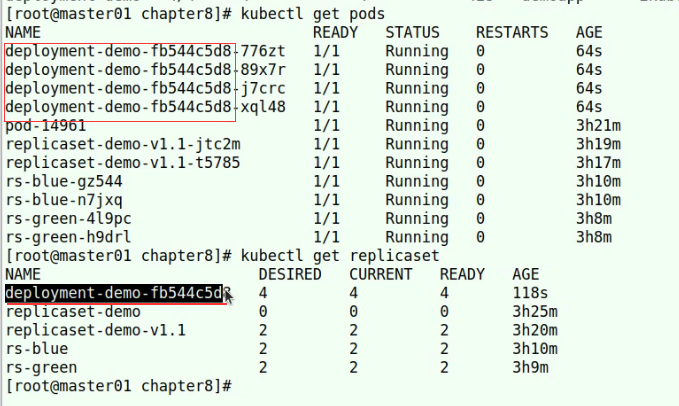
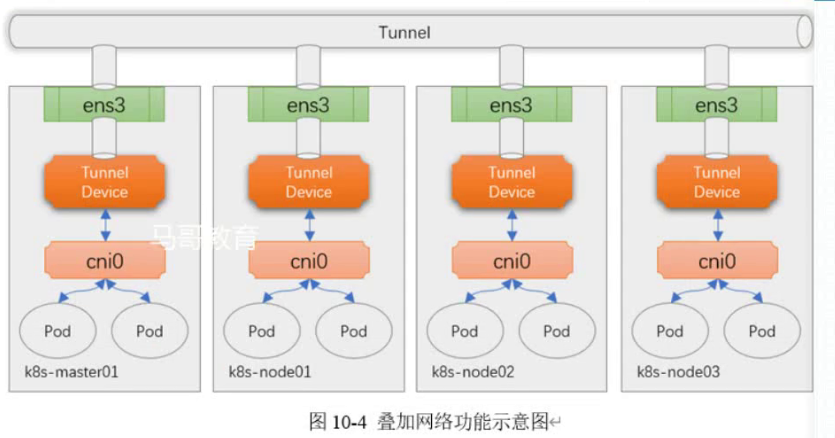
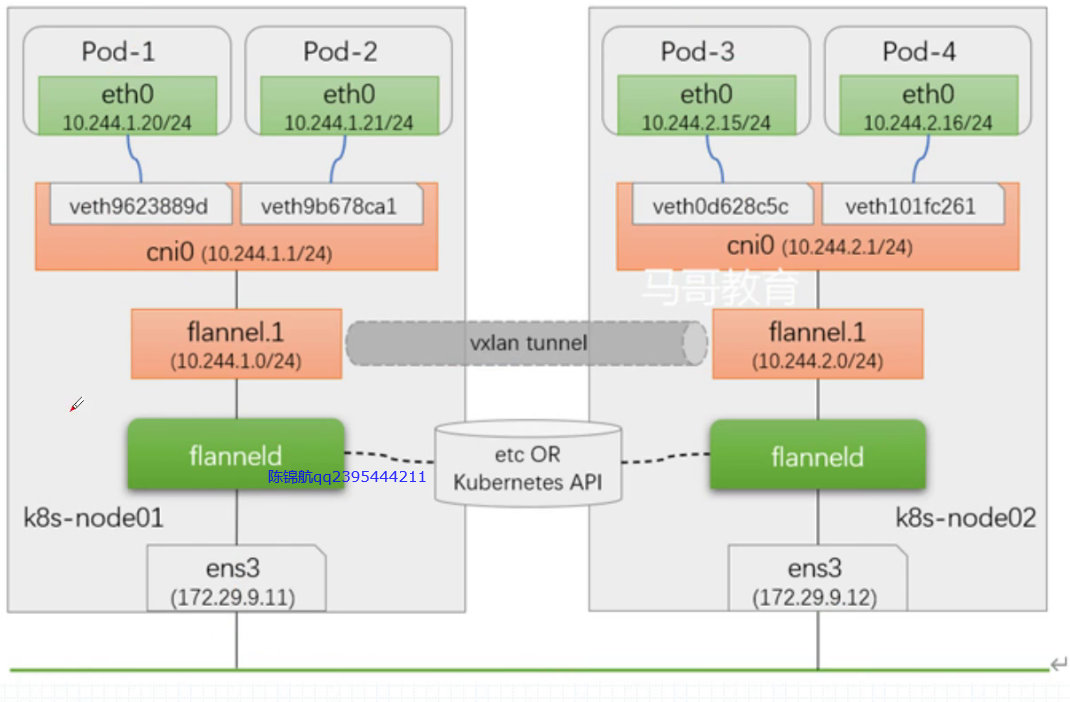
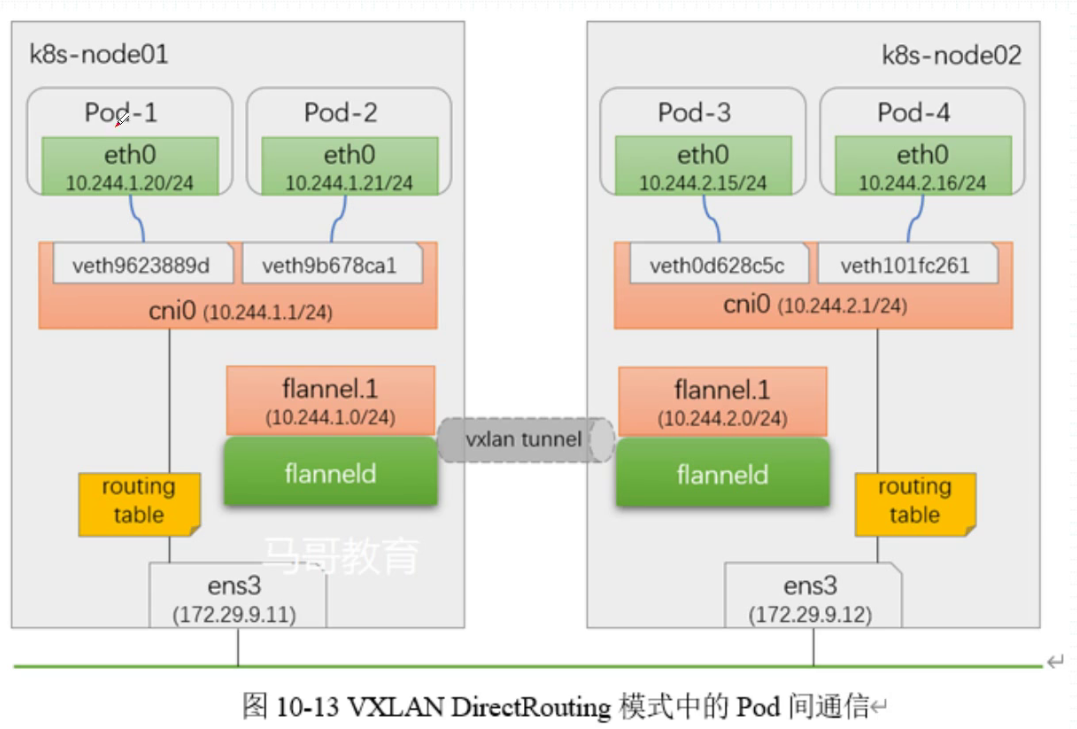
:拓扑无法满足maxSkew时采取的调度策略,默认值DoNotSchedule是一种强制约束,即不予调度至该区域,而另一可用值ScheduleAnyway则是柔性约束,无法满足约束关系时仍可将Pod放入该拓扑中。
32.6. pod优先级调度
PriorityClass
apiVersion: scheduling.k8s.io/v1 # 资源隶属的API群组及版本
kind: PriorityClass # 资源类别标识符
metadata:
name # 资源名称
value # 优先级,必选字段
description # 该优先级描述信息
globalDefault # 是否为全局默认优先级
preemptionPolicy # 抢占策略,Never为禁用,默认为PreemptLowerPriority允许,资源不足时抢占优先级低的pod,
33. 扩展k8s Api
k8s Api扩展源码基础上二开
开发独立的api server通过扩展点扩展
使用CRD
apiVersion: apiextensions.k8s.io/v1 # API群组和版本
kind: CustomResourceDefinition # 资源类别
metadata:
name <string> # 资源名称
spec:
conversion <Object> # 定义不同版本间的格式转换方式
trategy <string> # 不同版本间的自定义资源转换策略,有None和Webhook两种取值
webhook <Object> # 如何调用用于进行格式转换的webhook
group <string> # 资源所属的API群组
names <Object> # 自定义资源的类型,即该CRD创建资源规范时使用的kind
categories <[]string> # 资源所属的类别编目,例如”kubectl get all”中的all
kind <string> # kind名称,必选字段
listKind <string> # 资源列表名称,默认为"`kind`List"
plural <string> # 复数,用于API路径`/apis/<group>/<version>/.../<plural>`
shortNames <[]string> # 该资源的kind的缩写格式
singular <string> # 资源kind的单数形式,必须使用全小写字母,默认为小写的kind名称
preserveUnknownFields <boolean> # 预留的非知名字段,kind等都是知名的预留字段
scope <string> # 作用域,可用值为Cluster和Namespaced
versions <[]Object> # 版本号定义
additionalPrinterColumns <[]Object> # 需要返回的额外信息
name <string> # 形如vM[alphaN|betaN]格式的版本名称,例如v1或v1alpha2等
schema <Object> # 该资源的数据格式(schema)定义,必选字段
openAPIV3Schema <Object> # 用于校验字段的schema对象,格式请参考相关手册
served <boolean> # 是否允许通过RESTful API调度该版本,必选字段
storage <boolean> # 将自定义资源存储于etcd中时是不是使用该版本
subresources <Object> # 子资源定义
scale <Object> # 启用scale子资源,通过autoscaling/v1.Scale发送负荷
status <map[string]> # 启用status子资源,为资源生成/status端点
目前,扩展Kubernetes API的常用方式有3种:使用CRD(CustomResourceDefinitions)自定义资源类型、开发自定义的API Server并聚合至主API Server,以及定制扩展API Server源码。这其中,CRD最为易用但限制颇多,自定义API Server更富于弹性但代码工作量偏大,而仅在必须添加新的核心类型才能确保专用的Kubernetes集群功能正常,才应该定制系统源码。
34. ingress
Ingress:集群外部注入集群内部的流量
Egress:集群内部流出到集群外部的流量
集群外部注入集群内部的流量方法:
Service NodePort
Service externalIP
Service的代理模式:无法实现SSL会话的卸载因为工作在传输层
iptables
IPVS
Service从集群外部引入流量缺陷:
在集群到处打洞开端口而且不具有连续性,无法管理
Ingress:标准的资源类型
Ingress Controller:Ingress控制器七层代理http/TCP代理服务
正常情况下ingress不会吧流量转给service再转给pod,
service将pod归组,ingress需要借助于service识别pod,知道了pod有哪些,ingress进行代理,流量不再由service调度,直接由ingress调度
v1beta1 Ingress资源规范
apiVersion: extensions/v1beta1 # 资源所属的API群组和版本
kind: Ingress # 资源类型标识符
metadata: # 元数据
name <string> # 资源名称
annotations: # 资源注解,v1beta1使用下面的注解来指定要解析该资源的控制器类型
kubernetes.io/ingress.class: <string> # 适配的Ingress控制器类别
namespace <string> # 名称空间
spec:
rules <[]Object> # Ingress规则列表;
- host <string> # 虚拟主机的FQDN,支持“*”前缀通配,不支持IP,不支持指定端口
http <Object>
paths <[]Object> # 虚拟主机PATH定义的列表,由path和backend组成
- path <string> # 流量匹配的HTTP PATH,必须以/开头,URL匹配的进入到该service
pathType <string> # 匹配机制,支持Exact、Prefix和ImplementationSpecific
backend <Object> # 匹配到的流量转发到的目标后端
resource <Object> # 引用的同一名称空间下的资源,与下面两个字段互斥
serviceName <string> # 引用的Service资源的名称
servicePort <string> # Service用于提供服务的端口
tls <[]Object> # TLS配置,用于指定上rules中定义的哪些host需要工作HTTPS模式
- hosts <[]string> # 使用同一组证书的主机名称列表
secretName <string> # 保存于数字证书和私钥信息的secret资源名称
backend <Object> # 默认backend的定义,可嵌套字段及使用格式跟rules字段中的相同
ingressClassName <string> # ingress类名称,用于指定适配的控制器
v1 Ingress资源规范
apiVersion: networking.k8s.io/v1 # 资源所属的API群组和版本
kind: Ingress # 资源类型标识符
metadata: # 元数据
name <string> # 资源名称
annotations: # 资源注解,v1beta1使用下面的注解来指定要解析该资源的控制器类型
kubernetes.io/ingress.class: <string> # 适配的Ingress控制器类别
namespace <string> # 名称空间
spec:
rules <[]Object> # Ingress规则列表
- host <string> # 虚拟主机的FQDN,支持“*”前缀通配,不支持IP,不支持指定端口
http <Object>
paths <[]Object> # 虚拟主机PATH定义的列表,由path和backend组成
- path <string> # 流量匹配的HTTP PATH,必须以/开头
pathType <string> # 支持Exact(精确匹配)、Prefix(前置匹配)和ImplementationSpecific,必选
backend <Object> # 匹配到的流量转发到的目标后端
resource <Object> # 引用的同一名称空间下的资源,与下面两个字段互斥
service <object> # 关联的后端Service对象
name <string> # 后端Service的名称
port <object> # 后端Service上的端口对象
name <string> # 端口名称
number <integer> # 端口号
tls <[]Object> # TLS配置,用于指定上rules中定义的哪些host需要工作HTTPS模式
- hosts <[]string> # 使用同一组证书的主机名称列表
secretName <string> # 保存于数字证书和私钥信息的secret资源名称
backend <Object> # 默认backend的定义,可嵌套字段及使用格式跟rules字段中的相同
ingressClassName <string> # ingress类名称,用于指定适配的控制器
ingres-nginx示例 v1beta1
如果不使用www.ik8s.io域名访问无法访问404
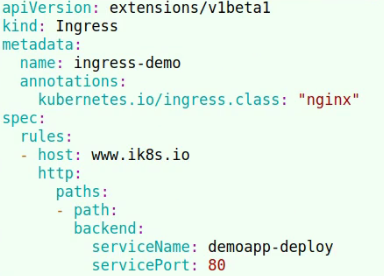
ingres-nginx示例 v1
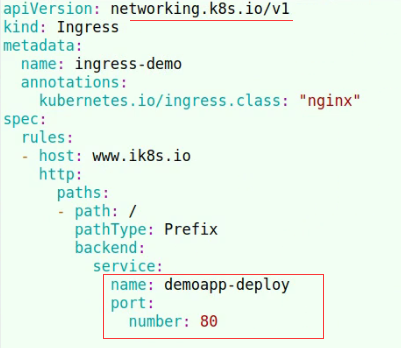
34.1. ingress-nginx https
scretName secret类型名称
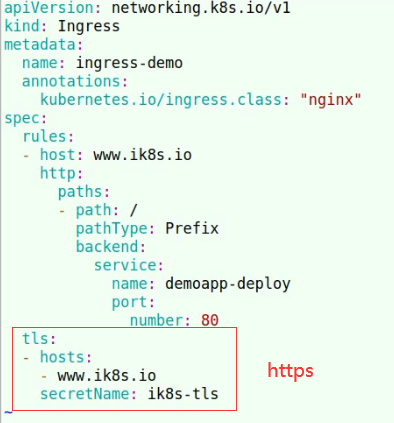
创建需要k8s secret 加密类型资源
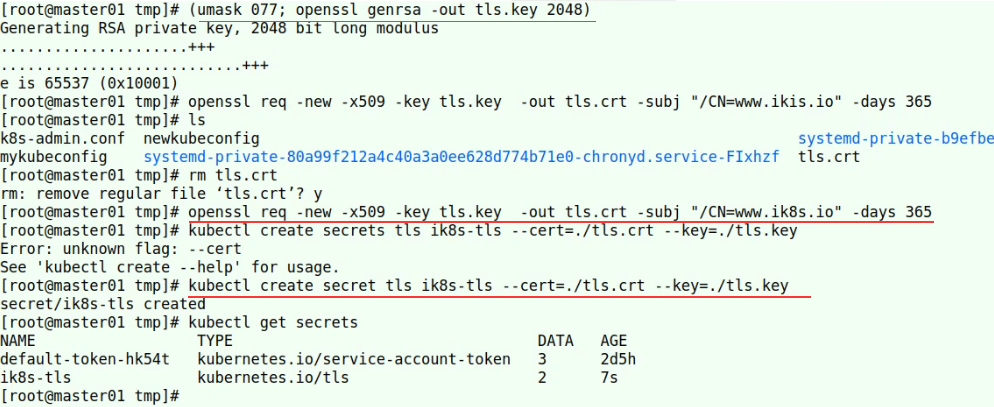
34.2. ingress dashboard

