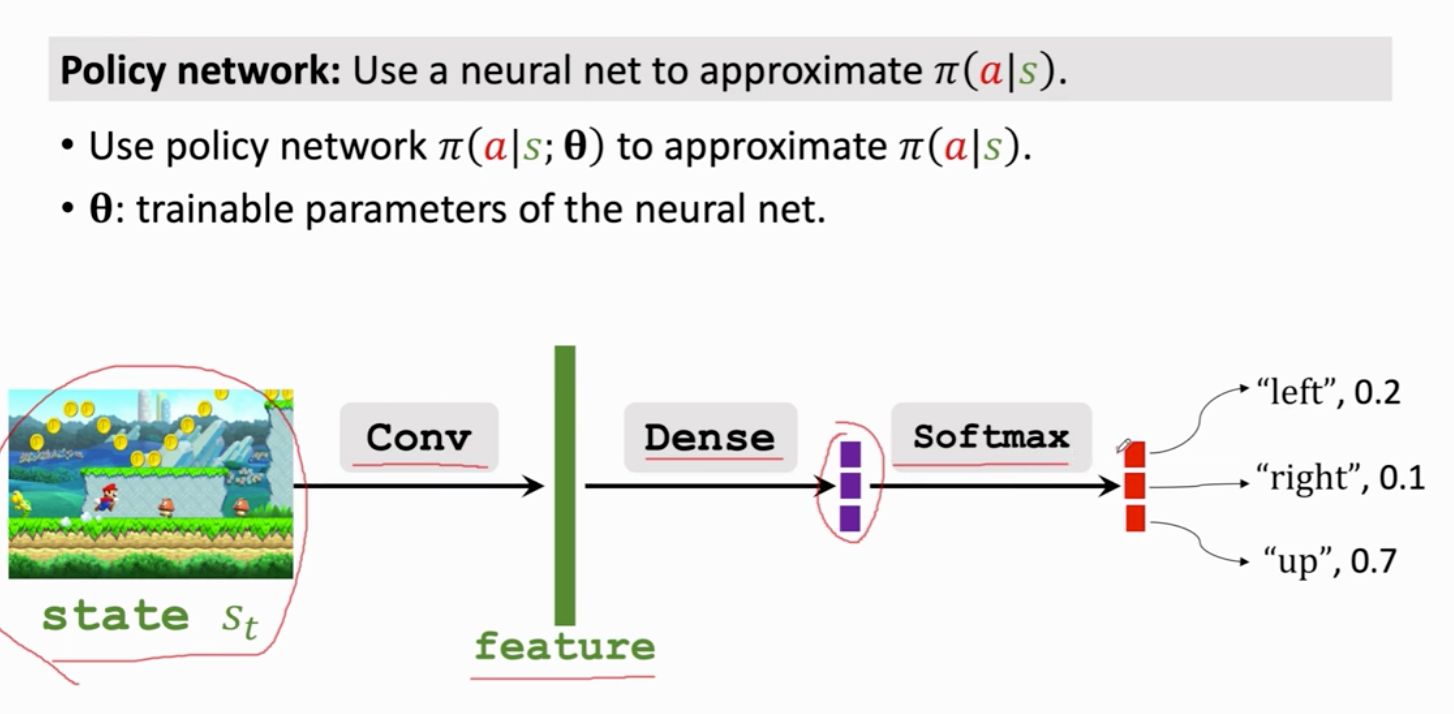
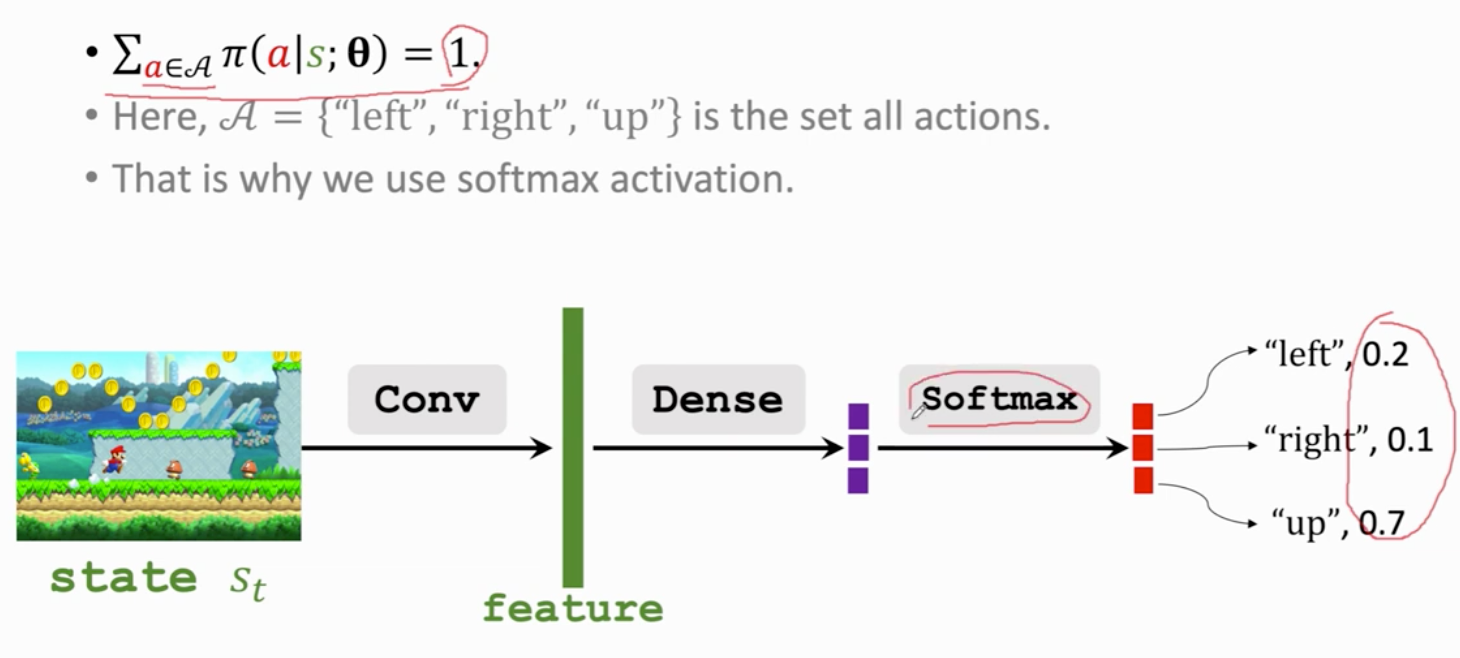
softmax输出的都是正数 且加和为1
