编译和解释并存
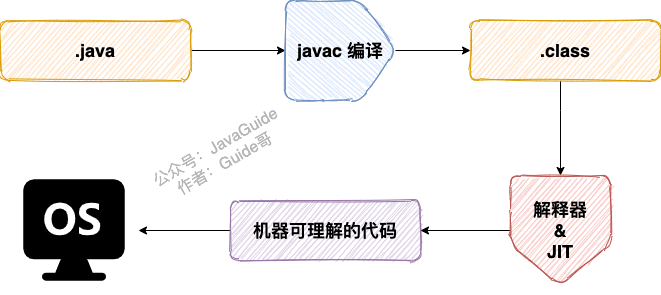
JIT:对于热点代码(执行次数多),当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用
编译型:执行效率高
解释型:执行效率低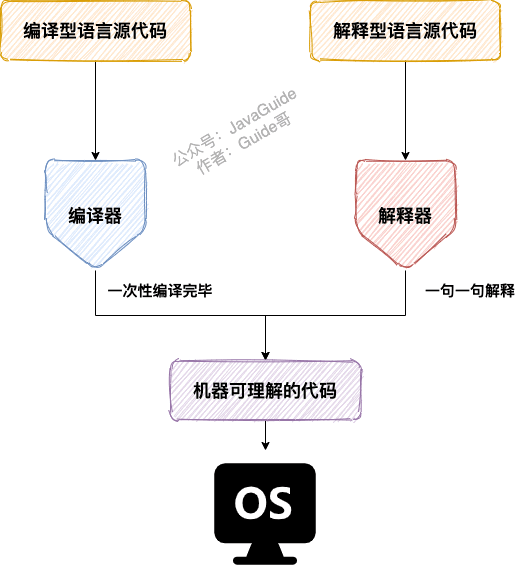
基本类型、包装类型
- 基本数据类型的局部变量存放在 Java 虚拟机栈中的局部变量表中,基本数据类型的成员变量(未被 static 修饰 )存放在 Java 虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
- 为什么说是几乎所有对象实例呢? 这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
- 基本数据类型存放在栈中是一个常见的误区! 基本数据类型的成员变量如果没有被 static 修饰的话(不建议这么使用,应该要使用基本数据类型对应的包装类型),就存放在堆中。
Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是缓存中的对象。Integer i1 = 40;Integer i2 = new Integer(40);System.out.println(i1==i2);
而Integer i2 = new Integer(40) 会直接创建新的对象。
因此,答案是 false 。你答对了吗?
自动拆箱可能会发生NPE
Integer a = null;
int i = a;
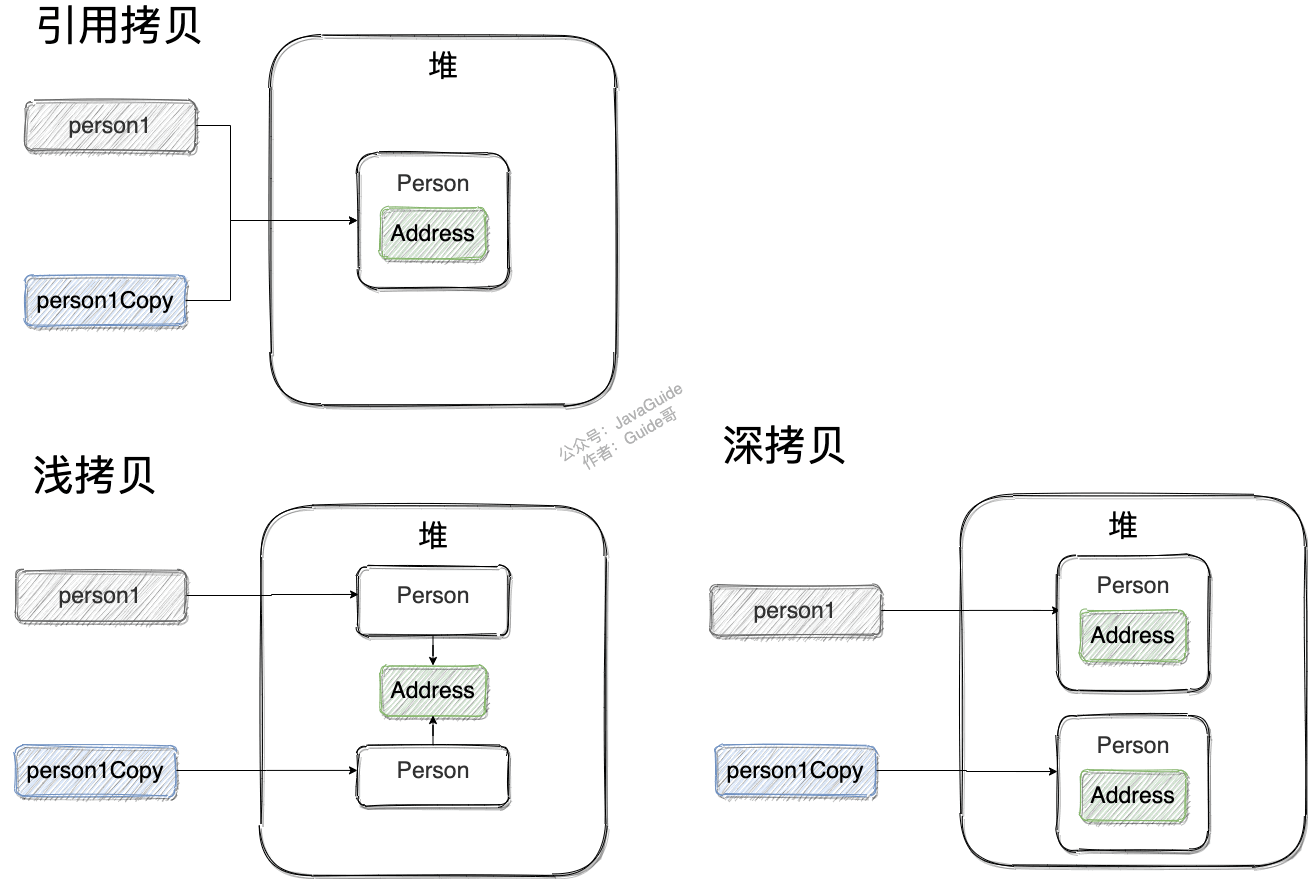
浅拷贝、深拷贝、引用拷贝
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝 :深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
- 那什么是引用拷贝呢? 简单来说,引用拷贝就是两个不同的引用指向同一个对象。
Object类
