
[toc]
JanusGraph
什么是图数据库
有别于关系型数据库,是NoSQL数据库的一种,应用图形理论存储实体之间的关系信息。
什么是Janusgraph,JanusGraph能干什么
【Janusgraph官网 https://docs.janusgraph.org/getting-started/architecture/】
JanusGraph是一个图形数据库引擎。JanusGraph本身专注于紧凑的图形序列化,丰富的图形数据建模和有效的查询执行。此外,JanusGraph利用Hadoop进行图分析和批处理图处理。
JanusGraph旨在支持当需要的存储和计算能力超出了单台计算机所能提供的范围的图处理。 包括对图数据进行实时遍历和分析查询,这是JanusGraph的基本优势。
Janusgraph和磁盘之间需要一个或多个存储和索引适配器,来对磁盘进行操作。
存储可用适配器:
- Cassandra
- HBase
- Berkeley
索引:
- ES
- Solr
- Luncene
优势
- 可以存储大图,比如包含数千亿顶点和边的图
- 分布式部署,支持集群
- 集群节点支持线性扩展
- 支持很多并发事务和操作图处理,处理能力随集群机器数量变化,毫秒级应答大型图上的复杂遍历查询
- 通过hadoop支持全局图分析和批处理
- 数据分布式存储,每份数据有多个副本
- 支持多个数据中心做高可用,支持热备份
- 支持后端存储系统,标准支持四种【Cassandra,HBase,Cloud Bigtable,BrekeleyDB】,也可增加第三方的存储系统
- 支持geo
- 集成ES,Solr,Lucene等后可以支持全文搜索
- 可视化存储
架构信息
Vertex【顶点】
代表每个实体,可以存在不同的property。
Edge【边/关系】
用于描述顶点之间的关系,可以存在不同的property。
不存在无向边,双向边使用两个方向相反的边表示。
- 边的类型
【MULTI】 允许在任意一对顶点之间使用同一标签的多个边。
【SINGLE】任意一对顶点之间最多存在一条这样的边.
【MANY2ONE】 多对一,对于某一顶点,只能有一条该标签的输出边,可以有多条输入边。如标签mother,因为每个人最多有一个母亲,但母亲可以有多个孩子。所以对于顶点A,输出的mother边只能有一条,但是输入边可以有多条。
【ONE2MANY】 一对多,对于某一顶点,可以有多条输出边,但是只能有一条该标签的输入边。如winnerOf,因为每个竞赛最多由一个人赢得,但一个人可以赢得多个竞赛。
【ONE2ONE】一对一,对于任何顶点上最多只有一条该标签的输入与输出边。如婚姻关系。与SINGLE的不同是ONE2ONE关系是相互的。
property【属性】
用于描述顶点和边的属性,但是属性键名必须是唯一的不能重复。
无论是边还是顶点都可以有属性键
如: 人是一个顶点,这个顶点可以有姓名属性
朋友关系是一条边,这条边可以有好友关系强度属性
- 属性数据类型
String
Character
Boolean
Byte
Short
Integer
Long
Float
Double
Date
Geoshape
UUID
- 数据属性集合类型
SINGLE 只允许存在一个值。如生日
LIST 可以存在任意数量的值。如多组交易数据
SET 允许多个值,但不能重复。如曾用名
schema【数据模型】
schema由edge labels【边标签】 , property keys【属性键】 和 vertex labels【顶点标签】组成
- 自动创建Schema
如果没有明确定义边标签,属性键或顶点标签,则在添加边,顶点或属性设置期间首次使用时,将隐式定义边标签,属性键或顶点标签。DefaultSchemaMaker配置用于JanusGraph图定义这样的类型。
默认情况下,隐式创建的边标签具有多样性MULTI,隐式创建的属性键具有基数SINGLE和数据类型Object.class。用户可以通过实现和注册他们自己的DefaultSchemaMaker来控制schema元素的自动创建。
强烈建议通过schema.default=none在JanusGraph图形配置中进行设置,明确定义所有schema元素并禁用自动schema创建
JanusGraph怎么用
安装
环境要求:
Java 8 SE
启动服务
./bin/janusgraph.sh start
两种连接和使用janusGraph方式
- 通过导入jar包到客户端程序中,客户端为其提供执行线程。
- JanusGraph提供了一个长时间运行的服务器进程【JanusGraph Server】,客户端可以将查询条件传递给该服务器,由该服务器执行。
API
基础操作
V()、E()、id()、label()、properties()、valueMap()、values()
- V():查询顶点,一般作为图查询的第1步,后面可以续接的语句种类繁多。例:g.V(),g.V(‘v_id’),查询图中所有顶点和特定点;
- E():查询边,一般作为图查询的第1步,后面可以续接的语句种类繁多 例:g.E(),g.E(‘S3:TinkerPop>4>>S4:Gremlin’);
- id():获取顶点、边的id。例:g.V().id(),查询所有顶点的id;
- label():获取顶点、边的 label。例:g.V().label(),可查询所有顶点的label。
- key() / value():获取属性的key/value的值。例:g.V().peoperites().key(), g.V().properties().value()//获取所有定点的key/value值
- properties():获取顶点、边的属性;可以和 key()、value()搭配使用,以获取属性的名称或值。例:g.V().properties(‘name’),查询所有顶点的 name 属性,若无name属性则调过。g.V().properties().key(),查询所有顶点属性名称;