32.3 ingres nginx访问认证
生成secret资源

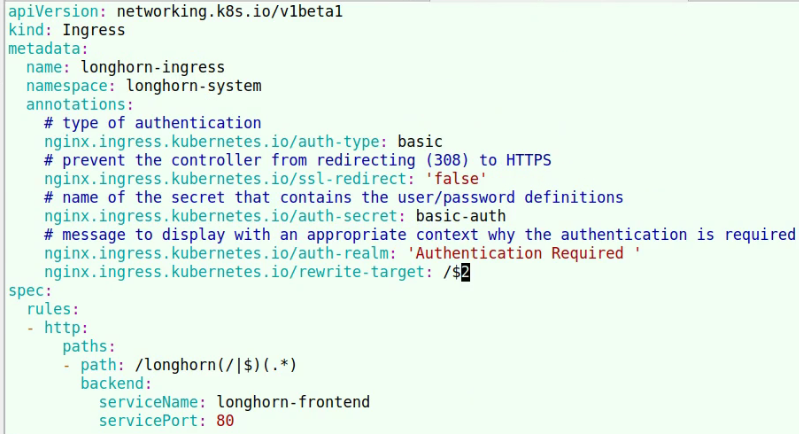
35. contour envoy
35.1. HTTPProxy
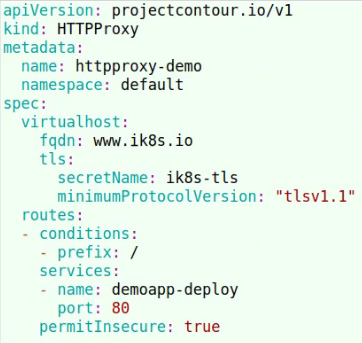
根据访问方式进行调度
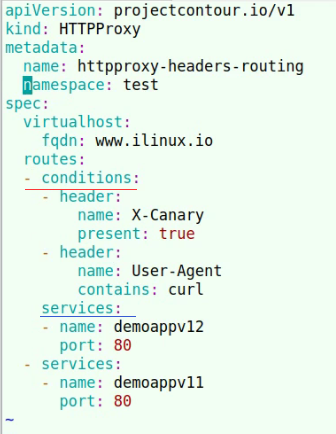
流量权重