/*** native方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 ,timeout 是等待时间。*/public final native void wait(long timeout) throws InterruptedException/*** 多了 nanos 参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 毫秒。。*/public final void wait(long timeout, int nanos) throws InterruptedException/*** 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念*/public final void wait() throws InterruptedException
Hashcode、equals
- 如果两个对象的hashCode 值相等,那这两个对象不一定相等(哈希碰撞)。
- 如果两个对象的hashCode 值相等并且equals()方法也返回 true,我们才认为这两个对象相等。
如果两个对象的hashCode 值不相等,我们就可以直接认为这两个对象不相等。
为什么重写 equals() 时必须重写 hashCode() 方法?因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
思考 :重写 equals() 时没有重写 hashCode() 方法的话,使用 HashMap 可能会出现什么问题。
插入equals的对象
总结 :equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
- 两个对象有相同的 hashCode 值,他们也不一定是相等的(哈希碰撞)。
String 真正不可变有下面几点原因:
- 保存字符串的数组被 final 修饰且为私有的,并且String 类没有提供/暴露修改这个字符串的方法。
- String 类被 final 修饰导致其不能被继承,进而避免了子类破坏 String 不可变。
String拼接
字符串对象通过“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。
不过,在循环内使用“+”进行字符串的拼接的话,存在比较明显的缺陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。
intern 方法有什么作用?
