做大数据的人应该对Hive不陌生,Hive应该是大数据SQL引擎的鼻祖。历经多个版本的改进,现在的Hive3已经具备比较完善的ACID功能,能够同时满足交互式查询和ETL 两种场景。
那怎么来用hive呢 ?如果你还在用beeline来跑hive sql的话,你就弱爆了,来看看强大的Zeppelin能够给你带来什么吧。
配置Hive Interpreter
未启用Shiro
未启用kerbose
| 配置项 | 配置值 |
|---|---|
| default.url | jdbc:hive2://localhost:10000/default |
| default.driver | org.apache.hive.jdbc.HiveDriver |
| default.user | hadoop |
dependencies: org.apache.hive:hive-jdbc:2.3.4
启用kerbose
| 配置项 | 配置值 |
|---|---|
| default.url | jdbc:hive2://emr-header-1:10000/default;principal=hive/emr-header-1.cluster-46727@EMR.46727.COM |
| default.driver | org.apache.hive.jdbc.HiveDriver |
| zeppelin.jdbc.auth.type | KERBEROS |
| zeppelin.jdbc.auth.kerberos.proxy.enable | false |
| zeppelin.jdbc.keytab.location | /etc/ecm/hive-conf/hive.keytab |
| zeppelin.jdbc.principal | hive/emr-header-1.cluster-46727@EMR.46727.COM |
dependencies: org.apache.hive:hive-jdbc:2.3.4
dependencies: org.apache.hive:hive-exec:2.3.4
启用shiro
未启用kerbose
启用kerbose
| 配置项 | 配置值 |
|---|---|
