什么是分词器?
分词的意思就是把一段文字分成一个个的关键字,我们在搜索的时候会把自己的信息进行分词,会把数据库中的数据进行分词,然后进行一个匹配操作。
例如,我搜索”奥特曼打小怪兽“,在搜索结果中你可能看到只包含”奥特曼“的信息,也有可能看到只包含”小怪兽”的信息,这就是程序对我们的搜索信息进行了分词。
而默认的中文分词器是将每一个字分成一个词,例如:”奥特曼“分解成”奥“”特“”曼“。这种粒度的分词显然是不太方便的,所以在此我们使用ik分词器插件。
ik分词器提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度切分。
安装ik分词器
1、下载
2、将压缩包解压到ElsticSearch的插件包中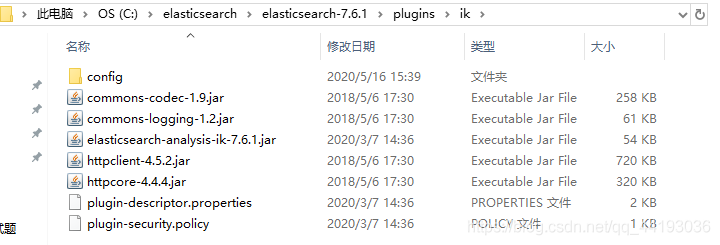
3、重启ElasticSearch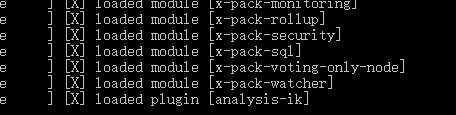
重启可以在日志中观察到ik分词器插件被加载。
4、使用ElasticSearch的命令查看插件是否安装成功
**
在ElasticSearch的bin目录中打开cmd窗口,输入命令elasticsearch-plugin list即可查看安装的插件列表:

使用Kibana测试
ik_smart为最少切分(不会有重复的)
GET _analyze{"analyzer": "ik_smart","text": "中国"}
分词效果:
ik_max_word为最细粒度切分。
分词器会根据语句中的词语进行分割,但是他们怎么认使什么字连起来是一个词呢?这是因为在分词器的内部有一个自己的字典,可以识别常用的正常词语,当我们输入一个人名或者自己捏造的词语的时候就无法达到想要的效果,例如:
发现问题狂神说被拆开了
我们就需要给ik分词器的词典进行自定义。
自定义ik分词器词典信息
我们打开ik分词器的配置文件,发现可以在配置文件中自定义词典配置:
所以,我们先需要创建一个自己的词典:
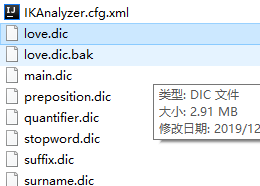
如图,自定义了一个love.dic词典,并在其中保存了梅雪这个词条,然后将这个词典配置到xml节点中即可。
配置完成之后,重启es,查看效果: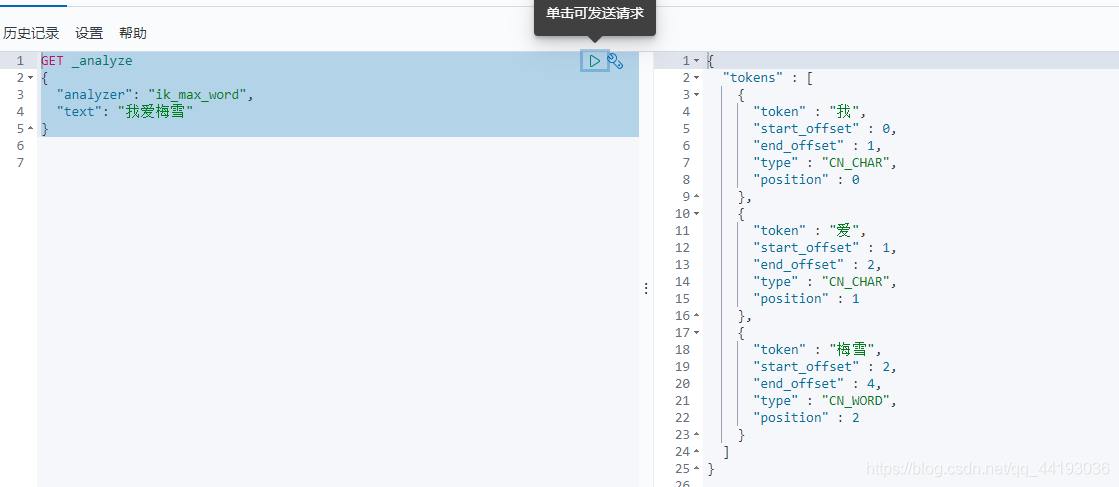
自定义词典成功!
注意:自定义词典的文件编码格式必须是UTF-8,不然的话会无效。

若有收获,就点个赞吧
0 人点赞