String.intern() 是一个 native(本地)方法,其作用是将指定的字符串对象的引用保存在字符串常量池中,可以简单分为两种情况:
- 如果字符串常量池中保存了对应的字符串对象的引用,就直接返回该引用。
- 如果字符串常量池中没有保存了对应的字符串对象的引用,那就在常量池中创建一个指向该字符串对象的引用并返回。
字符串编译与常量折叠
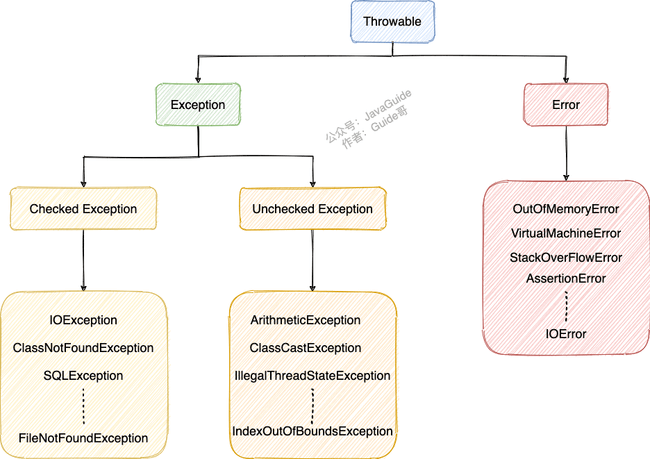
异常
try-catch-finally
注意:不要在 finally 语句块中使用 return! 当 try 语句和 finally 语句中都有 return 语句时,try 语句块中的 return 语句会被忽略。这是因为 try 语句中的 return 返回值会先被暂存在一个本地变量中,当执行到 finally 语句中的 return 之后,这个本地变量的值就变为了 finally 语句中的 return 返回值。
finally 中的代码一定会执行吗?
不一定的!在某些情况下,finally 中的代码不会被执行。
就比如说 finally 之前虚拟机被终止运行的话,finally 中的代码就不会被执行。
异常使用有哪些需要注意的地方?
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
- 抛出的异常信息一定要有意义。
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出NumberFormatException而不是其父类IllegalArgumentException。
- 使用日志打印异常之后就不要再抛出异常了(两者不要同时存在一段代码逻辑中)。
泛型
反射
应用场景
- 动态代理
- 注解
优点:灵活,便于框架开发
缺点:破坏泛型安全检查,性能影响不大
注解
- 编译期直接扫描 :编译器在编译 Java 代码的时候扫描对应的注解并处理,比如某个方法使用@Override 注解,编译器在编译的时候就会检测当前的方法是否重写了父类对应的方法。
运行期通过反射处理 :像框架中自带的注解(比如 Spring 框架的 @Value 、@Component)都是通过反射来进行处理的。
序列化和反序列化
参考文章:序列化和反序列化相关概念
序列化: 将数据结构或对象转换成二进制字节流的过程
