1.数组
寻找数组的中心索引

分析:我们可以定义一个指针,遍历数组,将左右两边的元素累加,若两边相等则找到该元素。
public static int demo(int[] arr) {// 右侧所有元素之和int rightSum = 0;for (int i = 0; i < arr.length; i++) {rightSum += arr[i];}// 左侧元素之和int leftSum = 0;for (int i = 0; i < arr.length; i++) {rightSum = rightSum - arr[i];if (leftSum == rightSum) {// 找到该位置return i;}leftSum += arr[i];}// 未找到该位置return -1;}
搜索插入位置

方式一:遍历
因为是排序数组,所以只需要遍历数组,找到第一个大于或等于目标值得下标即为该下标。
public static int demo(int[] nums, int target) {for (int i = 0; i < nums.length; i++) {if (target <= nums[i]) {return i;}}return nums.length;}
方式二:二分查找
- 若元素在数组中,最终通过
nums[mid]==target找到位置 - 元素不在数组中,因目标元素
target一定会大于left指针所指向的元素,故left即是目标位置。 ```java public static int demo(int[] nums, int target) { return search(nums, 0, nums.length - 1, target); }
public static int search(int[] nums, int left, int right, int target) {
if (left > right) {// target 至少在最左侧return left;}int mid = (left + right) / 2;if (nums[mid] == target) {return mid;} else if (target < nums[mid]) {// 左侧return search(nums, left, mid - 1, target);} else {// 右侧return search(nums, mid + 1, right, target);}
}
<a name="UkcI4"></a>#### 合并区间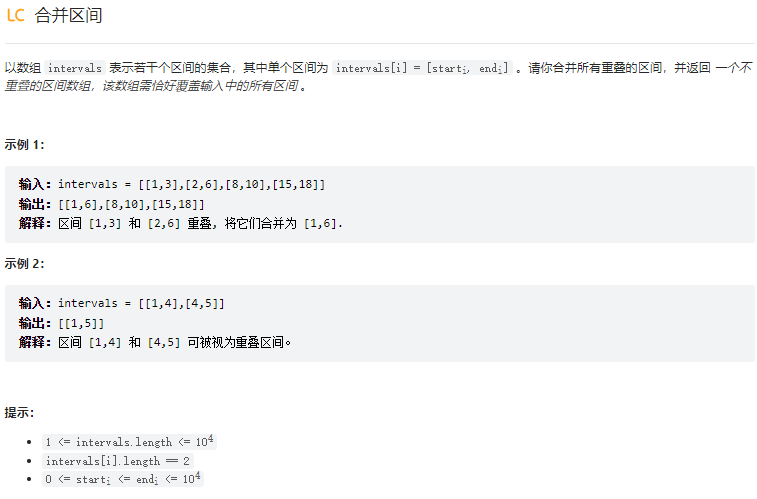<br />要点分析:1. 要合并区间,主要检查交叉的区间,那么首先可以对区间开始数字进行排序1. 遍历排序区间,循环外定义初始区间(默认第一个),遍历后续区间1. 若与该区间交叉,则合并区间1. 不交叉,将循环外区间加入结果集(不可能在交叉),重置初始区间为当前区间,继续遍历实现:```javapublic static void main(String[] args) {int[][] arr = new int[][]{{1, 5}, {2, 7}, {11, 16}, {3, 5}};int[][] test = test(arr);Arrays.stream(test).map(Arrays::toString).forEach(System.out::println);}private static int[][] test(int[][] arr) {List<int[]> list = new ArrayList<>();Arrays.sort(arr, Comparator.comparingInt(a -> a[0]));// 定义缓存int x = arr[0][0];int y = arr[0][1];for (int i = 1; i < arr.length; i++) {// 若与前一个区间交叉,则可以合并为更大的区间if (y > arr[i][0]) {y = Math.max(y, arr[i][1]);} else {// 不与前一个区间交叉,那么前一个区间(x,y)已经不可能和后面的交叉了list.add(new int[]{x, y});x = arr[i][0];y = arr[i][1];}}list.add(new int[]{x, y});return list.toArray(new int[0][]);}
2.二维数组
旋转矩阵