HTTPProxy服务弹性
spec:
routes <[]Route>
timeoutPolicy <TimeoutPolicy> # 超时策略
response <String> # 等待服务器响应报文的超时时长
idle <String> # 超时后,Envoy维持与客户端之间连接的空闲时长
retryPolicy <RetryPolicy> # 重试策略
count <Int64> # 重试的次数,默认为1
perTryTimeout <String> # 每次重试的超时时长
healthCheckPolicy <HTTPHealthCheckPolicy> # 主动健康状态检测
path <String> # 检测针对的路径(HTTP端点)
host <String> # 检测时请求的虚拟主机
intervalSeconds <Int64> # 时间间隔,即检测频度,默认为5秒
timeoutSeconds <Int64> # 超时时长,默认为2秒
unhealthyThresholdCount <Int64> # 判定为非健康状态的阈值,即连续错误次数
healthyThresholdCount <Int64> # 判定为健康状态的阈值
36. yaml
apiVersion: v1 #必选,版本号,例如v1
kind: Pod #必选,资源类型,例如 Pod
metadata: #必选,元数据
name: string #必选,Pod名称
namespace: string #Pod所属的命名空间,默认为"default"
labels: #自定义标签列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- name: string #引用pod定义的共享存储卷的名称,需用volumes[]部分定义的的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应少于512字符
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口库号列表
- name: string #端口的名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议,支持TCP和UDP,默认TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #Cpu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为Mib/Gib,将用于docker run --memory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用数量
lifecycle: #生命周期钩子
postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启
preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止
livenessProbe: #对Pod内各容器健康检查的设置,当探测无响应几次后将自动重启该容器
exec: #对Pod容器内检查方式设置为exec方式
command: [string] #exec方式需要制定的命令或脚本
httpGet: #对Pod内个容器健康检查方法设置为HttpGet,需要制定Path、port
path: string
port: number
host: string
scheme: string
HttpHeaders:
- name: string
value: string
tcpSocket: #对Pod内个容器健康检查方式设置为tcpSocket方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认1秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认10秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod的重启策略
nodeName: <string> #设置NodeName表示将该Pod调度到指定到名称的node节点上
nodeSelector: obeject #设置NodeSelector表示将该Pod调度到包含这个label的node上
imagePullSecrets: #Pull镜像时使用的secret名称,以key:secretkey格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为false,如果设置为true,表示使用宿主机网络
volumes: #在该pod上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes类型有很多种)
emptyDir: {} #类型为emtyDir的存储卷,与Pod同生命周期的一个临时目录。为空值
hostPath: string #类型为hostPath的存储卷,表示挂载Pod所在宿主机的目录
path: string #Pod所在宿主机的目录,将被用于同期中mount的目录
secret: #类型为secret的存储卷,挂载集群与定义的secret对象到容器内部
scretname: string
items:
- key: string
path: string
configMap: #类型为configMap的存储卷,挂载预定义的configMap对象到容器内部
name: string
items:
- key: string
path: string
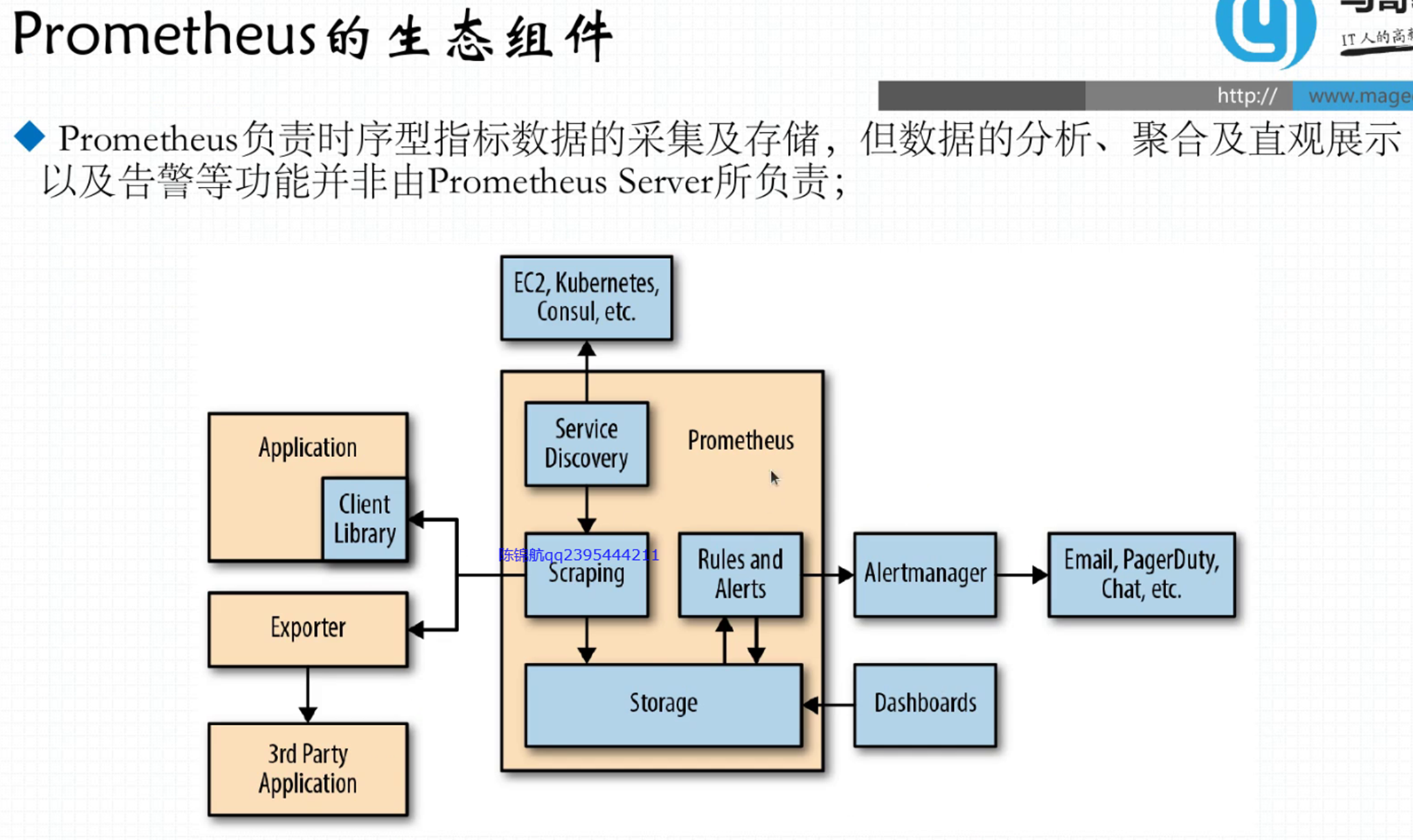
37. Prometheus

Prometheus的时序数据库默认保存时长有时限(好像是一个月),如果想要保存更久的时间,需要使用其他时序数据库InfluxDB


37.1. 组件介绍

37.2. 数据模型

37.3. 指标类型

37.4. 作业(job)和实例(Instance)
Instance:接入的地址:端口
job:所属job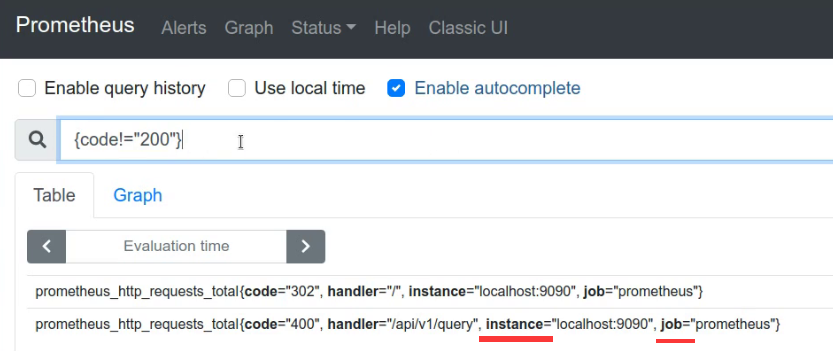
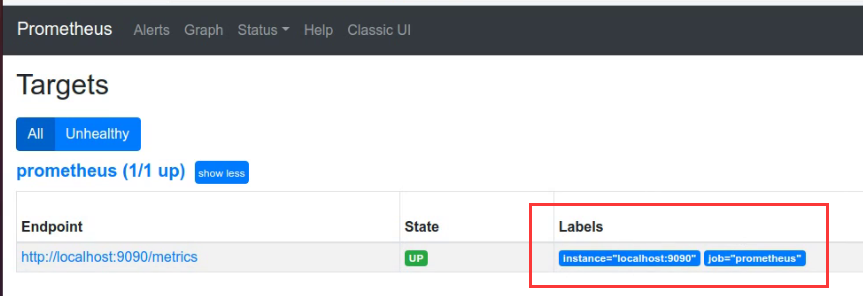

