数组
声明方式
let x = [1, 2, 3]
底层实现
使用内存管理器进行实现。每当你申请数组时,计算机在内存中开辟一段连续的地址,每段地址都可以直接通过内存管理器进行访问。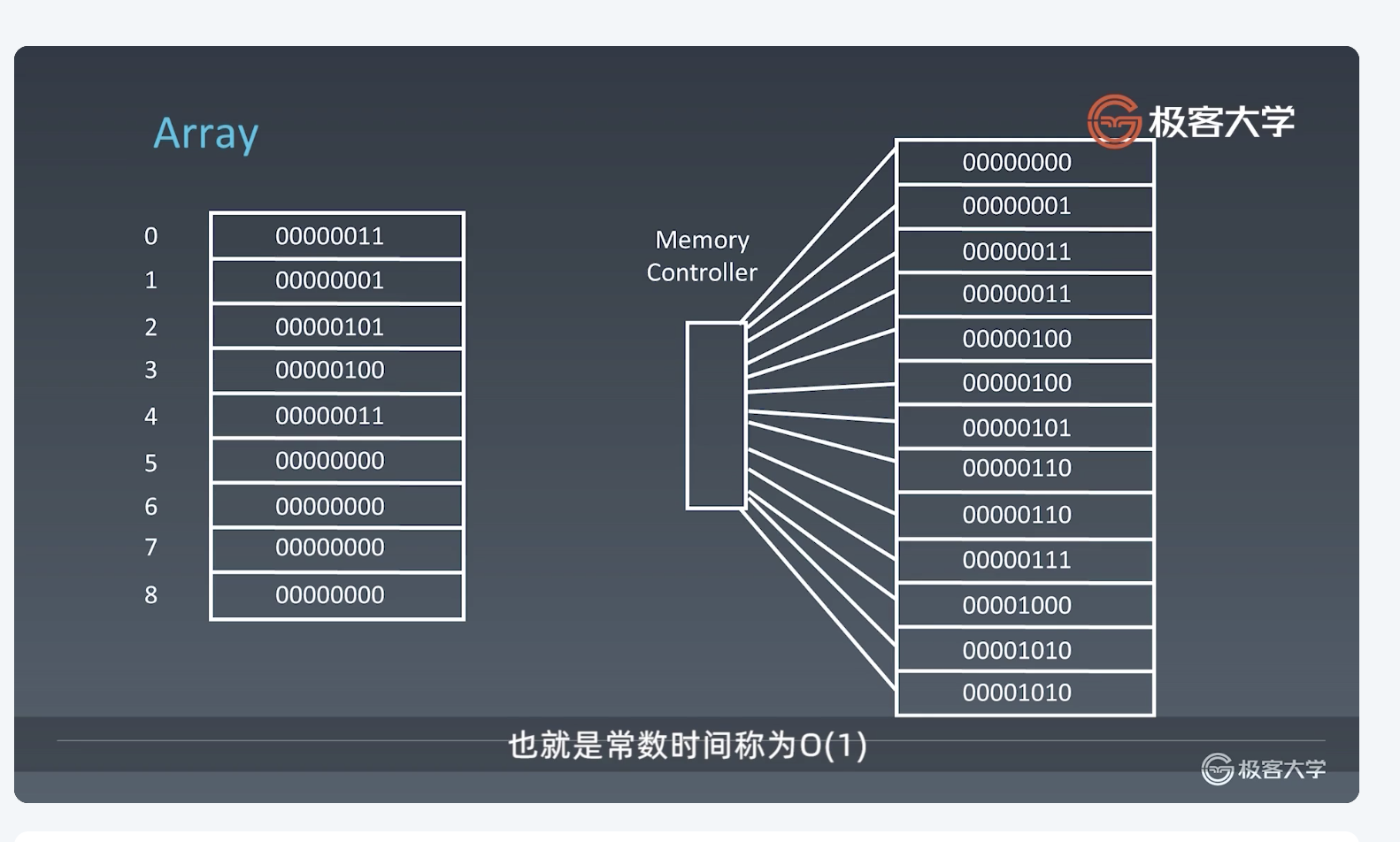
在这里可以看到,访问数组中任意一个元素,时间复杂度都是 **O(1)** ,它可以进行随机访问任何一个元素。所以访问时间特别快。
查询
数组实现随机访问,主要是依靠数组一个特性:连续的内存空间。
如果存储上实现了连续存储,则可以依靠 偏移量 进行访问存储的元素(什么是数组的偏移量?怎么计算呢?)。
例如一个数组,他的内存地址为 1000 - 1039 ,则起始位置为 1000 。如下图所示:
如果我们要访问数组下标为 [2] 的元素,则可以用以下公式找到下标为 [2] 的元素的内存地址:
a[2]_address = 1000 + 2 * data_type_size
data_type_size 为每个元素大小
插入
假设数组的index,从0一直到5,内容分别是 A B C E F G:
如果我们要在下标为 3 的位置插入元素D,则需要将 EFG 这三个元素依次向后挪动一位: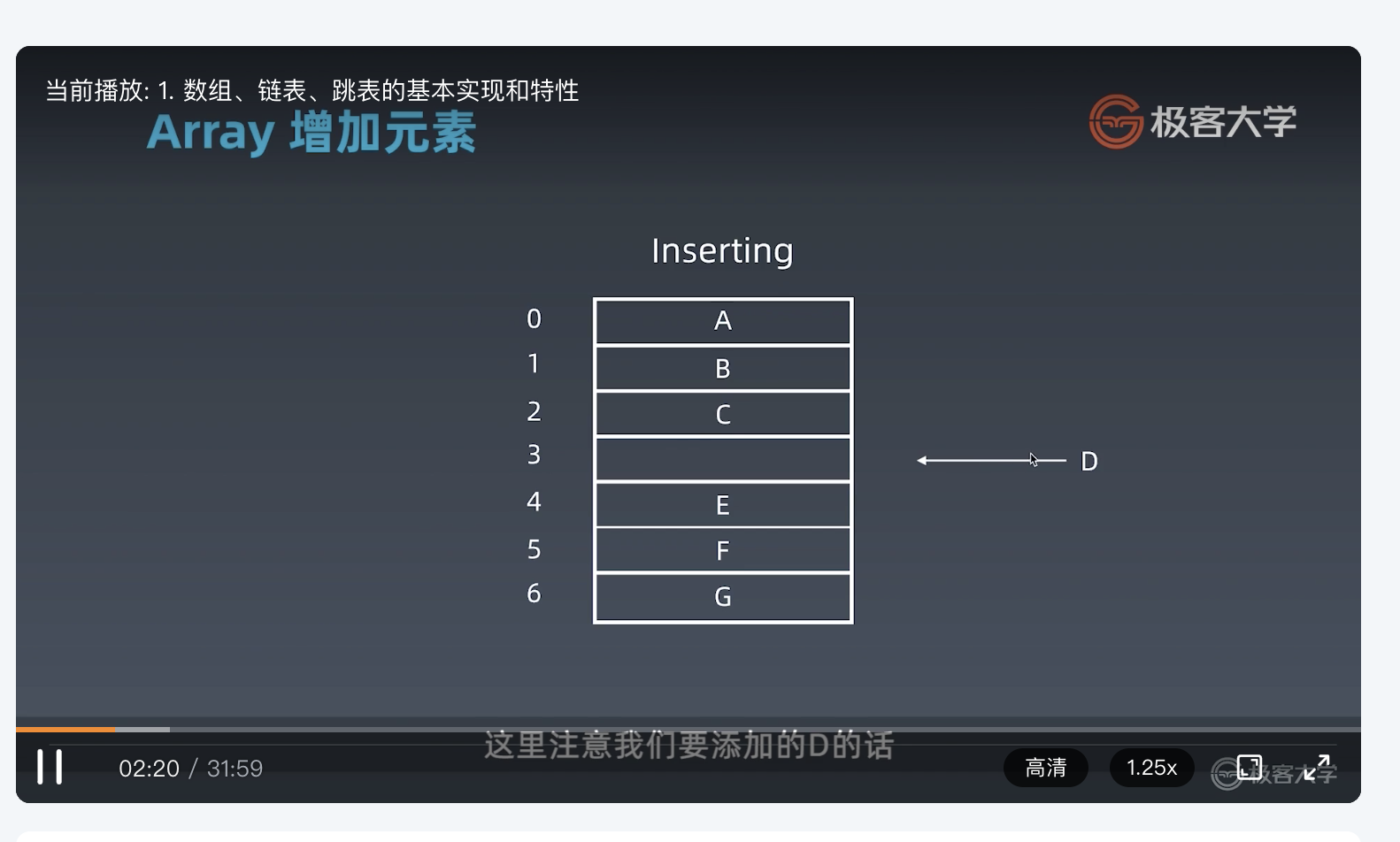
而这个移动操作,则导致我们的插入操作的时间复杂度变为了 O(n) (在最后插入元素不算) 。如果要在数组头部插入元素,则需要挪动整个 arr.length 。平均挪动次数为 **arr.length / 2** 。