- valueMap():获取顶点、边的属性,以Map的形式体现,和properties()比较像
- values():获取顶点、边的属性值。例,g.V().values() 等于 g.V().properties().value()
遍历操作
out()、in()、both()、outE()、inE()、bothE()、outV()、inV()、bothV()、otherV()
- 以顶点为基础
- out(label):根据指定的 Edge Label 来访问顶点的 OUT 方向邻接点(可以是零个 Edge Label,代表所有类型边;也可以一个或多个 Edge Label,代表任意给定 Edge Label 的边,下同);
- in(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接点;
- both(label):根据指定的 Edge Label 来访问顶点的双向邻接点;
- outE(label): 根据指定的 Edge Label 来访问顶点的 OUT 方向邻接边;
- inE(label):根据指定的 Edge Label 来访问顶点的 IN 方向邻接边;
- bothE(label):根据指定的 Edge Label 来访问顶点的双向邻接边;
- 以边为基础
- outV():访问边的出顶点,出顶点是指边的起始顶点;
- inV():访问边的入顶点,入顶点是指边的目标顶点,也就是箭头指向的顶点;
- bothV():访问边的双向顶点;
- otherV():访问边的伙伴顶点,即相对于基准顶点而言的另一端的顶点;
has过滤条件
- hasLabel(labels…)、hasId(ids…)、has(key, value)、has(label, key, value)、has(key, predicate)、hasKey(keys…)、hasValue(values…)、has(key)、hasNot(key)
- has语句是filter类型语句的代表,能够以顶点和边的属性作为过滤条件,决定哪些对象可以通过。has语句包括很多变种:
- hasLabel(labels…): 通过label来过滤顶点或边,满足label列表中一个即可通过 例 g.V().hasLabel(‘persion’),g.E().hasLabel(‘shopping’)//包含person标签的定点/包含shopping为标签的边
- hasId(ids…): 通过id来过滤顶点或者边,满足id列表中的一个即可通过。例:g.V().hasId(‘xiaowang’)/g.E().hasId(‘created’)
- has(key, value): 通过属性的名字和对应的值来过滤顶点或边 例:g.v().has(‘name’,‘xiaoming’)/g.e().has(‘label’,‘shopping’)//筛选顶点属性包含name并且值为xiaoming的顶点,边同理。
- has(label, key, value): 通过label和属性的名字和值过滤顶点和边 例:g.V().has(‘people’,‘name’,‘xiaoming’)//刷选顶点包含people的标签且name为小明的顶点数据,边同理。
- has(key, predicate): 通过对指定属性用条件过滤顶点和边,作用于顶点或者边 例:g.v().has(‘age’,gt(20))//筛选属性值大于20的age的顶点,边同理。
- hasKey(keys…): properties包含所有的key才能通过,例:g.v().porperties.hasKey(‘name’) //筛选属性值的key包含name的顶点,边同理。直接将hasKey()作用于顶点,仅后端是Cassandra时支持如 g.v().hasKey(‘name’)
- hasValue(values…): properties包含所有的value才能通过,例:
g.v().porperties().hasValue(‘xiaoming’) //属性值的值包含xiaoming字段的顶点,边同理。直接将hasValue()作用于顶点,仅后端是Cassandra时支持 如g.v().hasValue(‘xiaoming’)- has(key): 有这个属性的通过,作用于顶点或者边 例:g.v().has(‘name’) //属性值包含name的顶点,边同理
- hasNot(key): 没有这个属性的通过 ,例 g.v().hasNot(‘name’) 属性值不包含name的顶点,边同理
查询返回结果数限制
count()、range()、limit()、tail()、skip()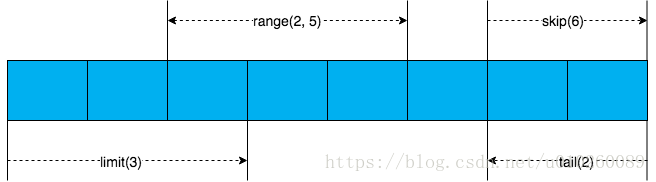
连接配置
/**storage.hostname 存储后端集群zookeeper的hostnamestorage.backen 使用HBase作为后端存储引擎storage.hbase.table 表名index.search.backend 索引引擎index.search.hostname 索引hostname*/JanusGraphFactory.Builder builder = JanusGraphFactory.build().set("storage.hostname", "grandland1, grandland2, grandland3").set("storage.backend", "hbase").set("storage.hbase.table", "janusgraph").set("index.search.backend", "elasticsearch").set("index.search.hostname", "grandland1");//建立连接graph = builder.open();
配置管理
