为什么要谈AST(抽象语法树)?
如果你查看目前任何主流的项目中的devDependencies,会发现前些年的不计其数的插件诞生。我们归纳一下有:javascript转译、代码压缩、css预处理器、elint、pretiier,postcss等。有很多js模块我们不会在生产环境用到,但是它们在我们的开发过程中充当着重要的角色。所有的上述工具,不管怎样,都建立在了AST这个巨人的肩膀上。
AST 运用广泛,比如:
- 编辑器的错误提示、代码格式化、代码高亮、代码自动补全;
- elint、pretiier 对代码错误或风格的检查;
- webpack 通过 babel 转译 javascript 语法;
同时在大屏工程中、以及在国信项目中都会看到这些实际应用的过程
什么是抽象语法树
概念
抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现;而类似于 if-condition-then 这样的条件跳转语句,可以使用带有两个分支的节点来表示。
作用
AST可以将代码转换成JSON语法树,基于语法树可以进行代码转换、替换等很多操作,其实AST应用非常广泛,我们开发当中使用的less/sass、eslint、TypeScript等很多插件都是基于AST实现的。
通过利用AST技术,不仅仅是上述的功能,在现在开发模式中,也诞生了各种各样的工具和框架和插件,很多底层多少都能看到ast的影子,比方说之前比较流行的vue转小程序,他就是通过将vue的语法树,解析成小程序的语法树,然后在小程序上运行的。当然这样的例子可能还有很多。。。
示例
下列辗转相除法编程码的抽象语法树具体展示查看:
let tips = ["Click on any AST node with a '+' to expand it","Hovering over a node highlights the \corresponding part in the source code","Shift click on an AST node expands the whole substree"];function printTips() {tips.forEach((tip, i) => console.log(`Tip ${i}:` + tip));}
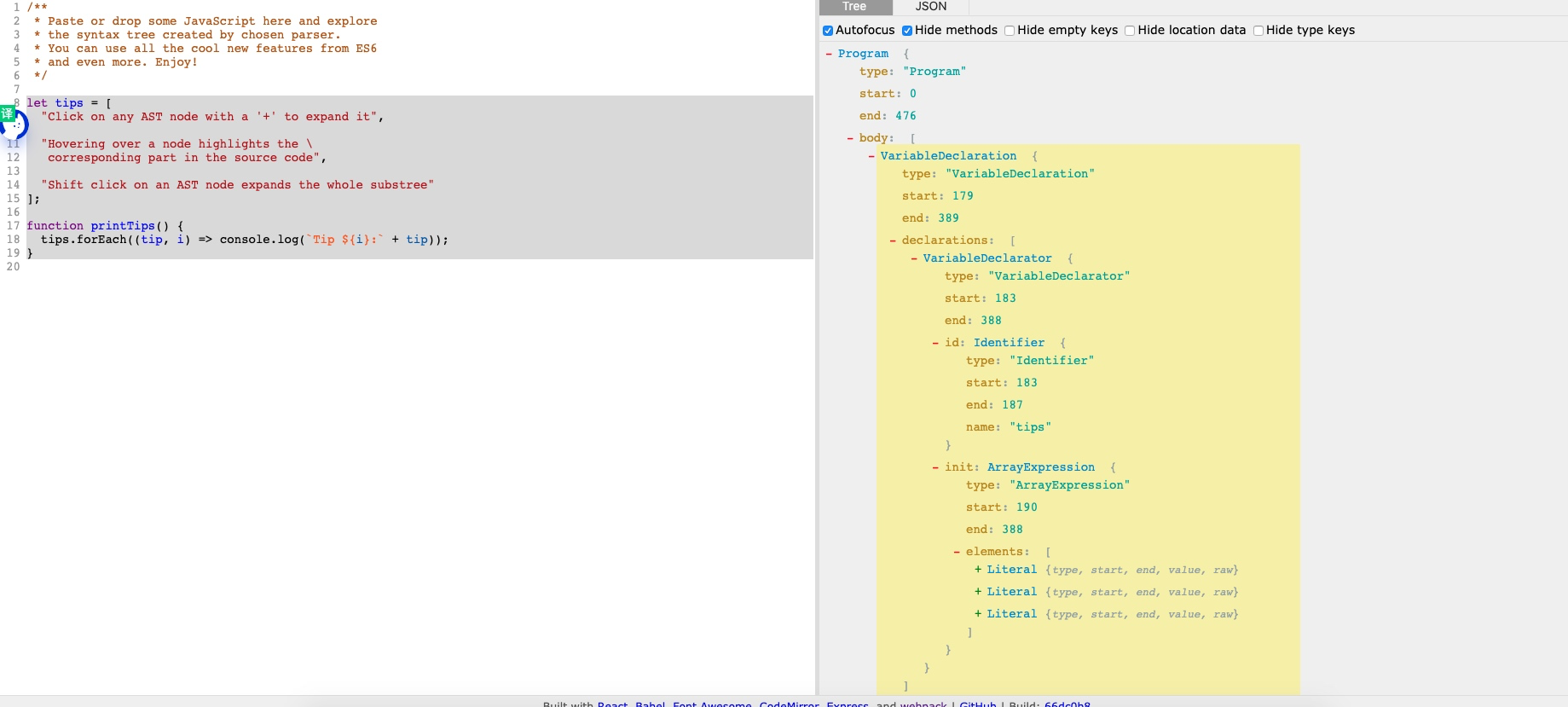
其他在线预览方式:esprima 在线预览
名词解释
词法分析器(Lexer)
词法分析器又称为Scanner,Lexical analyser和Tokenizer。程序设计语言通常由关键字和严格定义的语法结构组成。编译的最终目的是将程序设计语言的高层指令翻译成物理机器或虚拟机可以执行的指令。词法分析器的工作是分析量化那些本来毫无意义的字符流,将他们翻译成离散的字符组(也就是一个一个的Token),包括关键字,标识符,符号(symbols)和操作符供语法分析器使用。
上面是专业术语,白话来说就是,比如我们在读一句话的时候,我们也会做分词操作,比如:“今天天气真好”,我们会把他切割成“今天”,“天气”,“真好”。