| default.url | jdbc:hive2://emr-header-1:10000/default;principal=hive/emr-header-1.cluster-46727@EMR.46727.COM |
| default.driver | org.apache.hive.jdbc.HiveDriver |
| default.proxy.user.property | hive.server2.proxy.user |
dependencies: org.apache.hive:hive-jdbc:2.3.4
| 配置项 | 配置值 |
|---|---|
| default.url | jdbc:hive2://emr-header-1:10000/default;principal=hive/emr-header-1.cluster-46727@EMR.46727.COM |
| default.driver | org.apache.hive.jdbc.HiveDriver |
| zeppelin.jdbc.auth.type | KERBEROS |
| zeppelin.jdbc.auth.kerberos.proxy.enable | true |
| default.proxy.user.property | hive.server2.proxy.user |
| zeppelin.jdbc.keytab.location | /etc/ecm/hive-conf/hive.keytab |
| zeppelin.jdbc.principal | hive/emr-header-1.cluster-46727@EMR.46727.COM |
dependencies: org.apache.hive:hive-jdbc:2.3.4
dependencies: org.apache.hive:hive-exec:2.3.4
Interpreter 是Zeppelin里最重要的概念,每一种Interpreter对应一个引擎。Hive对应的Interpreter是Jdbc Interpreter, 因为Zeppelin是通过Hive的Jdbc接口来运行Hive SQL。