//使用JanusGraphManagement可以对配置,索引,标签等进行管理。JanusGraphManagement mgmt = graph.openManagement()mgmt.get('cache.db-cache')mgmt.set('cache.db-cache', true)mgmt.commit();
增
//添加一个顶点标签v_humanVertexLabel HumanLabel = graph.makeVertexLabel("v_human").make();//定义一个property属性PropertyKey pkName = graph.makePropertyKey("pk_name").dataType(String.class).cardinality(Cardinality.SET).make();//为v_human顶点添加pk_name属性graph.addProperties(HumanLabel,pkName);//添加一个v_human顶点Vertex jimo = graph.addVertex(“v_human”);//为该顶点实例对象增加pk_name属性jimo.property(pkName,jimo);//添加一个edge标签EdgeLabel ewifeLabel = graph.makeEdgeLabel("e_married").multiplicity(Multiplicity.ONE2ONE).make();//定义一个pk_married_year属性PropertyKey pkMarriedYear = graph.makePropertyKey("pk_married_year").dataType(Integer.class).cardinality(Cardinality.SINGLE).make();//为ewifeLabel标签添加一个属性graph.addProperties(ewifeLabel,pkMarriedYear);//在两个顶点之间添加边Vertex jimo = g.V().has(pkName,"JIMO").next();Vertex lily = g.V().has(pkName,"LILY").next();jimo.addEdge("e_married",lily,"pk_married_year",10);
删
//删除pkName为name的所有顶点g.V().has(pkName,name).drop().iterate();//删除pkName为LILY的所有顶点的所有输出边g.V().has(pkName,"LILY").outE().drop().iterate();//删除pkName为name的所有边里存在pk_married_year的边g.V().has(pkName,name).bothE().has("pk_married_year").drop().iterate();
改
//修改pk_name为old的pk_name属性为newNameVertex v = g.V().has("pk_name",old).next();v.property("pk_name",newName);//修改pkNmae为name的顶点的e_married边的pk_married_year属性值为100Edge list = g.V().has(pkName,name).outE("e_married").next();list.property("pk_married_year",100);/**修改将A的e_married关系修改为与B首先删除原有边,再重新建立新的关系*/Vertex jimo = g.V().has(pkName,A).next();Vertex hehe = g.V().has(pkName,B).next();Edge e = g.V().has(pkName,A).outE("e_married").next();g.V().has(pkName,name).outE("e_married").drop().iterate();Edge newE = jimo.addEdge("e_married",hehe,"pk_married_year",10);
查
//获取整个图GraphTraversalSource g = graph.traversal();//获取所有顶点列表g.V().toList();//获取所有关系列表g.E().toList();//分别获取所有顶点和边的属性列表g.V().propertyMap()g.E().propertyMap()//获取pk_name是123的顶点g.V().has(“pk_name”,"123")//获取pk_name是123的包含e_married的输出边g.V().has(pkName,name).outE("e_married")g.V().has(pkName,name).inE("e_married") //输入边g.V().has(pkName,name).bothE("e_married") //所有边//查询hercules顶点的盟友g.V(hercules).as('h').out('battled').in('battled').where(neq('h')).values('name')
排序
可以使用order().by()指令定义返回图形查询结果的顺序。该order().by()方法需要两个参数:用于排序结果的属性键的名称。结果将按此属性键的顶点或边的值排序。排序顺序:升序asc或降序desc复合索引不支持排序。混合索引支持排序,需要索引键中包含要排序的键//查询所有顶点中年龄最大的10个g.V().order().by('age', desc).limit(10)
批量导入
事务管理
JanusGraph具有事务安全性,可以在多个并行的线程中同时使用。
根据TinkerPop框架事务机制的描述,每一个线程在它执行第一个操作的时候开启一个事务
使用graph = builder.open();创建链接