最后完成挪动后,将元素 D 插入到index为 3 的位置。
删除
假设我们要删除元素 D ,则可以将 D 之后元素的位置依次向前挪动一位。然后将最后一个元素置为空,或者数组长度 - 1
时间复杂度

Java 中 ArrayList 的代码实现
ArrayLIst 为原生Array的封装。封装了数组删除,添加等操作
源码地址:http://developer.classpath.org/doc/java/util/ArrayList-source.html
插入一个元素(插入到数组末尾)
public boolean add(E e){modCount++;if (size == data.length){ensureCapacity(size + 1);}data[size++] = e;return true;}
- 判断数组SIze是否足够,如果不够,申请数组空间
- 在数组末尾插入元素 e
插入一个元素(插入到指定index)
public void add(int index, E element) {rangeCheckForAdd(index);ensureCapacityInternal(size + 1); // Increments modCount!!System.arraycopy(elementData, index, elementData, index + 1, size - index);elementData[index] = element;size++;}
- 判断数组是否越界
- 修改次数标识符 + 1
- 拷贝数组。将原数组地址,拷贝到目标地址的位置中去。拷贝 size - index 长度
- 赋新值
- 长度 + 1
ensureCapacity

作用:给数组开辟新的空间。实现思路如下:
声明方式
Java: LinkedList
概念
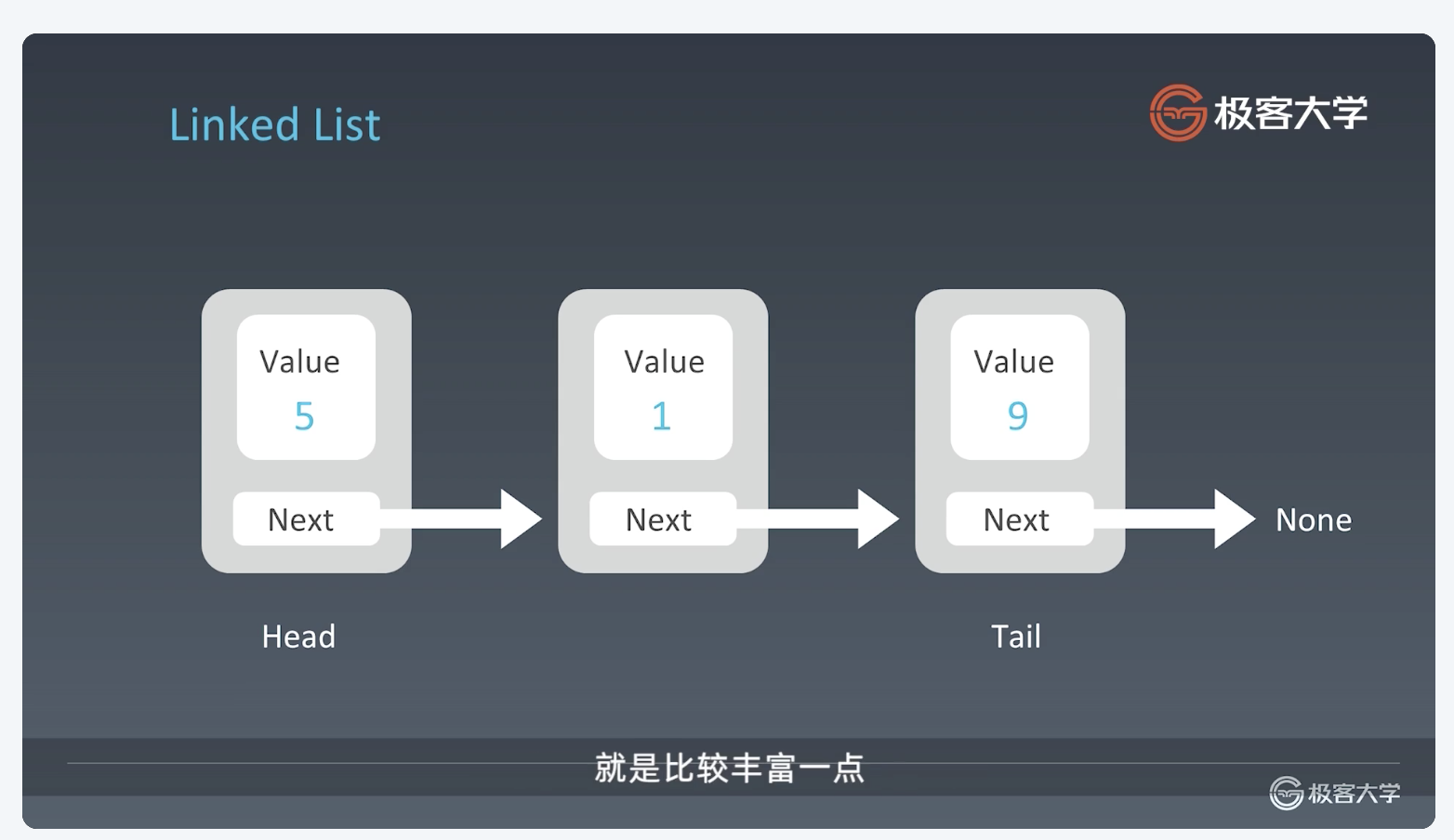
链表由一个个的节点组成。每个节点的 value 属性为节点值, next 为指向下个节点的指针。这样的做法,组成了 链表 。其中,第一个元素称为“头指针”,最后一个称为“尾指针”。
最后一个元素的后面没有其他元素,则next指向null。
如果每个节点还有一个prev指针指向前一个元素,则该链表叫做双向链表。