接下来你可以在Zeppelin的Interpreter页面配置Jdbc Interpreter来启用Hive。首先我想说明的是Zeppelin的Jdbc Interpreter可以支持所有Jdbc协议的数据库,Zeppelin 的Jdbc Interpreter默认是连接Postgresql。
启动Hive,可以有2种选择
- 修改默认jdbc interpreter的配置项(这种配置下,在Note里用hive可以直接
%jdbc开头) - 创建一个新的Jdbc interpreter,命名为hive (这种配置下,在Note里用hive可以直接
%hive开头)
这里我会选用第2种方法。我会创建一个新的hive interpreter,然后配置以下基本的属性(你需要根据自己的环境做配置)
| 配置项 | 配置值 |
|---|---|
| default.url | jdbc:hive2://localhost:10000/default |
| default.driver | org.apache.hive.jdbc.HiveDriver |
| default.user | |
| default.password |
hive.driver 配置成 org.apache.hive.jdbc.HiveDriver, 因为Zeppelin没有把Hive打包进去,所以默认情况下找不到这个Class的,你需要在这个Interpreter中添加dependency,如下图所示:
hive.url的默认配置形式是 jdbc:hive2://host:port/<db_name>, 这里的host是你的hiveserver2的机器名,port是 hiveserver2的thrift 端口 (如果你的hiveserver2用的是binary模式,那么对应的hive配置是hive.server2.thrift.port (默认是10000),如果是http模式,那么对应的hive配置是hive.server2.thrift.http.port,(默认是10001) 。db_name是你要连的hive 数据库的名字,默认是default。
到此为止,你就可以连接Hive数据库了,下图是一个简单的例子。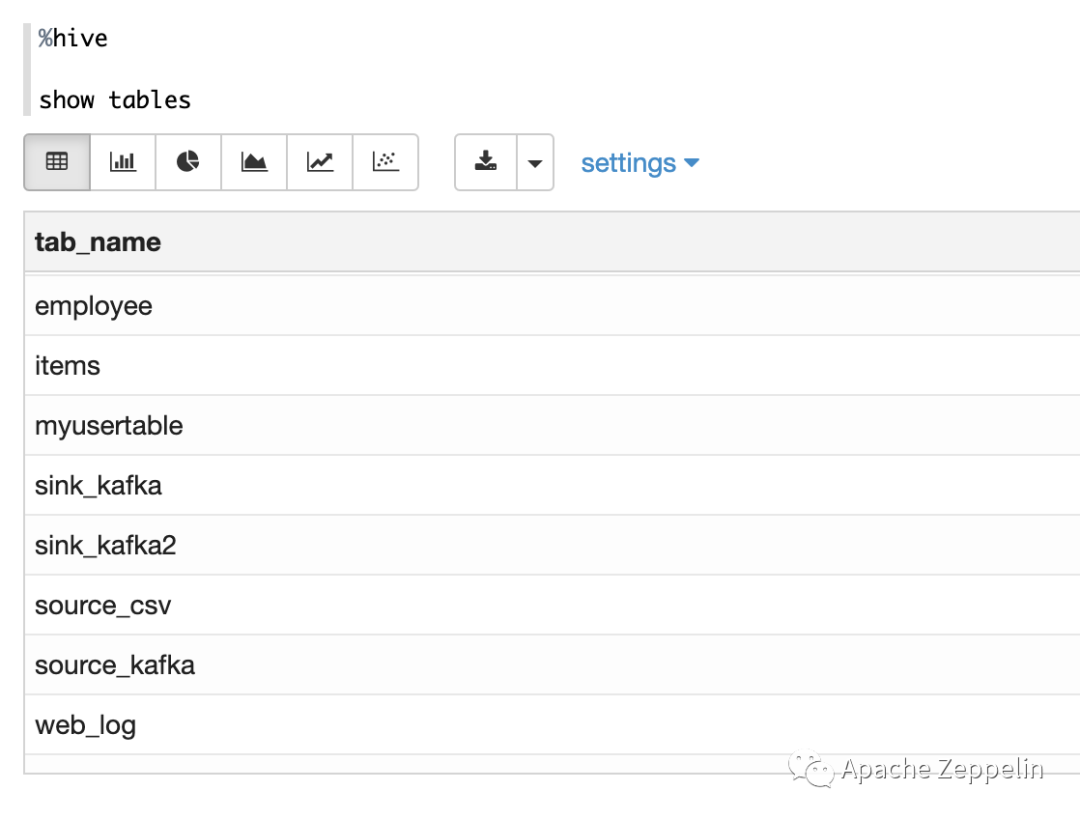
高级功能