那换成js的解析器呢,我们看一下下面一个语句console.log(1);,js会看成console,.,log,(,1,),;。
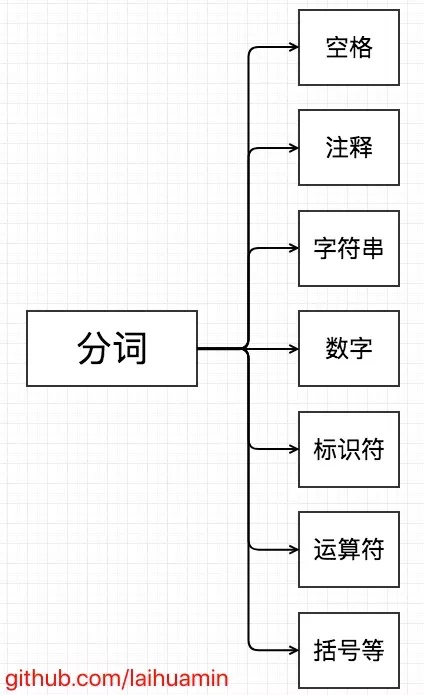
token 的类型
token的类型,根据程序设计语言的特点,单词可以分为五类:关键字、标识符、常量、运算符、界符
(1)标识符:用户自定义的变量名、函数名等字符串。
(2)关键字:具有特殊含义的标识符。
(3)运算符:例如+、-、*、/ 等。
(4)常量:例如3.24、92等。
(5)界符:具有特殊含义的符号,如分号、括号等。
词法分析的结果是识别出如下的单词符号:
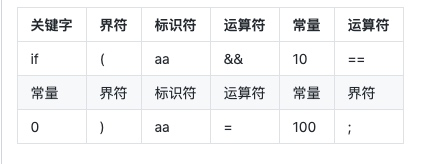
语法分析器(Parser)
编译器又称为Syntactical analyser。在分析字符流的时候,Lexer不关心所生成的单个Token的语法意义及其与上下文之间的关系,而这就是Parser的工作。语法分析器将收到的Tokens组织起来,并转换成为目标语言语法定义所允许的序列。
无论是Lexer还是Parser都是一种识别器,Lexer是字符序列识别器而Parser是Token序列识别器。他们在本质上是类似的东西,而只是在分工上有所不同而已。
字符输入流、tokens和AST之间的关系
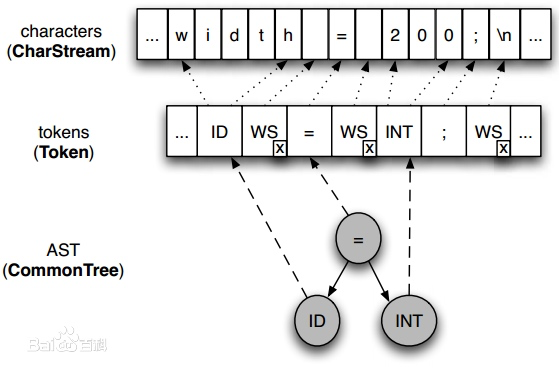
树分析器 (tree parser)
树分析器可以用于对语法分析生成的抽象语法树进行遍历,并能执行一些相关的操作。通常生成ast的作用是帮助识别关键字、替换语句等。
通常到这里一个ast tree就结束了,后续的就是对于树的各种解析处理,根据不同的需求处理语法树,生成自己需要的代码,这个根据不同的语言和解析器就各不相同了。
ast node节点
前述示例中,会看到在ast树中有很多属性,不同的ast语法解析会生成不同的树形结构,这里主要介绍一下js的语法树中常用的节点介绍
ESTree
这里不得不介绍一下ESTree,js社区有一种非官法的语法表达标准。一位Mozilla工程师在Firefox中创建了一个API,该API将SpiderMonkey引擎的JavaScript解析器公开为JavaScript API。这位工程师记录了它产生的格式,并且将该格式作为一种通用语言,用于处理JavaScript源代码的工具,而这个格式一直被更新延续至今,作为一个js解析标准,所以市面上看到的js解析器都按照该标准处理
estree是一个相对简单的静态语法描述,除了在源代码分析,转换方面有很大用处外,也可以用于语言的学习。把estree作为一个规范的快速索引,如果遇到有疑惑的地方,通过这个索引快速定位到规范的官方说明。规范里面,包含语法的静态和动态描述
节点介绍
{type: "Identifier",name: ...}{type: "BinaryExpression",operator: ...,left: {...},right: {...}}
