Hive认证和鉴权
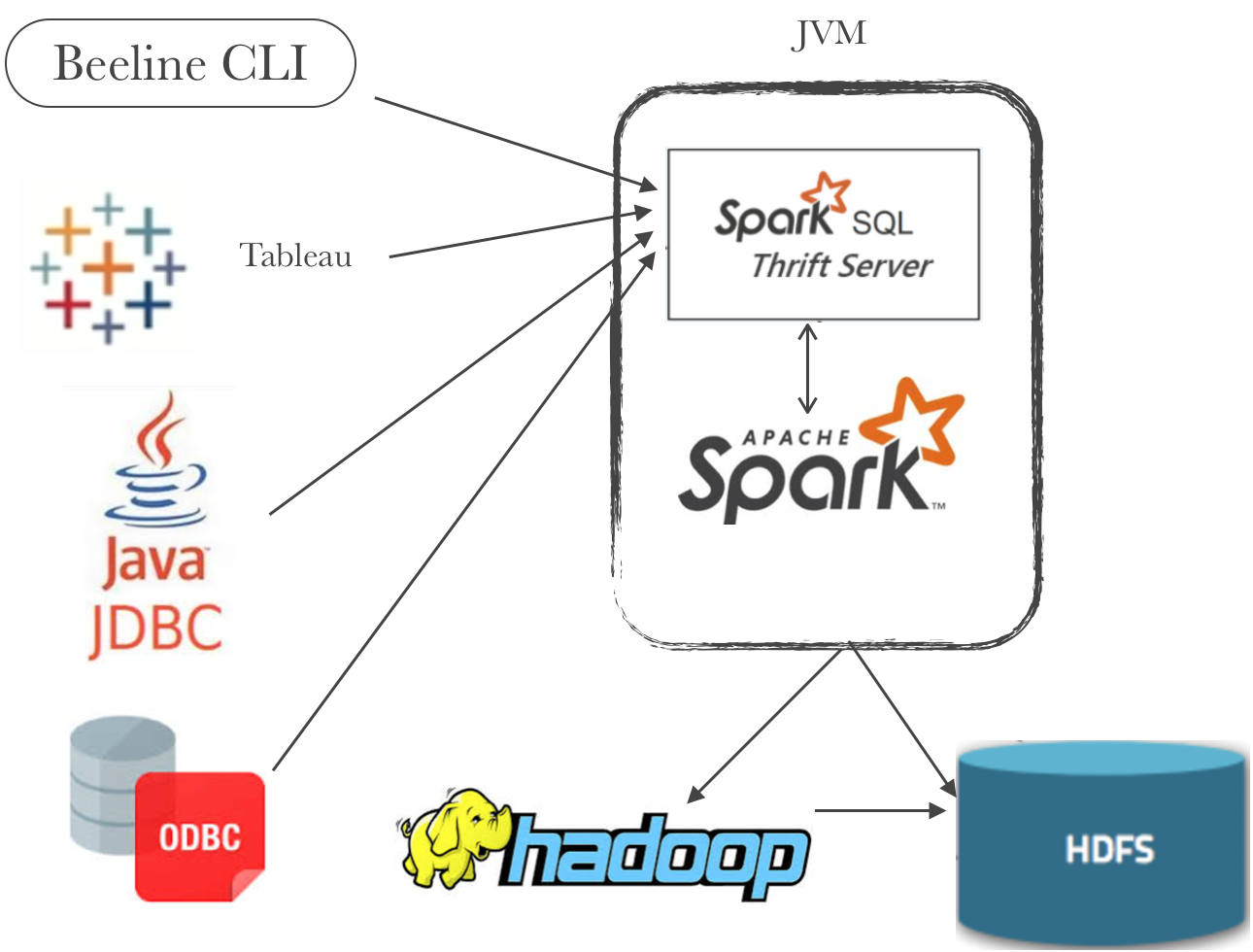
HiveServer2 & Spark Thriftserver架构
- Hive(HiveServer2, MetaStore)/Spark Thrift Server认证
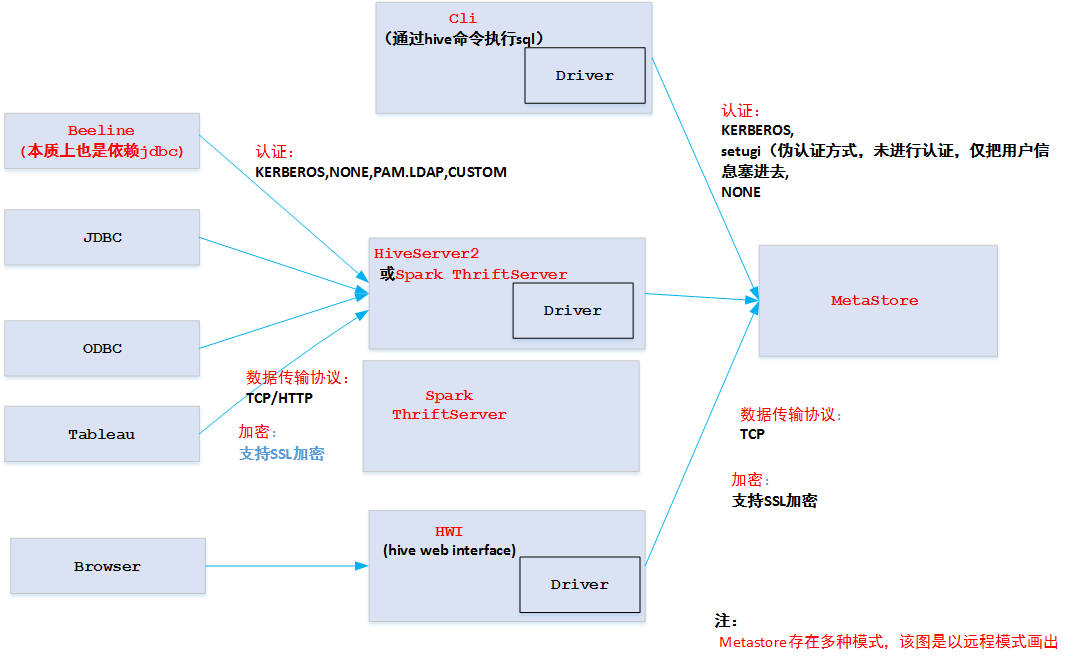
- spark thriftserver和hiveserver2本质上差不对,spark thriftserver复用了hiveserver2很多代码。实现上稍微有点区别。主要为了对接beeline、jdbc、odbc而不需要重新重新实现这些代码而引入。因此,spark使用jdbc时,需要将hive的jdbc模块jar包拿过来
Hive认证
HiveServer2认证(Spark ThriftSever也差不多)
- 支持不同的认证机制
HIVE_SERVER2_AUTHENTICATION("hive.server2.authentication", "NONE",new StringSet("NOSASL", "NONE", "LDAP", "KERBEROS", "PAM", "CUSTOM")
- 支持不同的传输协议
//支持tcp/http传输协议transport = isHttpTransportMode() ? createHttpTransport() : createBinaryTransport();分别对应ThriftHttpCLIService和ThriftBinaryCLIService
//LDAP认证配置样例<property><name>hive.server2.authentication</name><value>LDAP</value></property><property><name>hive.server2.authentication.ldap.url</name><value>ldap://bigdata110.bigdata.hikvision.com:389</value></property><property><name>hive.server2.authentication.ldap.baseDN</name><