由于cpu,内存和硬盘的速度不一致,为了平衡三者的速度差异,计算机体系结构引入了缓存来缓和矛盾,操作系统引入了进程线程以分时复用cpu,编译程序引入了编译优化来提高编译速度。但是在引入这些内容的时候如果不了解这些便利的底层逻辑,就很容易导致很多诡异的问题:
缓存导致的可见性问题
- 因为缓存是在cpu的一个核上的,所以对于多核cpu,不同的线程在不同cpu上对同一个共享变量进行操作就有可能导致得到的结果不一样。以下程序得到的结果就是10000-20000之间的一个随机数。
public class Test {private static long count = 0;private void add10K() {int idx = 0;while(idx++ < 10000) {count += 1;}}public static long calc() {final Test test = new Test();// 创建两个线程,执行add()操作Thread th1 = new Thread(()->{test.add10K();});Thread th2 = new Thread(()->{test.add10K();});// 启动两个线程th1.start();th2.start();// 等待两个线程执行结束th1.join();th2.join();return count;}}
- 因为缓存是在cpu的一个核上的,所以对于多核cpu,不同的线程在不同cpu上对同一个共享变量进行操作就有可能导致得到的结果不一样。以下程序得到的结果就是10000-20000之间的一个随机数。
线程切换带来的原子性问题
- 我们现在使用的一条高级语言,往往需要多条cpu指令完成,如 count+=1;
- 指令 1:首先,需要把变量 count 从内存加载到 CPU 的寄存器;
- 指令 2:之后,在寄存器中执行 +1 操作;
- 指令 3:最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)。
- 操作系统做任务切换,可以发生在任何一条cpu指令执行完,如下的顺序就会导致结果是1,而不是我们期望的2。
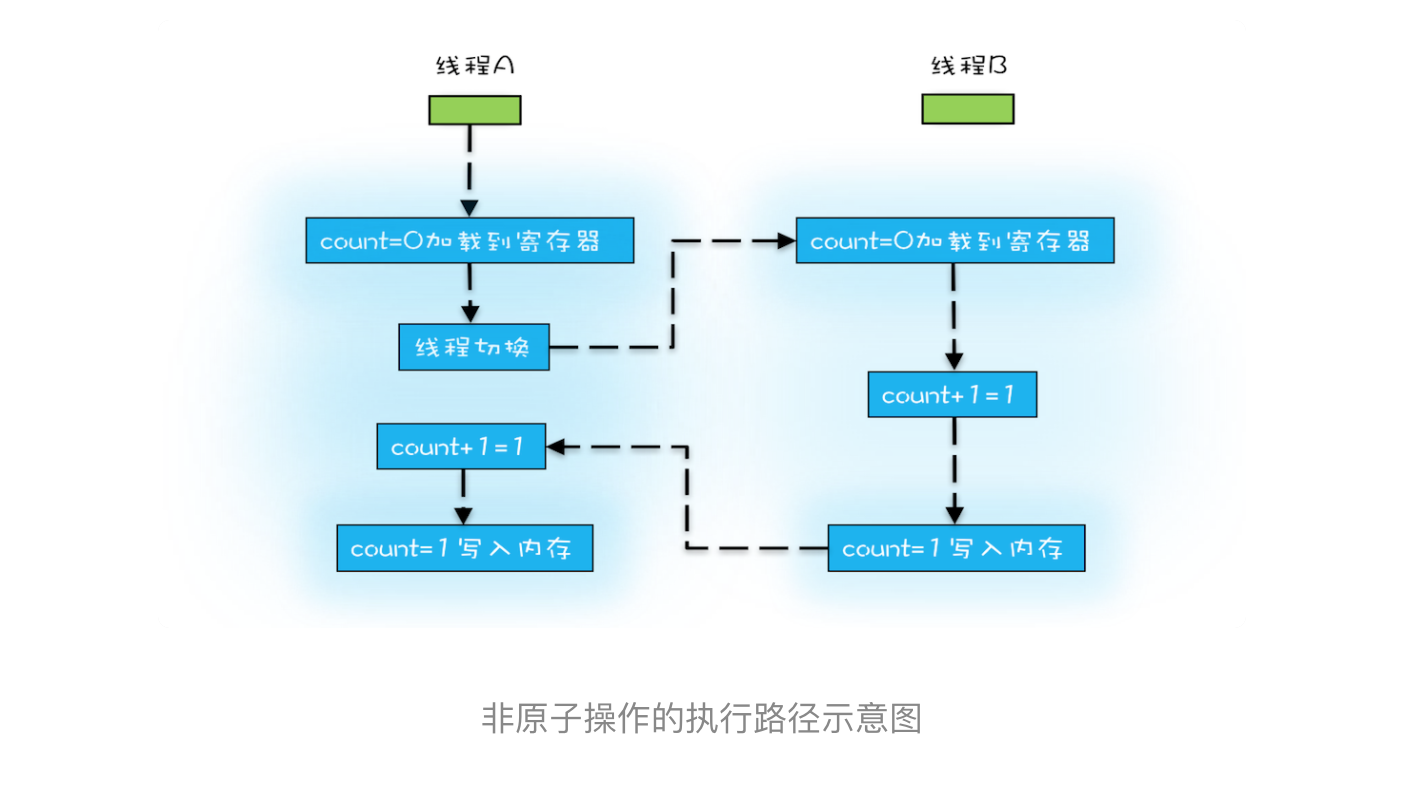
- 我们把一个或者多个操作在cpu执行的过程中不被中断的特性成为原子性。所以我们需要在高级语言层面保证操作的原子性
- 我们现在使用的一条高级语言,往往需要多条cpu指令完成,如 count+=1;
- 编译优化带来的有序性问题
- 编译器为了优化性能,有时候会改变程序中语句的先后顺序。
- 对于单例模式,本来的执行顺序为:
- 分配一块内存 M;
