1.论述题
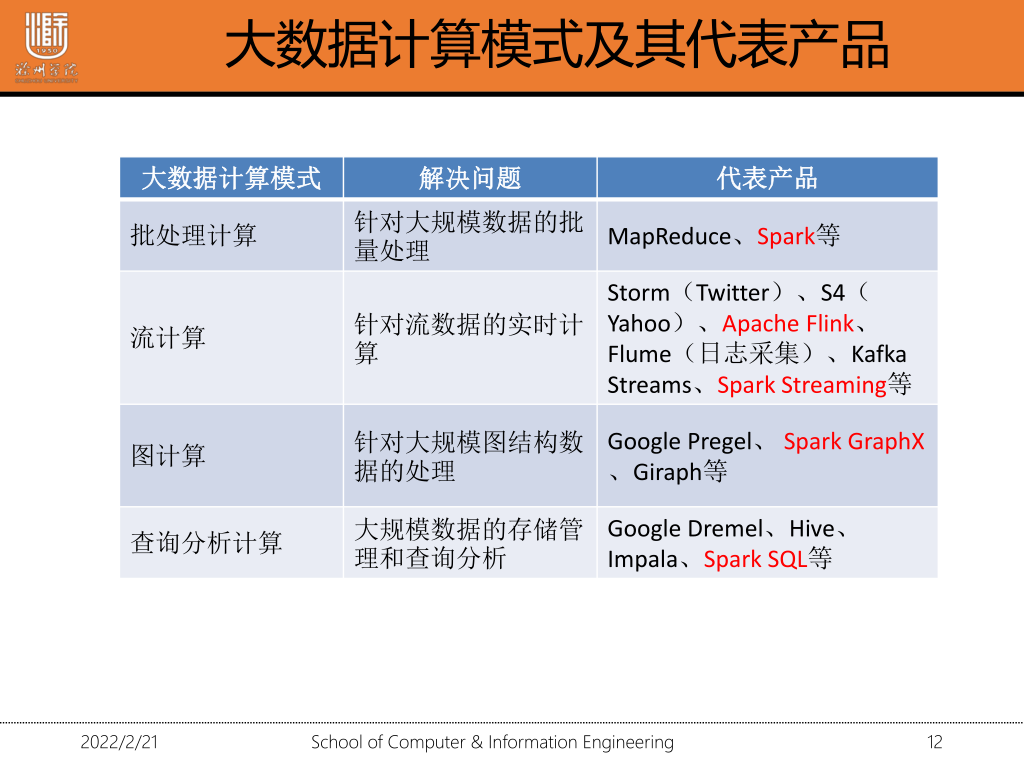
1·1 大数据的计算模式机器解决问题
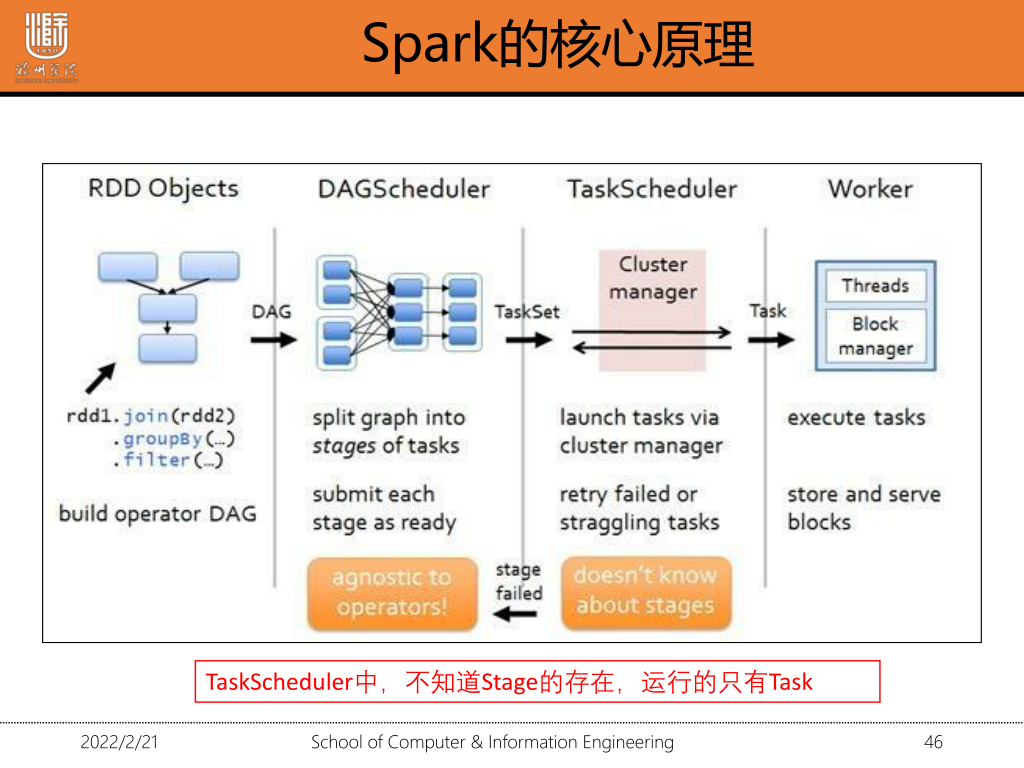
