1 - 并发容器
1.1 - 分类
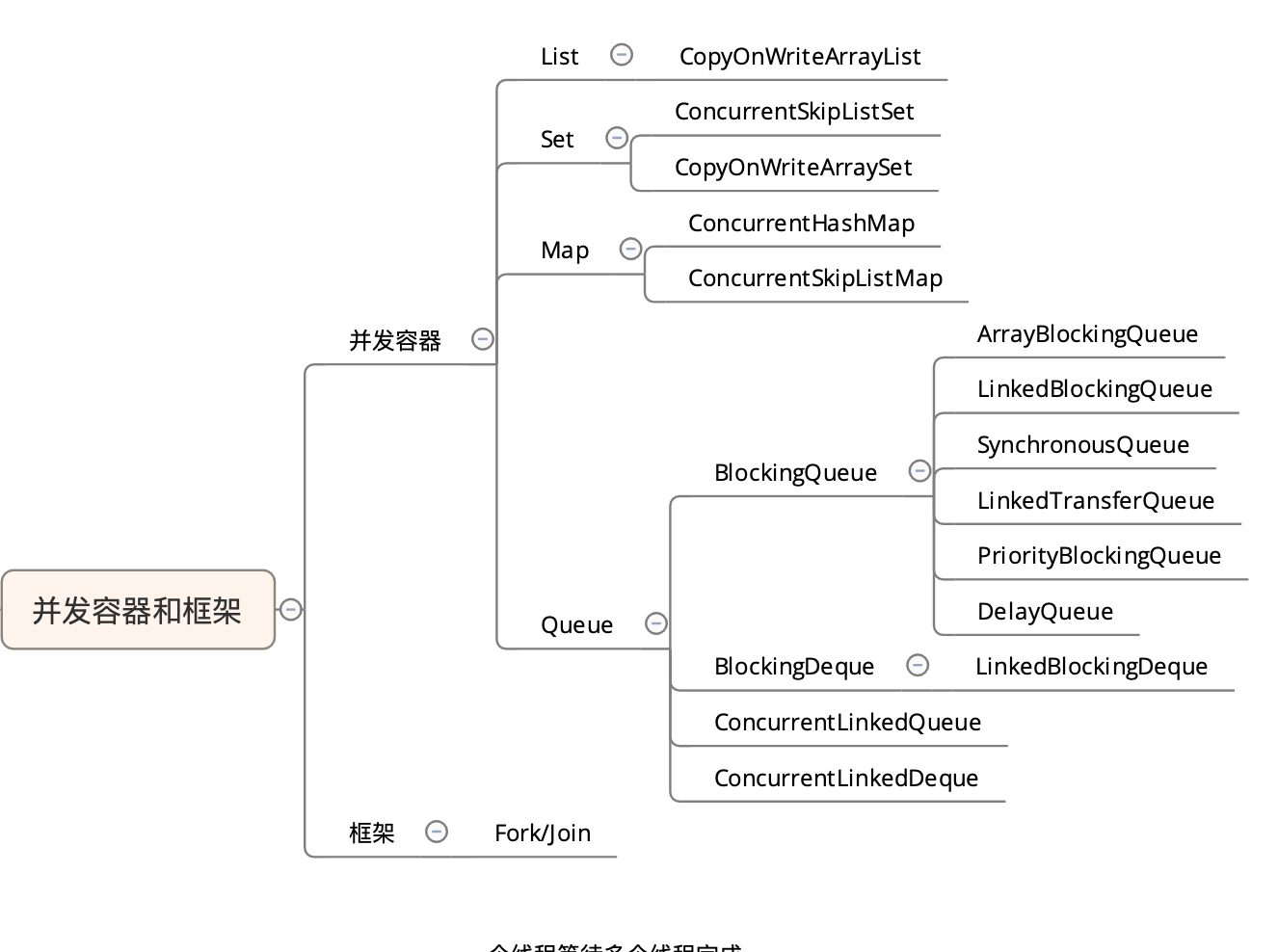
1.2 - List
1.2.1 - CopyOnWriteArrayList
CopyOnWrite含义: 写的时候会将共享变量复制一份. 这样做的好处是读的时候是完全无锁的.
实现原理:
- 内部维护一个数组array. 所有的读操作都是基于这个array进行
- 当有写操作时, 加一把ReentrantLock, 然后把array复制一份构造出一个新数组, 再让array指向这个新数组. 而此时进行的读操作, 是基于原先的array, 所以读操作时无锁的.