37.5. Prometheus配置
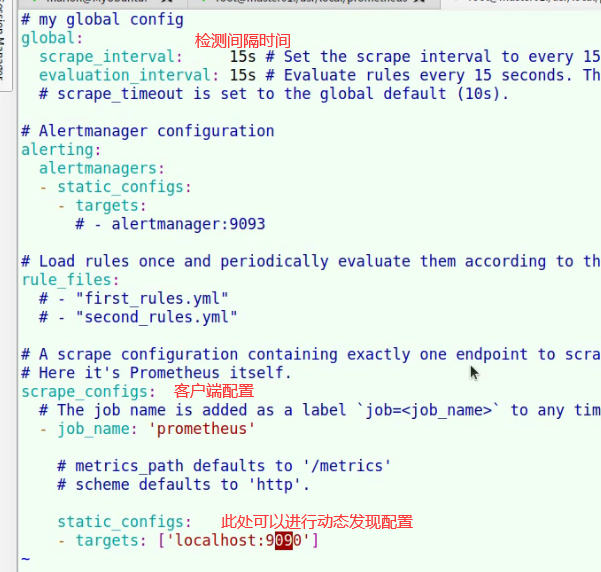

37.6. 动态发现节点服务发现
target
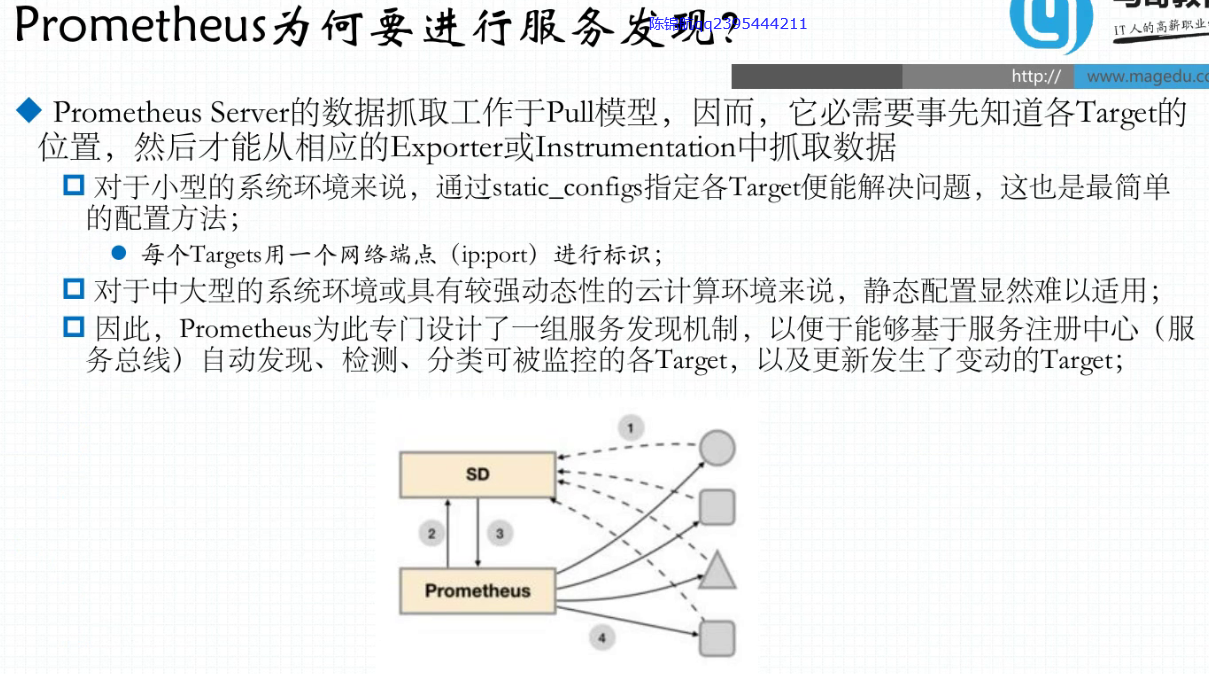
37.7. 指标抓取的生命周期

37.8. 可集成的服务发现机制

37.8.1. 基于文件的服务发现
Prometheus持续的监控着该文件,每隔一段时间当检测的到文件修改,会重载配置,就不需要重启Prometheus


37.8.2. 基于DNS的服务发现
对nds域名进行持续检测,
依赖于DNS的SRV资源记录

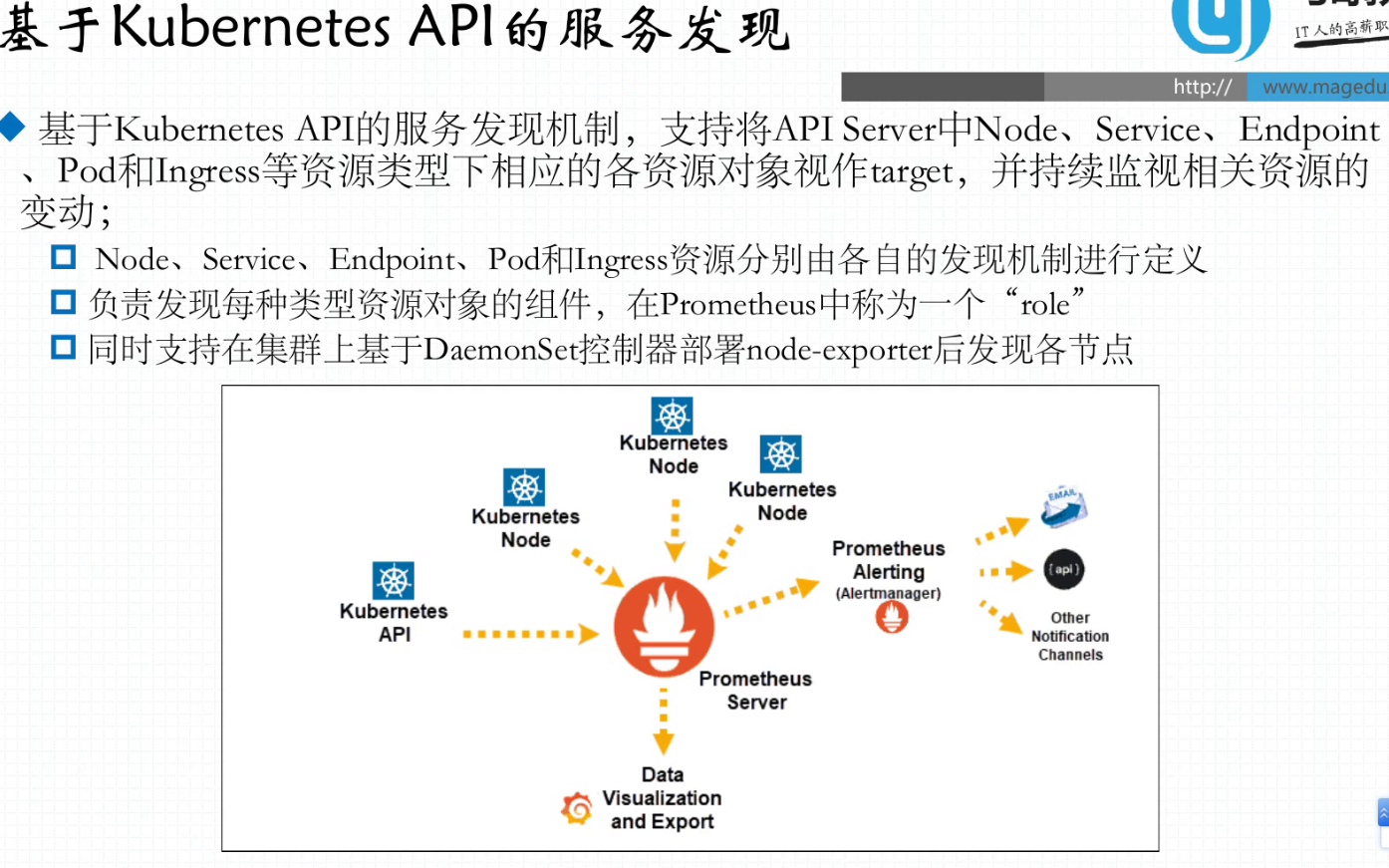
37.8.3. 基于kubernetes API的服务发现
基于kubernetes API的服务发现,将api server中node、service、Endpoint、Pod、Ingress等资源类型下相应的资源对象视作target
使用DaemonSet控制部署node-exporter发现各节点,node-exporter比kubelet监控更加丰富