1·2 spark-streaming的运行原理

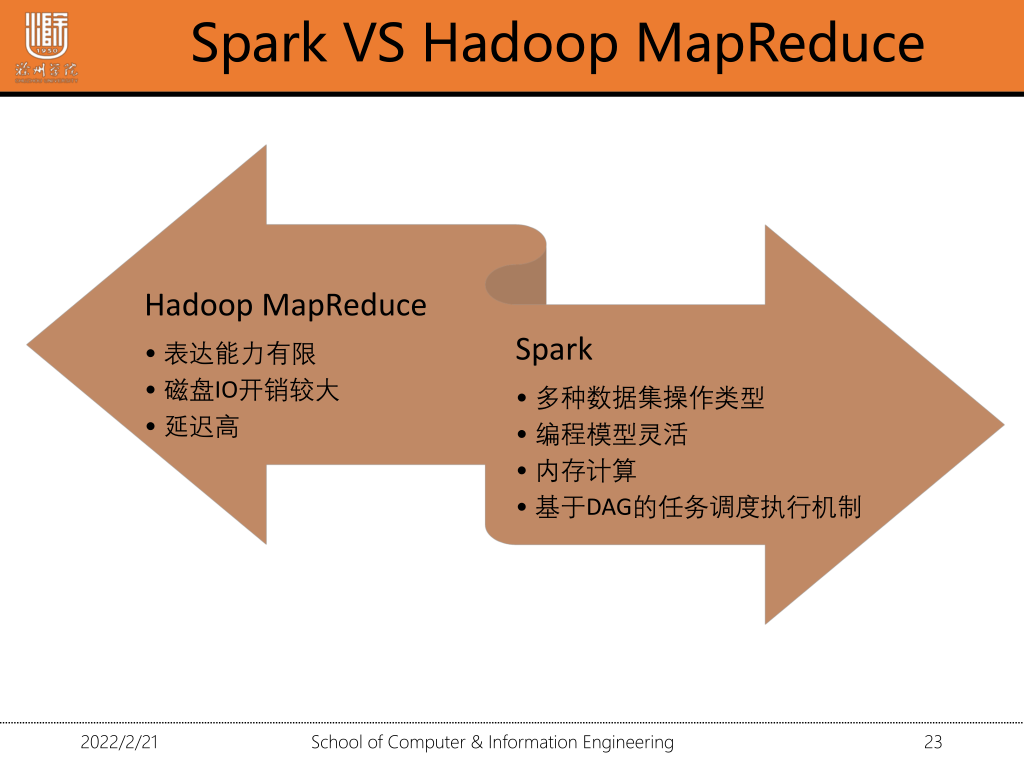
1·3 spark会取代Hadoop吗?
