排序方法的分类

存储介质分类
内部排序:数据量不大,数据在内存中就可以进行交换,无需内外存交替
外部排序:数据量较大,数据在外存 (文件排序);使用外部排序时,要将数据分批调入内存来排序,中间结果还要放入外存。
比较器个数分类
- 串行排序:单处理机(同一时刻比较一对元素)
- 并行排序:多处理机(同一时刻比较多对元素)
主要操作分类
- 比较排序:用比较的方法排序,常见的有插入排序,交换排序,选择排序和归并排序
- 基数排序:不比较元素的大小,仅仅根据元素本身的取值确定其有序的位置
按是否需要辅助空间分类
- 原地排序:不需要辅助空间,即额外的空间复杂度为O(1)
- 非原地排序:需要辅助空间
按稳定性分类
- 稳定排序:能够使任何数值相等的元素,排序后相对次序不变 (相对次序只有前后之分)
- 非稳定排序:相反呗
PS:排序的稳定性只对结构类型数据进行排序有意义

排序方法是否稳定不是衡量排序算法优劣的指标
按自然性分类
- 自然排序:输入数据越有序,排序的速度越快的排序方法
- 非自然排序:相反嗷
插入排序
每一步都将一个待排序的对象,按其关键码大小,插入到已经排好序的一组对象中的适当位置上,直到所有待排序对象插入完成

即边插入边排序,保证子序列中随时都是排好序的
操作:
- 在有序序列中插入一个元素,仍然保持序列有序,序列长度增加
- 一开始 array[0]可以认为是长度为1的有序子序列。然后将array[1] 至 array[n-1] 插入到有序子序列中
- 在插入array[i] 之前,数组array的前半段array[0]~array[i-1]是有序序列,后半段 array[i]~array[n-1] 是未插入的无序段
- 插入 array[i] 仍要使得 array[0]~array[i-1] 有序,也就是要为 a[i] 找到有序位置 j ( 0<=j<=i ) 将 array[i] 插入到 array[j]的位置上,维持有序
根据找有序位置 (即插入位置) j 的方法的不同,可以将插入排序分为以下几类:
- 顺序法定位插入位置:直接插入排序
- 二分法定位插入位置:折半插入排序
- 缩小增量多遍插入排序:希尔排序
直接插入排序
顺序查找法直接查找
void insert(sqList* list, int ele){for (int i = 1; i <= list->length+1; i++){if (ele <= list->arr[i]){for (int j = list->length; j >= i; j--){list->arr[j + 1] = list->arr[j];}list->arr[i] = ele;list->length++;break;}//尾部else if (i == list->length + 1){list->arr[i] = ele;list->length++;break;}}}
也可以使用带有哨兵的顺序查找,注意需要空出array[0]来设置为哨兵
void insert2(sqList* list, int ele){for (int i = 1; i <= list->length + 1; i++){list->arr[0] = ele;int j = list->length;while (list->arr[0] < list->arr[j]){list->arr[j + 1] = list->arr[j];j--;}list->arr[j+1] = ele;list->length++;break;}}
不是很喜欢这种情况下的哨兵,因为可能前面很多元素都比待插入的元素大,这样会造成很多次的额外移动
算法分析:
记录序列元素为待插入元素
最好:


最坏:


平均:

最好情况下:O(n)
最坏情况下:O(n)
平均情况下是最坏情况的一半,也是 O(n)
折半插入排序
从已经排好序的数组中查找插入位置,其实就是在不断二分中找到待插入元素应该存在的位置,即 mid
void binaryInsert(sqList* list, int ele){for (int i = 1; i <= list->length; i++){//right为有序序列的最大下标int right = list->length+1; //规定上限int left = 1; //规定下限//折半查找插入位置, 插入位置即mid上,因为mid位置总是待插入元素应该存在的位置int mid;while (left <= right){mid = (left + right) / 2;if (ele < list->arr[mid]) right = mid - 1;else left = mid + 1;}for (int j = list->length; j >= mid; j--){list->arr[j + 1] = list->arr[j];}list->arr[mid] = ele;list->length++;break;}}
比较次数:

移动次数:
折半插入排序的对象移动次数与直接插入排序相同
折半插入排序与直接插入排序相比:
- 减少了比较次数,没有减少移动次数
- 平均性能优于直接插入排序
希尔排序
基本思想:将相距某个增量的记录组成一个子序列,然后在子序列内分别进行直接插入排序
所以希尔排序的特点是:缩小增量和多遍插入


第一趟:
每5个间隔分为一组

交换后

上图中颜色相同的为一组
至此,第一趟排序完成,修改增量,开始第二趟排序
第二趟:

再次对颜色相同的进行排序,得到第二趟排序结果

再次修改增量
第三趟:

希尔排序思路:
- 定义增量序列D:D > D > … >D = 1 (增量序列的最后一个值必须是1)
- 对每个 D 进行 D - 间隔 的插入排序 ( k = n, n-1, … 1)
希尔排序特点:
- 一次移动的位置较大,跳跃式地接近排序后的最终位置
- 最后一次只需要少量移动
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
void shellSort(sqList* list){int add = list->length;int i;int k = 0;do{//子表:根据增量序列在表中划分的不同块add = add / 3 + 1; //增量序列,逐渐减小增量,缩小范围k++;for (i = add+1; i <= list->length; i++){//如果后面子表的对应位置上元素小于前面的子表的对应位置元素,则交换元素if (list->arr[i] < list->arr[i - add]){//存储较小的元素,做中间变量,用于交换list->arr[0] = list->arr[i];int j;//i - add,就是add前的子表中的对应下标//下面这段代码其实就是在交换两个元素//for循环是在遍历前面全部的子表中对应位置的元素进行比较,寻找插入位置for (j = i - add; j > 0 && list->arr[0] < list->arr[j]; j -= add){//j + add是j对应的是下一个增量子表中对应位置的元素,即较大的那个元素list->arr[j + add] = list->arr[j];}list->arr[j + add] = list->arr[0];}printf("第%d趟:", k);for (int i = 1; i <= list->length; i++){printf("%d-->", list->arr[i]);}putchar('\n');}}while (add > 1);}
希尔排序的算法效率与增量序列的取值有关:
Hibbard增量序列
D = 2 —— 相邻元素互质
最坏情况: T = O(n)
猜想: T = O(n)
Sedgewick增量序列
{1 , 5, 19, 41, 109, …} —— 94 - 92 +1 或
4 - 3*2 +1猜想:T = O(n) T = O(n)
增量序列的最后一个增量值必须为1
不适宜在链式存储结构上实现
交换排序
两两比较,如果两者顺序相反则交换,直到所有记录都排好序为止
常见的有:
- 冒泡排序 O(n)
- 快速排序 O(nlogn)
冒泡排序
每趟两两比较,按照规则进行交换
这里不再赘述算法
基于原有的冒泡算法,可以增设一个flag,如果在某一趟没有发生交换,则说明已经有序,不再进行交换

最好情况 (顺序与规则相同)
- 比较次数: n-1,只需两两比较一遍即可
- 移动次数:0
最坏情况 (顺序与规则完全相反)
比较次数:

移动次数:

这个3次指的是交换值时的三条语句
快速排序*
基本思路:
- 从需要排序的数据中任取一个元素为中心作为枢轴
- 所有比枢轴小的元素一律前放,比枢轴==大的元素一律后==放,形成左右两个子表 (缩小规模)
- 对各子表重新选择枢轴,并重复步骤2,直到每个子表中的元素只剩一个
//将枢轴放到理应存在的位置,使得其前面的元素都小于他,后面的元素都大于他int findCenter(sqList* list, int low, int high){list->arr[0] = list->arr[low]; //取第一位作为枢轴,存入0号位while (low < high){//循环找到枢轴后比枢轴小的元素,并放到前面来while (low < high && list->arr[0] <= list->arr[high]){high--;}//因为对low位置的做了备份存到0号位,因此可以直接赋值list->arr[low] = list->arr[high]; //将比枢轴小的交换到低端//循环找到枢轴前比枢轴大的元素,并放到后面来while (low < high && list->arr[0] >= list->arr[low]){low++;}list->arr[high] = list->arr[low]; //将比枢轴大的交换到高端}list->arr[low] = list->arr[0]; //将枢轴放至应在位置return low;}//递归子序列 [low .... high]void quickSort(sqList* list, int low, int high){int center = 0; //枢轴//递归整张表if(low < high){center = findCenter(list, low, high); //获得枢轴应在位置,并构成以枢轴大小为区分的左小右大子表quickSort(list, center + 1, high); //递归排序右子表quickSort(list, low, center - 1); //递归排序左子表}}
- 每次子表的形成是采用从两头向中间交替式逼近的
- 每趟中对子表的操作相同,采用递归
算法分析:
时间复杂度
- 平均计算时间:O(nlogn)
- quickSort(): O(logn)
- findCenter(): O(n)
空间复杂度
- 平均情况:O(logn) 的栈空间
- 最坏情况:O(n)

