爬取目标:豆瓣网址:https://movie.douban.com/top250
1.爬虫知识
爬虫是一种按照规则,自动爬取互联网信息的程序或脚本,根据用户需求抓取相关网页并分析得到相关资源
爬取内容:
图片,视频,浏览器访问的数据等
爬取本质:
模拟浏览器打开网页,获取需要的数据

2.爬虫流程
2.1准备工作
查看浏览器访问的内容进行分析,对编程基础有一定的规范
2.2获取数据
通过http向网站发起请求,如果响应200成功,会得到一个Response的页面
2.3解析内容
得到的资源内容可能是html,json内容,可以用页面解析库,正则表达式等进行资源解析
2.4保存数据
保存数据文本,也可以保存到数据库,或者是特定的格式
3.爬取豆瓣电影案例
3.1准备工作
豆瓣网址:https://movie.douban.com/top250
3.1.1网址内容规律: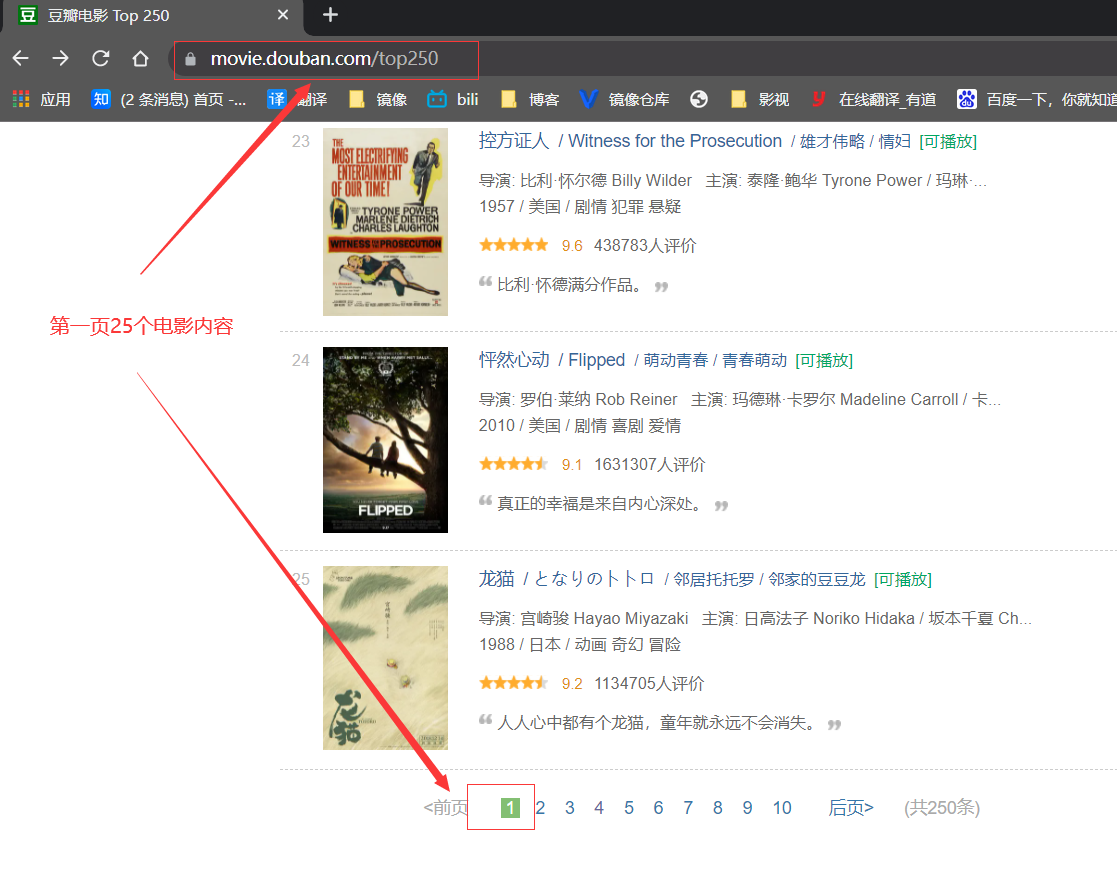
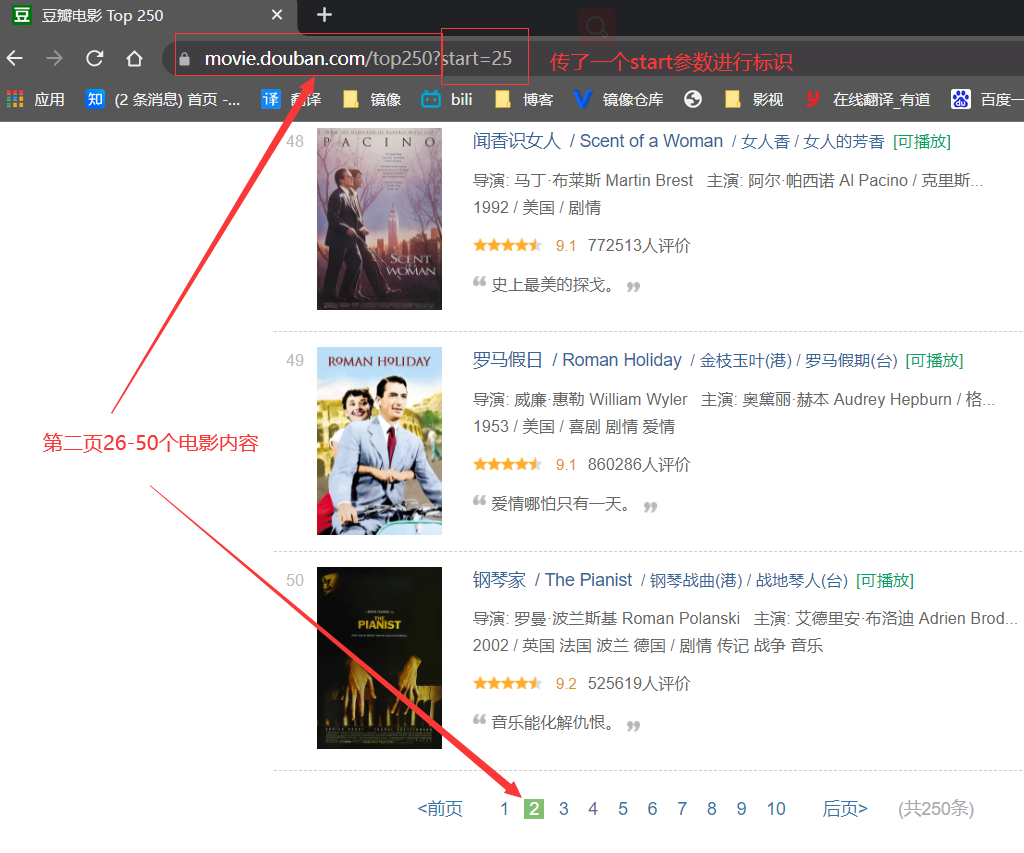 3.1.2分析页面
3.1.2分析页面
F12进行检查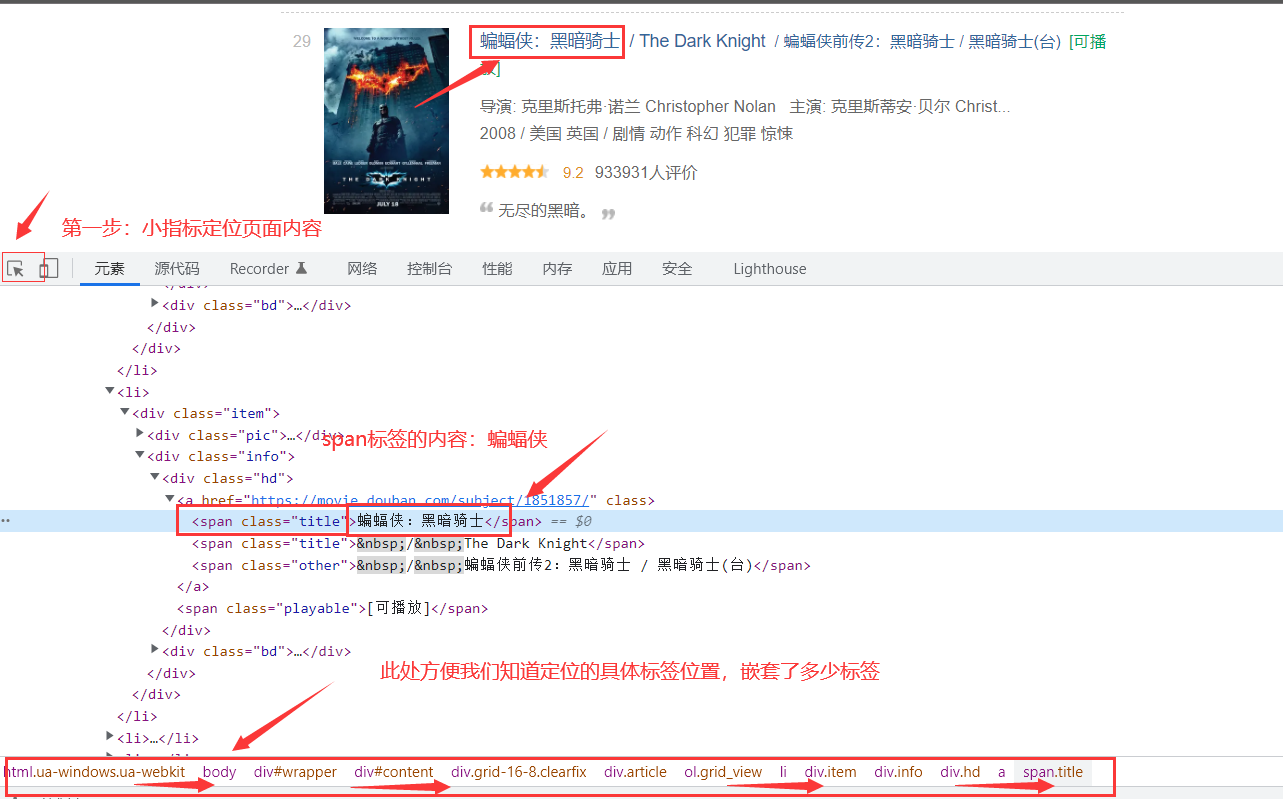
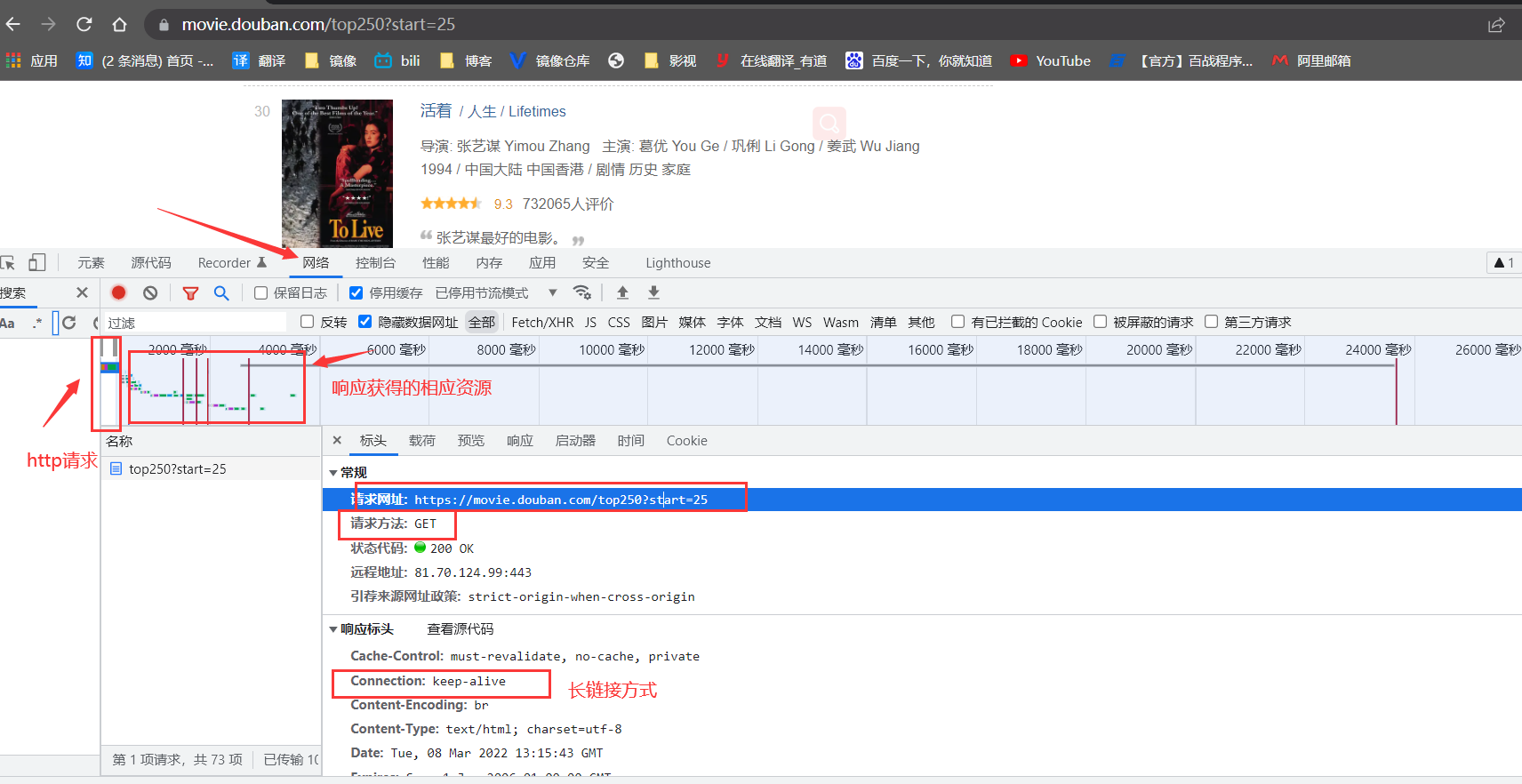

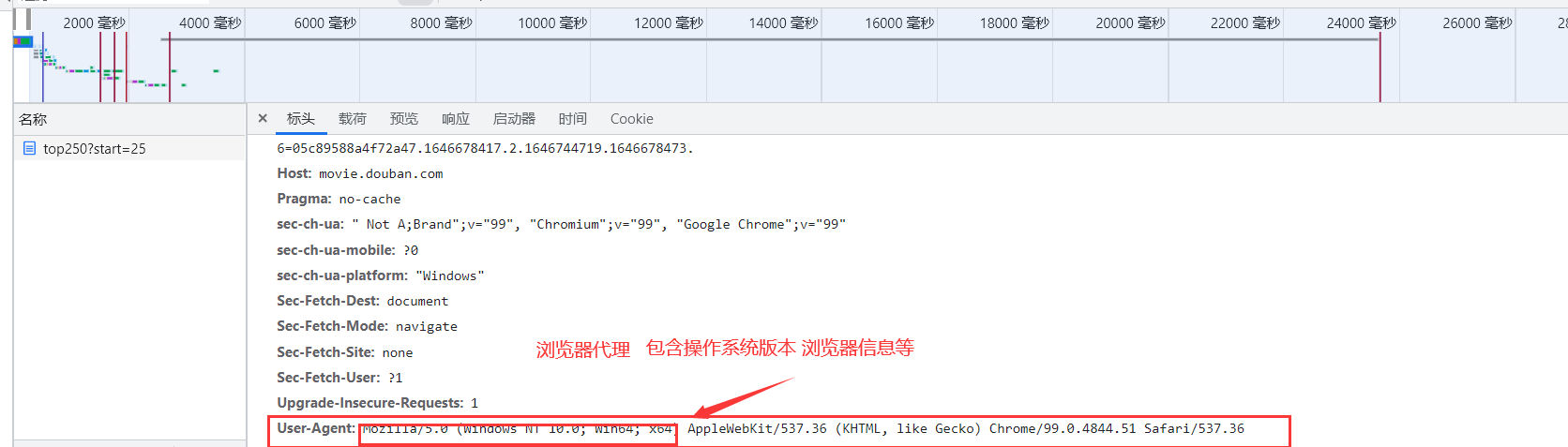
我们浏览器发送的请求是通过七层模型进行层层封装解封装(headers就是包含的请求内容),浏览器返回的内容是Response处界面内容进行页面呈现
3.1.3编码规范
#python开头加入,方便中文代码的书写#coding=utf-8 或 -*- coding:utf-8 -*-#函数实现相关功能的代码,提高可读重复率def x():x#python加入main函数用于测试程序if __name__ == "__main__":
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:38
#@Author : clq
#@file : spider.py
#@Software : PyCharm Community Edition
if __name__ == "__main__": #程序执行时,调用主函数,统一流程
3.1.4导入模块
模块(module):具有某个特定的功能 函数(function):将多个模块组合成的集合 from:引入包 import:导入模块
我们会用到很多模块,比如: 系统模块:sys 第三方模块:bs4 (网页解析.获取数据) re (正则表达式,文字匹配) urllib(制定url,获取网络数据) xlwt(excel方面操作) sqlite3(进行sqlite数据库操作)
下载第三方模块:
file——>settings——->project doban(项目)—->+(搜索第三方模块名下载)
自定义模块实例: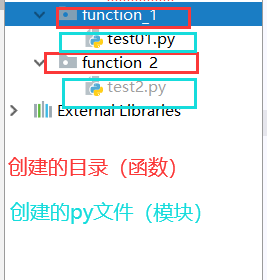
#test01代码
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:54
#@Author : clq
#@file : test01.py
#@Software : PyCharm Community Edition
def add(a,b,c):
return a*b*c
#test02代码(进行函数模块调用)
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:55
#@Author : clq
#@file : test2.py
#@Software : PyCharm Community Edition
from function_1 import test01
print(test01.add(10,10,10))
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:38
#@Author : clq
#@file : spider.py
#@Software : PyCharm Community Edition
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import sqlite3
if __name__ == "__main__":
3.2获取数据
3.2.1爬虫整个流程代码编写
大致流程:1.爬取网址(封装),2.解析数据(通常在循环内),3.保存数据 细致化方便阅读复用:一个流程对于一个函数实现功能
获取数据之前,我们先来学习一下必知内容~~
[urlib2库实例解析](针对于各种数据类型的请求)
模拟请求响应的网址:http://httpbin.org/ response的属性:status(状态)read(读)getheaders(属性)
代码状态418:爬虫请求被识破了
模拟get请求
import urllib.request
import urllib.response
response = urllib.request.urlopen("http://httpbin.org/get")
print(response.read().decode("utf-8"))