Qπ是Ut的条件期望 把 t+1时刻的s和a都消掉了
只依赖当前时刻的状态s 和动作a 还依赖策略函数π
评价在st状态下做出动作at 的好坏程度
Vπ 是 Qπ的期望 积掉动作A(随机变量 概率密度函数π)
Vπ评价π的好坏 值大说明π好


梯度上升
策略网络 策略梯度

π是概率密度函数





策略学习
π
第三节
π 策略函数 计算动作的概率
Qπ 判断动作的好坏 给动作打分
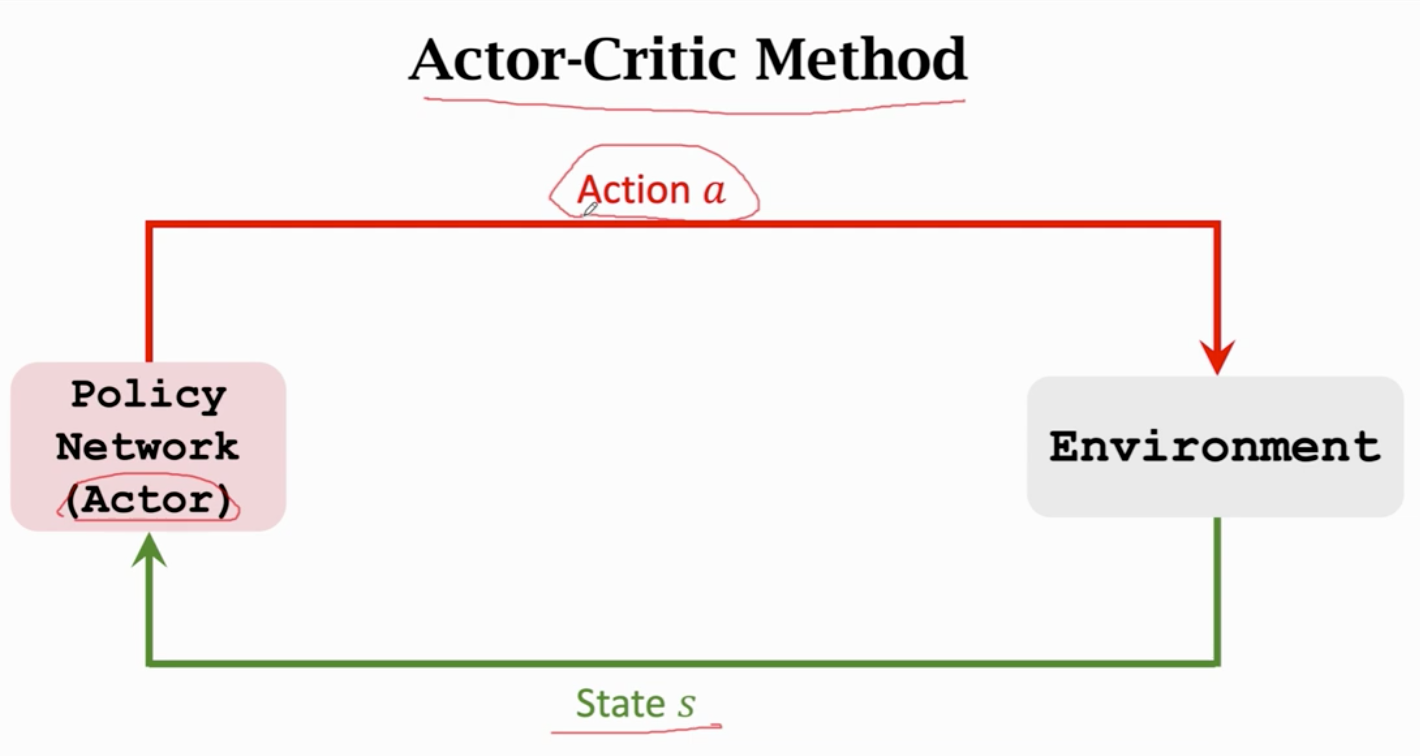