分析:
要实现旋转,一般我们可以考虑反转的方式实现
对于旋转90度,其演变过程,可以通过先上下反转,在对称反转。
代码实现
public static void main(String[] args) throws InterruptedException {
int n = 2;
int[][] arr = new int[n][n];
int start = 11;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
arr[i][j] = start++;
}
}
// 旋转前
Stream.of(arr).map(Arrays::toString).forEach(System.out::println);
test(arr);
System.out.println("------------------------------");
Stream.of(arr).map(Arrays::toString).forEach(System.out::println);
}
private static void test(int[][] arr) {
// 先上下反转
int len = arr.length;
int mid = len >> 1;
for (int i = 0; i < mid; i++) {
for (int j = 0; j < len; j++) {
int tmp = arr[i][j];
arr[i][j] = arr[len - 1 - i][j];
arr[len - 1 - i][j] = tmp;
}
}
// 沿对角线反转,只需处理上三角
for (int i = 0; i < len; i++) {
for (int j = 0; j < len; j++) {
if (i < j) {
int tmp = arr[i][j];
arr[i][j] = arr[j][i];
arr[j][i] = tmp;
}
}
}
}
零矩阵

分析:要将所有为0的,其行和列都要置位0,那么需要一个中间标记矩阵,标记若该位置为0就是true,不是0->false。在遍历中间矩阵,对所有为true的行列置位0.
public static void main(String[] args) {
int[][] arr = new int[][]{{1, 2, 3}, {4, 5, 0}};
Stream.of(arr).map(Arrays::toString).forEach(System.out::println);
test(arr);
System.out.println();
Stream.of(arr).map(Arrays::toString).forEach(System.out::println);
}
private static void test(int[][] arr) {
int m = arr.length;
int n = arr[0].length;
boolean[][] flags = new boolean[m][n];
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (arr[i][j] == 0) {
flags[i][j] = true;
}
}
}
// 置位0
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (flags[i][j]) {
// 每一行
for (int k = 0; k < m; k++) {
arr[k][j] = 0;
}
// 每一列
for (int k = 0; k < n; k++) {
arr[i][k] = 0;
}
}
}
}
}
对角线遍历

3.字符串
最长公共前缀

分析:
- 既然是公共前缀,完全可以暴力求解,挨个字符遍历,定义一个指针,挨个挨个字符遍历。
- 任取数组中的一个元素作为参照,这里取第一个元素 strs[0],定义一个指针 k,代表 strs[0] 的前 k 项是最长公共前缀,然后从第二个元素开始遍历,逐个字符比较,不断修改 k 值,得到最终结果;
```java
public static String longestCommonPrefix(String[] strs) {
if (strs.length == 0)
int k = strs[0].length(); for (int i = 1; i < strs.length; i++) {return "";
} return strs[0].substring(0, k); }// 取较短的 int len = Math.min(k, strs[i].length()); int j = 0; // 遍历 for (; j < len && strs[0].charAt(j) == strs[i].charAt(j); j++) ; // 重置 k = j;
public static void main(String[] args) { String[] a = {“dog”, “dracecar”, “dcar”}; System.out.println(longestCommonPrefix(a)); }
<a name="rl47h"></a>
#### 最长回文子串
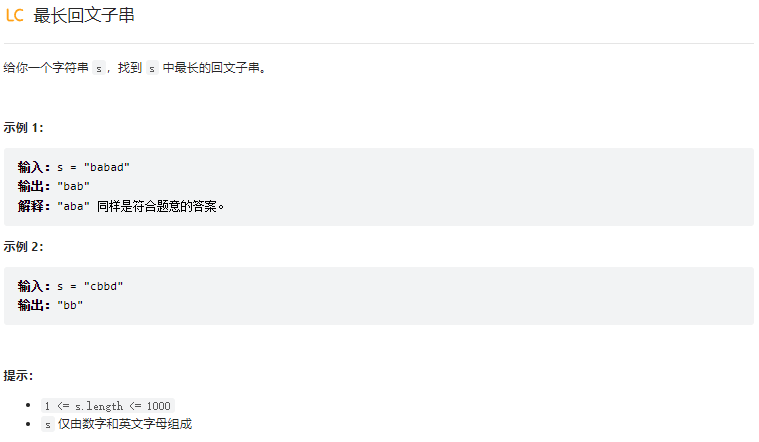<br />分析:面对这种题,不能从局部推演到全局,上一步的选择对下一步有影响,这种题一般想到的就是动态规划求解。<br />假设字符串长度为n, 我们定义n*n的二维矩阵arr,若arr[i][j]=true,则表示字符串从i到j就是回文字符。<br />首先我们需要确定状态转移方程:
1. 对于小于等于2个字符的子串,只需要判断s[i] == s[j]
1. 对于大于2个字符的子串,只有arr[i+1][j-1]是回文子串,并且s[i]==s[i]
即:arr[i+1][j-1] && s[i]==s[i]<br />因为在计算是无法保证arr[i+1][j-1]已经计算过,所以可以按长度子串长度遍历。
```java
public static void main(String[] args) {
String str = "hjabacabaegd";
test(str);
}
private static void test(String str) {
char[] chs = str.toCharArray();
int len = str.length();
boolean[][] dp = new boolean[len][len];
int maxLen = 1;
for (int i = 0; i < len; i++) {
// 单个字符
dp[i][i] = true;
// 两个字符
if (i < len - 1 && chs[i] == chs[i + 1]) {
dp[i][i + 1] = true;
maxLen = 2;
}
}
int start = 0, end = 0;
// 三个及以上字符 arr[i+1][j-1] && s[i]==s[i]
for (int l = 3; l <= len; l++) {
for (int i = 0; i < len - 1 - l; i++) {
// 状态转移
int j = i + l - 1;
if (chs[i] == chs[j] && dp[i + 1][j - 1]) {
dp[i][j] = true;
if (maxLen < l) {
start = i;
end = j;
}
}
}
}
System.out.println("原字符串" + str);
System.out.println("最大回文子串:" + str.substring(start, end + 1));
}
翻转字符串里的单词