get请求获得响应的数据
{
"args": {},
"headers": {
"Accept-Encoding": "identity",
"Host": "httpbin.org",
"User-Agent": "Python-urllib/3.8",
"X-Amzn-Trace-Id": "Root=1-622af0c1-1ed520de3c920b4406bfe1bb"
},
"origin": "116.76.179.172",
"url": "http://httpbin.org/get"
}
模拟post请求
import urllib.request
import urllib.parse
data = bytes(urllib.parse.urlencode({"hello":"python"}),encoding="utf-8")
response = urllib.request.urlopen("http://httpbin.org/post",data=data)
print(response.read().decode("utf-8"))
GET请求获取的信息与httpbin网址信息对比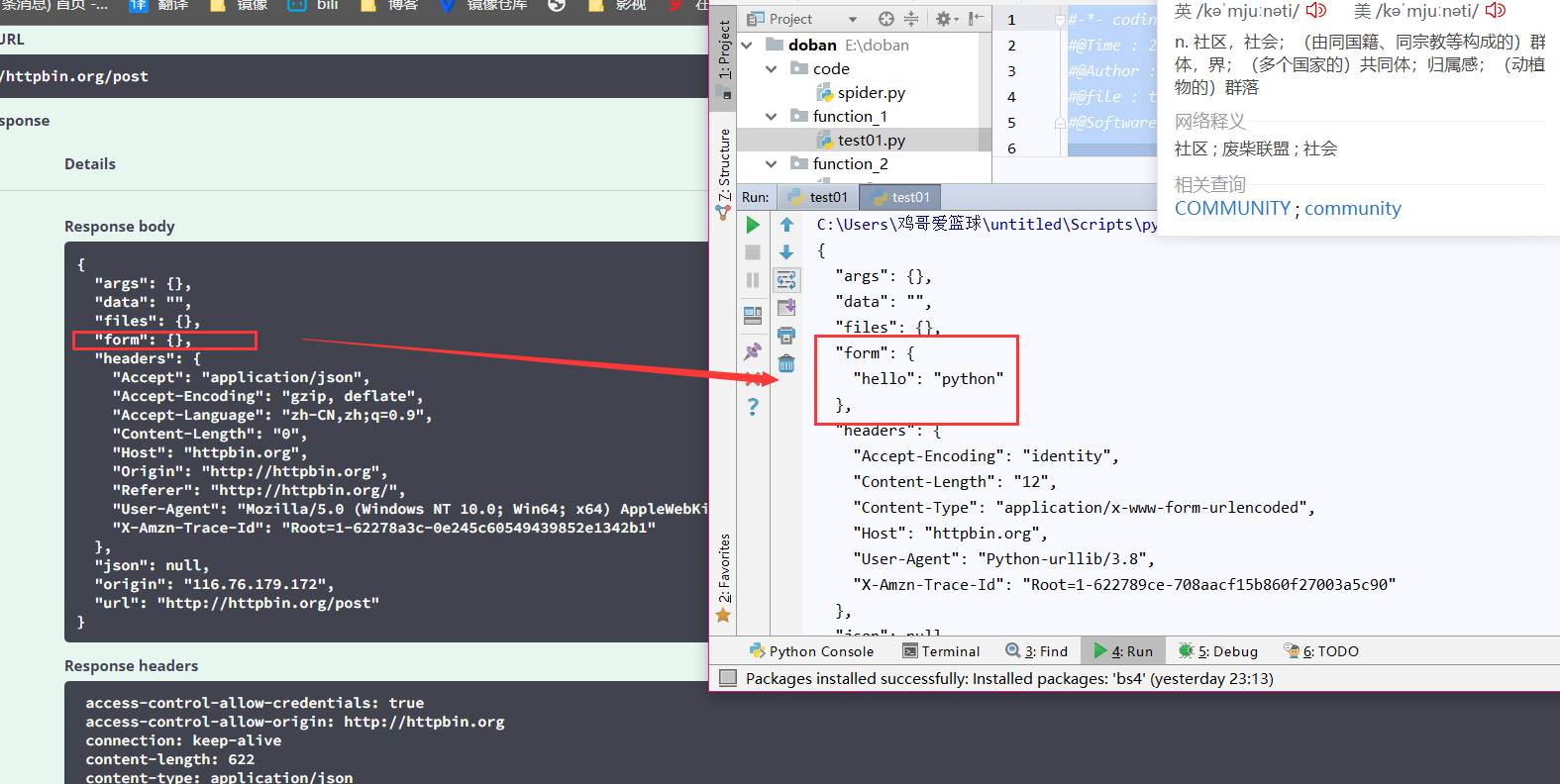
解决请求超时
请求数据难免会出现超时情况,因此要用到异常处理,跳过报错
import urllib.request
import urllib.response
try:
response = urllib.request.urlopen("http://httpbin.org/get",timeout=0.2) #超过0.2秒会出现异常报错
print(response.read().decode("utf-8"))
except urllib.error.URLError as info: #捕获该异常
print("request time error")
伪装爬虫请求
#导入相应模块
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import urllib.parse
import xlwt
import sqlite3
#目标网址
url = "http://httpbin.org/post"
#浏览器封装请求
headres = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
}
#请求携带的字节
data = bytes(urllib.parse.urlencode({"name":"test"},{"oppo":"7000"}),encoding='utf-8')
#将封装的数据url等封装成req变量
req = urllib.request.Request(url=url,data=data,headers=headres,method="POST")
#接受req变量进行网址请求
response = urllib.request.urlopen(req)
#打印阅读请求数据内容
print(response.read().decode('utf-8'))
HTML解析,并获得相应数据
BeautifulSoup4将复杂的html解析成一个有条理的结构 结构分为: Tag NavigableString BeautifulSoup Comment
提取有用的数据信息
bs.find_all:选定所有内容(重要)
css选择器:(重要) 如: test = bs.select(‘title’) #标签查找 test = bs.select(‘.mnav’) #类名查找 test = bs.select(“#id”) #id查找 test = bs.select(“a[class=’x’]”) #属性查找 test = bs.select(“html > head”) #父子标签方式查找 test = bs.select(“.mnav ~ .bri”) #兄弟标签方式查找 print(test[0].get_text())
#html内容
<!DOCTYPE html>
<html lang="en">
<title>输入用户的信息</title>
</html>
#py文件内容
from bs4 import BeautifulSoup
file = open("./baidu.html","rb")
html = file.read().decode('utf-8')
file.close()
bs = BeautifulSoup(html,"html.parser")
#使用bs查找title开头的内容
print(bs.title) #显示输出:<title>输入用户的信息</title>
print(type(bs.title)) #显示输出:<class 'bs4.element.Tag'>
print(bs.title.string) #显示输出:输入用户的信息
print(type(bs.title.string)) #显示输出:<class 'bs4.element.NavigableString'>
print(bs.内容.attrs) #以字典方式显示所有属性
-----------------以上是针对标签字符串进行搜索(bs.常用)-------------------------------