- 反序列化:将在序列化过程中所生成的二进制字节流转换成数据结构或者对象的过程
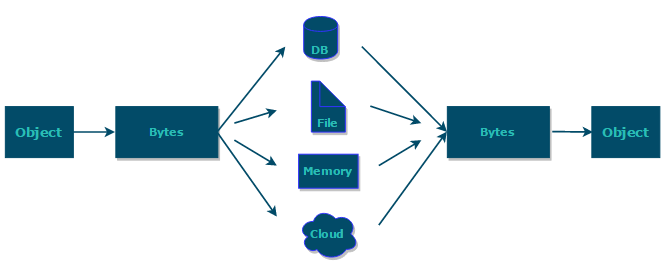
Java 序列化中如果有些字段不想进行序列化,怎么办?
对于不想进行序列化的变量,使用 transient 关键字修饰。
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
- transient 只能修饰变量,不能修饰类和方法。
- transient 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 int 类型,那么反序列后结果就是 0。
static 变量因为不属于任何对象(Object),所以无论有没有 transient 关键字修饰,均不会被序列化。
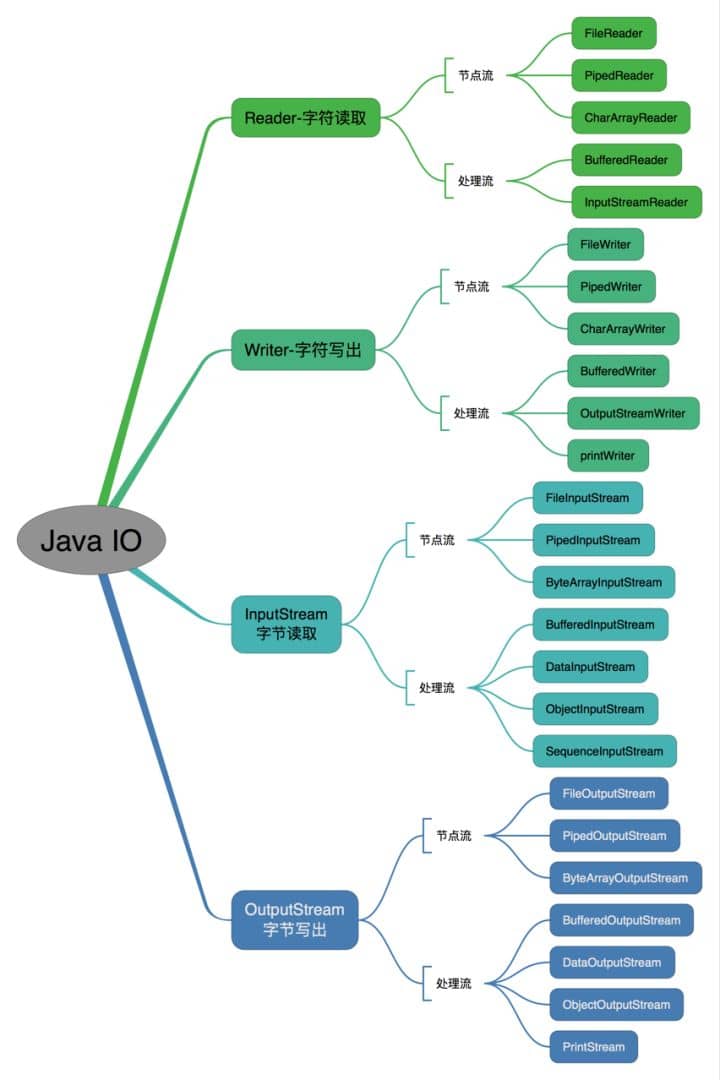
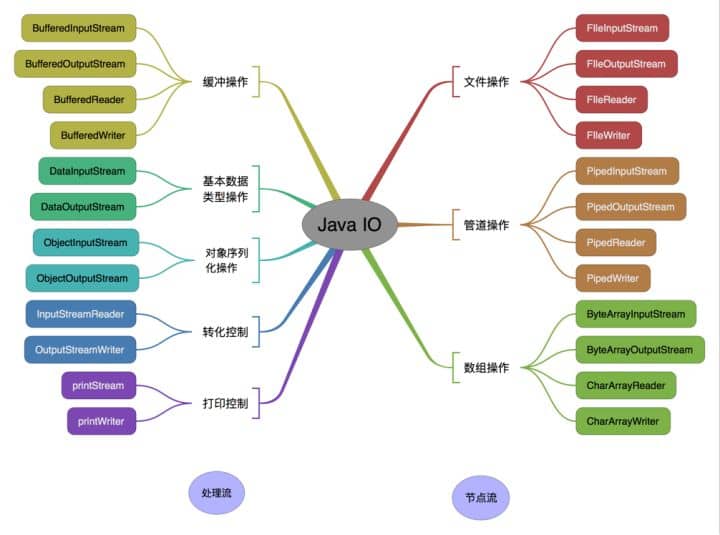
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
值传递
Java 中将实参传递给方法(或函数)的方式是 值传递 :
CGLIBopen in new window(Code Generation Library)是一个基于ASMopen in new window的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了CGLIBopen in new window, 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
- JDK 动态代理只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
- 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
io
何为-i-o
磁盘 IO(读写文件) 和 网络 IO(网络请求和响应)。
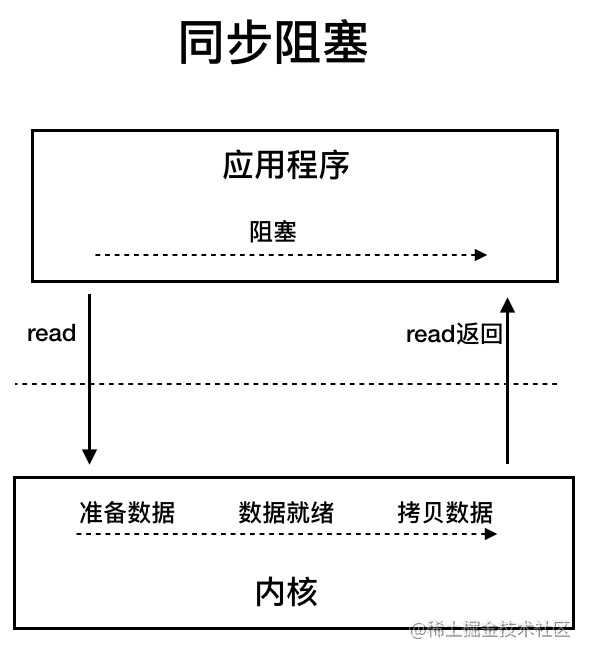
从应用程序的视角来看的话,我们的应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