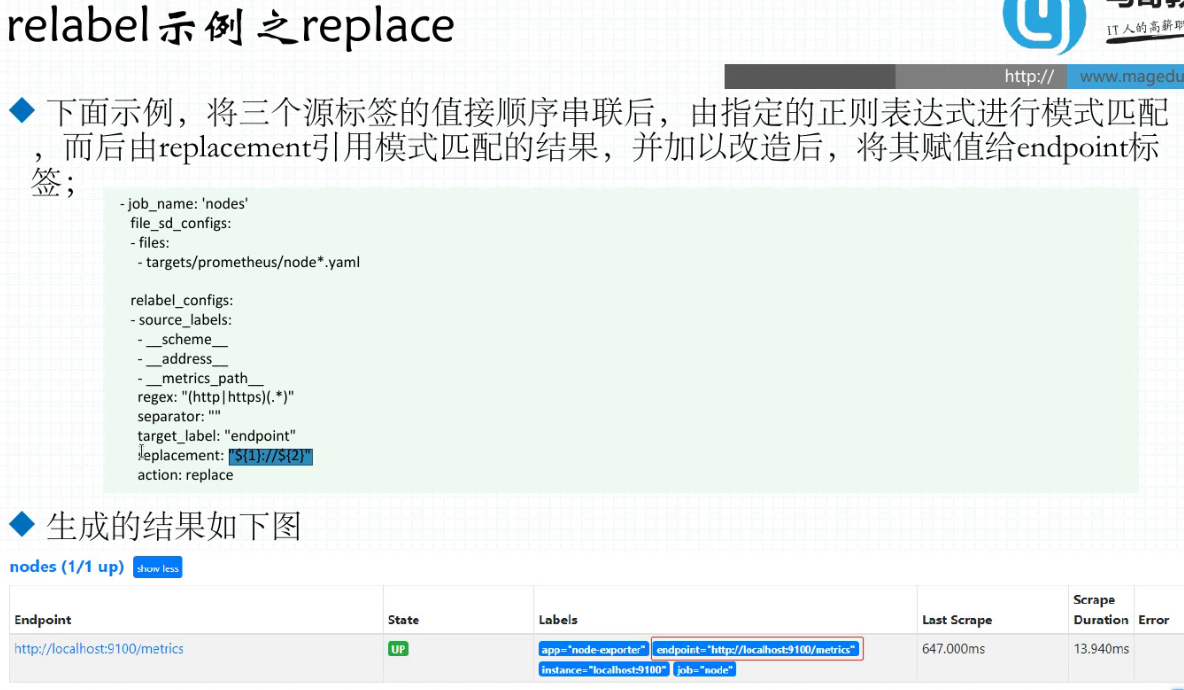
37.9. 对target重新打标

定义在relabel_config中


配置示例
37.10. 样本数据格式

37.11. promQL的数据类型

37.12. 向量
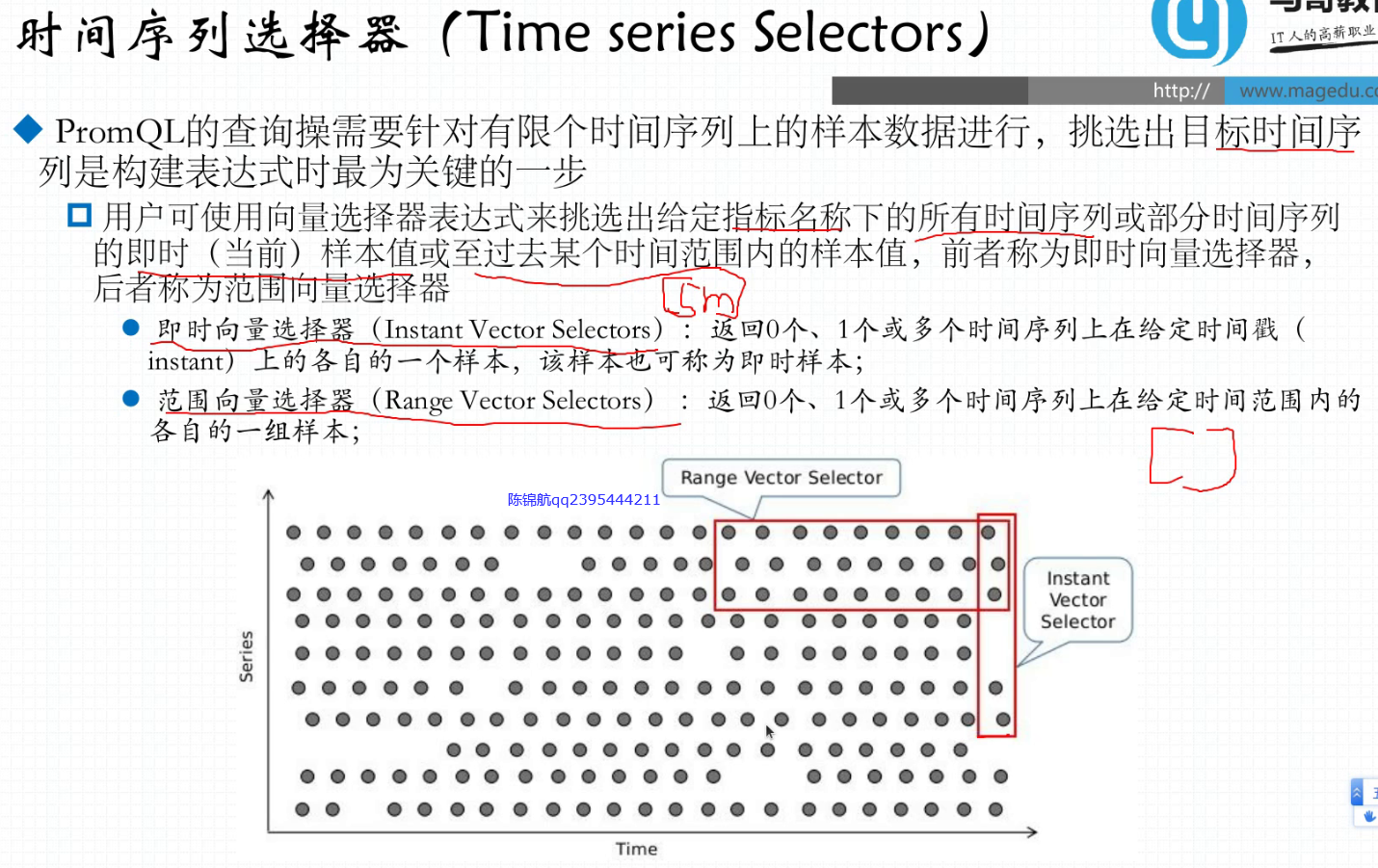
37.12.1. 时间序列选择器
即时向量选择器:一段时间范围内
范围向量选择器:时间序列范围内的数据样本
37.12.2. 向量表达式使用要点

37.13. alterManager
37.13.1. alertmanager去重、分组、抑制、静默、路由

37.13.2. alertmanager配置
Prometheus配置alertmanager
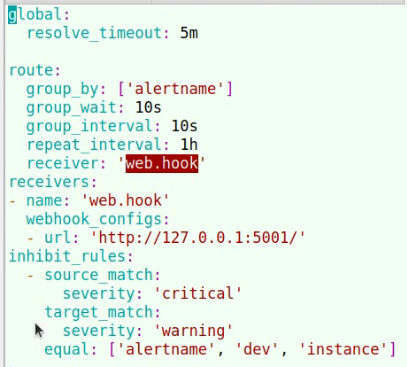
alertmanager配置邮件

37.13.3. 告警规则配置
Prometheus指向alertmanager,Prometheus定义好告警规则


37.14. alert告警路由



37.15. Prometheus监控kubernetes
配置k8s的toke和ca证书
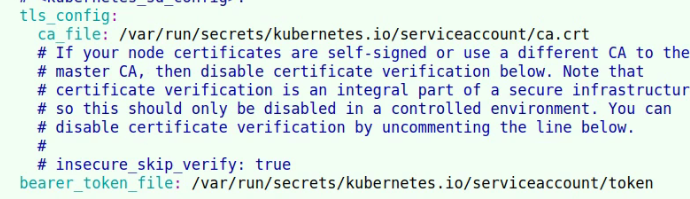
从k8s API获取指标数据
https://kubernetes.default.svc:443/api/v1/nodes/node01/proxy/metrics

对pod抓取
pod
prometheus.io/scrape: true/false
__meta_kubernetes_pod_annotation_prometheus_io_scrape = true|false
__meta_kubernetes_pod_annotation_prometheus_io_path = /metrics
__meta_kubernetes_pod_annotation_prometheus_io_port = 80
http://10.244.1.6:80/metrics
38. ELK

日志收集:
logstash:java ruby语言体量非常大
filebeat:较小的内存就能完成,轻巧便捷、适配能力弱
beats:较小的内存就能完成,轻巧便捷、适配能力弱
filebeat、beats —> logstash —> ElasticSearch
filebeat、beats数据发送到logstash,logstash利用自己的转换功能,将信息输出到ElasticSearch
上面这种结构弊端:
如果日志量请求非常大,一个logstash可能难以完成所有的转换,导致大量的阻塞和数据请求被丢弃
解决方案:
filebeat 到logstash中增加redis、kafka,logstash从kafak读取数据,数据来不及处理,放kafka中缓冲一会,在数据低估期间逐渐处理完成
38.1. NoSQL存储系统基础与ElasticSearch

