统计数据存储方式
InnoDB提供了两种存储统计数据的方式:
- 永久性的统计数据
这种统计数据存储在磁盘上,也就是服务器重启之后这些统计数据还在。
- 非永久性的统计数据
这种统计数据存储在内存中,当服务器关闭时这些这些统计数据就都被清除掉了,等到服务器重启之后,在某些适当的场景下才会重新收集这些统计数据。
设计MySQL的大叔们给我们提供了系统变量innodb_stats_persistent来控制到底采用哪种方式去存储统计数据。在MySQL 5.6.6之前,innodb_stats_persistent的值默认是OFF,也就是说InnoDB的统计数据默认是存储到内存的,之后的版本中innodb_stats_persistent的值默认是ON,也就是统计数据默认被存储到磁盘中。
通过指定STATS_PERSISTENT属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_PERSISTENT = (1|0);ALTER TABLE 表名 Engine=InnoDB, STATS_PERSISTENT = (1|0);
- STATS_PERSISTENT=1: 存到磁盘
- STATS_PERSISTENT=0: 存到内存
基于磁盘的永久性统计数据
当我们选择把某个表以及该表索引的统计数据存放到磁盘上时,实际上是把这些统计数据存储到了两个表里:
mysql> SHOW TABLES FROM mysql LIKE 'innodb%';
+---------------------------+
| Tables_in_mysql (innodb%) |
+---------------------------+
| innodb_index_stats |
| innodb_table_stats |
+---------------------------+
2 rows in set (0.01 sec)
- innodb_table_stats存储了关于表的统计数据,每一条记录对应着一个表的统计数据。
- innodb_index_stats存储了关于索引的统计数据,每一条记录对应着一个索引的一个统计项的统计数据。
innodb_table_stats
列:
字段名 描述
database_name 数据库名
table_name 表名
last_update 本条记录最后更新时间
n_rows 表中记录的条数
clustered_index_size 表的聚簇索引占用的页面数量
sum_of_other_index_sizes 表的其他索引占用的页面数量
- 这个表的主键是(database_name,table_name)
mysql> SELECT * FROM mysql.innodb_table_stats;
+---------------+---------------+---------------------+--------+----------------------+--------------------------+
| database_name | table_name | last_update | n_rows | clustered_index_size | sum_of_other_index_sizes |
+---------------+---------------+---------------------+--------+----------------------+--------------------------+
| mysql | gtid_executed | 2018-07-10 23:51:36 | 0 | 1 | 0 |
| sys | sys_config | 2018-07-10 23:51:38 | 5 | 1 | 0 |
| xiaohaizi | single_table | 2018-12-10 17:03:13 | 9693 | 97 | 175 |
+---------------+---------------+---------------------+--------+----------------------+--------------------------+
3 rows in set (0.01 sec)
- n_rows的值是9693,表明single_table表中大约有9693条记录,注意这个数据是估计值。
- clustered_index_size的值是97,表明single_table表的聚簇索引占用97个页面,这个值是也是一个估计值。
- sum_of_other_index_sizes的值是175,表明single_table表的其他索引一共占用175个页面,这个值是也是一个估计值。
n_rows统计项的收集
InnoDB统计一个表中有多少行记录的套路:
- 按照一定算法(并不是纯粹随机的)选取几个叶子节点页面,计算每个页面中主键值记录数量,然后计算平均一个页面中主键值的记录数量乘以全部叶子节点的数量就算是该表的n_rows值。
- innodb_stats_persistent_sample_pages 系统变量: 使用永久性的统计数据时,计算统计数据时采样的页面数量, 默认20