- 在内存 M 上初始化 Singleton 对象;
- 然后 M 的地址赋值给 instance 变量。
- 实际的优化后的执行顺序
- 分配一块内存 M;
- 将 M 的地址赋值给 instance 变量;
- 最后在内存 M 上初始化 Singleton 对象。
- 如果线程1在第二步失去cpu,线程2此时获得cpu,线程2执行到第一个判断null的地方,就会返回一个null的单例,可能会有bug
public class Singleton {static Singleton instance;static Singleton getInstance(){if (instance == null) {synchronized(Singleton.class) {if (instance == null)instance = new Singleton();}}return instance;}}
- 只要我们能够深刻理解可见性、原子性、有序性在并发场景下的原理,很多并发 Bug 都是可以理解、可以诊断的。
- 我们已经了解到导致可见性和有序性问题的原因是缓存和编译优化,所以直接禁用掉缓存和编译优化是最直接的方法。但是这样的话程序性能就不能够保证最优了,所以合理的解决办法就是合理禁用。按照我们自己的需求去禁用缓存和编译优化,java内存模型为我们提供了volatile,synchronized,final三个关键字和六项happens-before原则。
- 声明一个变量为volatile,即告诉编译器,对这个变量的读写要从内存中读取或写入,不能使用cpu缓存
- happens-before原则并不是谁发生在谁之前,而是说前面一个操作的结果对后续操作是可见的
- happens-before原则
- 在一个线程中,按照程序顺序,前面的操作happens-before后续的任意操作
- 对一个volatile变量的写操作,happens-before后续对这个volatile变量的读操作
- 传递性,如果a happens-before b,b happens-before c,则a happens-before c
- 对一个锁的解锁happens-before后续对这个锁的加锁
- 主线程 A 启动子线程 B 后,子线程 B 能够看到主线程在启动子线程 B 前的操作
- 主线程 A 等待子线程 B 完成(主线程 A 通过调用子线程 B 的 join() 方法实现),当子线程 B 完成后(主线程 A 中 join() 方法返回),主线程能够看到子线程的操作。当然所谓的“看到”,指的是对共享变量的操作
- final 修饰变量时,初衷是告诉编译器:这个变量生而不变,可以可劲儿优化

若有收获,就点个赞吧
0 人点赞