38.1.1. ElasticSearch分片
ElasticSearch把logs index索引,切成多个分片(shard),每一个分片就是一个独立而完整的索引,
正常是一个完整数据,把数据集组织为多个分片,而每个分片都是一个完整的索引,每一个索引都有一个节点来存储和使用。
默认分成5个片(shard)
分片的主从:
Primary Shard 主分片
Replicas Shard 副本分片
38.1.2. ElasticSearch端口
9300 Cluster Peer集群内部通信
9200 Client API 客户端连接
38.2. ElasticSearch index内部结构
index:Database(独立数据库存很多类型的数据)
Type:Table 把数据分到不同的Type中
Document:Row 数据存放
38.3. ES搜索引擎


38.4. ES状态接口获取ES集群状态
获取ElasticSearch集群状态信息
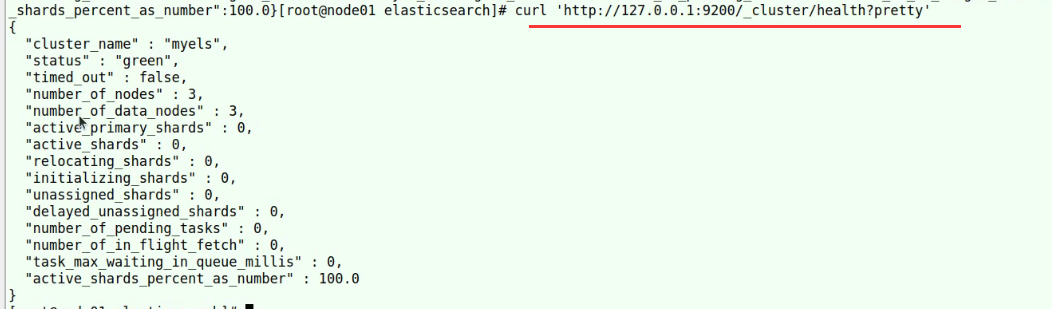
status:red有个索引的主分片副分片异常,yellow有副本残缺
number_of_nodes:集群节点数量
number_of_data_nodes:集群数据节点数量
active_primary_shards:活动的主分片数量
active_shards:活动的分片数量
relocating_shars:迁移分片数量
initializing_shards:正在初始化分片,一般是刚创建的分片
unassigned_shards:已经在集群中的分片,但在集群中又找不到
delayed_unassigned_shards:延迟未分配的分片
number_of_pending_tasks:处于挂起状态的任务数
number_of_in_flight_fetch:处于快速存取的
单个节点信息
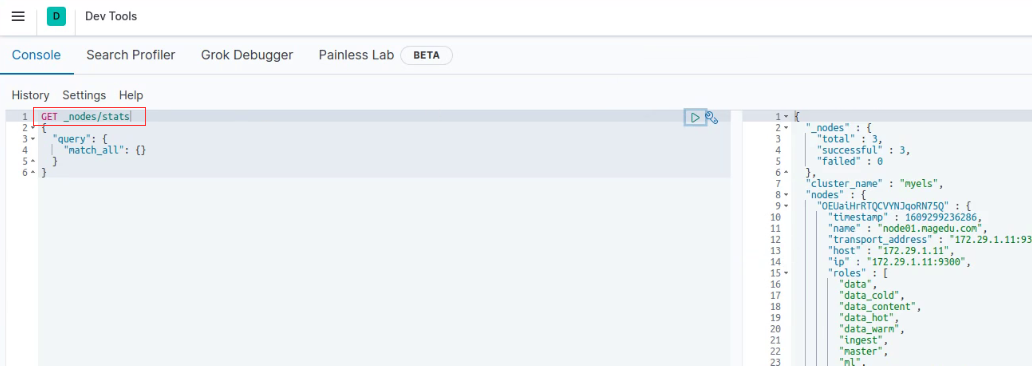
还包括了jvm数据信息
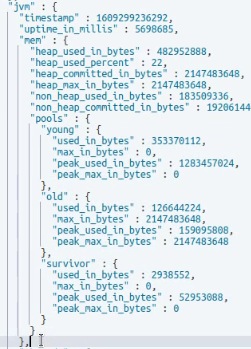
集群状态信息
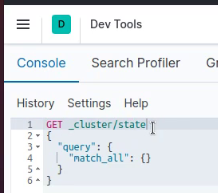
获取集群数据index信息
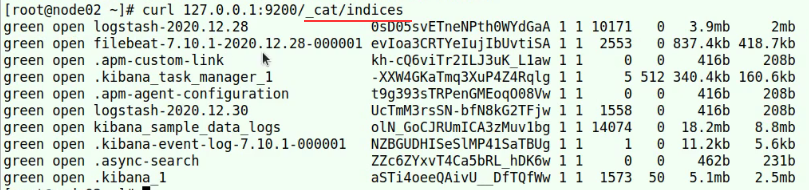
每个索引状态信息
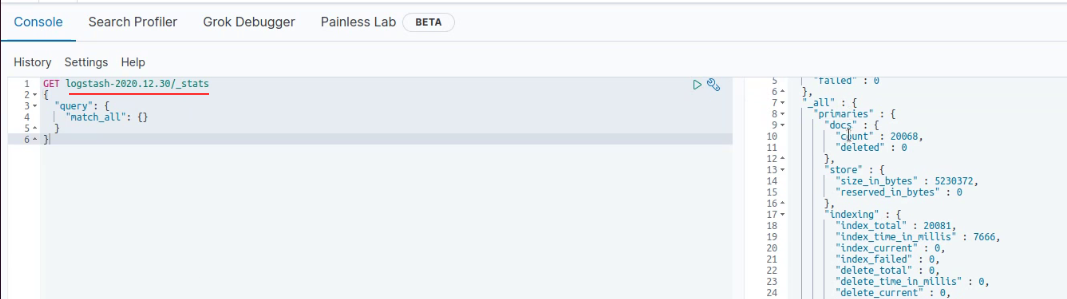
汇总出来的所有索引的信息,和每个索引的信息

38.5. logstash
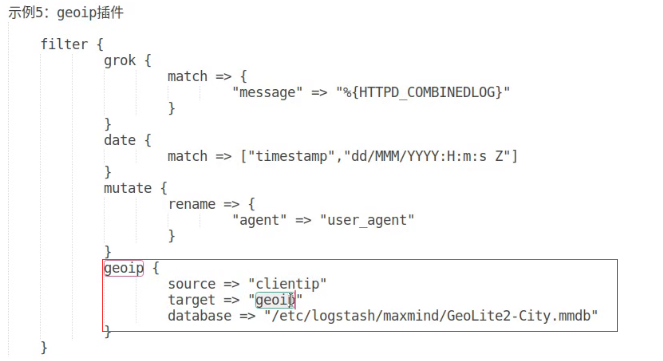
grok插件
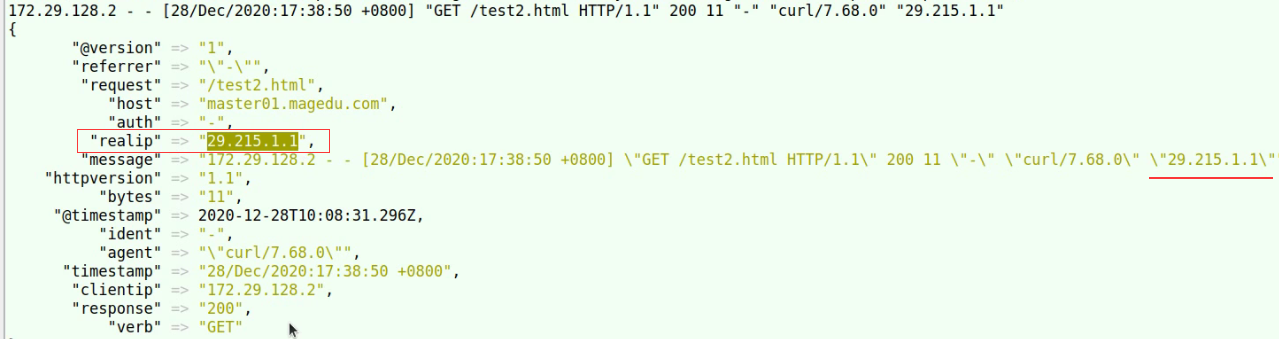
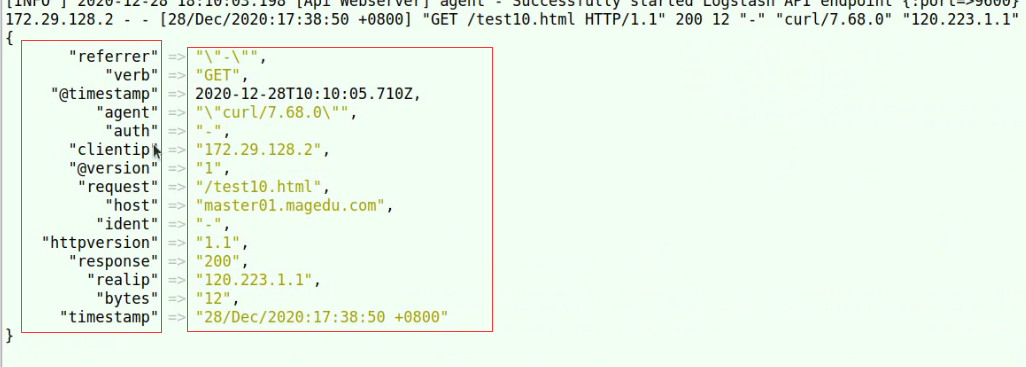
能把客户端送了的信息,所有的字段,基于内建的模式做文档化
文档化完成后删除message,自动完成匹配后给每个字段加上key