ast语法树中经常会看到这种结构,这些就被成为ast的节点,一个 AST 可以由单一的节点或是成百上千个节点构成。它们组合在一起可以描述用于静态分析的程序语法,介绍几个基础节点
Identifier
标识符,就是我们写 JS 时自定义的名称,如变量名,函数名,属性名,都归为标识符。
interface Identifier <: Expression, Pattern {
type: "Identifier";
name: string;
}
一个标识符可能是一个表达式,或者是解构的模式(ES6 中的解构语法)
Literal
字面量,这里不是指 [] 或者 {} 这些,而是本身语义就代表了一个值的字面量,如 1,“hello”, true 这些,还有正则表达式(有一个扩展的 Node 来表示正则表达式),如 /\d?/。我们看一下文档的定义:
interface Literal <: Expression {
type: "Literal";
value: string | boolean | null | number | RegExp;
}
这里即对应了字面量的值,我们可以看出字面量值的类型,字符串,布尔,数值,null 和正则。
####RegExpLiteral
这个针对正则字面量的,为了更好地来解析正则表达式的内容,添加多一个 regex 字段,里边会包括正则本身,以及正则的 flags。
interface RegExpLiteral <: Literal {
regex: {
pattern: string;
flags: string;
};
}
Programs
一般这个是作为跟节点的,即代表了一棵完整的程序代码树。
interface Program <: Node {
type: "Program";
body: [ Statement ];
}
body 属性是一个数组,包含了多个 Statement(即语句)节点
Functions
函数声明或者函数表达式节点。
ExpressionStatement
表达式语句节点,a = a + 1 或者 a++ 里边会有一个 expression 属性指向一个表达式节点对象(后边会提及表达式)。
BlockStatement
块语句节点,举个例子:if (…) { // 这里是块语句的内容 },块里边可以包含多个其他的语句,所以有一个 body 属性,是一个数组,表示了块里边的多个语句。
EmptyStatement
一个空的语句节点,没有执行任何有用的代码,例如一个单独的分号 ;
DebuggerStatement
debugger,就是表示这个,没有其他了。
ReturnStatement
返回语句节点,argument 属性是一个表达式,代表返回的内容。
IfStatement
if 语句节点,很常见,会带有三个属性,test 属性表示 if (…) 括号中的表达式。
consequent 属性是表示条件为 true 时的执行语句,通常会是一个块语句。