我们知道Hadoop包含三个组件yarn,hdfs,MapReduce,分别对应解决三个方面的问题,资源调度(yarn),分布式存储(hdfs),分布式计算(mapreudce)。而spark只解决了分布式计算方面的问题,跟MapReduce需要频繁写磁盘不同,spark重复利用内存,大大提高了计算效率,在分布式计算方面spark大有取代MapReduce之势,而在资源调度,和分布式存储方面spark还无法撼动。
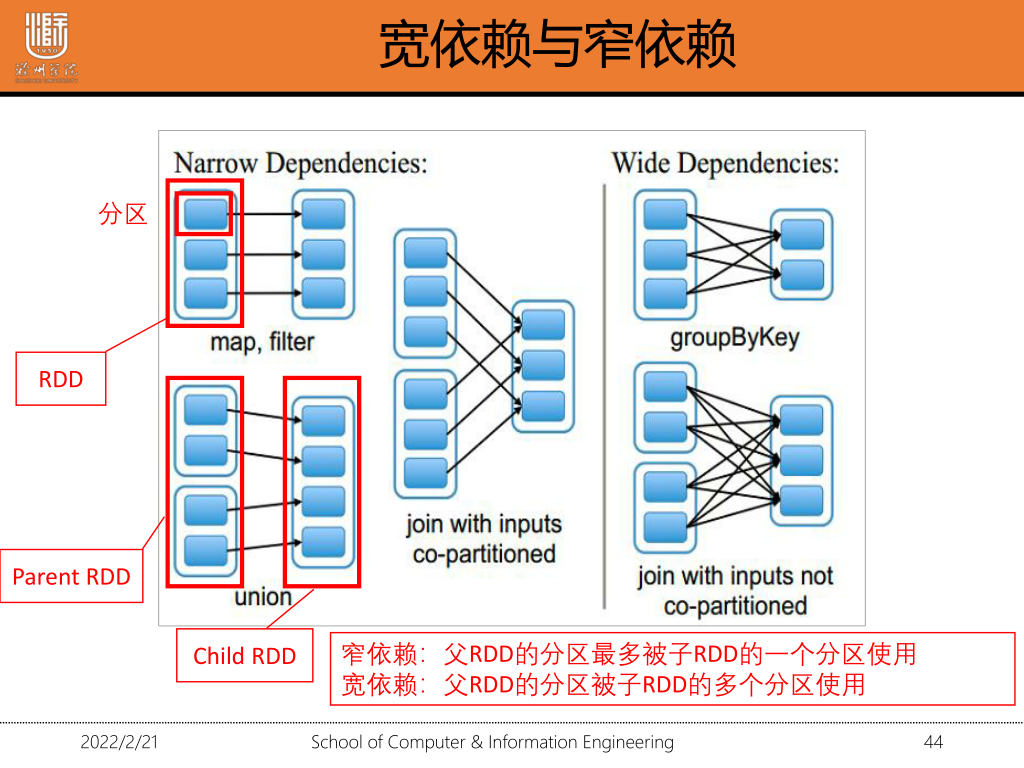
1·4 宽依赖与窄依赖及其区别
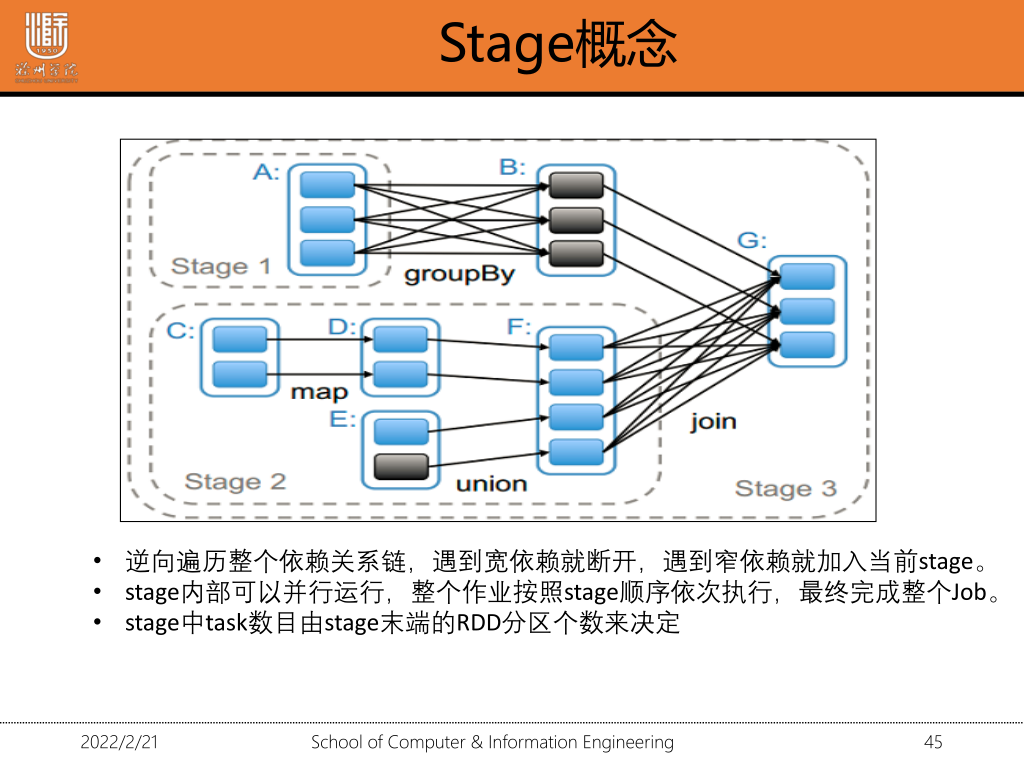
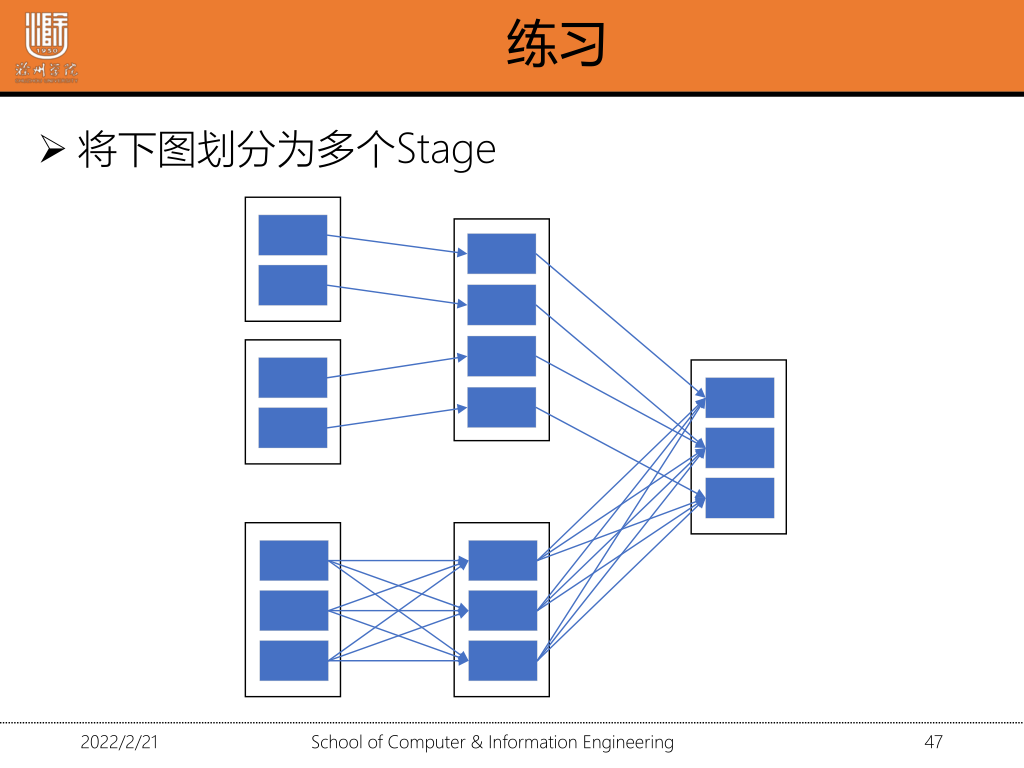
1·5 划分stage
 2.程序填空
2.程序填空
2.1文件的加载
1.加载parquet文件为DataFrame 结构化数据创建DataFramevar dfusers=spark.read.load(/user/users."")2.json-->dataframe json()val dfPeople=spark.read.json("josn文件名")val dfPeople1=spark.read.format("json").load("../data.json")3.外部数据库创建DFval jdbcDF=spark.read.format("jdbc").options()jdbcDF.show()
2.2 map/flatMap()
1. map() 筛选出满足函数func的元素,并返回一个新的数据集
val rdd1=sc.parallelize(List(1,2))
val square=rdd1.map(x=>x*x) //平方操作
2.flatmap() 常用来切分单词。先map-》flat 将不同级别迭代器中的元素当成同级别的元素
test.flatMap(x=>x.split("")).collect
2.3 filter/reduceByKey
1. filter() 筛选出满足函数func的元素,并返回一个新的数据集
val rdd1=sc.parallelize(List(("a",1),("b",2)))
rdd1.filter(_._2>1).collect //_表示x
rdd1.filter(x=>x._2>1).collect //第二个字段》1
rdd1.filter(x=>x._2>100).collect //删选出第二个字段大于100的
2.reduceByKey() 合并有相同键的值。一个转换操作。返回一个新的RDD
val rdd=sc.parallelize(List(("a",1),("a",2)))
val re_rdd=rdd.reduceByKey((a,b)=>a+b)
re_add.collect
2.4 保存输出文件
1.saveAsTextFiles:以文本形式保存,保存到任何文件系统
2.saveAsObjectFiles:序列化格式
3.saveAsHadoopFiles:以文件形式保存到HDFS上
2.2 文件名前缀 (prefix)&后缀(suffix)

1.将输出的内容保存到hdfs中
lines.saveSaTextFiles("hdfs://le/saveAsTextFile",'txt');
prefix:前缀
suffix:后缀
3.Spark-sql
3.1 case class
1.利用反射机制推断RDD模式 定义一个case class
case class Person(name:String,age:Int)
读取数据源