可以单独设置某个表的采样页面的数量,设置方式就是在创建或修改表的时候通过指定STATS_SAMPLE_PAGES属性来指明该表的统计数据存储方式:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
ALTER TABLE 表名 Engine=InnoDB, STATS_SAMPLE_PAGES = 具体的采样页面数量;
clustered_index_size和sum_of_other_index_sizes统计项的收集
收集过程如下:
- 从数据字典里找到表的各个索引对应的根页面位置。
系统表SYS_INDEXES里存储了各个索引对应的根页面信息。
- 从根页面的Page Header里找到叶子节点段和非叶子节点段对应的Segment Header。
在每个索引的根页面的Page Header部分都有两个字段:
- PAGE_BTR_SEG_LEAF:表示B+树叶子段的Segment Header信息。
- PAGE_BTR_SEG_TOP:表示B+树非叶子段的Segment Header信息。
- 从叶子节点段和非叶子节点段的Segment Header中找到这两个段对应的INODE Entry结构。

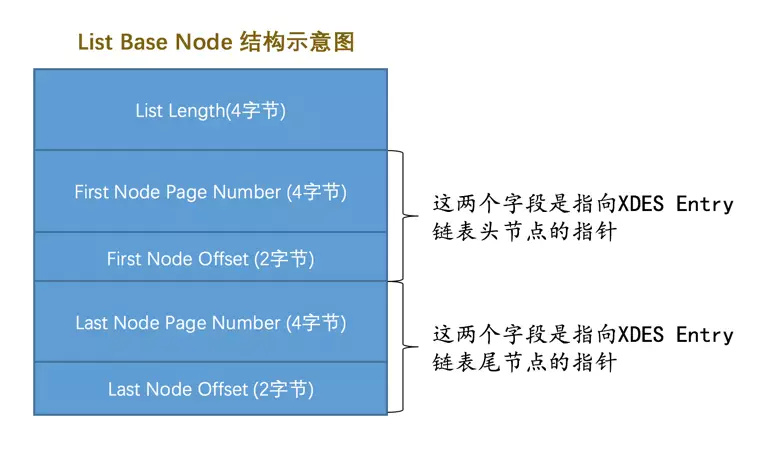
- 从对应的INODE Entry结构中可以找到该段对应所有零散的页面地址以及FREE、NOT_FULL、FULL链表的基节点。
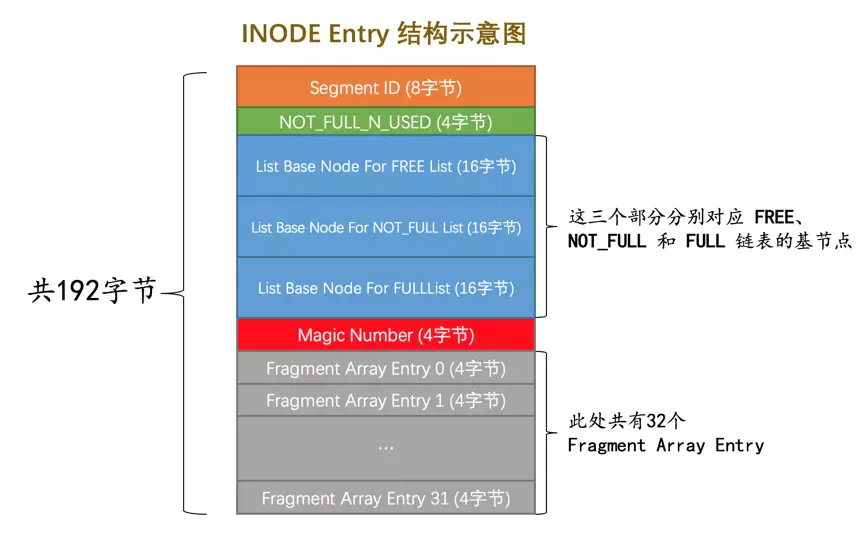
- 直接统计零散的页面有多少个,然后从那三个链表的List Length字段中读出该段占用的区的大小,每个区占用64个页,所以就可以统计出整个段占用的页面。
- 分别计算聚簇索引的叶子结点段和非叶子节点段占用的页面数,它们的和就是clustered_index_size的值,按照同样的套路把其余索引占用的页面数都算出来,加起来之后就是sum_of_other_index_sizes的值。
这里需要大家注意一个问题,我们说一个段的数据在非常多时(超过32个页面),会以区为单位来申请空间,这里头的问题是以区为单位申请空间中有一些页可能并没有使用,但是在统计clustered_index_size和sum_of_other_index_sizes时都把它们算进去了,所以说聚簇索引和其他的索引占用的页面数可能比这两个值要小一些。
innodb_index_stats
字段名 描述database_name 数据库名
table_name 表名
index_name 索引名
last_update 本条记录最后更新时间
stat_name 统计项的名称
stat_value 对应的统计项的值
sample_size 为生成统计数据而采样的页面数量
stat_description 对应的统计项的描述
- 这个表的主键是(database_name,table_name,index_name,stat_name)
我们直接看一下关于single_table表的索引统计数据都有些什么:
mysql> SELECT * FROM mysql.innodb_index_stats WHERE table_name = 'single_table';
+---------------+--------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
| database_name | table_name | index_name | last_update | stat_name | stat_value | sample_size | stat_description |
+---------------+--------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
| xiaohaizi | single_table | PRIMARY | 2018-12-14 14:24:46 | n_diff_pfx01 | 9693 | 20 | id |
| xiaohaizi | single_table | PRIMARY | 2018-12-14 14:24:46 | n_leaf_pages | 91 | NULL | Number of leaf pages in the index |
| xiaohaizi | single_table | PRIMARY | 2018-12-14 14:24:46 | size | 97 | NULL | Number of pages in the index |
| xiaohaizi | single_table | idx_key1 | 2018-12-14 14:24:46 | n_diff_pfx01 | 968 | 28 | key1 |
| xiaohaizi | single_table | idx_key1 | 2018-12-14 14:24:46 | n_diff_pfx02 | 10000 | 28 | key1,id |