如果尾节点指针指向头指针,则该链表叫做循环链表。
底层实现
由于链表是由指针串联起来的,其 next 只是存放了下个节点的 内存指针 ,所以链表的内存空间是非连续的。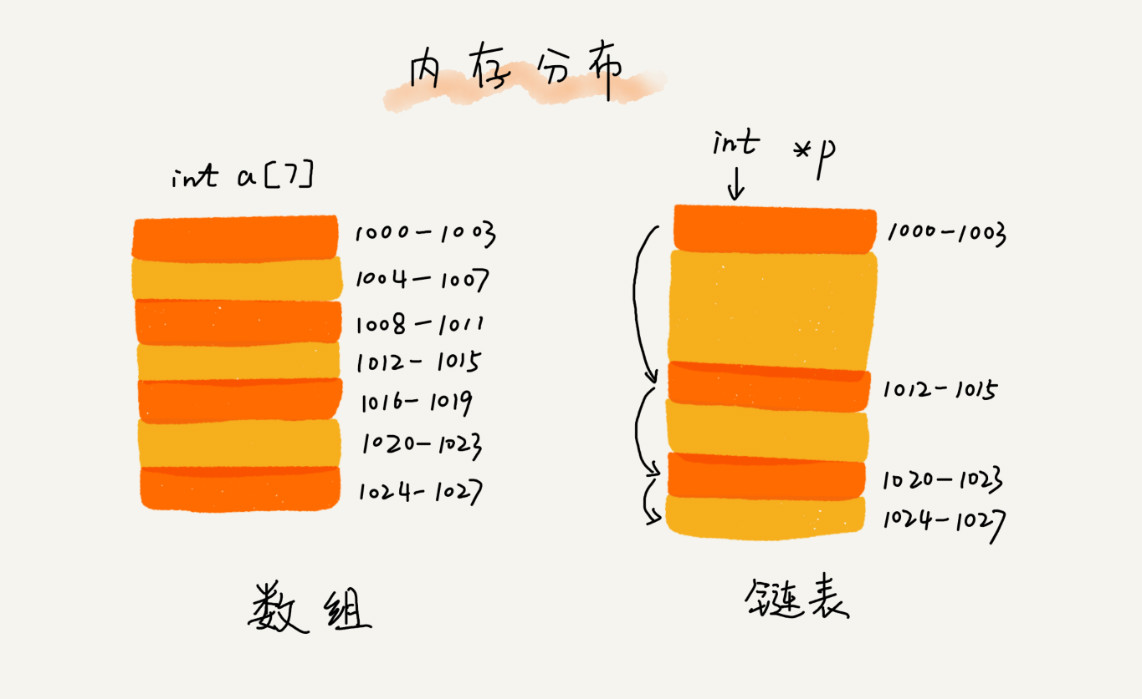
链表可以通过指针,把一系列零散的内存块串联起来。所以当内存中如果没有足够多的连续内存,链表依然可以照常工作。这就导致了,链表在删除/新增元素时,只需要将内存指针指向/解除对元素的关联即可,而不需要其他元素进行移动。但是当查询元素时,由于不是连续的内存空间,用偏移的方式查询也就失效。只能一个节点一个节点向下寻找。
如果链表删除一个元素,该元素在没有任何其他变量引用的情况下,编译器垃圾回收机制将会自动回收该空间(GC标记清除算法)
添加