使用g.V()...执行操作
使用g.tx().commit();提交一次修改操作
使用graph.close()关闭连接
使用createThreadedTx()方法开启一个独立于当前线程之外的事务,该事务中可以存在多个线程同时工作,在执行完之后,其中一个最终提交。
执行修改操作后,需要显示执行提交操作,关闭事务,如果未关闭事务,却执行了关闭连接操作,则操作回滚。所以,多线程情况每次执行操作后手动显示执行提交操作。
作用域
手动执行commit或rollback之后,所有与该操作关联的图形元素都不可用,但是JanusGraph会自动将顶点和类型转换到新的事务作用域中,如以下示例所示:
juno = graph.addVertex() //Automatically opens a new transactiongraph.tx().commit() //Ends transactionjuno.property("name", "juno") //Vertex is automatically transitioned
edge不会自动转换,需要刷新
e = juno.addEdge("knows", graph.addVertex())graph.tx().commit() //Ends transactione = g.E(e).next() //Need to refresh edgee.property("time", 99)
索引
参考
【https://www.cnblogs.com/shangshu/p/11107792.html#basics】
【https://segmentfault.com/a/1190000021479200】
【https://docs.janusgraph.org/index-management/index-performance/】
JanusGraph支持两种不同类型的索引来加速查询处理:图形索引和以顶点为中心的索引。
图形索引
图索引是整个图的全局索引结构,可通过其属性有效地检索顶点或边,以获取足够的选择性条件。
包含两种:符合索引和混合索引
图索引名称给必须唯一
复合索引
复合索引仅限于对先前定义好的属性键组合进行相等查找
复合索引可能只包含一个或多个键。仅具有一个键的复合索引有时称为键索引。
JanusGraphManagement janusGraphManagement = graph.openManagement();//添加nameIndexjanusGraphManagement.buildIndex("nameIndex",Vertex.class).addKey(name).buildCompositeIndex();//定义name唯一索引mgmt.buildIndex('byNameUnique', Vertex.class).addKey(name).unique().buildCompositeIndex()//添加nameAndageIndexjanusGraphManagement.buildIndex("nameAndageIndex",Vertex.class).addKey(name).addKey(age)buildCompositeIndex();try {//等待nameIndex索引变为可用ManagementSystem.awaitGraphIndexStatus(graph,"nameIndex").call();//修改索引状态。janusGraphManagement.updateIndex(janusGraphManagement.getGraphIndex(""), SchemaAction.REINDEX).get();//提交janusGraphManagement.commit();} catch (InterruptedException e) {e.printStackTrace();} catch (ExecutionException e) {e.printStackTrace();}索引的应用------>//使用nameIndex索引g.V().has('name', 'hercules')//使用nameAndageIndex索引g.V().has('age', 30).has('name', 'hercules')//不适用索引g.V().has('age', 30)//只能使用nameIdex,因为复合索引只能用于相等(equals)约束,age查询范围所以无法使用索引g.V().has('name', 'hercules').has('age', inside(20, 50))
混合索引
混合索引通过先前添加的属性键的任意组合来检索顶点或边。混合索引比复合索引提供了更大的灵活性,并支持除相等性之外的其他条件谓词,所以,对于大多数相等性查询,混合索引比复合索引慢。
混合索引需要配置索引后端,利用索引后端执行查找。janusGraph支持多个索引后端。
索引后端名称需要和set("index.search.backend", "elasticsearch")配置的index后的search相同,如果为index.elasticsearch.backend,则名称为elasticsearch
- 与复合索引不同,混合索引不支持唯一性。
