逻辑设计:
- 文档 -> 表中的一行
- 类型 -> 数据表
- 索引 -> 数据库
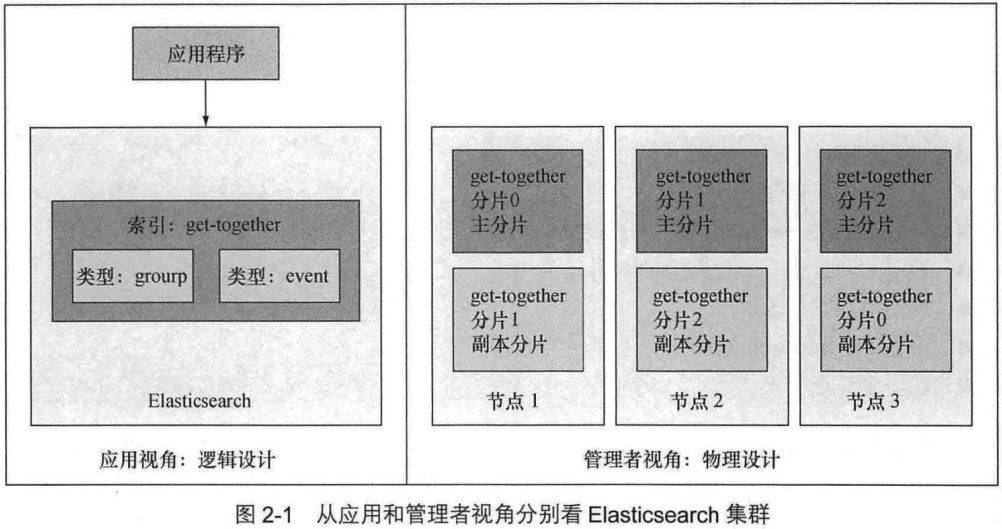
2.1 理解逻辑设计: 文档, 类型和索引
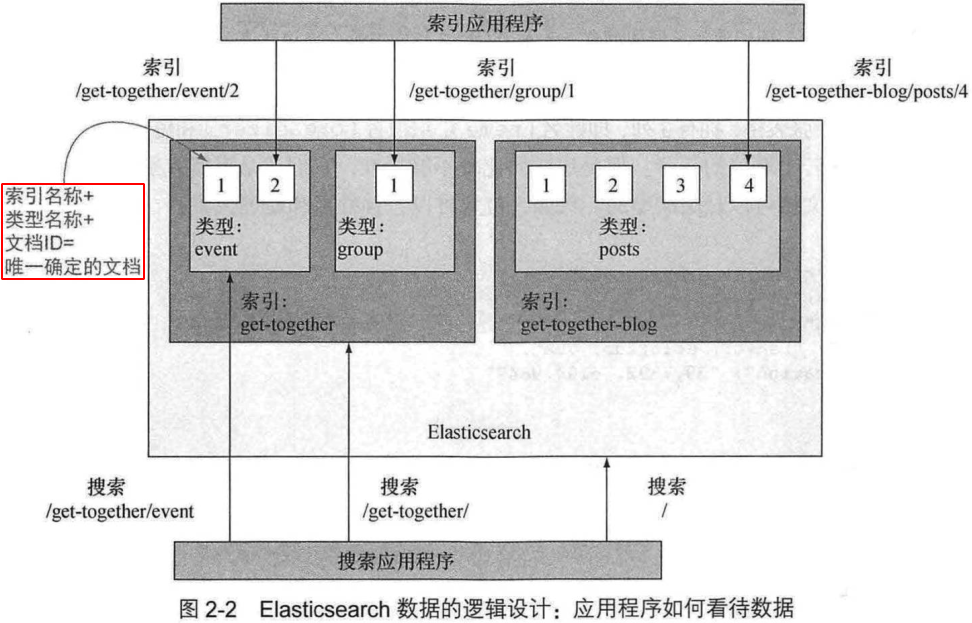
2.1.1 文档