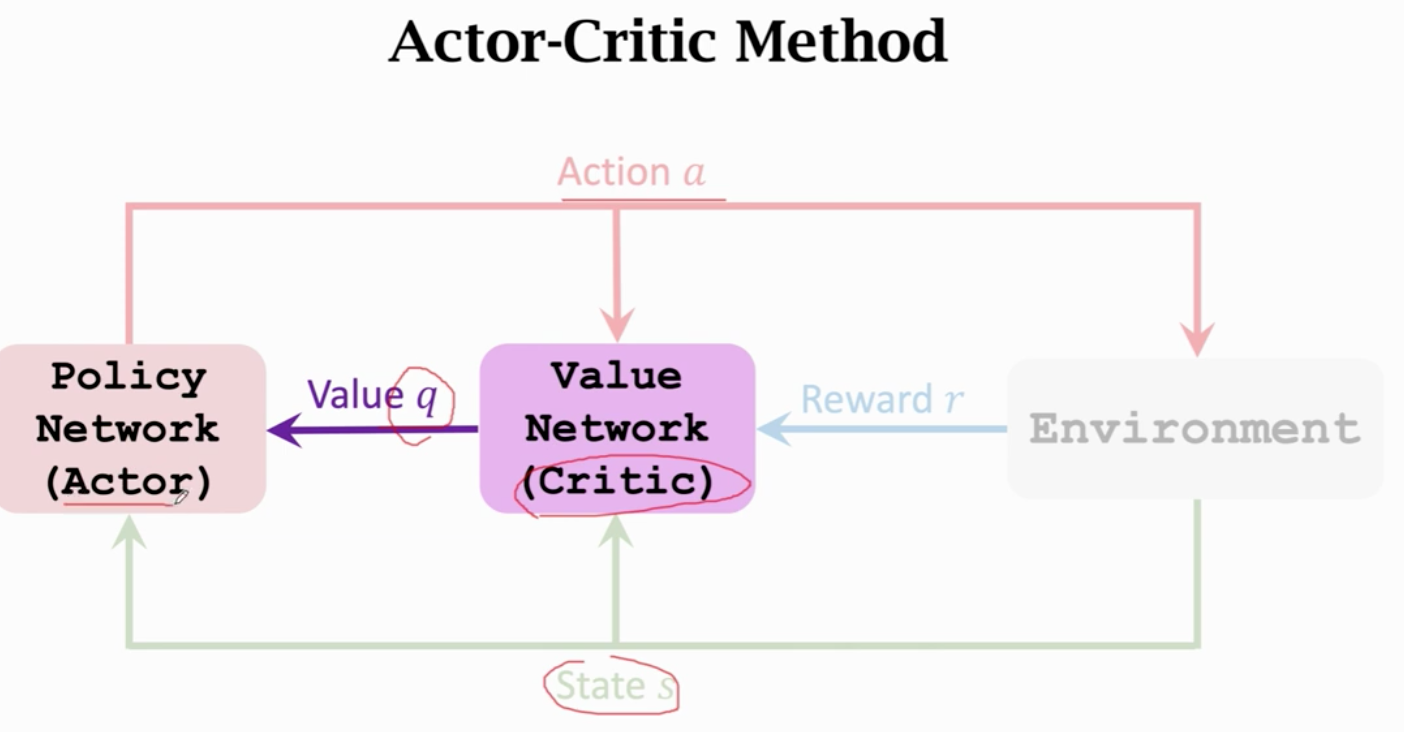
π相当于运动员 q相当于裁判
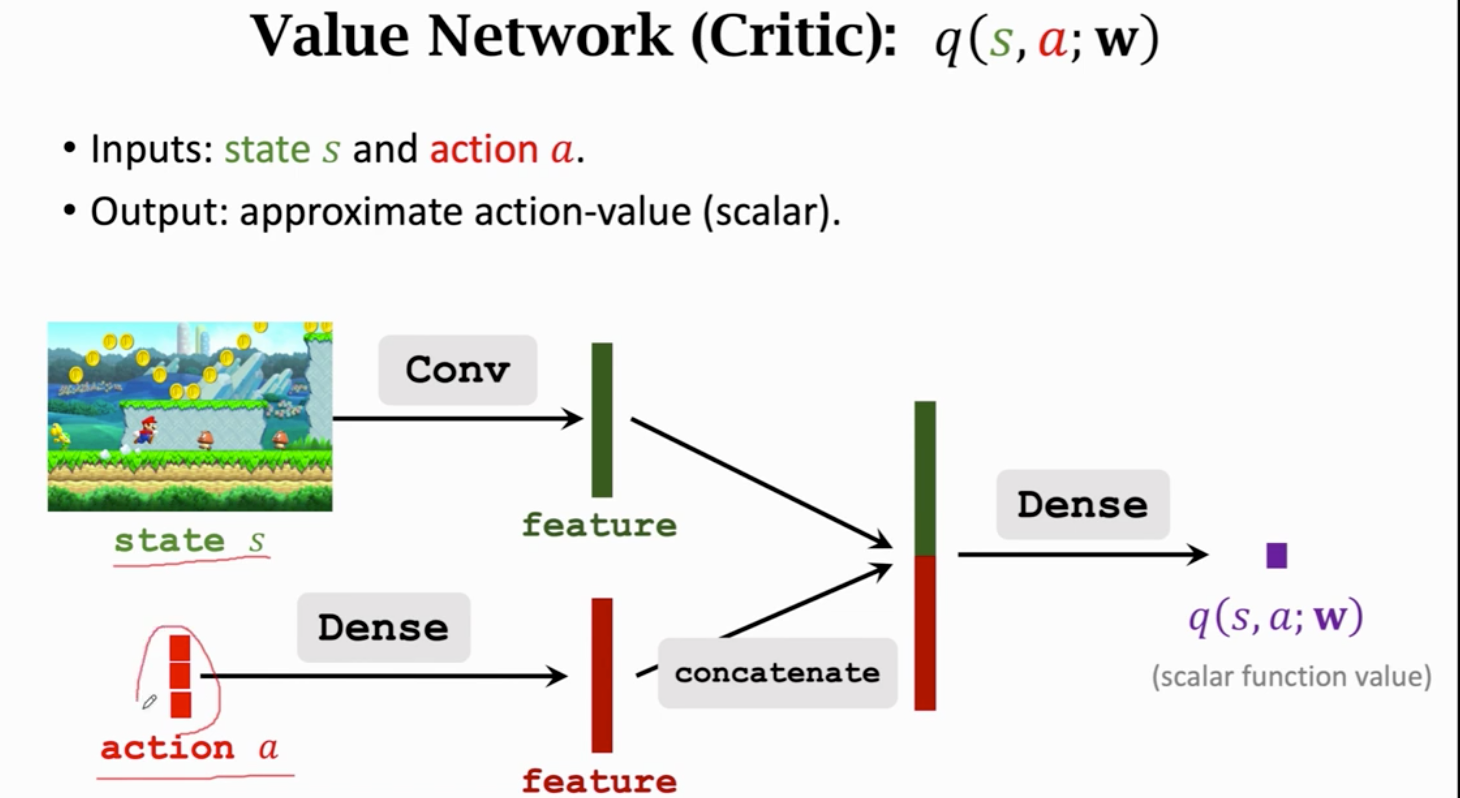