| xiaohaizi | single_table | idx_key1 | 2018-12-14 14:24:46 | n_leaf_pages | 28 | NULL | Number of leaf pages in the index |
| xiaohaizi | single_table | idx_key1 | 2018-12-14 14:24:46 | size | 29 | NULL | Number of pages in the index |
| xiaohaizi | single_table | idx_key2 | 2018-12-14 14:24:46 | n_diff_pfx01 | 10000 | 16 | key2 |
| xiaohaizi | single_table | idx_key2 | 2018-12-14 14:24:46 | n_leaf_pages | 16 | NULL | Number of leaf pages in the index |
| xiaohaizi | single_table | idx_key2 | 2018-12-14 14:24:46 | size | 17 | NULL | Number of pages in the index |
| xiaohaizi | single_table | idx_key3 | 2018-12-14 14:24:46 | n_diff_pfx01 | 799 | 31 | key3 |
| xiaohaizi | single_table | idx_key3 | 2018-12-14 14:24:46 | n_diff_pfx02 | 10000 | 31 | key3,id |
| xiaohaizi | single_table | idx_key3 | 2018-12-14 14:24:46 | n_leaf_pages | 31 | NULL | Number of leaf pages in the index |
| xiaohaizi | single_table | idx_key3 | 2018-12-14 14:24:46 | size | 32 | NULL | Number of pages in the index |
| xiaohaizi | single_table | idx_key_part | 2018-12-14 14:24:46 | n_diff_pfx01 | 9673 | 64 | key_part1 |
| xiaohaizi | single_table | idx_key_part | 2018-12-14 14:24:46 | n_diff_pfx02 | 9999 | 64 | key_part1,key_part2 |
| xiaohaizi | single_table | idx_key_part | 2018-12-14 14:24:46 | n_diff_pfx03 | 10000 | 64 | key_part1,key_part2,key_part3 |
| xiaohaizi | single_table | idx_key_part | 2018-12-14 14:24:46 | n_diff_pfx04 | 10000 | 64 | key_part1,key_part2,key_part3,id |
| xiaohaizi | single_table | idx_key_part | 2018-12-14 14:24:46 | n_leaf_pages | 64 | NULL | Number of leaf pages in the index |
| xiaohaizi | single_table | idx_key_part | 2018-12-14 14:24:46 | size | 97 | NULL | Number of pages in the index |
+---------------+--------------+--------------+---------------------+--------------+------------+-------------+-----------------------------------+
20 rows in set (0.03 sec)
- index_name列,这个列说明该记录是哪个索引的统计信息
- stat_name表示针对该索引的统计项名称,stat_value展示的是该索引在该统计项上的值,stat_description指的是来描述该统计项的含义的
都有哪些统计项:
- n_leaf_pages:表示该索引的叶子节点占用多少页面。
- size:表示该索引共占用多少页面。
- n_diff_pfxNN:表示对应的索引列不重复的值有多少
- n_diff_pfx01表示的是统计key_part1这单单一个列不重复的值有多少。
- n_diff_pfx02表示的是统计key_part1、key_part2这两个列组合起来不重复的值有多少。
- n_diff_pfx03表示的是统计key_part1、key_part2、key_part3这三个列组合起来不重复的值有多少。