alternate 属性则是用来表示 else 后跟随的语句节点,通常也会是块语句,但也可以又是一个 if 语句节点,即类似这样的结构:if (a) { //… } else if (b) { // … }。alternate 当然也可以为 null。
interface IfStatement <: Statement {
type: "IfStatement";
test: Expression;
consequent: Statement;
alternate: Statement | null;
}
SwitchStatement
switch 语句节点,有两个属性,discriminant属性表示 switch 语句后紧随的表达式,通常会是一个变量,cases 属性是一个 case 节点的数组,用来表示各个 case 语句。
interface SwitchStatement <: Statement {
type: "SwitchStatement";
discriminant: Expression;
cases: [ SwitchCase ];
}
SwitchCase
switch 的 case 节点。test 属性代表这个 case 的判断表达式,consequent 则是这个 case 的执行语句。
当 test 属性是 null 时,则是表示 default 这个 case 节点。
interface SwitchCase <: Node {
type: "SwitchCase";
test: Expression | null;
consequent: [ Statement ];
}
这里就不一一枚举了,可以如果碰到了具体的不清楚的节点,可以参考estree的具体文档
实际开发中常见的几个
babel
babel的过程就是: 解析 -> 转换 -> 生成
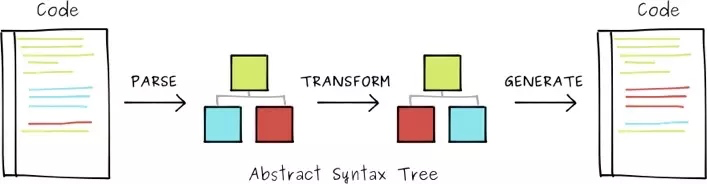
首先介绍下我们需要使用的工具 Babel
- @babel/parser : 将 js 代码 ———->>> AST 抽象语法树;
- @babel/traverse 对 AST 节点进行递归遍历;
- @babel/types 对具体的 AST 节点进行进行修改;
- @babel/generator : AST 抽象语法树 ——->>> 新的 js 代码;
以ES6代码转译为ES5代码为例,babel转译的具体过程如下:
- ES6代码输入
- babel-parser进行解析(重度依赖acorn、acorn-jsx),得到AST
- babel插件plugin用babel-traverse对AST树进行遍历转译,得到新的AST树
- 用babel-generator通过AST树生成ES5代码
postcss
PostCSS 的主要功能只有三个:
- 提到的把 CSS 解析成 JavaScript 可以操作的 AST,
- 调用插件来处理 AST 并得到结果。它负责把 CSS 代码解析成抽象语法树结构(Abstract Syntax Tree,AST),