字符串匹配算法:KMP
Knuth–Morris–Pratt(KMP)算法是一种改进的字符串匹配算法,它的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的。它的时间复杂度是 O(m+n)。
这段话你可能并不理解。没关系,我们来看一个例子。
情景 1
假如你是一名生物学家,现在,你的面前有两段 DNA 序列S和T,你需要判断T是否可以匹配成为S的子串。
你可能会凭肉眼立即得出结论:是匹配的。可是计算机没有眼睛,只能对每个字符进行逐一比较。
对于计算机来讲,首先它会从左边第一个位置开始进行逐一比较:
这样,当匹配到T的最后一个字符时,发现不匹配,于是从 S 的第二个字符开始重新进行比较:
仍然不匹配,再次将 T 与 S 的第三个字符开始匹配……不断重复以上步骤,直到从 S 的第四个字符开始时,最终得出结论:S 与 T 是匹配的。
你发现这个方法的弊端了吗?我们在进行每一轮匹配时,总是会重复对**A**进行比较。也就是说,对于S中的每个字符,我们都需要从T第一个位置重新开始比较,并且S前面的A越多,浪费的时间也就越多。假设S的长度为m,T 的长度为n,理论上讲,最坏情况下迭代 m−n+1 轮,每轮最多进行n次比对,一共比较了 (m−n+1)×n次,当 m>>n 时,渐进时间复杂度为 O(mn)。
而 KMP 算法的好处在于,它可以将时间复杂度降低到 O(m+n),字符序列越长,该算法的优势越明显。它是怎么实现的呢?
情景 2
再来举一个例子,现在有如下字符串S和P,判断P是否为S的子串。
我们仍然按照原来的方式进行比较,比较到 P 的末尾时,我们发现了不匹配的字符。
注意,按照原来的思路,我们下一步应将字符串P的开头,与字符串S的第二位 C 重新进行比较。而 KMP 算法告诉我们,我们只需将字符串 **P** 需要比较的位置重置到图中 **j** 的位置,**S** 保持 **i** 的位置不变,接下来即可从 i,j 位置继续进行比较。
为什么?我们发现字符串 P 有子串 ACT 和 ACY,当 T 和 Y 不匹配时,我们就确定了 S 中的蓝色 AC 并不匹配 P 右侧的 AC,但是可能匹配左侧的 AC,所以我们从位置 i 和 j 继续比较。
换句话说,Y 对应下标 2,表示下一步要重新开始的地方。