//定义nameAndage混合索引,索引后端名称search。janusGraphManagement.buildIndex("nameAndAge",Vertex.class).addKey(name).addKey(age).buildMixedIndex("search");//定义nameAnd混合索引,定义Mapping.TEXT.asParameter()文本索引,默认索引使用文本索引janusGraphManagement.buildIndex("nameAndAge",Vertex.class).addKey(name, Mapping.TEXT.asParameter()).buildMixedIndex("search");以下查询行为均使用了索引---->g.V().has('name', textContains('hercules')).has('age', inside(20, 50))g.V().has('name', textContains('hercules'))g.V().has('age', lt(50))g.V().has('age', outside(20, 50))g.V().has('age', lt(50).or(gte(60)))g.V().or(__.has('name', textContains('hercules')), __.has('age', inside(20, 50)))修改索引---->/**要添加新定义的键,我们首先按名称从管理事务中检索现有索引,然后调用addIndexKey 将键添加到该索引的方法。如果添加的密钥在同一管理事务中定义,则它将立即可用于查询。如果属性键已在使用中,则添加键需要执行重新索引过程,以确保索引包含所有先前添加的元素。在重新索引过程完成之前,该键将在混合索引中不可用。*///获取先前定义的nameAndage索引JanusGraphIndex nameAndAge = janusGraphManagement.getGraphIndex('nameAndAge')//将sex键添加到nameAndage索引janusGraphManagement.addIndexKey(nameAndAge, sex);janusGraphManagement.commit();//等待nameAndage索引边为ENABLEManagementSystem.awaitGraphIndexStatus(graph, 'nameAndAge').status(SchemaStatus.REGISTERED, SchemaStatus.ENABLED).call()janusGraphManagement = graph.openManagement()//重新添加索引janusGraphManagement.updateIndex(mgmt.getGraphIndex("nameAndAge"), SchemaAction.REINDEX).get()
顶点索引
以顶点为中心的索引是每个顶点单独构建的局部索引结构。以顶点为中心是建立在边上的索引
//寻找由h发起的bttle次数在10次到20次之间的顶点g.V(h).outE('battled').has('time', inside(10, 20)).inV()//在battled边标签上建立battlesByTime索引,方向为双向,依据次数降序排列janusGraphManagement.buildEdgeIndex(battled, 'battlesByTime', Direction.BOTH, Order.desc, time)//在battle边标签上建立battlesByRatingAndTime索引,输出方向,根据rating和time降序排列,janusGraphManagement.buildEdgeIndex(battled, 'battlesByRatingAndTime', Direction.OUT, Order.desc, rating, time)顶点索引是前缀索引,首先匹配rating,再匹配time----->g.V(h).outE('battled').has('rating', gt(3.0)).inV()g.V(h).outE('battled').has('rating', 5.0).has('time', inside(10, 50)).inV()//该查询无法使用索引g.V(h).outE('battled').has('time', inside(10, 50)).inV()
标签索引
//该索引仅作用于god顶点标签janusGraphManagement.buildIndex('byNameAndLabel', Vertex.class).addKey(name).indexOnly(god).buildCompositeIndex()//标签限制同样适用于混合索引janusGraphManagement.buildIndex("",Vertex.class).addKey(name).indexOnly(god).buildMixedIndex("serach");将具有标签限制的复合索引定义为唯一时,唯一性约束仅适用于指定标签的顶点或边上的属性。
有序遍历
g.V(h).local(outE('battled').order().by('time', desc).limit(10)).inV().values('name')g.V(h).local(outE('battled').has('rating', 5.0).order().by('time', desc).limit(10)).values('place')
模糊查询
在索引后端定义混合索引时设置。
全文搜索
mgmt.buildIndex('booksBySummary', Vertex.class).addKey(summary, Mapping.TEXT.asParameter()).buildMixedIndex("search")
可用搜索谓词
- textContains:如果(至少)文本字符串内的一个单词与查询字符串匹配,则为true
- textContainsPrefix:如果(至少)文本字符串内的一个单词以查询字符串开头,则为true
- textContainsRegex:如果(至少)文本字符串中的一个单词与给定的正则表达式匹配,则为true
- textContainsFuzzy:如果(至少)文本字符串中的一个单词与查询字符串相似(基于Levenshtein编辑距离),则为true
字符串搜索
