在 JAVA 中,内存的分配和和释放由程序自行操作。其中清除释放内存由垃圾收集器处理。
垃圾收集器的工作就是查看堆内存,确定需要被回收的空间,进行空间回收。
垃圾收集器需要完成的主要工作两项
垃圾收集器在进行垃圾回收前,需要先确定那些对象可以被回收,该操作也叫做”标记“。
针对不同类型内存,该内存区域能否被回收的判断方式不同
简单来说可以被回收的对象就是不存在引用的对象。(不够准确,后面会聊聊引用类型)
1.1.1、引用计数
引用计数概述:在对象中添加一个引用计数器,每当有一个地方引用对象时,计数器 + 1,当引用失效时,计数器减一。当引用计数器为 0 表示该对象可以被回收。
该算法简单,只需要额外的内存空间即可完成对象标记。但是引用计数存在一个缺陷:循环引用。
比如存在两个对象:对象 A、对象 B。
对象 A 持有 对象 B 引用。
对象 B 持有 对象 A 引用。
但是从程序上来说,这两个对象已经没用了,应该会被回收,但是对象 A 和对象 B 中引用计数器不为 0 ,所以对象无法被回收。
1.1.2、可达性分析
可达性分析概述:选定“活动的对象“作为 GC ROOT,以”GC ROOT” 为根节点将对象及其引用关系组成追踪链条。
如下图:
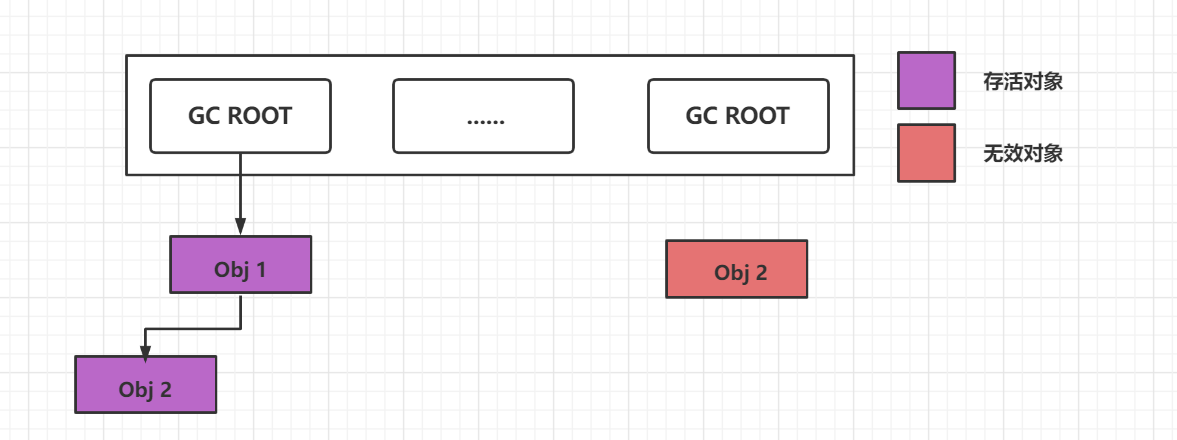
在 JVM 定义中,能够作为 GC ROOT 的对象可以是
- 虚拟机栈中正在引用的对象
如:方法堆栈中用到的参数、局部变量、临时变量等。 - 本地方法栈(Native方法)中正在引用的对象
- 方法区中类静态属性引用的对象
如:Java 类的引用类型静态变量 - 方法区常量引用的对象
如:字符串常量池里的引用 - Java 虚拟机内部的引用
如:基本数据类型对应的 Class 对象。
常驻的异常对象 NullPointException 等 - 所有被同步锁(synchronized 关键字)持有的对象
1.2、方法区回收
方法区回收的主要内容
- 废弃的常量
- 不在使用的 class
1.2.1、废弃的常量回收
回收废弃常量与回收Java堆中的对象类似。
以字符串字面量回收为例。
假如一个字符串”zhixing“曾经进入常量池中。此时”zhixing“不被任何字符串对吸纳管引用,虚拟机中也没有其他地方引用了这个字面量。如果此时发生内存回收,且垃圾收集器判断有必要的话,会将 “zhixing”常量清理出常量池。
常量池中的其他类、方法、字段、方法的符号也类似。
1.2.2、不在使用的 class 回收
关于 class 的回收条件比较苛刻,当同时满足如下三个条件时,class 允许被回收
- 该 类 的所有实例都已经被回收,即 Java 堆中不存在该类及其子类的实例
- 加载该类的加载器已经被回收。该条件通常除了自定义类加载器之外,很难达到。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用。
当同时满足上述三个条件时,class “允许”被回收,而不是一定会被回收。
二、进行垃圾回收
在确定了那些对象是需要被回收的,接下来就是进行回收释放空间。
2.1、回收算法
日常中收集垃圾的方式有多种,每个地方扫一堆;所有地方扫一堆等。
同样的JVM 中对象的回收算法也有多种,常见的几种 算法 如下:
1.1、标记-清除算法
![[JVM]-垃圾收集 - 图2](/uploads/projects/it-learn@java-base/5c9653793921c6e79aaa1f2bb62fd6e0.webp)
原理:标记所有可回收的对象,然后在回收的时候直接清除被标记对象。
优点:所有存活对象都被标记,所有在清除的时候速度很快
缺点:清除之后容易操作内存空间不连续,容易产生内存碎片。而当程序需要分配连续的大块的内存空间时,由于无法分配,导致触发GC。
1.2、复制算法
![[JVM]-垃圾收集 - 图3](/uploads/projects/it-learn@java-base/35886bee67a2524275a9eb789675d8d4.webp)
原理:将内存空间一分为二,只有一般进行内存分配,当内存满了进行回收的时候,把存活的对象移动到另一块空闲的内存中,并按照顺序排列,然后将除了这写连续的存活对象之外的所有空间进行清除回收。
优点:解决了标记-清除算法存在的内存空间不连续的问题。
缺点:内存空间是昂贵的资源,该算法直接将内存空间一分为二,使得可使用内存空间变少。