假设新节点要插入在链表第2个位置的地方,我们只需要将第2个的前继节点的next指针指向新元素,将新元素的next指针指向原来的第2个元素即可。常数级操作,时间复杂度为O(1)
删除
删除操作与刚才的一致。例如要删除链表中第2个元素,我们只需要将要删除元素的前继节点的next指针,指向要删除元素的next指针指向的元素即可。常数级操作,时间复杂度为O(1)
查询
因为链表是非连续存储,所以查询的效率为O(1)。
时间复杂度对比
跳表
链表元素有序

如果是一个有序数组,可以使用二分查找进行元素查找。如果是一个有序链表的话,则可以使用跳表优化查询速度

跳表只能适用于链表元素有序的情况下。它对标的是AVL和二分查找。
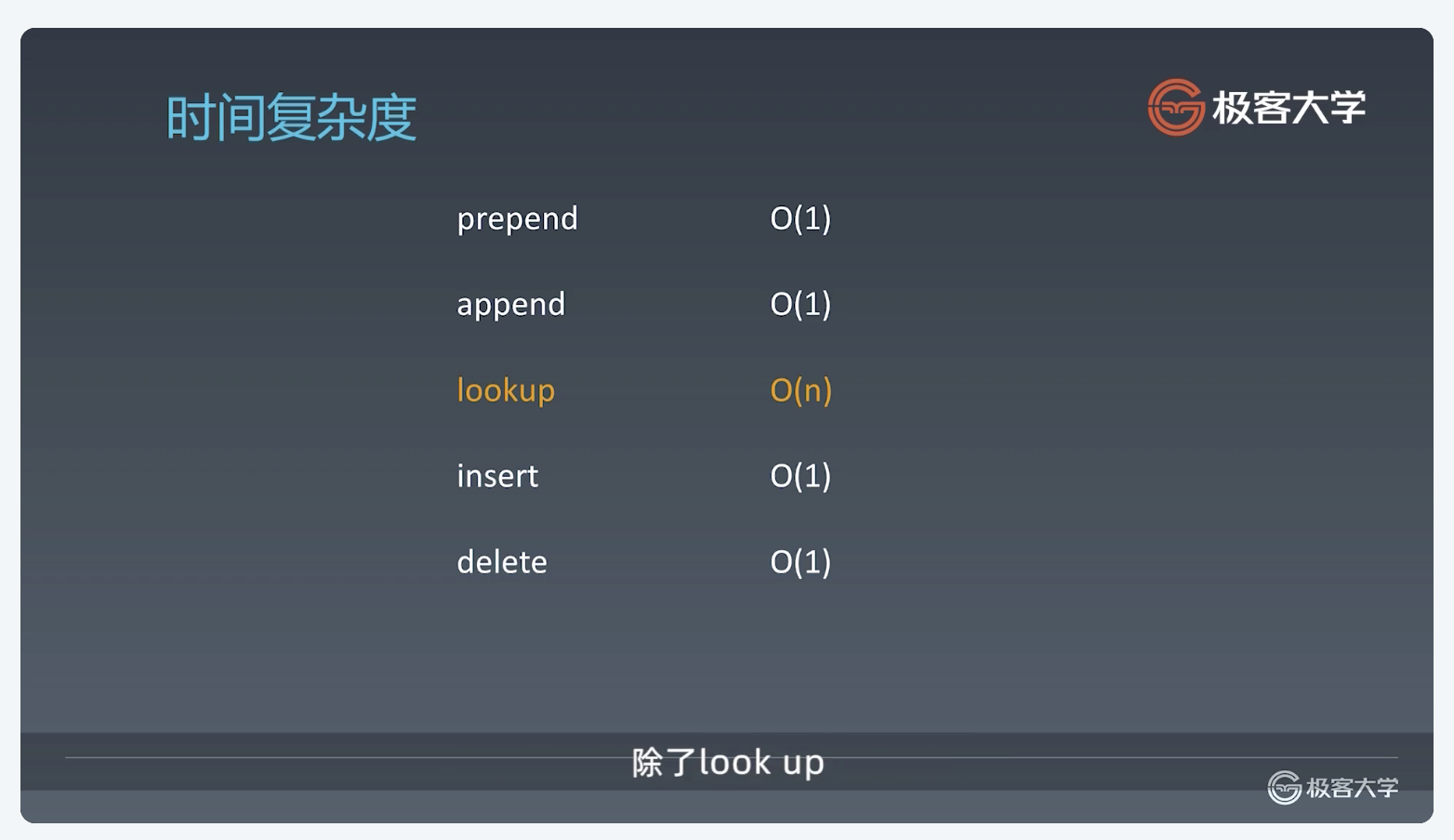