rename
修改字段名称

geoip
基于mmdb的数据库,识别客户端的ip属于哪个地区,保存到geoip字段中
修改key的名称

将message的内容,自动完成匹配后给每个字段加上key
date match 修改时间的格式
rename 修改key的名字修改字段名字
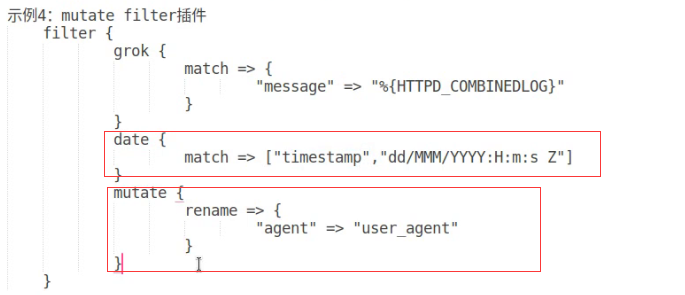
geopip mmdb
geopip找到存有ip地址的字段—>clientip,将ip地址抽取出来转换成地理位置信息,将转换后的结构存放的geoip当中
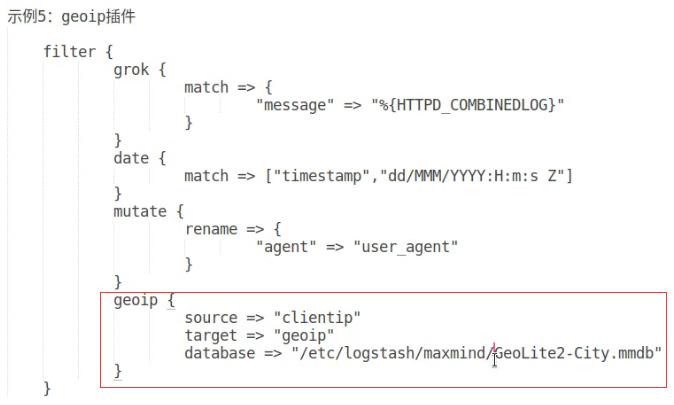
geoip结果
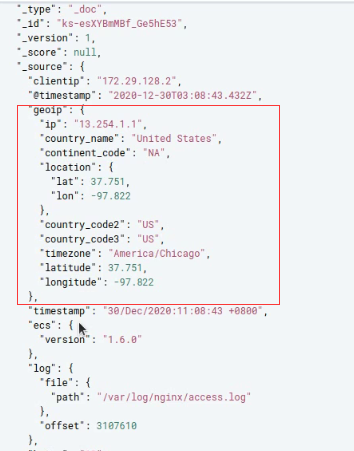
38.6. nginx日志json格式
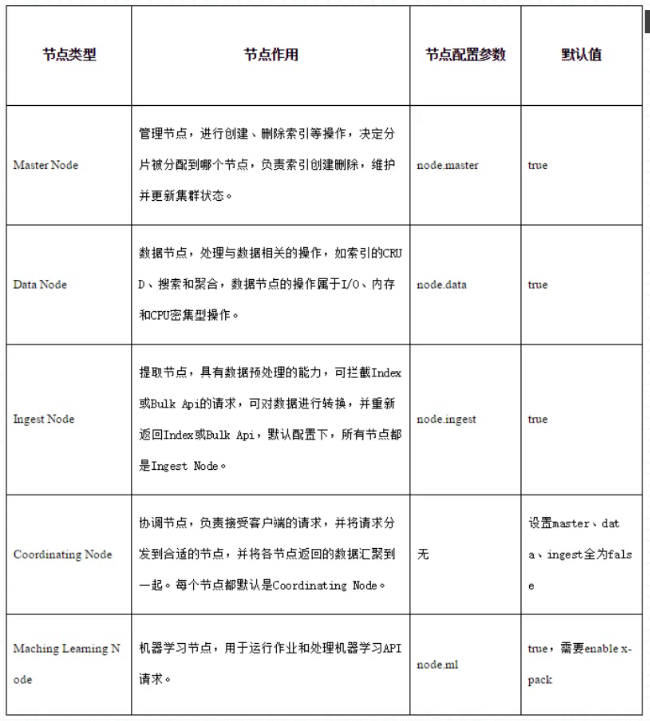
38.7. ElasticSearch节点类型节点作用
38.8. ES的重要配置参数
gateway.recover_after_nodes
集群中的节点至少恢复了3个,才开始数据恢复,否则不启动数据恢复,只是要等待其他节点启动
gateway.recover_after_time
等待超时时间
gateway.expected_nodes
期望节点数量