1.3、标记-整理 算法
![[JVM]-垃圾收集 - 图4](/uploads/projects/it-learn@java-base/345f0cee87792c9942b337ccbf89a1ea.webp)
原理:标记-整理算法可以说是标记-清除算法和复制算法的整合。标记所有可达的对象,然后通过移动算法将所有可达和不可达的对象进行排序,排序之后将所有不可达的对象进行清除回收内存空间。
1.4、分代收集算法

原理:分代的思想,根据对象额存活周期,将 Heap 分成 “新生代 ”和 “老年代”。不同的分区采用不同的垃圾收集算法。
新生代中,通常遵循2-8原则,能够存活的对象一般不超过20%甚至更少,可以使用复制算法,只要付出少量的存活对象复制成本就可以完成收集。
老年代,对象存活率高,没有额外过多内存空间分配可以使用标记清除算法 或标记整理算法来进行收集。
2.2、具体实现:垃圾收集器
垃圾收集器是 GC 算法的具体实现。
JVM 中常见的垃圾收集器有:Serial、ParNew、Serial Old 等。它们实现的算法不同,使用的场景也不同,常见的使用组合,如下图:
![[JVM]-垃圾收集 - 图6](/uploads/projects/it-learn@java-base/2366e5ec1067e545c4f1001bbbfba826.webp)
垃圾收集器总的可以分为两类:新生代垃圾收集器、老年代垃圾收集器。
2.1、新生代垃圾收集器
2.1.1、Serial
-XX:+UseSerialGC
![[JVM]-垃圾收集 - 图7](/uploads/projects/it-learn@java-base/083240be50c1caf2baf83faf80948e10.webp)
Serial收集器是单线程收集器,它进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束,这时候会后 Stop The World 的情况出现。
Serial 收集器也是一个分代收集器,针对新生代其采用了复制算法。
2.1.2、ParNew
![[JVM]-垃圾收集 - 图8](/uploads/projects/it-learn@java-base/c980d49cee9d8c83a7e9af1a1e80930d.webp)
ParNew 是 Serial 垃圾收集器的多线程版本。
2.1.3、Parallel Scavenge
-XX:+UseParallelGC
![[JVM]-垃圾收集 - 图9](/uploads/projects/it-learn@java-base/cbbb6871d24c49f7ba9bf9824b5bb954.webp)
Parallel Scavenge 是一个新生代并行收集器,使用的复制算法。
不同于 ParNew 其注重吞吐量,且吞吐量可控制,能够有效控制GC停顿时间。
不同于 Serial ,Parallel 是并行的。
2.2、老年代垃圾收集器
2.2.1、Serial Old
-XX:+UseSerialOldGC
Serial Old 和 Serial 一样都是一个单线程的收集器,不过 Serial Old 是针对老年代的垃圾收集器,其采用的是标记-整理算法。
2.2.2、Parallel Old
-XX:+UseParallelOldGC
Parallel Old 和 Parallel 一样,不过Parallel Old 针对的是老年代的垃圾收集器,采用的是标记-整理的算法。
2.2.3、CMS(Concurrent Mark Sweep)
-XX:+UseConcMarkSweepGC
CMS 是老年代的垃圾收集器,采用的 标记-清除的算法。CMS 是一个力求最短回收停顿时间的收集器。
CMS 缺点:采用标记清除,会存在内存碎片化问题,长时间运行会发生 Full GC,导致恶劣的停顿。
同时CMS 会占用更多 CPU 资源,并和用户线程这个争抢。
2.3、新生代、老年代通吃:G1
G1(Garbage First ) 垃圾收集器是当今垃圾回收技术最前沿的研究成果之一。同CMS垃圾回收器一样,G1也是关注最小时延的垃圾回收器,也同样适合大尺寸堆内存的垃圾收集,官方也推荐使用G1来代替选择CMS。G1最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至CMS的众多缺陷。

若有收获,就点个赞吧
0 人点赞