value>cn=users,cn=accounts,dc=bigdata,dc=hikvision,dc=com</value></property><property><name>hive.server2.authentication.ldap.userDNPattern</name><value>uid=%s,cn=users,cn=accounts,dc=bigdata,dc=hikvision,dc=com</value></property>
MetaStore认证
- 认证方式支持的不如HiveServer2,并不是提供某个类型来确定是哪种认证
//kerberos认证USE_SSL("metastore.use.SSL", "hive.metastore.use.SSL", false,"Set this to true for using SSL encryption in HMS server."),//setugi方式认证EXECUTE_SET_UGI("metastore.execute.setugi", "hive.metastore.execute.setugi", true, ...""),
Hive鉴权
HiveServer2/MetaStore鉴权
- DefaultHiveAuthorizationProvider: Old default Hive Authorization (Legacy Mode)
由于每个用户都可以给自己授权,只能防止用户误操作,无法解决恶意用户访问的问题 - SQLStdHiveAuthorizerFactory: SQL Standard Based Hive Authorization
有专门的admin角色用于创建角色和授权等 - StorageBasedAuthorizationProvider基于存储的鉴权
底层依赖于hdfs的鉴权系统,用于MetaStore鉴权,可以和SQLStdHiveAuthorizerFactory联合使用 - 基于ranger(基于策略的鉴权PBAC)和sentry(基于角色的鉴权RBAC)的插件鉴权
策略:对应一组黑白名单(allowACL, denyAcl)
注:前面三个是hive内置的,具体配置和说明见参考文献第一个hive wiki 文档