---------------------文档搜索(bs.find_all最常用)-----------------------------------
#html内容
<html lang="en">
<title>输入用户的信息</title>
<p>电影</p>
<h1>小说</h1>
</html>
#py文件内容
from bs4 import BeautifulSoup
file = open("./baidu.html","rb")
html = file.read()
file.close()
bs = BeautifulSoup(html,"html.parser")
search01 = bs.find_all("h1")
search02 = bs.find_all("p")
print(search01) #显示输出:[<h1>小说</h1>]
print(search02) #显示输出:[<p>电影</p>]
#传入一个函数方法,指定搜索(了解)
def name_exists(tag):
return tag.has_attr("name")
test = bs.find_all(name_exists)
print(test)
---------------------kwargs参数搜索-----------------------------------
test = bs.find_all(id="p")
---------------------正则搜索-----------------------------------------
test = bs.find_all(text = re.compile("\d")) #查找所有包含数字的内容
---------------------指定范围搜索-----------------------------------
test = bs.find_all("head",limit=2) #搜索head内容,限定最多查2个
RE正则表达式
正则表达式简单通俗来说就是查找字符串的标准
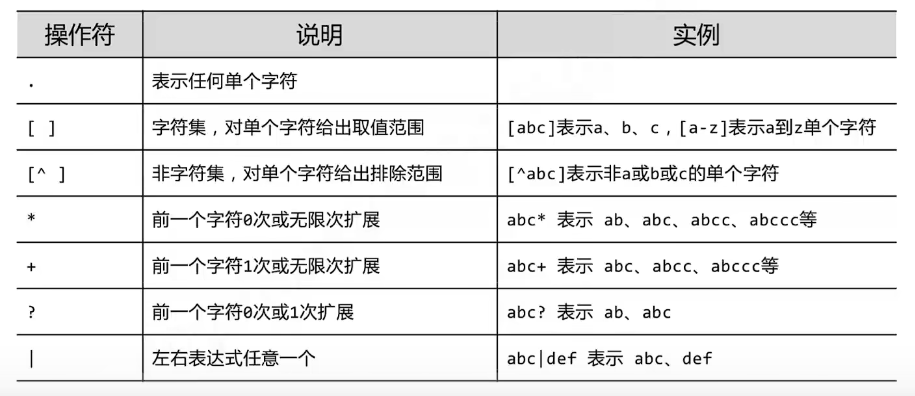
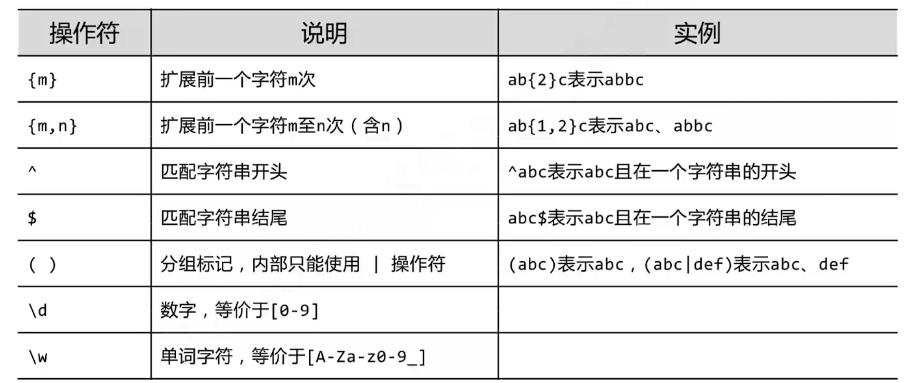

import re
test = re.search("a","b") #"a":字符串模板 "b":查找的对象,找到显示位置内容,否则显示none
test = re.findall("cai","cai oppo") #以上同理
#实际应用
test = re.findall("[1-9A-Z]","A")) #[1-9A-Z]:定义的范围规则,查找A内容
test = re.findall("[1-9A-Z]+","A")) #只要符合的要求至少打印一次
------------------------------------sub替换内容---------------------------------------
#sub的使用
语法: re.sub("被替换的内容","替换的内容","文本内容")
print(re.sub('p','P',"this is password")) #打印输出this is Password
写代码时加了r,表示不使用正则表达式
爬取豆瓣代码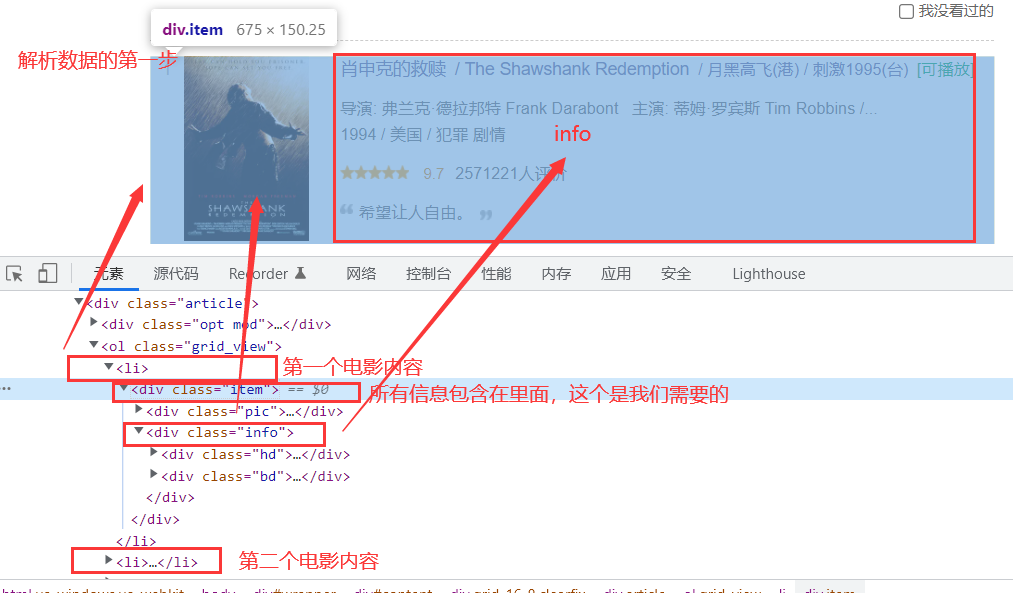
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:38
#@Author : clq
#@file : spider.py
#@Software : PyCharm Community Edition
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import sqlite3
#主函数用来调用其它函数
def main():
print("3 2 1 ..开始爬取豆瓣网站数据")
#目标网址
baseurl = "https://movie.douban.com/top250?start="
#调用爬取网址数据函数
datalist = getdata(baseurl)
#调用保存数据函数
savepath = ".\\豆瓣电影top250.xsl"
# savedata(savepath)
#调用givenURL函数
# givenURL("https://movie.douban.com/top250?start=")
'''
<a class="" href="https://movie.douban.com/subject/1292052/">
<a class="" href="https://movie.douban.com/subject/1291546/">
根据俩个电影的超链接定义匹配规则,从而拿到相应链接,其它同理
'''
overlink = re.compile(r'<a class="(.*?)">') #(电影链接)定义正则表达式匹配的规则
overname = re.compile(r'<span class="title">(.*?)</span>') #(电影名字)