当应用程序发起 I/O 调用后,会经历两个步骤:
- 内核等待 I/O 设备准备好数据
- 内核将数据从内核空间拷贝到用户空间。
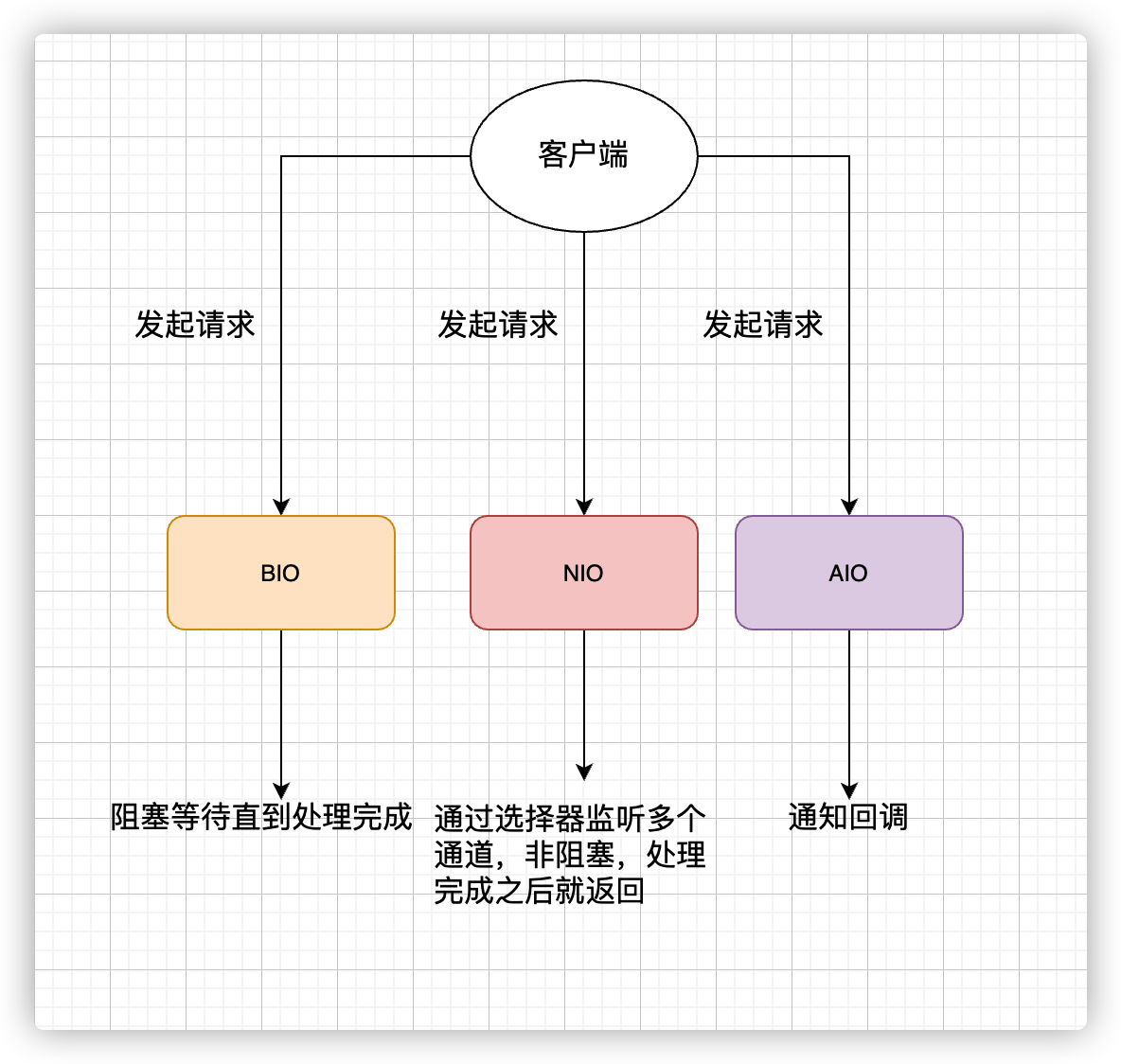
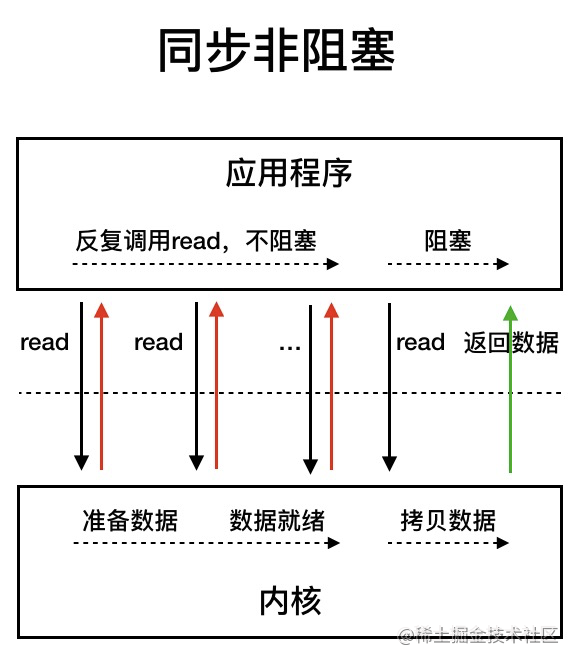
同步非阻塞 IO 模型中,应用程序会一直发起 read 调用,等待数据从内核空间拷贝到用户空间的这段时间里,线程依然是阻塞的,直到在内核把数据拷贝到用户空间。
相比于同步阻塞 IO 模型,同步非阻塞 IO 模型确实有了很大改进。通过轮询操作,避免了一直阻塞。
但是,这种 IO 模型同样存在问题:应用程序不断进行 I/O 系统调用轮询数据是否已经准备好的过程是十分消耗 CPU 资源的。
这个时候,I/O 多路复用模型 就上场了。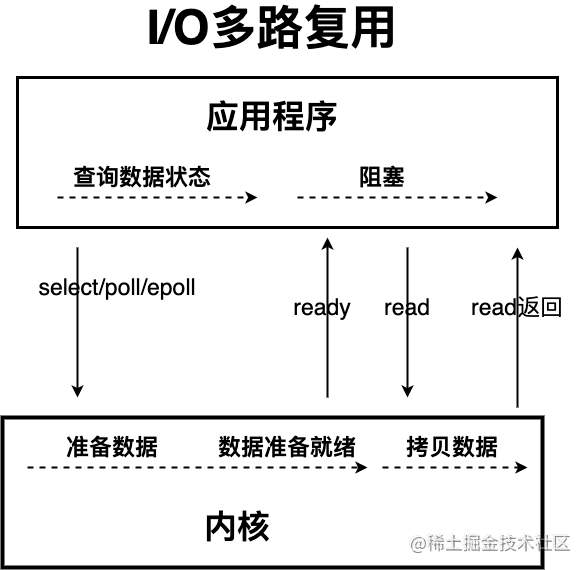
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间 -> 用户空间)还是阻塞的。
IO 多路复用模型,通过减少无效的系统调用,减少了对 CPU 资源的消耗。
Java 中的 NIO ,有一个非常重要的选择器 ( Selector ) 的概念,也可以被称为 多路复用器。通过它,只需要一个线程便可以管理多个客户端连接。当客户端数据到了之后,才会为其服务。
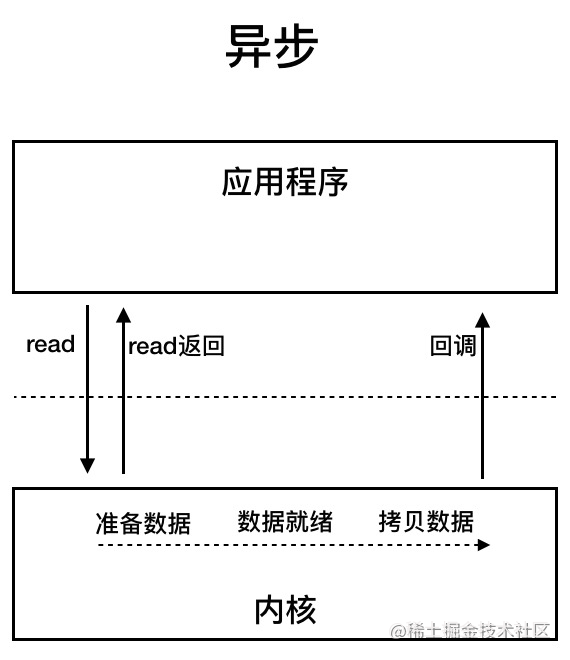
AIO 也就是 NIO 2。Java 7 中引入了 NIO 的改进版 NIO 2,它是异步 IO 模型。
异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
BigDecimal 详解
《阿里巴巴 Java 开发手册》中提到:浮点数之间的等值判断,基本数据类型不能用==来比较,包装数据类型不能用 equals 来判断。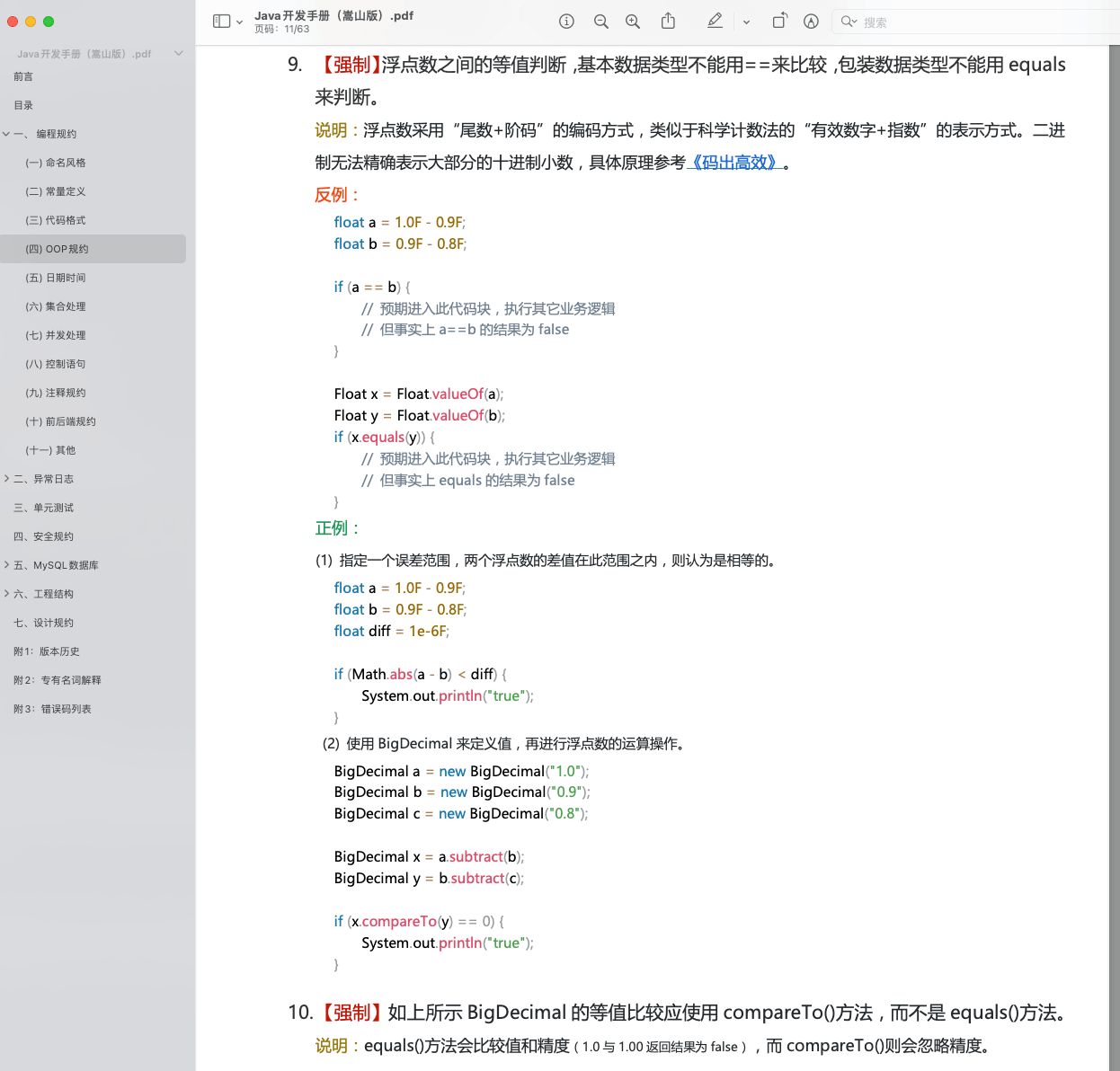
注意:我们在使用 BigDecimal 时,为了防止精度丢失,推荐使用它的BigDecimal(String val)构造方法或者 BigDecimal.valueOf(double val) 静态方法来创建对象。