ranger鉴权配置样例
//ranger鉴权样例<property><name>hive.security.authorization.enabled</name><value>true</value></property><property><name>hive.security.authorization.manager</name><value>org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizerFactory</value></property><property><name>hive.security.authenticator.manager</name><value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticator</value></property><property><name>hive.conf.restricted.list</name><value>hive.security.authorization.enabled,hive.security.authorization.manager,hive.security.authenticator.manager</value></property>
Ranger鉴权
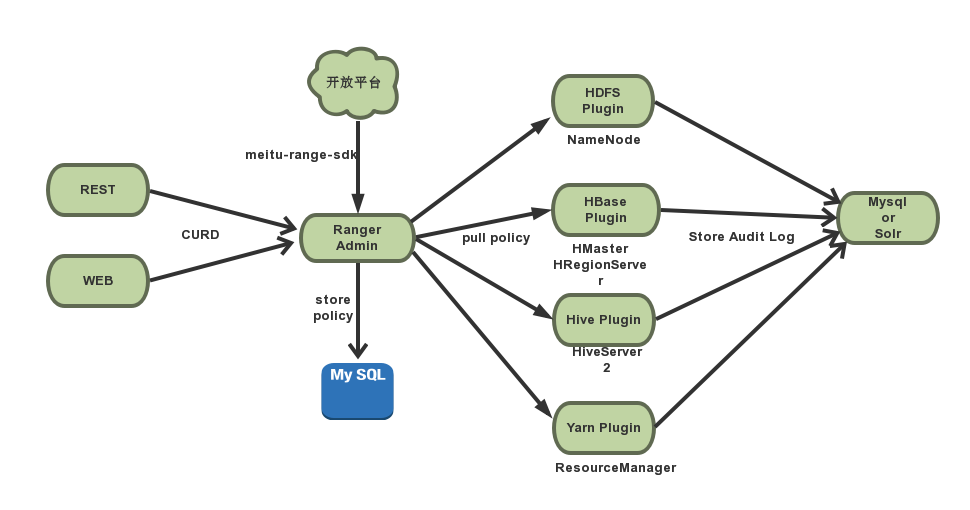
Ranger架构
- RangerAdmin: 以restful方式提供策略的增删改查接口,同时内置一个Web管理页面,讲策略存储数据库中。
- Service Plugin: 以插件形式安装在各组件的classpath下
- 定期从RangerAdmin拉取策略
- 根据策略执行访问决策树
- 实时记录访问审计
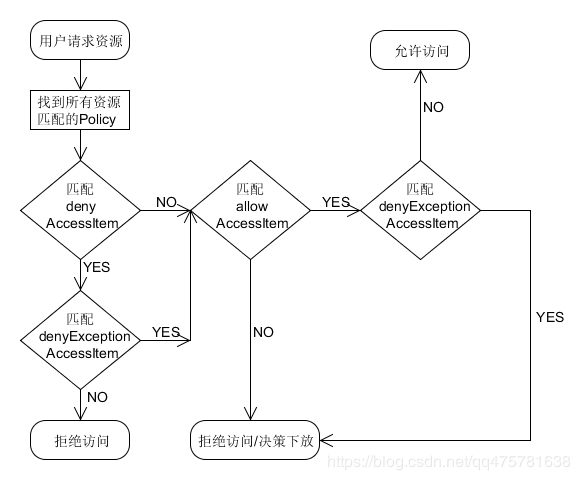
鉴权流程
- 优先级
- 黑名单优先级高于白名单
- 黑名单排除优先级高于黑名单
- 白名单排除优先级高于白名单
Hive MetaStore(HMS)
Hive metastore执行模式
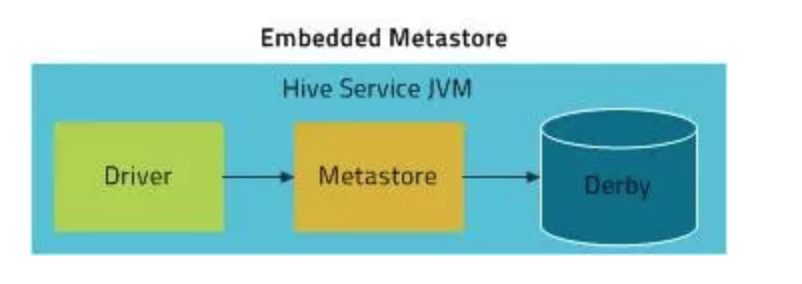