因此,枢轴元素的选取是影响时间性能的关键;输入数据次序越乱,所选枢纽元素值得随机性越好,排序速度越快;
可以用以下方法对上述快排进行优化:
- 优化选取枢轴:三数取中法 —>> 取三个关键字先进行排序,将中间数作为枢轴,一般是取左端,右端和中间三个数
- 优化递归操作为尾递归
选择排序
简单选择排序
基本思路:在待排序的数据中选出最大 (小)的元素放在其最终位置
步骤:
- 首先通过 n-1 次关键字比较,从 n 个记录中找出关键字最小的记录,将它与第一个记录交换
- 再通过 n-2 次,从剩余的 n-1 个记录 (剩下的未有序序列) 中找出关键字第二小的记录,将它与第二个记录交换
- 重复上述操作,进行 n-1 趟排序后结束
算法不再赘述,贴张图

k != i 说明 i 所指元素不是当前未有序序列的最小元素,k指向的才是,这时才交换
时间复杂度:
记录的移动次数
- 最好:0
- 最坏:3(n-1) 3为交换值算法的三步
- 比较次数:O(n)
堆排序*
堆的定义:若 n 个元素组成的序列 {a,a … a} 满足

则分别称该序列 {a, a … a} 位 小根堆(根小) 或 大根堆(根大)
所以堆其实是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于 (大于) 它的孩子结点
堆排序算法:利用堆进行排序的方法
堆排序算法基本思路:
- 将待排序的序列构造成一个大根堆(也可以是小根堆)。此时整个序列的最大值就是堆顶的根结点。
- 将它与堆数组的末尾元素交换,此时末尾元素就是最大值
- 然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中第二大的值。反复执行
实现堆排序的两个问题:
- 由无序序列创建堆 ——> 堆建立
- 输出堆顶元素后如何调整剩余元素为一个新的堆 ——> 堆调整
堆建立:
所有序号小于 list->length / 2 的结点都是非叶子结点,因此需要成为堆 (分治) 后完全二叉树整个才能成为一个堆基本思路:从下往上,从左至右,将每个非叶子结点当做根结点,将其和其子树调整为大根堆,形成堆 (贪心)
堆调整:
基本思路和堆建立差不多,只是每次将一个元素调整到堆底后需要再次调整。
堆建立和调整用到了贪心思想,本质是选取每层中最大的那个元素上浮一层,然后堆顶和堆底交换,进而有序
//创建初始大根堆和后续调整堆//调整 list->arr[parent ... length] 成为一个大顶堆void heap(sqList* list, int root, int length){//保存根结点副本int temp = list->arr[root];//沿元素较大的孩子向下查找,一旦某个根结点的右孩子大于左孩子,左孩子的所有子树都小于右孩子for (int j = 2 * root; j < length; j*=2){//贪心思想,本质是选取每层中最大的那个替换到根结点if (j < length && list->arr[j] < list->arr[j + 1]){j++; //记录root及其两个孩子中元素较大的那个,用来替换根结点}//如果根结点(在堆调整中指堆顶,在堆初始中指当前传入的根结点)比向下查找的所有元素都大,则不替换//因为是从下往上建立的大根堆,因此根结点一旦比起孩子中最大的那个还大,//就一定是以其为根结点这棵树中最大的结点if (temp >= list->arr[j]){break;}//在堆调整中,用于将堆顶(arr[1])尽可能向下放,将最大的元素放到堆顶list->arr[root] = list->arr[j]; //将较大的替换为根结点root = j; //下寻找到比根结点还小的结点;如果没找到则根结点就是最小的,循环完后放在最底下即可}list->arr[root] = temp; //替换根结点值,构建堆的时候用来把根结点放在最底下(这时的根结点一定是当前最小的)//;调整堆时都是让最大元素到堆顶}void heapSort(sqList* list){// i =list->length/2的原因:从list->length/2开始至1,在完全二叉树中他们都是有孩子的结点for (int i = list->length / 2; i > 0; i--){//建立大根堆,其实就是从下往上,将每个非叶子结点当做根结点,将其和其子树调整为大顶堆//这样在进行堆调整的时候heap(list, i, list->length);}//每循环一次说明从大根堆取出了最大值,即根结点for (int i = list->length; i > 0; i--){//交换堆顶(1号位即堆顶)最大元素到堆底,表示出堆,[i ... list->length] 表示已经排好序的序列list->arr[0] = list->arr[i];list->arr[i] = list->arr[1];list->arr[1] = list->arr[0];//list->arr[1 ... i-1] 重新调整为最大堆heap(list, 1, i - 1); //堆调整,i-1相当于最顶上元素已经排好了}}
性能分析:
- 初始化: < O(n)
- 排序阶段:一次堆调整时间 < O(n);n-1次堆调整为 O(nlogn)
T(n) = O(n) + O(nlogn) = O(nlogn)
归并排序*
归并排序是一个用到了分治法的典型算法,在每一层中递归中都有以下过程
- 分割:将n个元素分成个含 n/2 个元素的子序列
- 解决:用合并排序法对两个子序列递归的排序
- 归并:合并两个已排序的子序列以得到排序结果
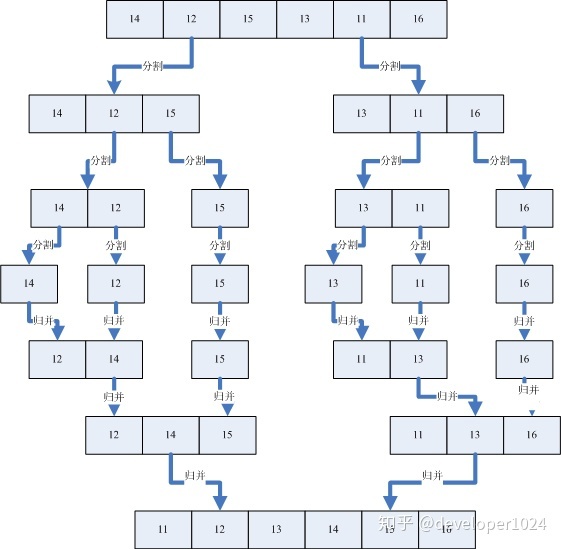
Java代码如下:
package 归并排序;import java.util.Arrays;/*** @Author: antigenMHC* @Date: 2020/4/16 10:27* @Version: 1.0**/public class 归并 {public static void main(String[] args) {int[] arr = new int[]{2,4,7,1,4,7,3,8};mergeSort(arr);System.out.println(Arrays.toString(arr));}static void mergeSort(int[] list){int[] tmp = new int[list.length];mSort(list, tmp, 0, list.length-1);}static void mSort(int[] list, int[] tmp, int left, int right){if(left<right){int mid = (left+right)/2;//左序列排序mSort(list, tmp, left, mid);//右序列排序,mid+1保证了分段mSort(list, tmp, mid+1, right);//归并mergeS(list, tmp, mid, left, right);}}static void mergeS(int[] list, int[] tmp, int mid, int left, int right){//左序列指针int leftPoint = left;//右序列指针int rightPoint = mid+1;//临时数组指针int tmpPoint = 0;while(leftPoint<=mid && rightPoint<=right){//取出较小的元素放到tmp中,然后朝右移动,比较下一个元素if(list[leftPoint] <= list[rightPoint]){tmp[tmpPoint++] = list[leftPoint++];}else{tmp[tmpPoint++] = list[rightPoint++];}}//如果左序列有剩余,则添加到临时数组while(leftPoint<=mid){tmp[tmpPoint++] = list[leftPoint++];}//如果右序列有剩余,则添加到临时数组while(rightPoint<=right){tmp[tmpPoint++] = list[rightPoint++];}//临时数组内容赋值到原数组上for (int i = 0; left <= right;) {list[left++] = tmp[i++];}}}

若有收获,就点个赞吧
0 人点赞