import java.math.BigDecimal;import java.math.RoundingMode;/*** 简化BigDecimal计算的小工具类*/public class BigDecimalUtil {/*** 默认除法运算精度*/private static final int DEF_DIV_SCALE = 10;private BigDecimalUtil() {}/*** 提供精确的加法运算。** @param v1 被加数* @param v2 加数* @return 两个参数的和*/public static double add(double v1, double v2) {BigDecimal b1 = BigDecimal.valueOf(v1);BigDecimal b2 = BigDecimal.valueOf(v2);return b1.add(b2).doubleValue();}/*** 提供精确的减法运算。** @param v1 被减数* @param v2 减数* @return 两个参数的差*/public static double subtract(double v1, double v2) {BigDecimal b1 = BigDecimal.valueOf(v1);BigDecimal b2 = BigDecimal.valueOf(v2);return b1.subtract(b2).doubleValue();}/*** 提供精确的乘法运算。** @param v1 被乘数* @param v2 乘数* @return 两个参数的积*/public static double multiply(double v1, double v2) {BigDecimal b1 = BigDecimal.valueOf(v1);BigDecimal b2 = BigDecimal.valueOf(v2);return b1.multiply(b2).doubleValue();}/*** 提供(相对)精确的除法运算,当发生除不尽的情况时,精确到* 小数点以后10位,以后的数字四舍五入。** @param v1 被除数* @param v2 除数* @return 两个参数的商*/public static double divide(double v1, double v2) {return divide(v1, v2, DEF_DIV_SCALE);}/*** 提供(相对)精确的除法运算。