val data=sc.textFile("/user/wang/people.txt").map(_.split(","))
map转化为DF
val people=data.map(p=>Person(p(0),p(1).trim.toInt)).toDF()
3.2 如何使用join/groupBy
1.groupBy 根据字段进行分组
val userGroupBy=user.groupBy("gender")
2.使用join将两张表连接在一起
val bigdata=sc.textFile("__.txt").map{x=>val line=x.split("\t");(line(0),line(2).toInt)}
val math=sc.textFile("__.txt").map{x=>val line=x.split("\t");(line(0),line(2).toInt)}
val user=student.join(bigdata).join(math)
保存
val user1.repartition(1).saveAsTextFile("地址")
3.3 sql改成dataframe语句 不清楚
4.操作题
1.启动
./start-dfs.sh
启动spark ./spark-shell
启动spark集群 ./spark-all.sh
2.上传文件
hdfs dfs -put /本地文件目录 /上传路径
3.查看目录是否创建成功
hdfs dfs -ls /
4.查看是否上传成功
hdfs dfs -cat /文件
5.创建目录
hdfs dfs -mkdir /test/input
6.删除
删除文件
hdfs dfs -rm /文件目录
删除文件夹
hdfs dfs -rm -r /文件夹目录
7.下载文件到本地
hdfs dfs -get /hdfs路径 /本地路径
hdfs dfs -get
8.提交到集群
./spark-submit --master yarn-cluster --class 程序入口 jar包路径 输入文件路径 输出文件路径
./spark-submit --master yarn-cluster --class demo.spark.WorldCount /opt/word.jar /user/root/words.txt /user/root/word_count
数据库操作
1.启动Hive的metastore
hive --service metastore &
2.登录
mysql -uroot -p
3.创建表
create table student(id int,name string)
4.使用spark.sql()执行sql语句
saprk.sql("show database").show()
DataFrame操作·
1.加载parquet文件为DataFrame 结构化数据创建DataFrame
var dfusers=spark.read.load(/user/users."")
2.json-->dataframe json()
val dfPeople=spark.read.json("josn文件名")
val dfPeople1=spark.read.format("json").load("../data.json")
3.外部数据库创建DF
val jdbcDF=spark.read.format("jdbc").options(
)
jdbcDF.show()
jdbc连接数据库

4.Spark-Streaming

1.监控文件系统
val lines=ssc.textFileStream("home/wang/streaming/data")
2.slice