看到这边,你可能会说Zeppelin不就是连接hive jdbc来运行sql嘛,也没什么特别的啊。稍安勿躁,接下来我们来看看除了以上基本sql的执行功能,Zeppelin的Jdbc Interpreter还能为Hive做什么:
- Dynamic Forms
- 支持一次运行多条SQL语句
- 支持并发运行多条SQL语句
- 展示Hive Job运行过程log
- 关联Job URL
- Rest API 运行 Hive SQL
Dynamic Forms
Dynamic Forms 是Zeppelin的一个高级功能,允许用户在代码中插入UI控件来允许用户定制化你的代码。Jdbc Interpreter支持这一功能,用户可以定制SQL,下面是一个下拉框的例子。
Zeppelin也支持文本框,Checkbox,具体可以参考 http://zeppelin.apache.org/docs/0.8.0/usage/dynamic_form/intro.html
支持一次运行多条SQL语句
默认情况下,Zeppelin支持在一个Paragraph中按顺序运行多条SQL语句。每条SQL语句以分号隔开,如下图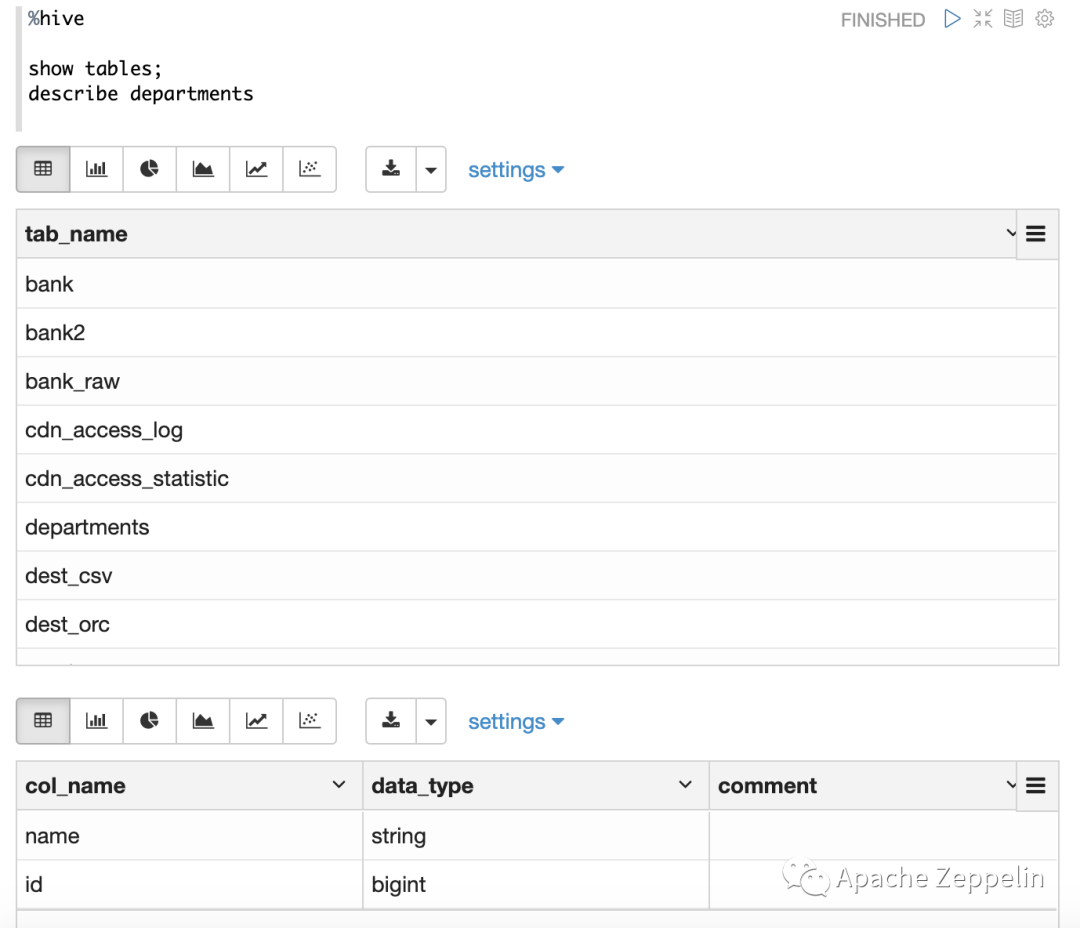
支持并发运行多条SQL语句
默认情况下,Jdbc Interpreter能够允许同时运行多条SQL语句(运行多个Hive Job),你可以修改以下配置来调整。

展示Hive Job运行过程log
在最新版本的Zeppelin中可以展示Hive Job的运行过程log,和你在beeline里看到的一样。如下图所示: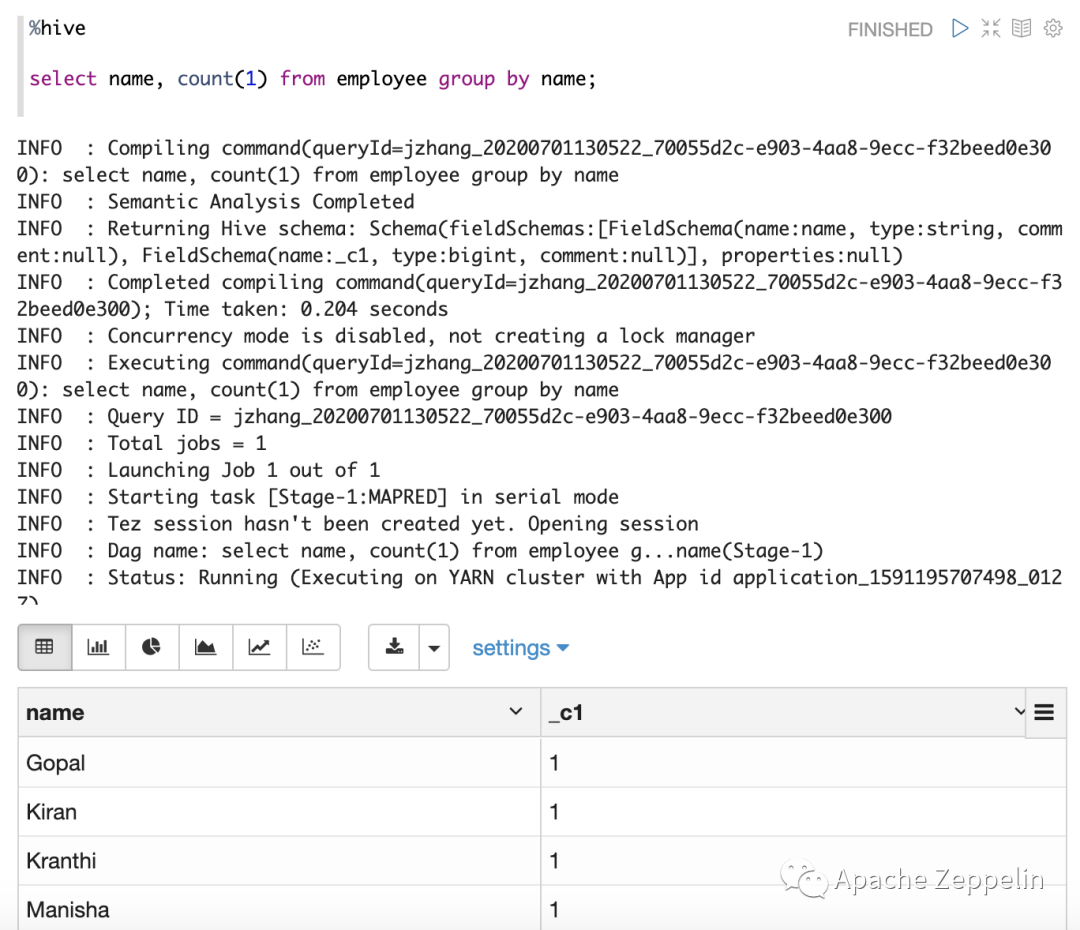
如果你不想看到log,那么有2种方式
- 设置hive interpreter的属性 hive.log.display 为false,这样所有的paragraph都不会展示log
- 设置paragraph的local property:displayLog=false来控制每个paragraph的log输出,如下图:

关联Job URL
如果你是用MR引擎,那么Zeppelin还帮你自动关联到对应MR Job URL。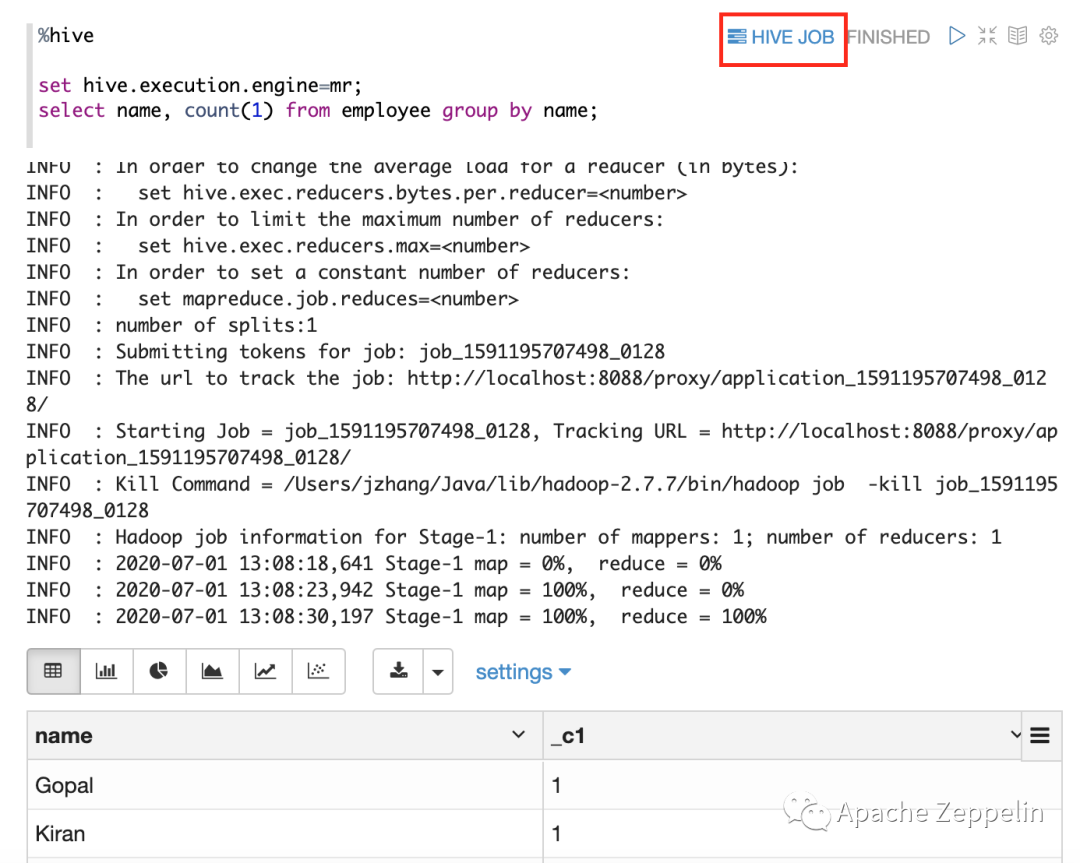
公众号 钉钉群



若有收获,就点个赞吧
0 人点赞