- 交由插件来进行处理。插件基于 CSS 代码的 AST 所能进行的操作是多种多样的,比如可以支持变量和混入(mixin),增加浏览器相关的声明前缀,或是把使用将来的 CSS 规范的样式规则转译(transpile)成当前的 CSS 规范支持的格式。
postcss plugin api
这是api.postcss编写plugin的地址,打开能够发现,这里大部分api都是基于ast节点进行处理的
postcss node节点
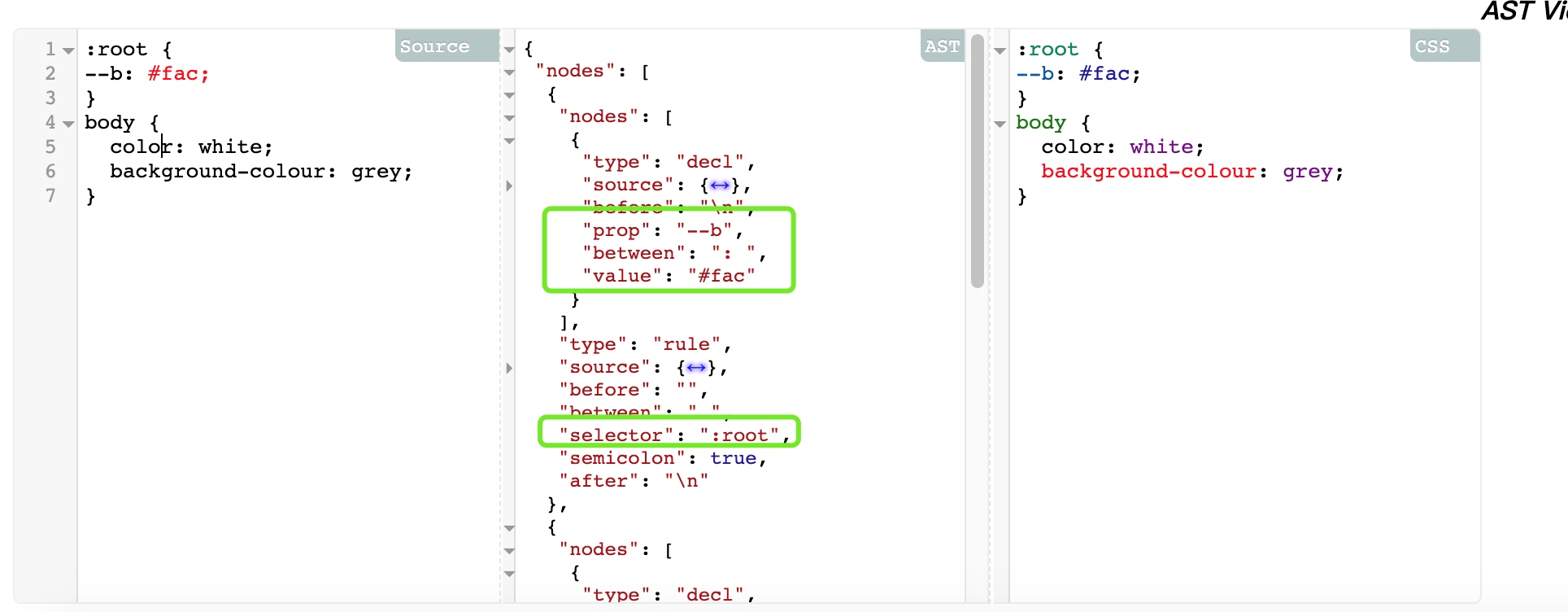
typescript
ts编译流程:
- SourceCode(源码) ~~ Scanner扫描器 ~~> 从源码生成Token 流
- Token 流 —> Parser解析器 —> AST(抽象语法树)
- AST —> Binder绑定器 —> Symbols(符号)
- AST + 符号 —> Checker检查器 —> 类型检查/验证(符号和 AST 是检查器用来验证源代码语义的)
- AST + 检查器 —> Emitter发射器 —> 生成最终的JavaScript 代码 (需要输出 JavaScript 时)
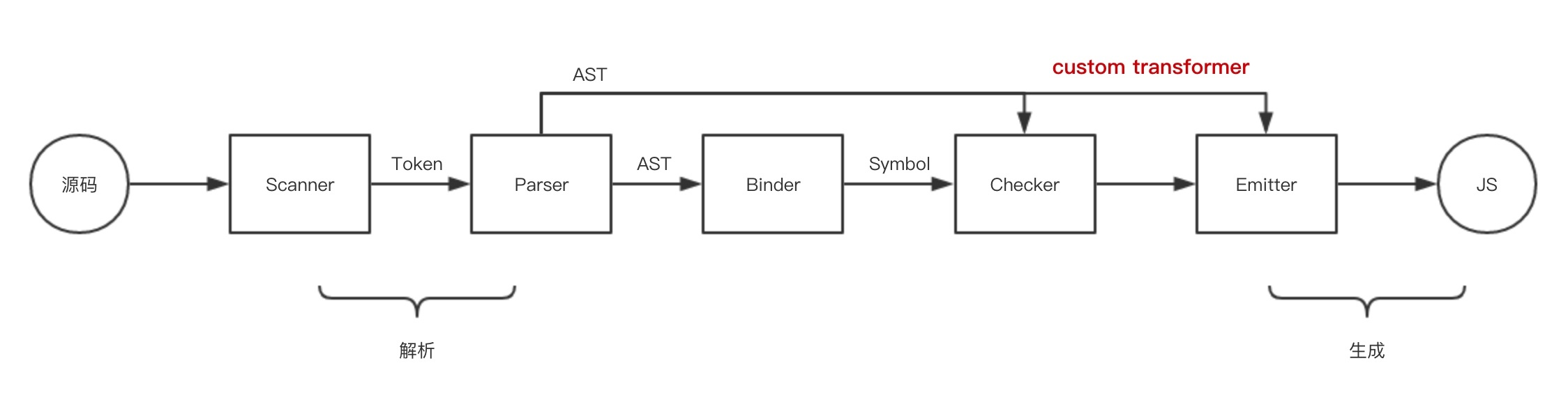
对于ts plugin通常是在emitter阶段起作用的具体ts介绍请参考
ts node节点
ts是一个js超集,是一个编译型语言,同样在ast节点中会与js有不同,其中ts中大概已经有三百多个节点
在 TypeScript/typescript.d.ts 源码中,用枚举类型 SyntaxKind 定义了所有的 AST 节点类型,到目前为止近 400 个,可以看出来 AST 的树形结构非常得精确细致,想手动分析记忆比较困难,可以借助 ts-ast-viewer 这个可视化工具帮助理解代码的 AST 结构。
ts getSourceFile 入口相关代码
https://github.com/microsoft/TypeScript/blob/4c7844be74e97b172c3eb0ac37b51bc4e55706f2/src/compiler/emitter.ts#L754
ts-loader 处理先关
https://github.com/TypeStrong/ts-loader/blob/ce39c25a00641cb708efcd2e31556cb3f7afa771/src/instances.ts#L601
https://github.com/TypeStrong/ts-loader/blob/e9ef049cf2368b4b5e1f092789cf729cdc208d2c/src/index.ts#L443
ts node节点预览


vue 编译插件 vue-template-compiler
上面说了很多,当然也不会丢掉现在开发中最常用的框架vue。目前现有项目中,对vue的解析都是通过配置vue-loader解析,但是底层实现的借助的是vue-template-compiler
vue-template-compiler这个插件在现有的大屏工程中用于解析组件template中,用于识别slot插槽名称、$emit事件名称