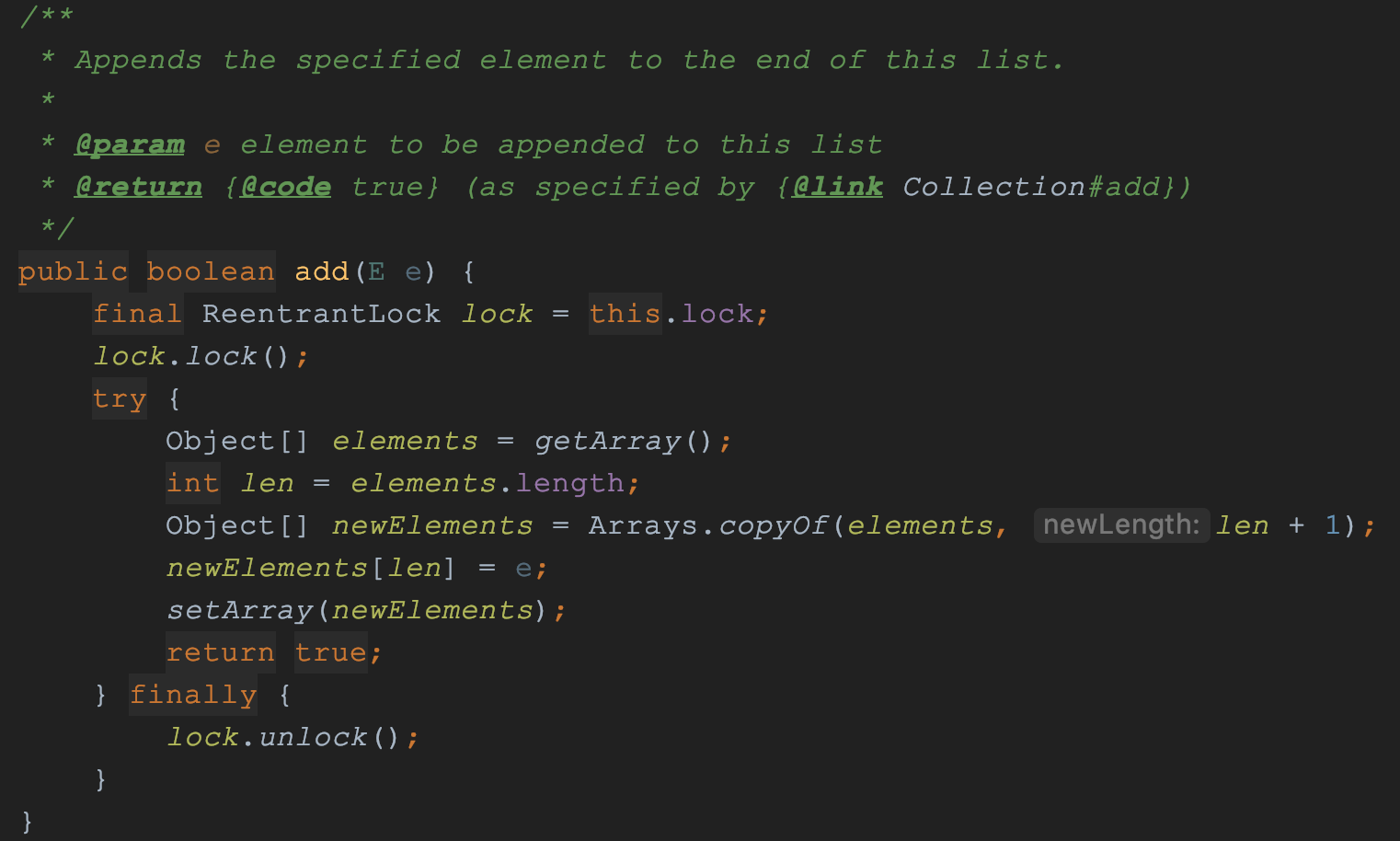
需要注意的是:
- 应用场景: 适用于读多写少的场景, 而且能够容忍读写的短暂不一致
- array字段是volatile修饰, 根据happens-before原则. 当array指向新数组后, 后续读的线程都会读到array最新的数据.