当发生除不尽的情况时,由scale参数指* 定精度,以后的数字四舍五入。** @param v1 被除数* @param v2 除数* @param scale 表示表示需要精确到小数点以后几位。* @return 两个参数的商*/public static double divide(double v1, double v2, int scale) {if (scale < 0) {throw new IllegalArgumentException("The scale must be a positive integer or zero");}BigDecimal b1 = BigDecimal.valueOf(v1);BigDecimal b2 = BigDecimal.valueOf(v2);return b1.divide(b2, scale, RoundingMode.HALF_UP).doubleValue();}/*** 提供精确的小数位四舍五入处理。** @param v 需要四舍五入的数字* @param scale 小数点后保留几位* @return 四舍五入后的结果*/public static double round(double v, int scale) {if (scale < 0) {throw new IllegalArgumentException("The scale must be a positive integer or zero");}BigDecimal b = BigDecimal.valueOf(v);BigDecimal one = new BigDecimal("1");return b.divide(one, scale, RoundingMode.HALF_UP).doubleValue();}/*** 提供精确的类型转换(Float)** @param v 需要被转换的数字* @return 返回转换结果*/public static float convertToFloat(double v) {BigDecimal b = new BigDecimal(v);return b.floatValue();}/*** 提供精确的类型转换(Int)不进行四舍五入** @param v 需要被转换的数字* @return 