既然如此,如果每次不匹配的时候,我们都能立刻知道 P 中不匹配的元素,下一步应该从哪个下标重新开始,这样不就能大大简化匹配过程了吗?这就是 KMP 的核心思想。
KMP 算法中,使用一个数组 next 来保存 P 中元素不匹配时,下一步应该重新开始的下标。由于计算机不能像我们人类一样,通过视觉来得出结论,因此这里有一种适合计算机的构造 next 数组的方法。
小插曲:构造 next 数组
构造方法为:next[i] 对应的下标,为 P[0...i-1] 的最长公共前缀后缀的长度,令 P[0]=-1。 具体解释如下:
例如对于字符串 abcba:
前缀:它的前缀包括:a, ab, abc, abcb,不包括本身;
后缀:它的后缀包括:bcba, cba, ba, a,不包括本身;
最长公共前缀后缀:abcba的前缀和后缀中只有 a是公共部分,字符串 a 的长度为 1。
所以,我们将 P[0...i-1] 的最长公共前后缀的长度作为 next[i] 的下标,就得到了 next数组。
回到情景 2
我们将思绪切换回来,上次我们还停留在位置 i 和 j,现在继续进行比较。从如下图所示,由于我们已经构造了 next 数组,当继续移动到图中的 r 和 c 位置时,发现不匹配,根据 next 数组,我们可以立即将位置 c 回到下标 0 的位置:
之后的情形就很简单了:
K与A不匹配,查看next数组,A对应next中的元素为-1,表示不动,r加1;- 位置
r字符与位置c字符匹配,继续比较下一位; - 后面元素均匹配,最终找到匹配元素。
以上就是 KMP 算法的思想,现在回过头来看文章开头的第一句话,你是否有更加深刻的理解了呢?
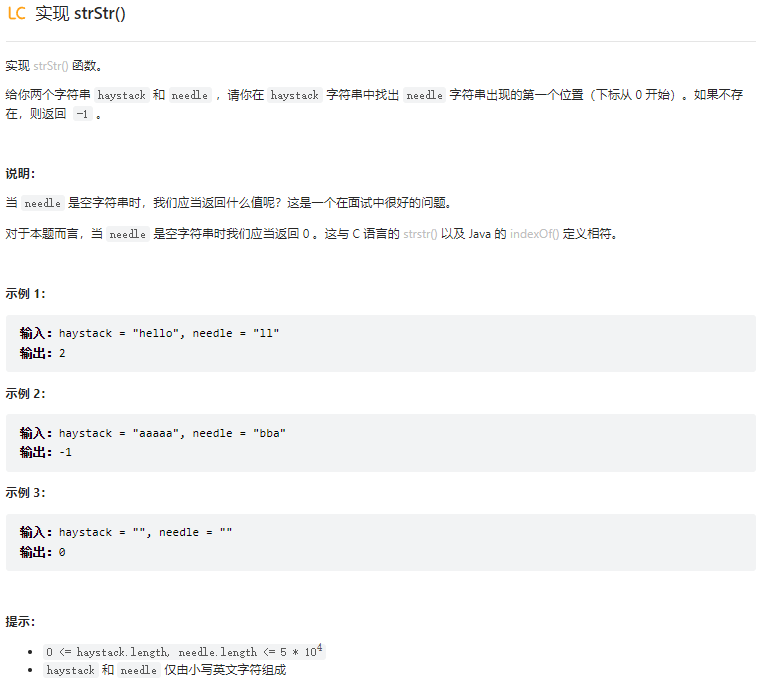
实现strStr()
4.双指针技巧
情景一
在上一章中,我们通过迭代数组来解决一些问题。通常,我们只需要一个指针进行迭代,即从数组中的第一个元素开始,最后一个元素结束。然而,有时我们会使用两个指针进行迭代。
示例
让我们从一个经典问题开始:
反转数组中的元素。比如数组为
['l','e','e','t','c','o','d','e'],反转之后变为['e','d','o','c','t','e','e','l']。
使用双指针技巧,其思想是分别将两个指针分别指向数组的开头及末尾,然后将其指向的元素进行交换,再将指针向中间移动一步,继续交换,直到这两个指针相遇。
反转字符串