设置窗口长度为3s,滑动时间间隔为1s
val windowWords=words.window(Seconds(3),Seconds(1))
3.window参数
val windowWords=words.window(Seconds(3),Seconds(1))
4.socket连接
val ssc=new StreamingContext(sc,Seconds(5))
val lines=ssc.socketTextStream("localhost",8888)
5.reduceByKeyAndWindow
val windowWords=pairs.reduceByKeyAndWindow((a;Int,b:Int)=>a+b,Seconds(3),Seconds(1))
8.启动
ssc.start();
ssc.awaitTermination()

每隔10秒钟统计最近60秒的热点热搜词的搜索频率
val lines=ssc.socketTextStream("localhost",8888) //连接输入数据流
val words=lines.flatMap(_.split(" ")) //将数据分割
//设置窗口长度 滑动时间间隔
val windowWords=words.map(x=>x._1).reduceByKeyAndWindow((a:Int,b:Int)=>a+b),Seconds(60),Seconds(10)
2.排序 DStream operation :transfrom
val hottestWords=windowWords.transform(rdd={rdd.sort(_.2,false)})
//取前十打印出来
hottestWords.foreachRDD(_.take(10).foreach(println))
ssc.start()
ssc.awaitTermination() //等待子线程结束
ssc.stop()
网页热度排序 transform
val hottestHtml=htmlCount.transfrom(rdd=>{
val top10=rdd.sortBy(_._2,false).take(10);
sc.makeRDD(top10)
})
5.Spark机器学习
—————————————————————————————————————————————————
下面不用看
5.1.1 查询学生成绩的前五名
1.创建RDD
val bigdata=sc.textFile("") //
val mathdata=sc.textFile("")
2.数据转换:将数据拆分成3列
val m_bigdata=bigdata.map(x=> val line=x.split("\t");(line(0),line(1),line(2).toInt))
val m_mathdata=mathdata.map(x=> val line=x.split("\t");(line(0),line(1),line(2).toInt))
3.按成绩排序
val sort_bigdata=m_bigdata.sortBy(x=>x._3,false,1);
4.取前五个
sort_bigdata.take(5)
5.1.2 输出单科成绩为100的同学ID—对两个RDD进行合并
union():合并RDD--两个RDD元素类型一致
distinct:去重
filter():对每个元素应用函数 保留返回值为true的函数
val f_bigdata=m_bigdata.filter(x=>x._3==100)
val f_mathdata=m_mathdata.filter(x=>x._3==100)