compiler.compile
compiler.compile(template, [options]),主要作用是编译模板字符串,并返回后的js代码,下面是该api的返回值
{
ast: ?ASTElement, // 解析模板过后生成的ast
render: string, // 主要的渲染函数代码
staticRenderFns: Array<string>, // 静态子树的呈现代码(如果有)
errors: Array<string> // 模板语法错误(如果有的话返回)
}
上面的render和staticRenderFns与通过Vue.compile(template)生成的返回一致,稍微介绍一下下面两个东西
render函数
下面是被渲染的vue 模板
<div id="app">
<header>
<h1>I'm a template!</h1>
</header>
<p v-if="message">
{{ message }}
</p>
<p v-else>
No message.
</p>
</div>
生成的render函数
(function() {
with(this){
return _c('div',{ //创建一个 div 元素
attrs:{"id":"app"} //div 添加属性 id
},[
_m(0), //静态节点 header,此处对应 staticRenderFns 数组索引为 0 的 render function
_v(" "), //空的文本节点
(message) //三元表达式,判断 message 是否存在
//如果存在,创建 p 元素,元素里面有文本,值为 toString(message)
?_c('p',[_v("\n "+_s(message)+"\n ")])
//如果不存在,创建 p 元素,元素里面有文本,值为 No message.
:_c('p',[_v("\n No message.\n ")])
]
)
}
})
staticRenderFns
staticRenderFns是一个数组数组,这个数组中的函数与 VDOM 中的 diff 算法优化相关,我们会在编译阶段给后面不会发生变化的 VNode 节点打上 static 为 true 的标签,那些被标记为静态节点的 VNode 就会单独生成 staticRenderFns 函数
[
(function() { //上面 render function 中的 _m(0) 会调用这个方法
with(this){
return _c('header',[_c('h1',[_v("I'm a template!")])])
}
}),
...
]
后语
这个分享,目的不是为了分享ast,ast不是一门技术,而更多的是一个偏向于程序设计的思想,如果能够了解这门思想,然后理解他的原理,以及实现思路,包括作用。在这种思维基础上,可能给我们做了无限的支撑。
技术很强大,但是技术背后的原理以及实现思路可能同样重要,能在前辈的基础上造轮子也是种硬实力。

若有收获,就点个赞吧
0 人点赞