overimg = re.compile(r'<img.* src="(.*?)"',re.S) #(电影图片)re.S 让换行符包含在字符内
overRating = re.compile(r'<span class="rating_num".*>(.*?)</span>')
overnumber = re.compile(r'<span>(.*?)</span>')
overlanguage = re.compile(r'<span class="inq">(.*)</span>')
overcontent = re.compile(r'<p class="">(.*?)</p>',re.S)
#第二步:爬取网址
def getdata(baseurl): #定义了一个请求url的函数
datalist = [] #定义一个存放数据的空列表
'''
baseurl="https://movie.douban.com/top250?start=" #俩url对比 进行for循环得到所有的内容
url="https://movie.douban.com/top250?start=0"
'''
for i in range(0,10):
url = baseurl +str(i*25) #url进行10次循环读取,10*25=250次
html = givenURL(url) #得到所有网页源码
# 第三步:依次解析源码
soup = BeautifulSoup(html,"html.parser") #对html继续解析,形成相应的树状结构(tag,NavigableString等)
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串内容,形成列表(在网站上查看规律),注意属性要加_下划线
# print(item) #测试,此时已经拿到了所有的内容
data = [] #保存电影重要的信息
item = str(item) #想用正则表达式,需要把格式转换为字符串
# 电影名可能有中文英文俩个,判断一下
dyname = re.findall(overname, item) # #通过正则表达式规则,查找指定的内容,正则表达式规则变量放在全局变量处,[0]:每个电影只显示一个链接即可
if (len(dyname)==2):
CHname = dyname[0] #添加中文名
data.append(CHname)
ENname = dyname[1].replace("/","") #英文名前面有/,因此将它去掉
data.append(ENname)
else:
data.append(dyname[0])
data.append(' ') #外国名留空
dylink = re.findall(overlink,item)[0]
data.append(dylink) #添加电影链接
dyimg = re.findall(overimg,item)[0]
data.append(dyimg) #添加电影图片
dyRating = re.findall(overRating,item)[0]
data.append(dyRating) #添加电影评分
dynumber = re.findall(overnumber,item)[0]
data.append(dynumber) #添加电影人数
dylanguage = re.findall(overlanguage,item)
data.append(dylanguage) #添加电影评价
# 电影概述有一些可能没有,需要判断一下
dycontent = re.findall(overcontent,item)
if len(dycontent) !=0:
gaishu = dycontent[0].replace("。","") #去掉句号
data.append(gaishu) #添加电影概述
else:
data.append(" ") #没有电影概述情况
#针对取得的内容(电影概述)继续规范处理,比如不要的字符空格等
stand = re.findall(overcontent,item)[0] #定义要处理的内容
stand = re.sub('<br(\s+)?/>(\s+)?'," ",stand) #<br(\s+)需要去掉的内容一个或没有," "替换为空,对象是stand
stand = re.sub('/'," ",stand) #去掉/
data.append(stand.strip()) #去掉前后空格,并且再次添加概述
datalist.append(data) #将处理好的电影信息放入datalist
#print(datalist) 最后测试打印所有内容
return datalist #返回数据列表
#第一步:一个网页内容爬取(0-25个电影)
def givenURL(url):
#伪装浏览器代理
headres = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
}
#定义伪装请求的变量
encaresponse = urllib.request.Request(url,headers=headres)
html = ""
#对可能出现的异常进行捕获
try:
response = urllib.request.urlopen(encaresponse)