价值网络给动作打分
td算法更新q
策略网络

梯度上升更新参数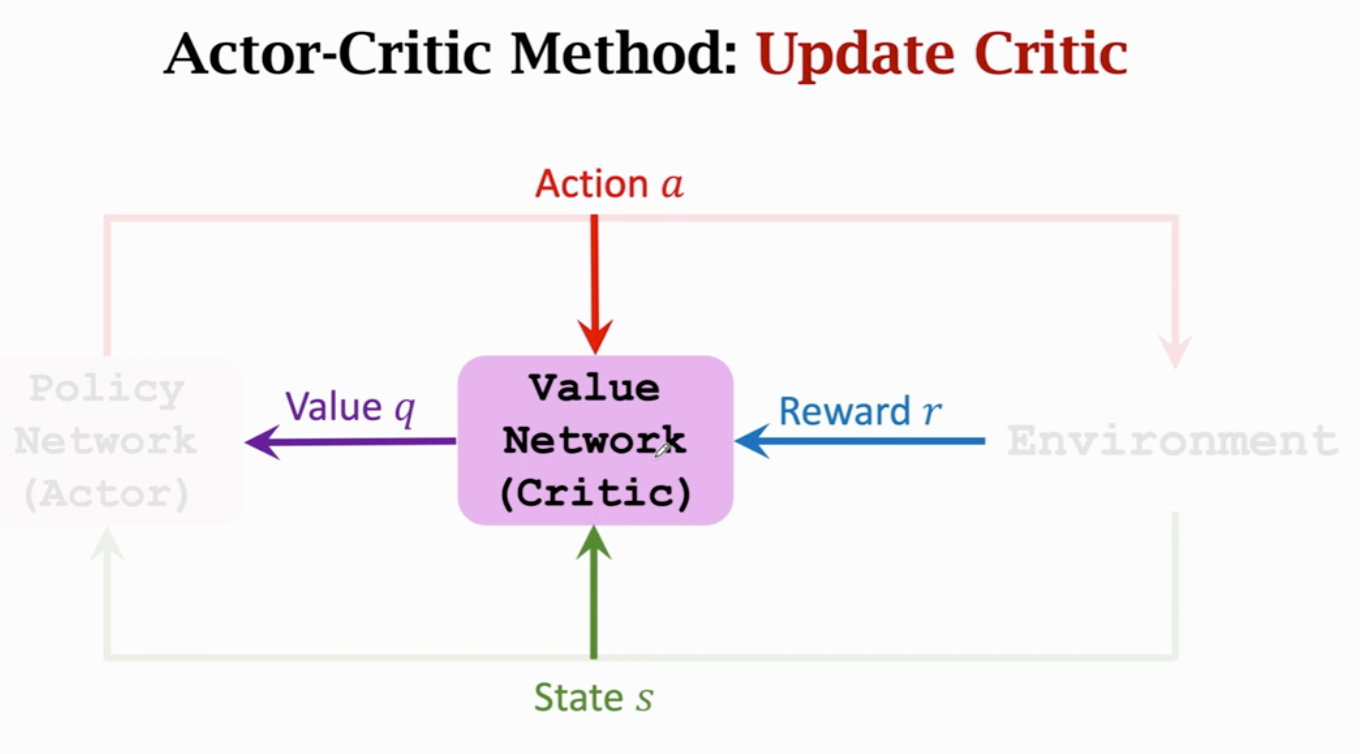
td算法跟新价值网络参数 让裁判打分更精准




若有收获,就点个赞吧
0 人点赞