分析:翻转字符串,也就是翻转顺序,一般我们想到的就是先进后出,也就是栈结构,将字符串分割后先后入栈再出栈。
public static String test(String originStr) {
if (originStr == null) {
return "";
}
Stack<String> stack = new Stack<>();
String[] arr = originStr.trim().split(" ");
for (int i = 0; i < arr.length; i++) {
if (arr[i].trim().equals("")) {
continue;
}
stack.push(arr[i]);
}
StringBuilder sb = new StringBuilder();
while (!stack.isEmpty()) {
sb.append(stack.pop()).append(" ");
}
return sb.toString().trim();
}
数组拆分 I

分析:从规律上看,通过贪心算法,我们尽量加大的,也就是将数组排序后,倒序两两组合,这样取出来的值累加才能达到最大。
public static int test(int[] arr) {
// 排序
quickSort(arr, 0, arr.length);
//将奇数位置的累加即可
int sum = 0;
for (int i = 0; i < arr.length; i += 2) {
sum += arr[i];
}
return sum;
}
public static void quickSort(int[] arr, int start, int end) {
if (start >= end) {
return;
}
int base = arr[start];
int i = start + 1;
int j = end;
while (i < j) {
while (arr[i] < base && i < j) {
i++;
}
while (arr[j] > base && i < j) {
j--;
}
swap(arr, i, j);
}
swap(arr, start, i);
quickSort(arr, start, i - 1);
quickSort(arr, i + 1, end);
}
private static void swap(int[] arr, int i, int j) {
int tmp = arr[i];
arr[i] = arr[j];
arr[j] = tmp;
}
两数之和 II - 输入有序数组

分析:遍历数组,使用hash结构记录已经遍历过的元素及其位置,避免时间复杂度过大
public int[] test(int[] arr, int target) {
Map<Integer, Integer> map = new HashMap<>();
for (int i = 0; i < arr.length; i++) {
int otherNum = target - arr[i];
if (map.containsKey(otherNum)) {
return new int[]{map.get(otherNum), i};
} else {
map.put(arr[i], i);
}
}
return null;
}
双指针-情景二
有时,我们可以使用两个不同步的指针来解决问题,即快慢指针。与情景一不同的是,两个指针的运动方向是相同的,而非相反。
示例
让我们从一个经典问题开始:
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
如果我们没有空间复杂度上的限制,那就更容易了。我们可以初始化一个新的数组来存储答案。如果元素不等于给定的目标值,则迭代原始数组并将元素添加到新的数组中。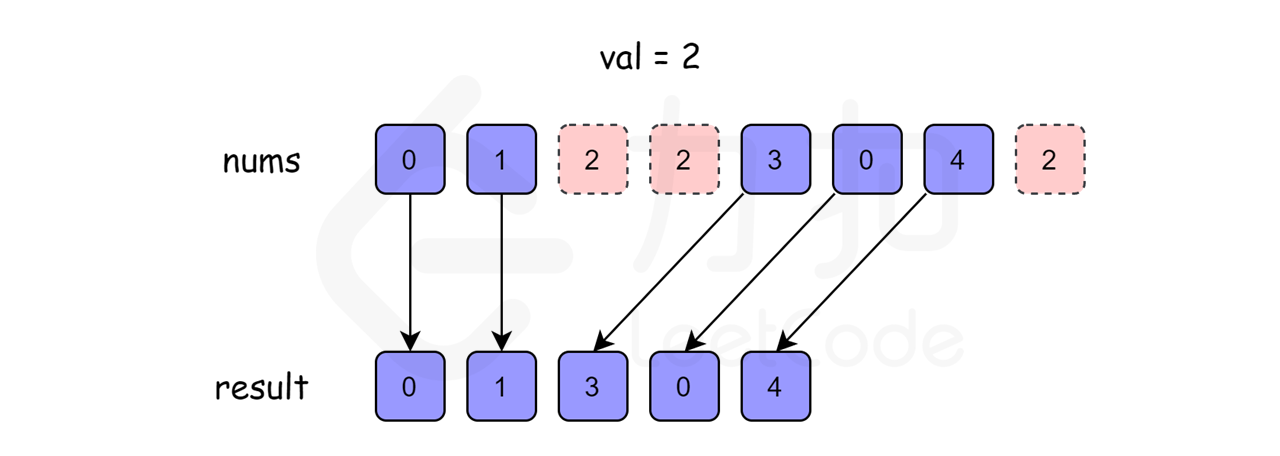
实际上,它相当于使用了两个指针,一个用于原始数组的迭代,另一个总是指向新数组的最后一个位置。
考虑空间限制
如果我们不使用额外的数组,只是在原数组上进行操作呢?
此时,我们就可以采用快慢指针的思想:初始化一个快指针 fast 和一个慢指针 slow,fast 每次移动一步,而 slow 只当 fast 指向的值不等于 val 时才移动一步。
移除元素

分析:要原地移除指定的元素,那么可以利用双指针,一个从左至右找不等于val的元素,一个从右至左找一个不等于val的元素,然后交换位置,直到左右指针碰撞结束。
public static int parse(int[] arr, int val) {
int left = 0;
int right = arr.length - 1;
while (left < right) {
while (arr[left] != val) {
left++;
}
while (arr[right] == val) {
right--;
}
if (left < right) {
swap(arr, left, right);
}
}
// 新数组长度
return right + 1;
}
private static void swap(int[] arr, int left, int right) {
arr[left] = arr[left] ^ arr[right];
arr[right] = arr[left] ^ arr[right];
arr[left] = arr[left] ^ arr[right];
}
最大连续1的个数