html = response.read().decode('utf-8')
#print(html)
except urllib.error.HTTPError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
#返回爬出的内容
return html
#保存数据
def savedata(savepath):
print("da")
#固定格式
if __name__ == "__main__": #程序执行时,调用主函数,统一流程
#调用main函数
main()
3.3保存数据
3.3.1Excel表存储数据
利用python库xlwt将数据写入excel表格
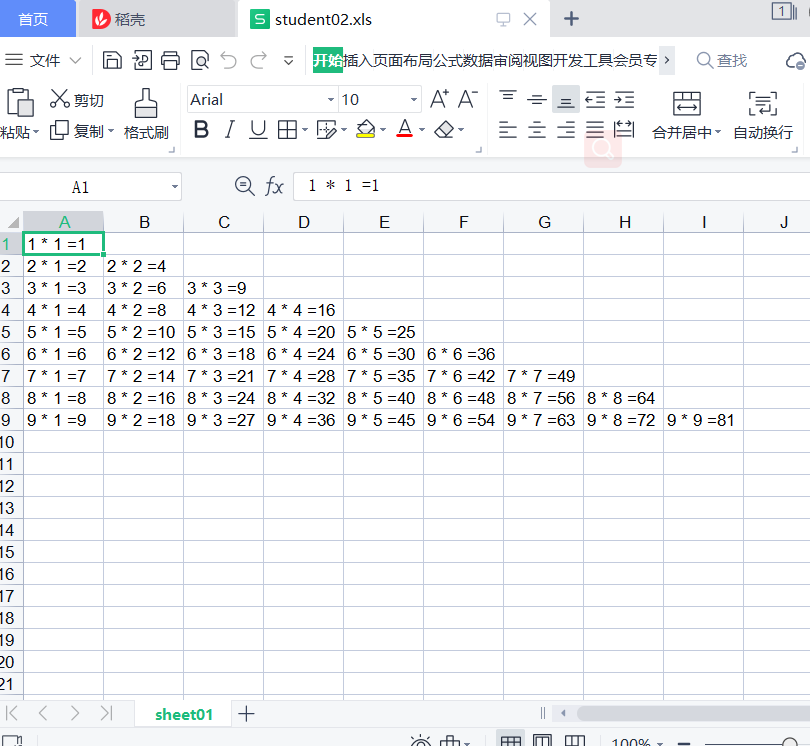
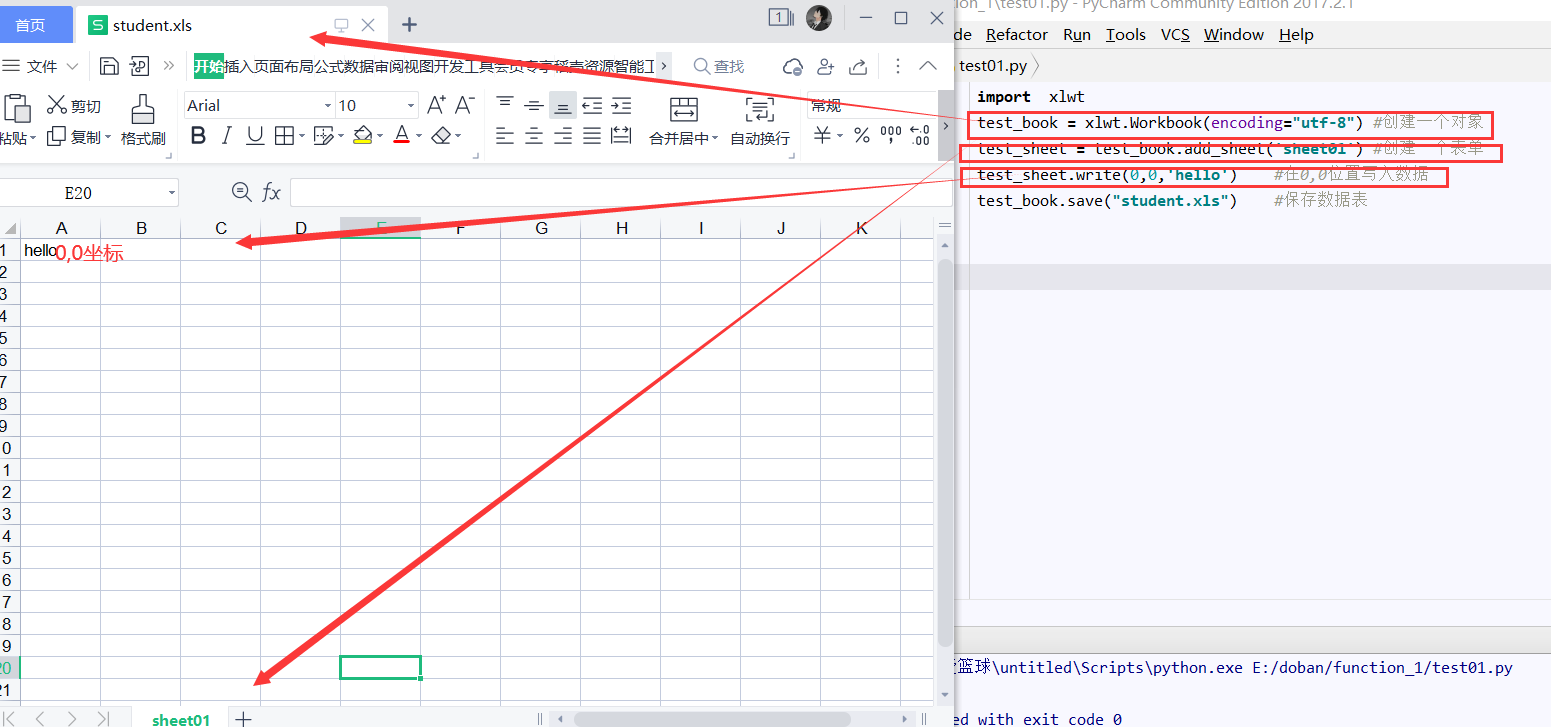 练习:九九乘法表写入excel表
练习:九九乘法表写入excel表
import xlwt
test_book = xlwt.Workbook(encoding="utf-8") #创建一个对象
test_sheet = test_book.add_sheet('sheet01') #创建一个表单
for i in range(0,9):
for j in range(0,i+1):
test_sheet.write(i,j,"%d * %d =%d"%(i+1,j+1,(i+1)*(j+1)))
test_book.save("student02.xls") #保存数据表
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:38
#@Author : clq
#@file : spider.py
#@Software : PyCharm Community Edition
from bs4 import BeautifulSoup
import re
import urllib.request,urllib.error
import xlwt
import sqlite3
#主函数用来调用其它函数
def main():
print("3 2 1 ..开始爬取豆瓣网站数据")
#目标网址
baseurl = "https://movie.douban.com/top250?start="
#调用爬取网址数据函数
datalist = getdata(baseurl)
#调用保存数据函数
savepath = ".\\豆瓣电影.xls"
savedata(datalist,savepath) #带的俩个参数
#调用givenURL函数
# givenURL("https://movie.douban.com/top250?start=")
'''
<a class="" href="https://movie.douban.com/subject/1292052/">
<a class="" href="https://movie.douban.com/subject/1291546/">
根据俩个电影的超链接定义匹配规则,从而拿到相应链接,其它同理
'''
overlink = re.compile(r'<a class="(.*?)">') #(电影链接)定义正则表达式匹配的规则
overname = re.compile(r'<span class="title">(.*?)</span>') #(电影名字)
overimg = re.compile(r'<img.* src="(.*?)"',re.S) #(电影图片)re.S 让换行符包含在字符内
overRating = re.compile(r'<span class="rating_num".*>(.*?)</span>')
overnumber = re.compile(r'<span>(.*?)</span>')
overlanguage = re.compile(r'<span class="inq">(.*)</span>')
overcontent = re.compile(r'<p class="">(.*?)</p>',re.S)
#第二步:爬取网址
def getdata(baseurl): #定义了一个请求url的函数
datalist = [] #定义一个存放数据的空列表
'''
baseurl="https://movie.douban.com/top250?start=" #俩url对比 进行for循环得到所有的内容
url="https://movie.douban.com/top250?start=0"
'''
for i in range(0,10):
url = baseurl +str(i*25) #url进行10次循环读取,10*25=250次
html = givenURL(url) #得到所有网页源码
# 第三步:依次解析源码
soup = BeautifulSoup(html,"html.parser") #对html继续解析,形成相应的树状结构(tag,NavigableString等)
for item in soup.find_all('div',class_="item"): #查找符合要求的字符串内容,形成列表(在网站上查看规律),注意属性要加_下划线