一组字段和其值的类型的映射关系组成了 “类型”.
2.1.2 类型

2.1.3 索引
2.2 理解物理设计: 节点和分片
一个有3个节点的集群, 数据库被划分为5个分片, 每个分片有一个副本:
- 分片是一个目录中的文件
- 分片是数据迁移的最小单位
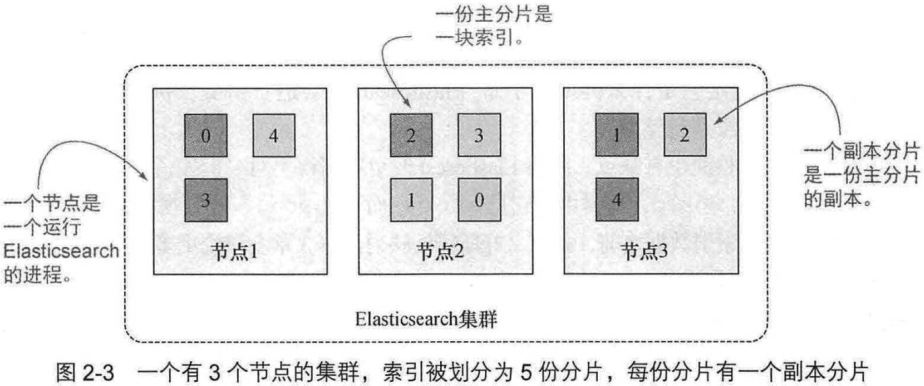
2.2.1 创建拥有一个或多个节点的集群
1. 当索引一篇文档时发生了什么
这里的 “索引文档” 应该是指插入文档.
- 先把文档发到主分片
- 再同步文档到副本分片
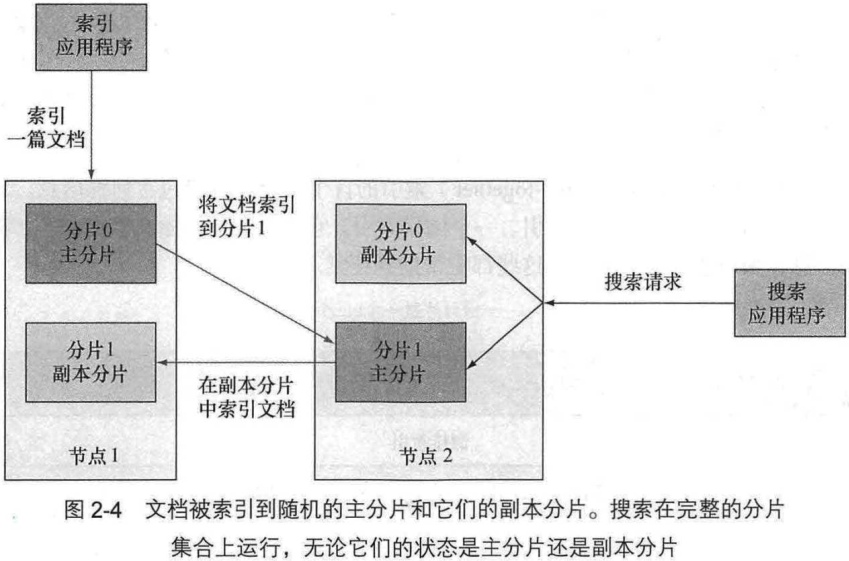
2. 搜索索引时发生了什么
搜索是可以搜索主分片和副本分片.
2.2.2 理解主分片和副本分片
一个分片是 Lucene 的索引: 一个包含倒排索引的文件目录.

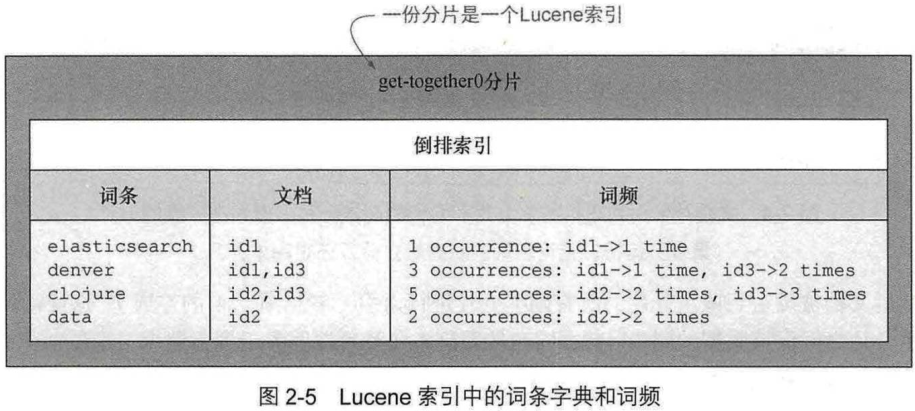
Elasticsearch 索引由一个或多个主分片以及零个或多个副本分片构成:

副本分片的数量可以随时更改, 但是主分片不能, 在创建时就需要确定主分片的数量, 5个是推荐的.
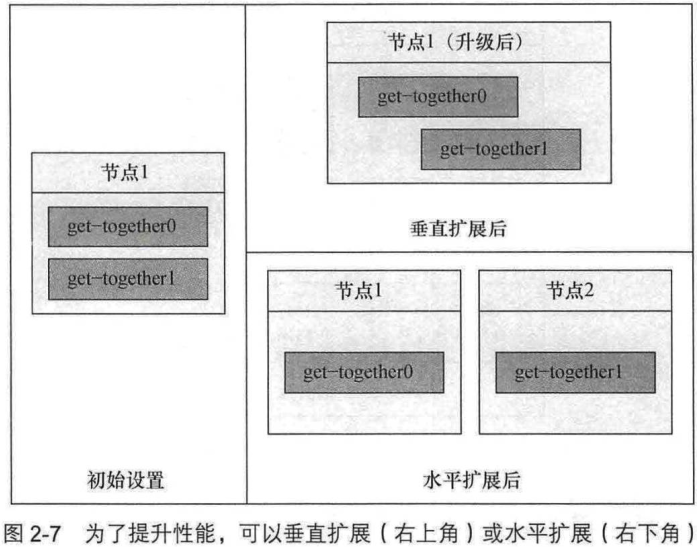
2.2.3 在集群中分发分片
加节点称为水平扩展.
2.2.4 分布式索引和搜索
每份分片 (应该指主分片) 拥有相同的散列范围, 接收新文档的机会均等.
- 然后复制文档到副本分片, 复制成功后响应索引结果
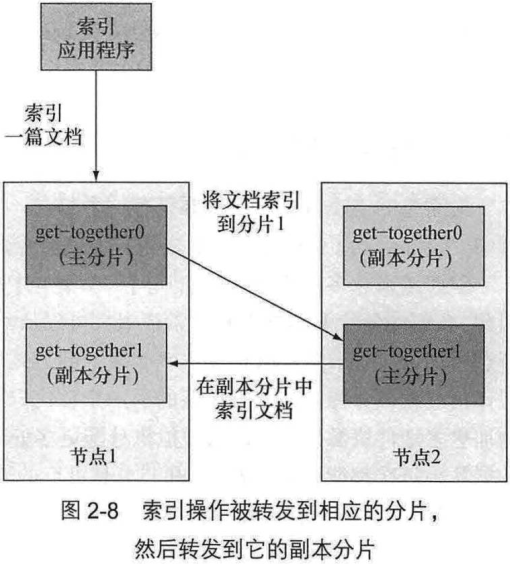
在搜索的时候, 接受请求的节点将请求转发到一组包含所有数据的分片:
- round-robin
- Elasticsearch 从这些分片收集结果并聚集到单一回复

2.3 索引新数据
使用 cURL:

2.3.1 通过 cURL 索引一篇文档
$ curl -XPUT 'localhost:9200/get-together/group/1?pretty' -H 'Content-Type:application/json' -d '{"name": "Elasticsearch Denver","organizer": "Lee"}'{"_index" : "get-together","_type" : "group","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1}
2.3.2 创建索引和映射类型
1. 手动创建索引
$ curl -XPUT 'localhost:9200/new-index'{"acknowledged":true,"shards_acknowledged":true,"index":"new-index"}
2. 获取映射
获取表结构:
$ curl 'localhost:9200/get-together/_mapping/group?pretty&include_type_name=true'{"get-together" : {"mappings" : {"group" : {"properties" : {"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"organizer" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}}}}}}}
2.3.3 通过代码样例索引文档
2.4 搜索并获取数据

若有收获,就点个赞吧
0 人点赞