mgmt.buildIndex('booksBySummary', Vertex.class).addKey(name, Mapping.STRING.asParameter()).buildMixedIndex("search")
可用搜索谓词
- eq:如果字符串与查询字符串相同
- neq:如果字符串与查询字符串不同
- textPrefix:如果字符串值以给定的查询字符串开头
- textRegex:如果字符串值完全匹配给定的正则表达式
- textFuzzy:如果字符串值类似于给定的查询字符串(基于Levenshtein编辑距离)
全文和字符串搜索
索引后端使用ES时,可以同事为文本和字符串定义索引,可以使用所有谓词进行模糊匹配
数据将两次存储在索引中,一次用于精确匹配,一次用于模糊匹配。
mgmt.buildIndex('booksBySummary', Vertex.class).addKey(summary, Mapping.TEXTSTRING.asParameter()).buildMixedIndex("search")
TinkerPop
将TinkerPop文本谓词与JanusGraph一起使用,但是这些谓词不使用索引,这意味着它们需要在内存中进行过滤。
索引的生命周期
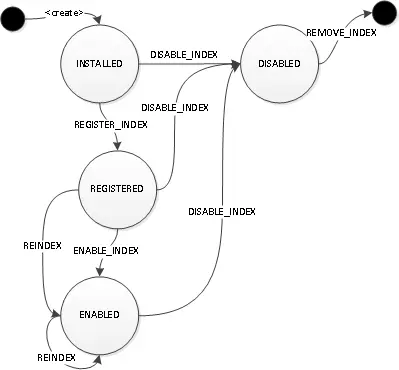
删除索引
索引删除过程分为两段,第一阶段将索引状态改为DISABLED,停止是用该索引进行检索,在存储后端中仍然存在相关数据。
第二阶段,取决于是混合索引还是复合索引,复合索引可以通过janusgraph删除。混合索引需要到索引后端中手动删除。
简单示例
import org.apache.tinkerpop.gremlin.process.traversal.dsl.graph.GraphTraversalSource;import org.apache.tinkerpop.gremlin.structure.Edge;import org.apache.tinkerpop.gremlin.structure.Property;import org.apache.tinkerpop.gremlin.structure.Vertex;import org.apache.tinkerpop.gremlin.structure.VertexProperty;import org.janusgraph.core.*;import java.util.Iterator;import java.util.List;/*** Created by zheng on 2020-08-03.*/public class JanusgraphUtil {private JanusGraph graph1;private JanusGraphTransaction graph;String HumanLabel = "v_human";String pkName = "pk_name";public void connectJanusGraph(){System.out.println("start connect");JanusGraphFactory.Builder builder = JanusGraphFactory.build().set("storage.hostname", "grandland1, grandland2, grandland3").set("storage.backend", "hbase").set("storage.hbase.table", "janusgraph").set("index.search.backend", "elasticsearch").set("index.search.hostname", "grandland1");graph1 = builder.open();boolean open = graph1.isOpen();System.out.println("is open:" + open);graph = graph1.newTransaction();System.out.println("connect end");}/*** 顶点v_human有一个pk_name属性。*/public void intHumanVertex() {System.out.println("start init schema");PropertyKey pkName = graph.makePropertyKey("pk_name").dataType(String.class).cardinality(Cardinality.SET).make();VertexLabel HumanLabel = graph.makeVertexLabel("v_human").make();graph.addProperties(HumanLabel,pkName);System.out.println("init schema end");}public void initHuman(){System.out.println("start init human");Vertex jimo = graph.addVertex(HumanLabel);jimo.property(pkName,"JIMO");Vertex lily = graph.addVertex(HumanLabel);lily.property(pkName,"LILY");Vertex hehe = graph.addVertex(HumanLabel);hehe.property(pkName,"HEHE");System.out.println("init human end");}public void findHuman() {System.out.println("start find human");GraphTraversalSource g = graph.traversal();Vertex v = g.V().has(pkName,"JIMO").next();System.out.print(v.label() + ":" );Iterator<VertexProperty<Object>> ps = v.properties();while(ps.hasNext()){System.out.println(ps.next());}System.out.println("find end");}/*** 边e_married有一个pk_married_year属性*/public void initEWifeEdge(){System.out.println("start insert edge");PropertyKey pkMarriedYear = graph.makePropertyKey("pk_married_year").dataType(Integer.class).cardinality(Cardinality.SINGLE).make();EdgeLabel ewifeLabel = graph.makeEdgeLabel("e_married").multiplicity(Multiplicity.ONE2ONE).make();graph.addProperties(ewifeLabel,pkMarriedYear);}public void insertEWife() {System.out.println("start init EWife");GraphTraversalSource g = graph.traversal();Vertex jimo = g.V().has(pkName,"JIMO").next();Vertex lily = g.V().has(pkName,"LILY").next();jimo.addEdge("e_married",lily,"pk_married_year",10);System.out.println("init EWife end");}public void initEFriendEdge() {PropertyKey pkFriend = graph.makePropertyKey("pk_tight").dataType(Double.class).cardinality(Cardinality.SINGLE).make();EdgeLabel eFriend = graph.makeEdgeLabel("e_friend").multiplicity(Multiplicity.MULTI).make();graph.addProperties(eFriend,pkFriend);}public void initEFriend() {GraphTraversalSource g = graph.traversal();Vertex lily = g.V().has(pkName,"LILY").next();Vertex hehe = g.V().has(pkName,"HEHE").next();lily.addEdge("e_friend",hehe,"pk_tight",8.8);}public void findWifeEdge(){GraphTraversalSource g = graph.traversal();Vertex v = g.V().has("pk_name","JIMO").out("e_married").next();Vertex friend = g.V().has("pk_name","LILY").out("e_friend").next();printVertex(v);printVertex(friend);//获取LILY的双向边,遍历输出List<Edge> list = g.V(v).bothE().toList();for(Edge e : list) {System.out.println(e.label());Iterator<Property<Object>> ps = e.properties();while (ps.hasNext()) {Property<Object> property = ps.next();System.out.print(property + ",");}System.out.println();}}public void printVertex(Vertex v) {Iterator<VertexProperty<Object>> properties = v.properties();System.out.println(v.label() + ":");while(properties.hasNext()){VertexProperty<Object> property = properties.next();System.out.println(property + ",");}System.out.println();}public void close() {graph.commit();graph.close();}public static void main(String[] args) {JanusgraphUtil janusgraphUtil = new JanusgraphUtil();janusgraphUtil.connectJanusGraph();// janusgraphUtil.initEWifeEdge();// janusgraphUtil.insertEWife();// janusgraphUtil.initEFriendEdge();// janusgraphUtil.initEFriend();janusgraphUtil.findWifeEdge();/*janusgraphUtil.intHumanVertex();janusgraphUtil.initHuman();janusgraphUtil.findHuman();*/janusgraphUtil.close();}}
Gremlin

若有收获,就点个赞吧
0 人点赞