2.提取出id
val bigdata_id=f_bigdata.map(x=>x._1)
val mathdata_id=f_mathdata.map(x=>x._1)
3.合并
val id=bigdata_id.union(mathdata_id)
4.去重
val uid=id.distinct
5.查询
uid.collect
val f_bigdata=m_bigdata.filter(x=>x._3==100)
val f_mathdata=m_mathdata.filter(x=>x._3==100)
val bigdata_id=f_bigdata.map(x=>x._1)
val mathdata_id=f_mathdata.map(x=x._1)
合并
val id=bigdata_id.union(mathdata_id)
val uid=id.distinct
uid.collect
5.1.3 输出每个学生所有成绩之和
合并成绩表
val score=m_bigdata.union(m_math);
2.以学生id为健 ,将成绩转化成RDD
val kv_score=score.map(x._1->x._3)
3.合并具有相同键的值
val total=kv_score.reduceByKey((a,b)=>a+b)
4.查询
total.select
输出每位学生的average-score
val averge=kv_score.reduceByKey((a,b)=>a+b).map(x=>(x._1,x._2/2.0))
将第一个值提取出来 将第二个值除以二
5.1.4 使用join将几个任务的结果连起来
val bigdata=sc.textFile("__.txt").map{x=>val line=x.split("\t");(line(0),line(2).toInt)}
val math=sc.textFile("__.txt").map{x=>val line=x.split("\t");(line(0),line(2).toInt)}
使用将表连接起来
val user=student.join(bigdata).join(math)
val user1.repartition(1).saveAsTextFile("地址")
6.RDD
RDD的转换与操作
6.1.1 filter() 筛选出满足函数func的元素,并返回一个新的数据集
val rdd1=sc.parallelize(List(("a",1),("b",2)))
rdd1.filter(_._2>1).collect //_表示x
rdd1.filter(x=>x._2>1).collect //第二个字段》1
rdd1.filter(x=>x._2>100).collect //删选出第二个字段大于100的
6.1.2 map() 筛选出满足函数func的元素,并返回一个新的数据集
val rdd1=sc.parallelize(List(1,2))
val square=rdd1.map(x=>x*x) //平方操作
6.1.3 reduceByKey() 合并有相同键的值。一个转换操作。返回一个新的RDD
定义一个含有多个相同键的PairRDD,对每个键的值进行求和
val rdd=sc.parallelize(List(("a",1),("a",2)))
val re_rdd=rdd.reduceByKey((a,b)=>a+b)
re_add.collect
6.1.4 reduce()操作:通过函数func(输入两个参数并返回一个参数) 聚合数据集中元素
7.SparK SQL
为什么推出Spark Sql?