分析:
方式一:遍历数组,用一个临时变量curr记录已经遇到的连续1的个数,用另外一个临时变量result记录结果,遇到0时result=Math.max(resut,curr)记录最多连续1个数,直到遍历结束。
方式二:使用快慢指针,慢指针指i向第一连续1的开始位置,快指针指j向连续1的结束位置,其差值就是连续1的个数,用临时变量存储连续最多1的个数,result=Math.max(result,j-i)
// 方式1:临时变量
public static int parse(int[] arr) {
int max = 0;
int curr = 0;
for (int i = 0; i < arr.length; i++) {
if (arr[i] == 1) {
curr++;
} else {
max = Math.max(max, curr);
curr = 0;
}
}
return max;
}
// 方式二:快慢指针
public static int parse2(int[] arr) {
int result = 0;
int i = 0;
int j = 0;
for (int k = 0; k < arr.length; k++) {
if (arr[k] == 1) {
j++;
} else {
result = Math.max(result, j - i);
i = ++j;
}
}
return result;
}
长度最小的子数组

其他
杨辉三角
给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。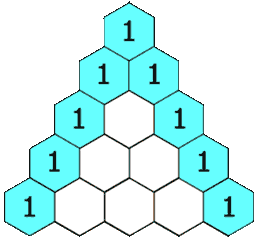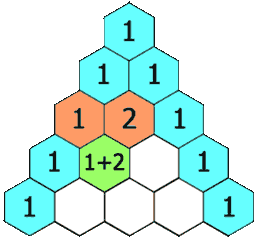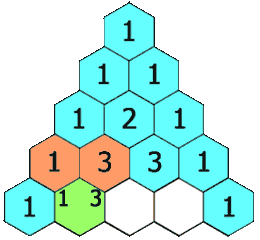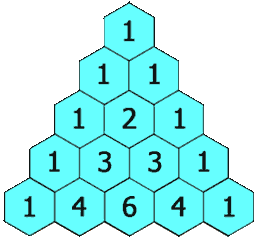
示例 1: 输入: numRows = 5 输出: [[1],[1,1],[1,2,1],[1,3,3,1],[1,4,6,4,1]]
示例 2:
输入: numRows = 1 输出: [[1]]
提示:
1 <= numRows <= 30
杨辉三角 II
给定一个非负索引 rowIndex,返回「杨辉三角」的第 rowIndex 行。
在「杨辉三角」中,每个数是它左上方和右上方的数的和。
示例 1:
输入: rowIndex = 3 输出: [1,3,3,1]
示例 2:
输入: rowIndex = 0 输出: [1]
示例 3:
输入: rowIndex = 1 输出: [1,1]
提示:
0 <= rowIndex <= 33
进阶:
你可以优化你的算法到 O(rowIndex) 空间复杂度吗?
反转字符串中的单词 III

寻找旋转排序数组中的最小值

删除排序数组中的重复项

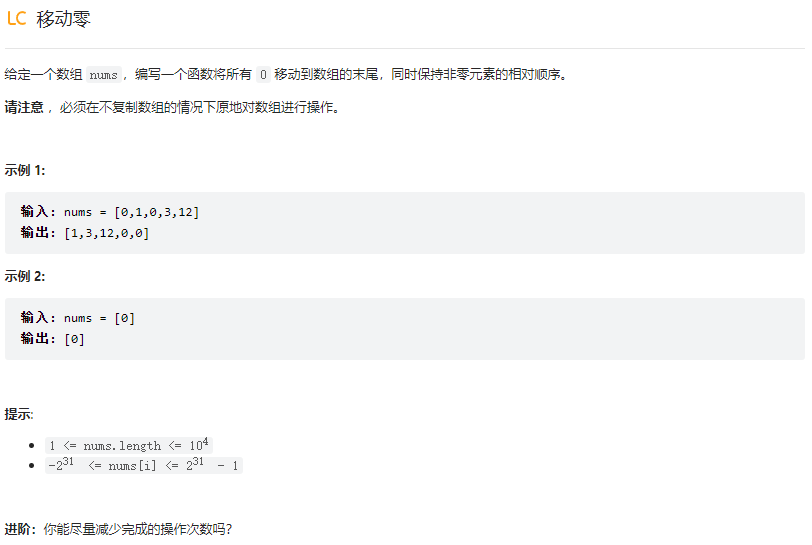
移动零

若有收获,就点个赞吧
0 人点赞