返回转换结果*/public static int convertsToInt(double v) {BigDecimal b = new BigDecimal(v);return b.intValue();}/*** 提供精确的类型转换(Long)** @param v 需要被转换的数字* @return 返回转换结果*/public static long convertsToLong(double v) {BigDecimal b = new BigDecimal(v);return b.longValue();}/*** 返回两个数中大的一个值** @param v1 需要被对比的第一个数* @param v2 需要被对比的第二个数* @return 返回两个数中大的一个值*/public static double returnMax(double v1, double v2) {BigDecimal b1 = new BigDecimal(v1);BigDecimal b2 = new BigDecimal(v2);return b1.max(b2).doubleValue();}/*** 返回两个数中小的一个值** @param v1 需要被对比的第一个数* @param v2 需要被对比的第二个数* @return 返回两个数中小的一个值*/public static double returnMin(double v1, double v2) {BigDecimal b1 = new BigDecimal(v1);BigDecimal b2 = new BigDecimal(v2);return b1.min(b2).doubleValue();}/*** 精确对比两个数字** @param v1 需要被对比的第一个数* @param v2 需要被对比的第二个数* @return 如果两个数一样则返回0,如果第一个数比第二个数大则返回1,反之返回-1*/public static int compareTo(double v1, double v2) {BigDecimal b1 = BigDecimal.valueOf(v1);BigDecimal b2 = BigDecimal.valueOf(v2);return b1.compareTo(b2);}}

若有收获,就点个赞吧
0 人点赞