# print(item) #测试,此时已经拿到了所有的内容
data = [] #保存电影重要的信息
item = str(item) #想用正则表达式,需要把格式转换为字符串
# 电影名可能有中文英文俩个,判断一下
dyname = re.findall(overname, item) # #通过正则表达式规则,查找指定的内容,正则表达式规则变量放在全局变量处,[0]:每个电影只显示一个链接即可
if (len(dyname)==2):
CHname = dyname[0] #添加中文名
data.append(CHname)
ENname = dyname[1].replace("/","") #英文名前面有/,因此将它去掉
data.append(ENname)
else:
data.append(dyname[0])
data.append(' ') #外国名留空
dylink = re.findall(overlink,item)[0]
data.append(dylink) #添加电影链接
dyimg = re.findall(overimg,item)[0]
data.append(dyimg) #添加电影图片
dyRating = re.findall(overRating,item)[0]
data.append(dyRating) #添加电影评分
dynumber = re.findall(overnumber,item)[0]
data.append(dynumber) #添加电影人数
dylanguage = re.findall(overlanguage,item)
data.append(dylanguage) #添加电影评价
# 电影概述有一些可能没有,需要判断一下
dycontent = re.findall(overcontent,item)
if len(dycontent) !=0:
gaishu = dycontent[0].replace("。","") #去掉句号
data.append(gaishu) #添加电影概述
else:
data.append(" ") #没有电影概述情况
#针对取得的内容(电影概述)继续规范处理,比如不要的字符空格等
stand = re.findall(overcontent,item)[0] #定义要处理的内容
stand = re.sub('<br(\s+)?/>(\s+)?'," ",stand) #<br(\s+)需要去掉的内容一个或没有," "替换为空,对象是stand
stand = re.sub('/'," ",stand) #去掉/
data.append(stand.strip()) #去掉前后空格,并且再次添加概述
datalist.append(data) #将处理好的电影信息放入datalist
# print(datalist)
return datalist #返回数据列表
#第一步:一个网页内容爬取(0-25个电影)
def givenURL(url):
#伪装浏览器代理
headres = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36"
}
#定义伪装请求的变量
encaresponse = urllib.request.Request(url,headers=headres)
html = ""
#对可能出现的异常进行捕获
try:
response = urllib.request.urlopen(encaresponse)
html = response.read().decode('utf-8')
#print(html)
except urllib.error.HTTPError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
#返回爬出的内容
return html
#保存数据
def savedata(datalist,savepath):
print("正在保存爬取数据")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建一个对象,style_compression=0:样式压缩的效果
sheet = book.add_sheet('豆瓣电影',cell_overwrite_ok=True) # 创建一个表单,cell_overwrite_ok:覆盖以前的内容
#列的定义(元组)
col = ('电影中文名','电影英文名','电影链接:',"电影图片",'电影评分','电影人数','电影评价','电影概述')
for i in range(0,8):
sheet.write(0,i,col[i]) #表的列写入
for i in range(0,250):
print("第%d个"%(i+1))
data = datalist[i] #电影的数据内容
for j in range(0,8):
sheet.write(i+1,j,data[j])
book.save(savepath) # 保存数据表
#固定格式
if __name__ == "__main__": #程序执行时,调用主函数,统一流程
#调用main函数
main()
print("爬取成功!")