var dfusers=spark.read.load("") 1.加载parquet文件为DataFrame
val dfPeople=spark.read.format("json").load("") 2.json-->dataframe json()
val dfPeople1=spark.read.json()
8.2 常用操作
printSchema、select、filter、groupBy、sort
1.printSchema 打印数据模式
movies.printSchema
2.select 获取指定字段
val userSelect=user.select("userId","gender")
3. filter 和where的使用方法一样 筛选符合条件的数据
val userFileter=user.filter("gender="s" and age=18")
4.groupBy 根据字段进行分组
val userGroupBy=user.groupBy("gender")
5.sort 降序desc 升序asc
val userSort=user.sort(asc("userId"))
val userSort=user.sort($"userId".asc)
6.show
show()/show(true):只显示前20条数据
show(false):全部显示
8.3 RDD创建DataFrame
1.利用反射机制推断RDD模式 定义一个case class
case class Person(name:String,age:Int)
读取数据源
val data=sc.textFile("/user/wang/people.txt").map(_.split(","))
map转化为DF
val people=data.map(p=>Person(p(0),p(1).trim.toInt)).toDF()
8.5 DataFrame查看数据
1.准备数据
(1)上传到hdfs
hdfs dfs -put /文件路径 /hdfs路径
(2)加载为RDD
val data=sc.textFile(dir).map(_.split("::"))
val data=sc.textFile(dir).map(_.split("::"))
(3)RDD-->DF
case class=Movie(movieID:Int,titile:String,Genres:String)
val movie=data.map(m=>Movie(m(0).trim.toInt,m(1),m(2))).toDF()

movies.collect() //将DataFrame中的所有数据都获取到,并返回一个Array对象
movie.collectAsList() // 获取所有数据到List
RDD-》DataFrame
./spark-submit --master yarn-cluster --class 程序入口 jar包路径 输入文件路径 输出文件路径
例:./spark-submit --master yarn-cluster --class demo.spark.WorldCount /opt/word.jar /user/root/words.txt /user/root/word_count
持久化
rdd.cache()
分区
rdd.partitionBy()
9 SparkStreaming
9.1 数据的两种处理模型
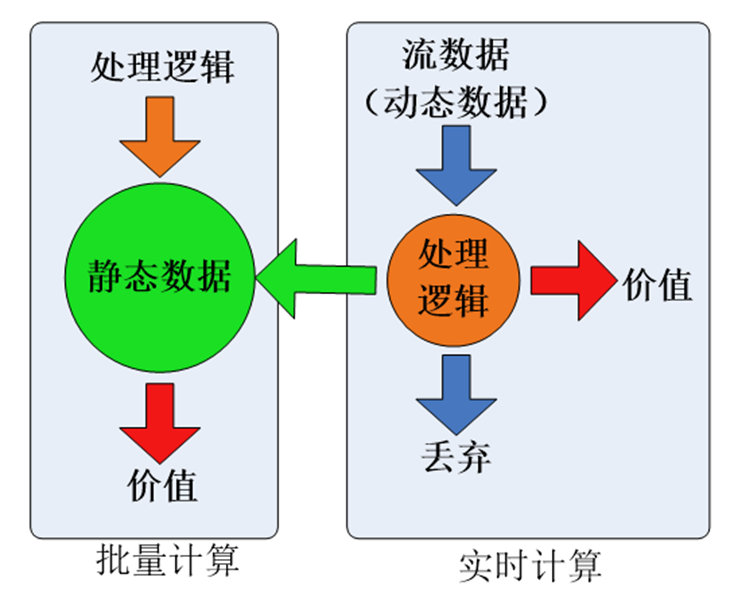
9.2 SparkSteaming的设计
将当前长度为3的时间窗口中的所有数据元素根据key进行 合并。统计前三秒不同单词出现的次数
irs
val ssc=new StreamingContest(sc.Seconds(1))
val lines=ssc.socketTextStream("localhost",8888)
val words=lines.flatMap(_.split(" "))
val pairs=wprds.map(word=>(word,1))