- 嵌入模式
- metastore,derby数据库和driver同属于一个进程,如使用hiveserver2,则都有hiveserver2管理
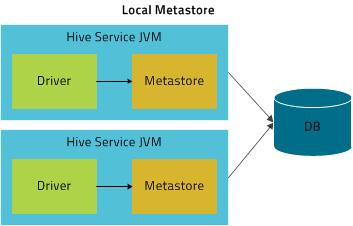
- 本地模式
- metastore,driver同属于一个进程,如使用hiveserver2,则都有hiveserver2管理
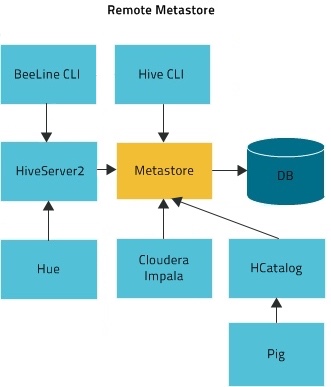
- 远程模式
- metastore,driver,mysql数据库分别属于不同进程
flink hive鉴权对接
需要做哪些?
- flink将hive元数据存储在MetaStore,目前HBP平台MetaStore层面是没有做认证和鉴权的,因此hlink/flink无需做什么。
flink鉴权
需要做什么?
- 既然是做鉴权,那得看flink有没有 资源,有了资源自然需要考虑鉴权。flink sql层面有表资源?
- 和其他组件如hbase/hdfs/kafka/hive等交互的鉴权,有各组件服务端去完成,我们只需要携带用户信息即可。
怎么做
- spark sql和ranger对接的权限管理,目前并没有内置该功能,hbp中该spark ranger插件来自于他人开发的,见 https://github.com/yaooqinn/spark-ranger.我们可以参考该项目,采用注入规则的方式实现(可贡献社区)
- 修改flink代码增加鉴权接口,实现接口(可贡献社区)
- 将下面内容抽到上层,遍历Operation类型进行鉴权操作(项目自己实现的方式)
public TableResult executeSql(String statement) {List<Operation> operations = parser.parse(statement);if (operations.size() != 1) {throw new TableException(UNSUPPORTED_QUERY_IN_EXECUTE_SQL_MSG);}return executeOperation(operations.get(0));}
参考文献

若有收获,就点个赞吧
0 人点赞