执行输出:
C:\Users\鸡哥爱篮球\untitled\Scripts\python.exe E:/doban/code/spider.py
3 2 1 ..开始爬取豆瓣网站数据
正在保存爬取数据
第1个
第2个
...
第249个
第250个
爬取成功!
文档查看: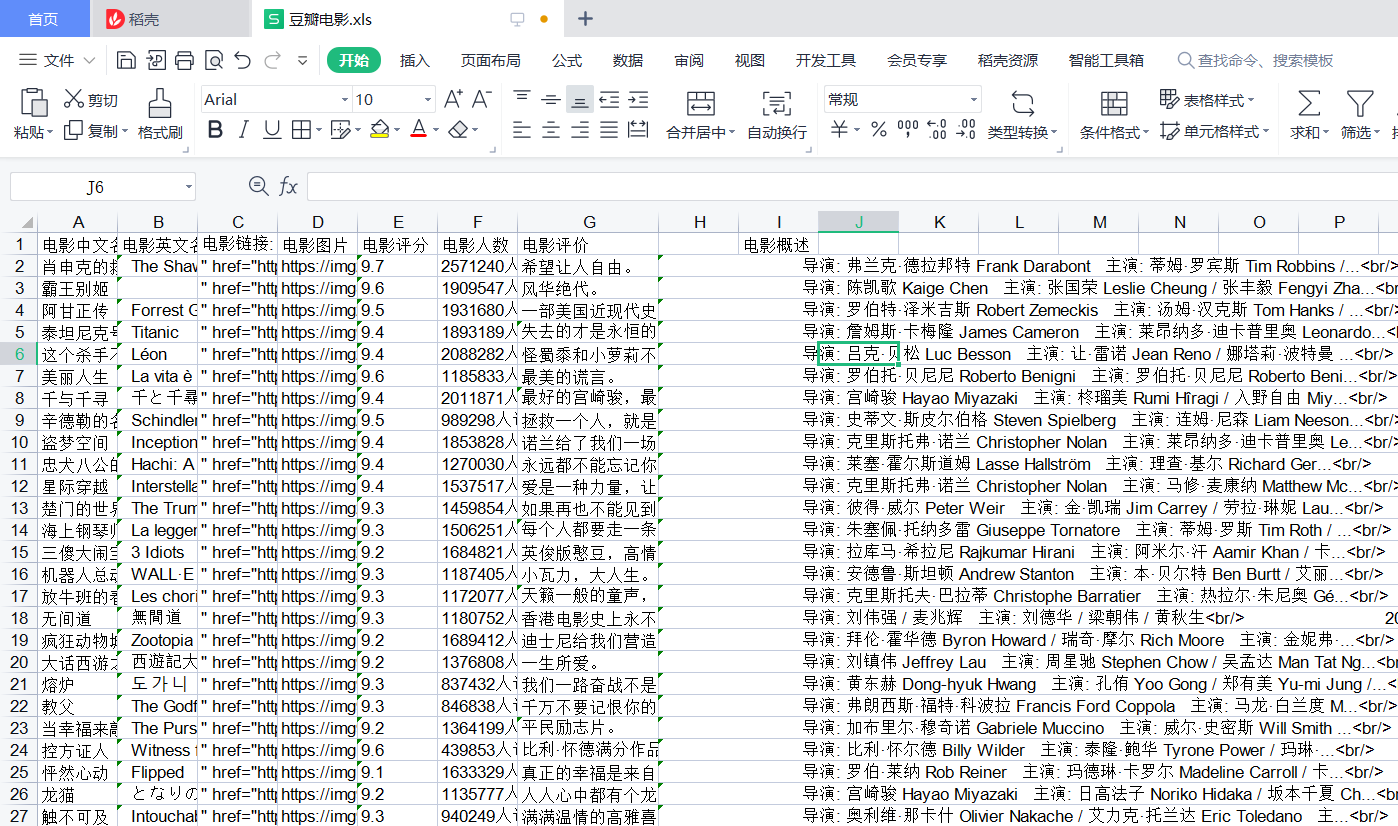
3.3.2Sqlite存储
Pycharm最好处于2018版本以上
针对没有Database情况:点击file —-> settings ——->plugins——->搜索Database Navigator ——->重启
sqlite数据类型: NULL
integer 带符号的整数 REAL 浮点值,存储为8字节 text 文本字符串 blob 值是一个blob数据,根据输入存储 varchar
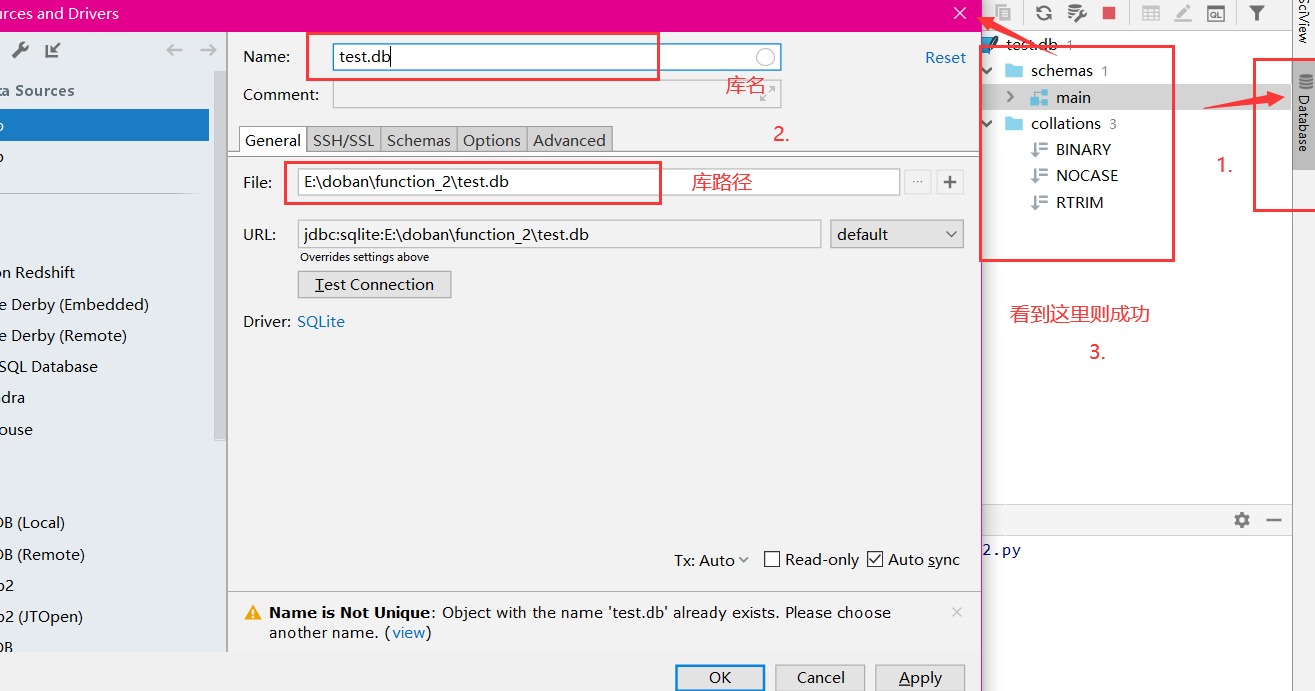
创建表,插入表内容,查询表内容练习
创建表以及插入表语句执行成功后需要注释掉,再进行查询的操作
#-*- coding = utf-8 -*-
#@Time : 2022/3/8 22:55
#@Author : clq
#@file : test2.py
#@Software : PyCharm Community Edition
import sqlite3
#第一步创建数据库表
# # 创建并连接一个数据库对象
# conn = sqlite3.connect("test.db")
# print("opened database success")
#
# #以下是通过游标将sql的语句提交执行,方便实用(增删改查)
# cur = conn.cursor() #引入库的游标
# #创建表的语句
# sql = '''
# create table test
# (id int not null
# primary key,
# name text not null,
# age int not null,
# address char(50),
# salary real);
# '''
# cur.execute(sql) #执行sql语句
# conn.commit() #提交数据库操作
# conn.close() #关闭数据库连接
# print("success create tables")
#第二步插入数据内容
# conn = sqlite3.connect("test.db")
# print("opened database success")
#
# #以下是通过游标将sql的语句提交执行,方便实用(增删改查)
# cur = conn.cursor() #引入库的游标
# #插入表数据内容语句
# sql = '''
# insert into test(id,name,age,address,salary)
# values(1,'小蔡',21,'湖北',9500),(2,'xiao蔡',22,'深圳',15000);
# '''
# cur.execute(sql) #执行sql语句
# conn.commit() #提交数据库操作
# conn.close() #关闭数据库连接
# print("insert test-tables success ")
#第三步查询数据内容
conn = sqlite3.connect("test.db")
print("========opened database success========")
#以下是通过游标将sql的语句提交执行,方便实用(增删改查)
cur = conn.cursor() #引入库的游标
#插入表数据内容语句