- n_diff_pfx04表示的是统计key_part1、key_part2、key_part3、id这四个列组合起来不重复的值有多少。
在计算某些索引列中包含多少不重复值时,需要对一些叶子节点页面进行采样,sample_size列就表明了采样的页面数量是多少。
对于有多个列的联合索引来说,采样的页面数量是:innodb_stats_persistent_sample_pages × 索引列的个数。当需要采样的页面数量大于该索引的叶子节点数量的话,就直接采用全表扫描来统计索引列的不重复值数量了。
定期更新统计数据
设计MySQL的大叔提供了如下两种更新统计数据的方式:
- 开启innodb_stats_auto_recalc
系统变量innodb_stats_auto_recalc决定着服务器是否自动重新计算统计数据,它的默认值是ON,也就是该功能默认是开启的。
我们也可以单独为某个表设置是否自动重新计算统计数的属性:
CREATE TABLE 表名 (...) Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
ALTER TABLE 表名 Engine=InnoDB, STATS_AUTO_RECALC = (1|0);
当STATS_AUTO_RECALC=1时,表明我们想让该表自动重新计算统计数据,当STATS_AUTO_RECALC=0时,表明不想让该表自动重新计算统计数据。
- 手动调用ANALYZE TABLE语句来更新统计信息
mysql> ANALYZE TABLE single_table;
+------------------------+---------+----------+----------+
| Table | Op | Msg_type | Msg_text |
+------------------------+---------+----------+----------+
| xiaohaizi.single_table | analyze | status | OK |
+------------------------+---------+----------+----------+
1 row in set (0.08 sec)
手动更新innodb_table_stats和innodb_index_stats表
其实innodb_table_stats和innodb_index_stats表就相当于一个普通的表一样,我们能对它们做增删改查操作。这也就意味着我们可以手动更新某个表或者索引的统计数据。
- 步骤一:更新innodb_table_stats表。
UPDATE innodb_table_stats
SET n_rows = 1
WHERE table_name = 'single_table';
- 步骤二:让MySQL查询优化器重新加载我们更改过的数据。
FLUSH TABLE single_table;
基于内存的非永久性统计数据
与永久性的统计数据不同,非永久性的统计数据采样的页面数量是由innodb_stats_transient_sample_pages控制的,这个系统变量的默认值是8。
innodb_stats_method的使用
索引列不重复的值的数量 的应用场景主要有两个:
- 单表查询中单点区间太多
SELECT * FROM tbl_name WHERE key IN ('xx1', 'xx2', ..., 'xxn');
当IN里的参数数量过多时,采用index dive的方式直接访问B+树索引去统计每个单点区间对应的记录的数量就太耗费性能了,所以直接依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。
- 连接查询时,如果有涉及两个表的等值匹配连接条件,该连接条件对应的被驱动表中的列又拥有索引时,则可以使用ref访问方法来对被驱动表进行查询
SELECT * FROM t1 JOIN t2 ON t1.column = t2.key WHERE ...;
在真正执行对t2表的查询前,t1.comumn的值是不确定的,所以我们也不能通过index dive的方式直接访问B+树索引去统计每个单点区间对应的记录的数量,所以也只能依赖统计数据中的平均一个值重复多少行来计算单点区间对应的记录数量。
设计MySQL的大叔蛮贴心的,他们提供了一个名为innodb_stats_method的系统变量,相当于在计算某个索引列不重复值的数量时如何对待NULL值这个锅甩给了用户,这个系统变量有三个候选值:
- nulls_equal:认为所有NULL值都是相等的。这个值也是innodb_stats_method的默认值。
如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别多,所以倾向于不使用索引进行访问。
- nulls_unequal:认为所有NULL值都是不相等的
如果某个索引列中NULL值特别多的话,这种统计方式会让优化器认为某个列中平均一个值重复次数特别少,所以倾向于使用索引进行访问
- nulls_ignored:直接把NULL值忽略掉

若有收获,就点个赞吧
0 人点赞