val windowWords=pairs.reduceByKeyAndWindow((a:int,b:int)=>a+b,Seconds(3),Seconds(1))
windowWords.print()
ssc.start()
开启监听窗口
nc -l 8888
设置窗口长度为3s,滑动时间间隔为1s
val windowWords=words.window(Seconds(3),Seconds(1))
2.DStream输出操作
2.1 保存DStream中的内容到文件
1.saveAsTextFiles:以文本形式保存,保存到任何文件系统
2.saveAsObjectFiles:序列化格式
3.saveAsHadoopFiles:以文件形式保存到HDFS上
2.2 文件名前缀 (prefix)&后缀(suffix)
1.将输出的内容保存到hdfs中
lines.saveSaTextFiles("hdfs://le/saveAsTextFile",'txt');
prefix:前缀
suffix:后缀
网站热词排名




nc -l 8888
以socket连接作为数据源读取数据
val ssc=new StreamingContext(sc,Seconds(5))
val lins=ssc.socketTextStream("localhost",8888) //以socket作为连接读取数据
val words=lines.flatMap(_.split(""))
val wordCount=words.map(x=>x._1).reduceByKey(_+_)
wordsCount.print()
将热度最高的10个网页更新到热门博文板块
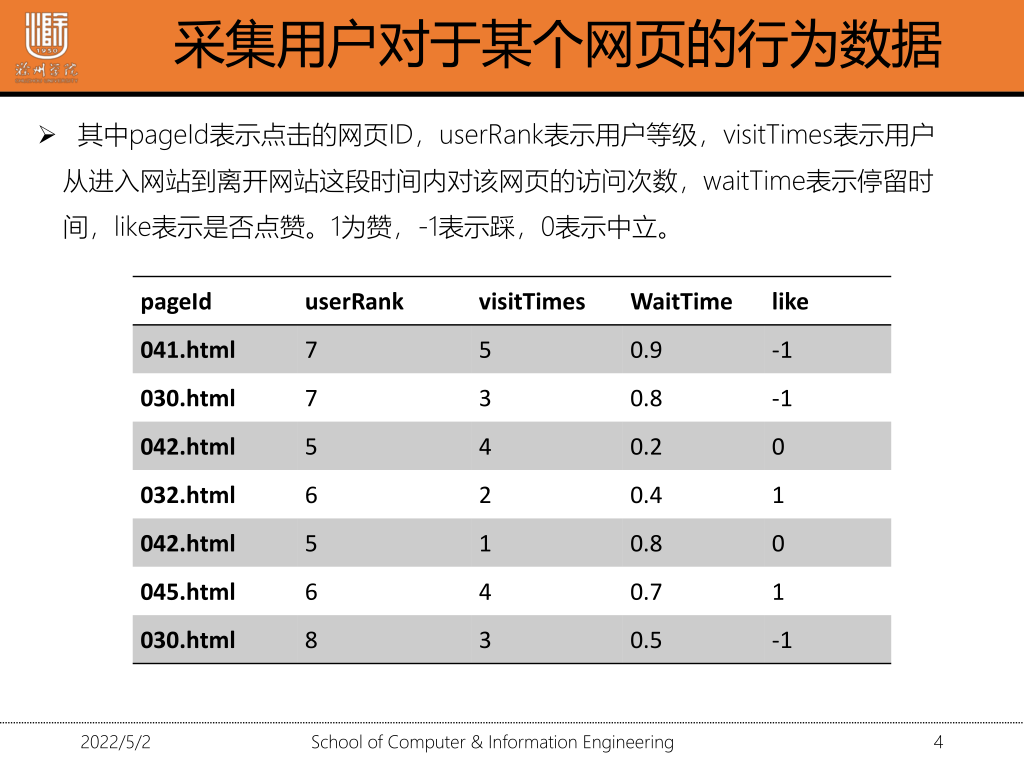
在mysql中设计一张表
| 列名 | 解释 | 备注 |
|---|---|---|
| ranking | 热度排名 | 主键 |
| htmlID | 网页ID | |
| pageHeat | 网页热度 |
create table top_web_page(ranking int,htmlID varchar(30),pageHeat double)
create table table_name(key keyType,key1 keyType)
1.采集数据
2.创建StreamingContext对象并监控streaming/data日志文件目录
val sc=new SparkConf().setAppName("pagehot")
val ssc=new StreamingContext(sc,Seconds(5))
val lines=ssc.textFileStream("home/wang/streaming/data")
3.计算网页热度
分隔数据,生成以网页ID为键,热度为值的键值对数据
val html=lines.map{line=>val words=line.split(",");(words(0),0.1*words(1).toInt+0.9*words(2).toInt+0.4*words(3).toDouble+words(4).toInt}
计算每个网页的热度综合
val htmlCount=html.reduceByKeyAndWindow((v1:Double,v2:Double)=>v1+v2,Seconds(60),Seconds(10))
4.按照网页的热度总和降序排序 转换为RDD
val hottestHtml=htmlCount.transform(rdd=>{
val top10=rdd.sortBy(_._2,false).take(10);
sc.makeRDD(top10);
})
val hottestHtml=htmlCount.transform(rdd=>{
val top10=rdd.sortBy(_._2,false).take(10);
sc.makeRDD(top10);
})

启动Spark Streaming
select * from top_web_page //查询数据


若有收获,就点个赞吧
0 人点赞