- 写操作包含原数组的复制, 如果此时有并发读写, 在写线程还没有执行setArray()方法时发生了线程切换,
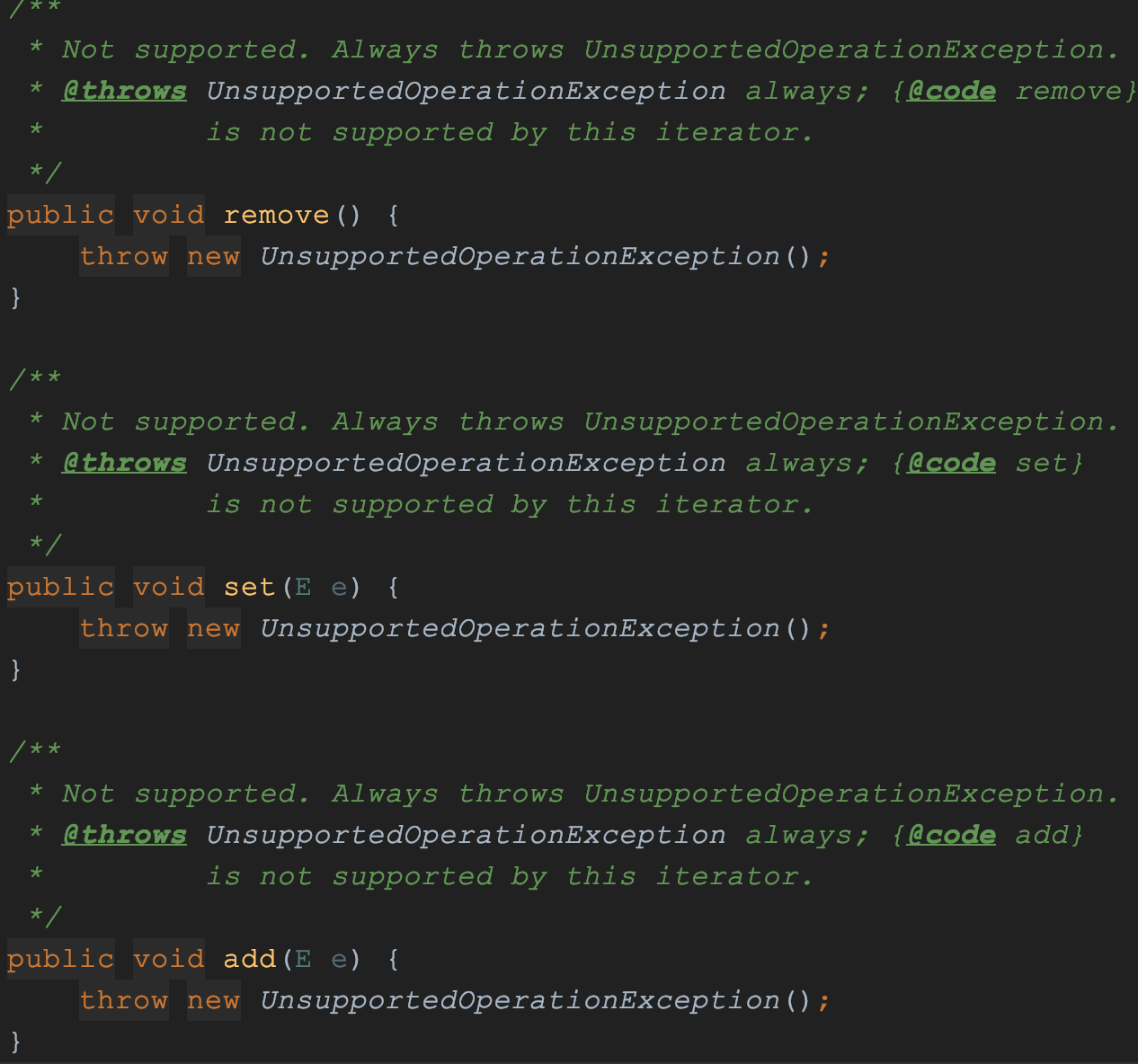
- 迭代器是只读, 遍历时无法进行增删改操作. 迭代器遍历的仅仅是数据的快照.
1.3 - Map
Map接口的两个实现是ConcurrentHashMap和ConcurrentSkipListMap.
- 前者的key是无序的, 后者key是有序
- 两者的key和value都不允许是null
我们知道, HashMap在多线程环境下会导致死循环, CPU飙升. 如果仍然需要在多线程环境下使用map结构,通常有三种办法:
- Hashtable. 线程安全类, 几乎所有的方法都添加了synchronized方法
- Collections.synchronizedMap: 线程安全类, 对方法添加synchronized方法
- ConcurrentHashMap.
Hashtable和Collections.synchronizedMap的方法中都添加了synchronized关键字, 相当于对整个hash表加了一把全局锁, 对元素的所有操作都需要竞争同一把锁, 在多线程竞争激烈的情况下性能会很差.
HashMap为什么不安全: https://mp.weixin.qq.com/s/yxn47A4UcsrORoDJyREEuQ
1.3.1 - ConcurrentHashMap
1.3.2.1 - JDK7中的实现
JDK7中ConcurrentHashMap使用分段锁的思想.
- 将HashMap中的数组分成多个小数组
- 每个小数组中又有多个HashEntry(冲突链表)
- 小数组叫做Segment, 继承自ReentrantLock
put操作:
- 计算key的hash值, 并以此来确定目标segment
- 获取到segment之后, 获取独占锁
- 根据key的hash
1.3.2.2 - JDK8中的实现
在JDK8中, 取消了ConcurrentHashMap的Segment分段锁的设计. 转而使用cas + synchronized来实现.
1.3.2 - ConcurrentSkipListMap
1.4 - Queue
2 - 并发框架

若有收获,就点个赞吧
0 人点赞