sql = '''
select * from test
'''
chaxun = cur.execute(sql) #将执行sql的语句赋予chaxun
for row in chaxun:
print("id = ",row[0])
print("name =",row[1])
print("age =",row[2] )
print("address =",row[3])
print("salary =",row[4],'\n')
conn.close() #关闭数据库连接
print("========查询完毕========")
sqlite方式保存爬取的数据内容
#调用保存数据函数
dbpath = "movie.db" #sqlite方式
savedata2(datalist,dbpath) #sqlite方式
#第四步保存数据内容(excel sqlite二选一方式)
def savedata2(datalist,dbpath):
print("正在以sqlite方式保存爬取数据")
def initialize_db(dbpath):
# 创建数据库
sql = '''
create table movie250To
(
id integer primary key autoincrement,
cname varchar,
ename varchar,
info_link text,
pic_link text,
score numeric,
rated numeric,
instroduction text,
info text
)
'''
conn = sqlite3.connect(dbpath) #连接数据库
cursor = conn.cursor() #定义游标变量
cursor.execute(sql) #执行sql语句
conn.commit() #提交数据库内容
conn.close() #关闭数据库连接
#函数入口
if __name__ == "__main__": #程序执行时,调用主函数,统一流程
#调用main函数
# main() #暂时关闭主函数
# print("爬取成功!")
initialize_db("movie.db") #进行数据库的初始创建
执行完,可以点击database进行打开sqlite数据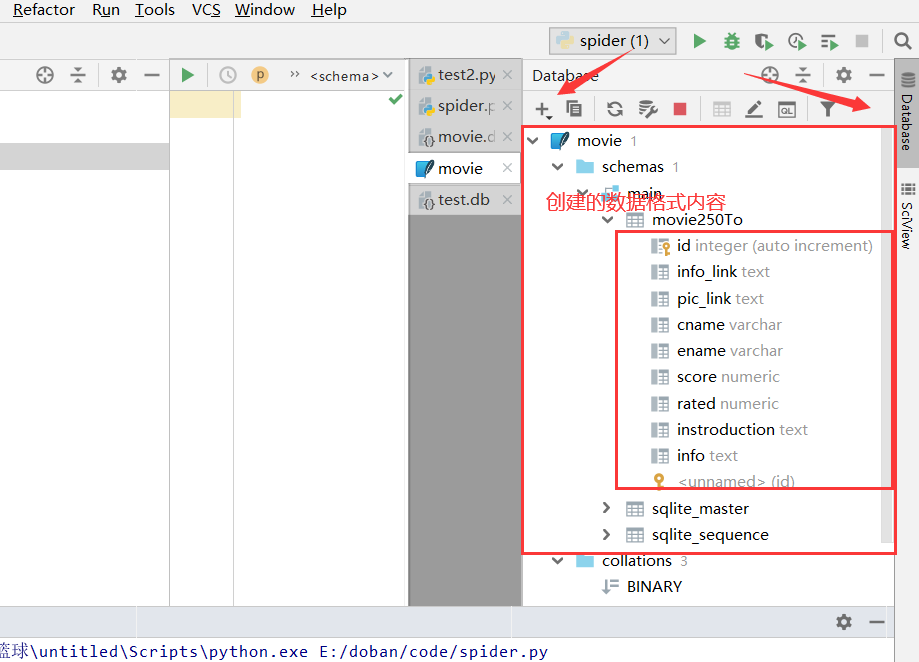
创建完数据库后,需要将其注释掉
往往创建与插入均需要注释
# initialize_db("movie.db")
先把movie数据库删除,再执行否则报错
def savedata2(datalist,dbpath):
print("正在以sqlite方式保存爬取数据")
initialize_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
for index in range(len(data)):
data[index] = '"'+str(data[index])+'"' #超链接需要用""扩起,有些字符串名字同理
sql = '''
insert into movie250To(cname,ename,info_link,pic_link,score,rated,instroduction,info)
values(%s)'''%",".join(data)
print(sql)
# cur.execute(sql)
# conn.commit()
cur.close()
conn.close()
测试输出内容: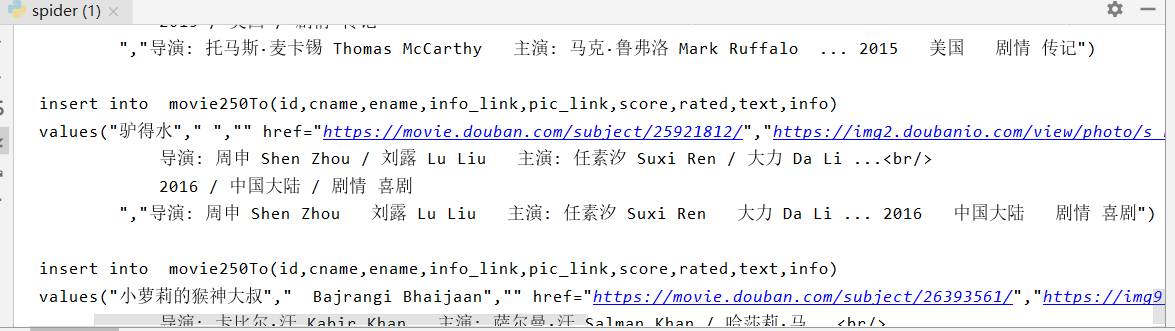

若有收获,就点个赞吧
0 人点赞