如何给有序的链表加速

升维
一维的数据结构如果想加速,可以采用升维的方式。多一级维度,则多一层信息,也就可以帮助你很快的找到元素。
在原始链表的情况下,我们可以用添加索引的方式加快查询速度。
例如我们要找到元素8,可以先走一级索引,走到9。我们发现9大于8,则可以从9挨个向前查找。向前1个元素后,则找到8。这样我们利用一级索引,只走了4步。
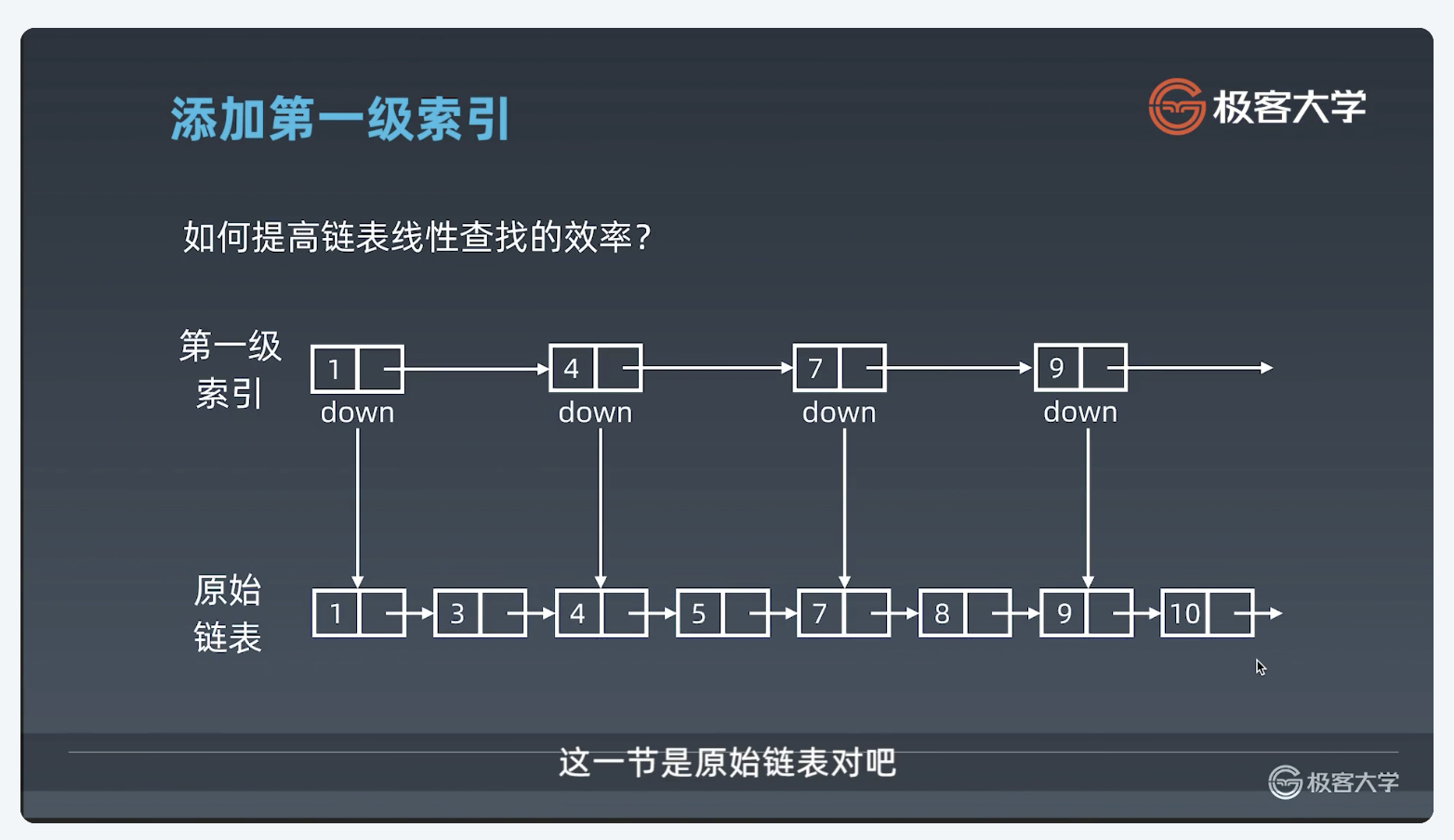
如果还想加速,则可以再加一级缓存:
以此类推,则可以向上加索引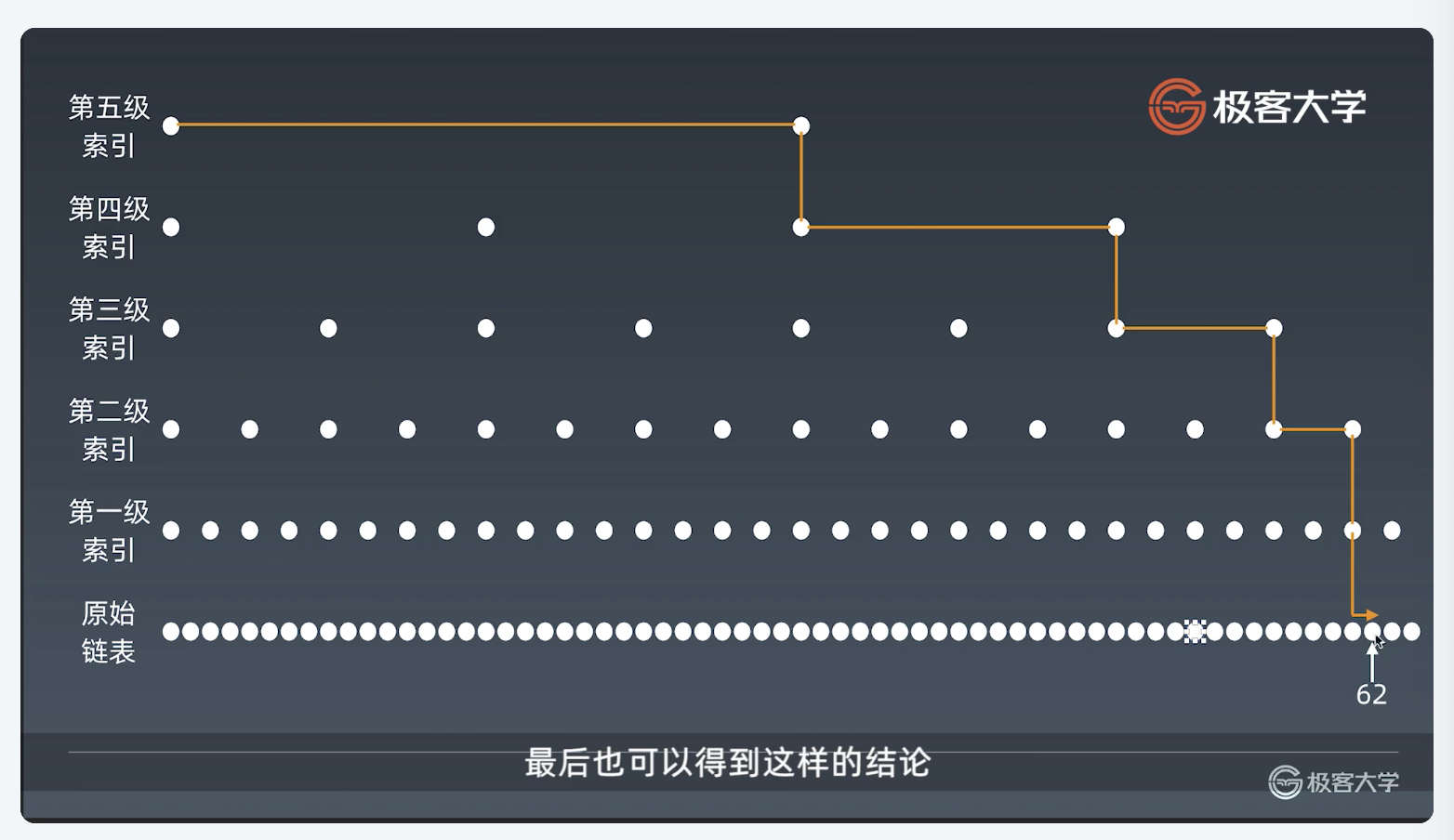
时间复杂度

通过计算,可以得出时间复杂度为logn

若有收获,就点个赞吧
0 人点赞