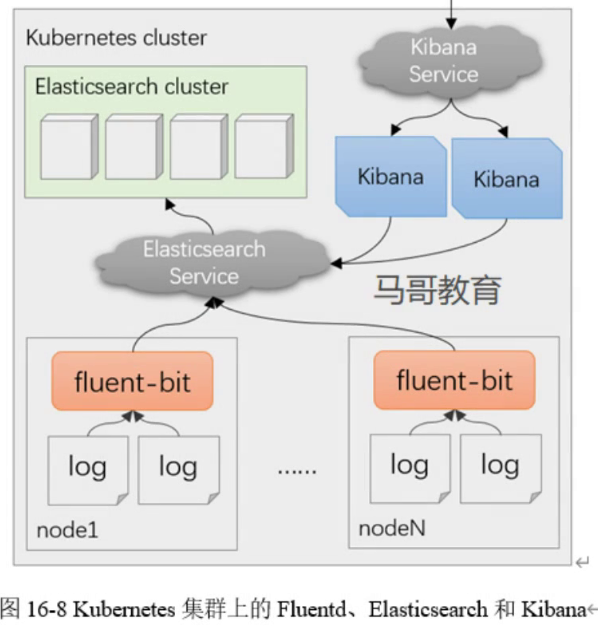
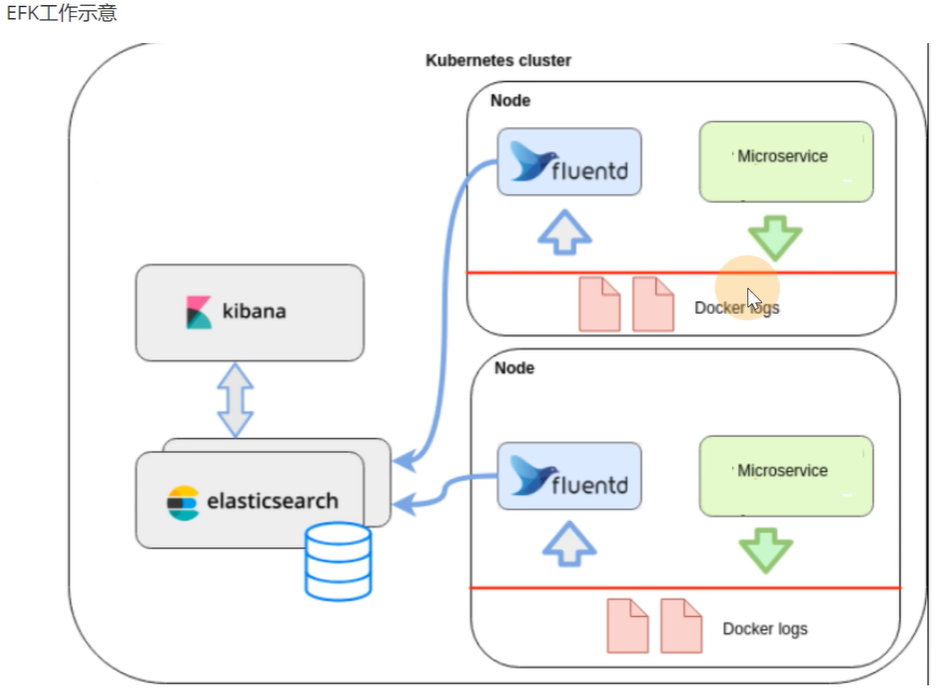
39. k8s部署ELK Fluent-bit
架构模式
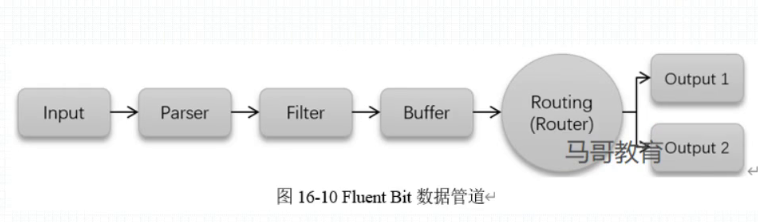
39.1. Fluent-bit数据管道
input:指定的文件进行收集
parser:做分析
Filter:过滤、移除不需要的项
output:输出
39.2. Fluent-bit配置
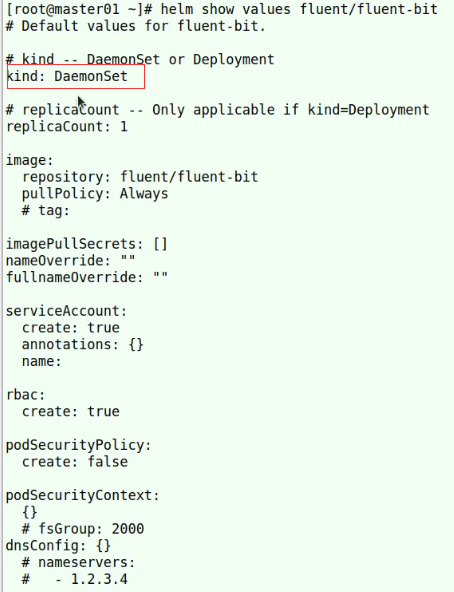
# kind -- DaemonSet or Deployment
kind: DaemonSet
image:
repository: fluent/fluent-bit
pullPolicy: IfNotPresent
service:
type: ClusterIP
port: 2020
annotations:
prometheus.io/path: "/api/v1/metrics/prometheus"
prometheus.io/port: "2020"
prometheus.io/scrape: "true"
resources: {}
# limits:
# cpu: 100m
# memory: 128Mi
#requests:
# cpu: 100m
# memory: 128Mi
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
config:
service: |
[SERVICE]
Flush 3
Daemon Off
#Log_Level info
Log_Level debug
Parsers_File custom_parsers.conf
Parsers_File parsers.conf #分析器配置文件
HTTP_Server On
HTTP_Listen 0.0.0.0 #监听地址
HTTP_Port 2020
inputs: |
[INPUT]
Name tail
Path /var/log/containers/*.log #读取哪些文件
Parser cri
Tag kube.*
Mem_Buf_Limit 5MB #数据缓冲空间大小
Skip_Long_Lines On #跳过特别长的日志
Refresh_Interval 10
[INPUT]
Name systemd
Tag host.*
Systemd_Filter _SYSTEMD_UNIT=kubelet.service
Systemd_Filter _SYSTEMD_UNIT=docker.service
Systemd_Filter _SYSTEMD_UNIT=node-problem-detector.service
Read_From_Tail On
filters: |
[FILTER]
Name kubernetes
Match kube.* #标签匹配
Kube_URL https://kubernetes.default.svc:443 #apiserver访问入口
Kube_CA_File /var/run/secrets/kubernetes.io/serviceaccount/ca.crt #加载证书
Kube_Token_File /var/run/secrets/kubernetes.io/serviceaccount/token
Kube_Tag_Prefix kube.var.log.containers.
Merge_Log On #日志合并功能
Merge_Parser catchall
Keep_Log Off #将日志合并后就不保留原有字段
K8S-Logging.Parser On #打开k8s内置的日志分析器,对日志分析完后,对相应字段加上key
K8S-Logging.Exclude On #pod通过注解排除日志
outputs: |
[OUTPUT]
Name es
Match kube.* #匹配的标签
Host es-elasticsearch-coordinating-only.logging.svc.cluster.local.
Logstash_Format On
Logstash_Prefix k8s-cluster
Type flb_type
Replace_Dots On
[OUTPUT]
Name es
Match host.*
Host es-elasticsearch-coordinating-only.logging.svc.cluster.local.
Logstash_Format On
Logstash_Prefix k8s-node
Type flb_type
Replace_Dots On
customParsers: |
[PARSER] #为日志加上时间
Name docker_no_time #分析器名称
Format json
Time_Keep Off
Time_Key time
Time_Format %Y-%m-%dT%H:%M:%S.%L
[PARSER]
Name ingress-nginx #分析器
Format regex #
Regex ^(?<message>(?<remote>[^ ]*) - (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*) "(?<referer>[^\"]*)" "(?<agent>[^\"]*)" (?<request_length>[^ ]*) (?<request_time>[^ ]*) \[(?<proxy_upstream_name>[^ ]*)\] \[(?<proxy_alternative_upstream_name>[^ ]*)\] (?<upstream_addr>[^ ]*) (?<upstream_response_length>[^ ]*) (?<upstream_response_time>[^ ]*) (?<upstream_status>[^ ]*) (?<req_id>[^ ]*).*)$
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
[PARSER]
Name catchall
Format regex
Regex ^(?<message>.*)$
容器中的日志
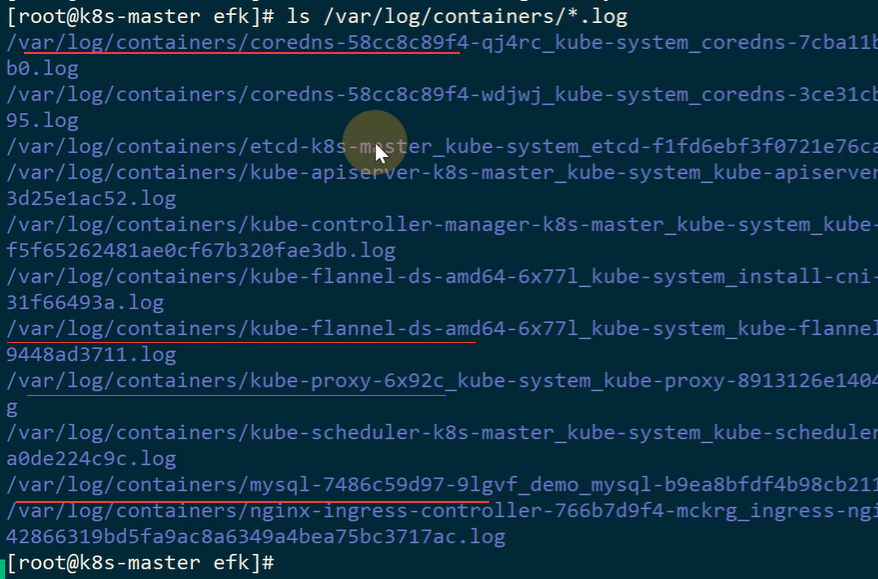

39.3. Fluent-bit部署
40. jenkins

40.1. 多分支流水线

40.2. pipeline是什么

40.3. pipeline语法初步脚本式声明式

40.3.1. pipeline语法组成

40.4. pipeline编辑器特性

40.5. pipeline脚本式基础及代码示例

40.6. 回放功能


40.7. pipeline声明式的结构








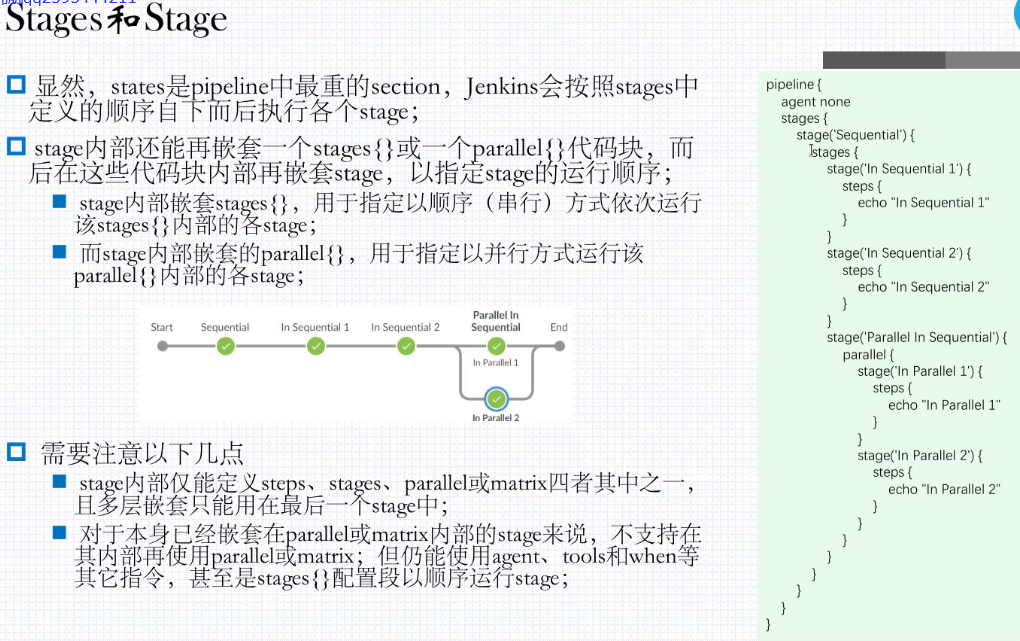
40.8. maven简介


40.9. golang构建环境

40.10. python构建环境方法一

40.11. python构建环境方法二
40.12. 触发任务
自动化的pipeline会按照一定的规则自动启动并运行,这类的规则便是所谓的触发条件;
触发的常用方法有如下三种
对于pipeline风格的任务来说,在web界面中就可以指定触发条件;
对于脚本式pipeline,可以在代码顶部指定一个properties代码块来定义触发条件;
该方式定义的触发条件将会和Web界面中定义的触发条件合并处理,并且Web界面上定义的条件优先生效;
对于声明式pipeline,可将触发条件定义在triggers{}指令定义的配置段中;
triggers内置支持cron、pollSCM和upstream三种触发机制;
其它触发机制可借助于插件来实现,例如基于代码仓库上webhook通知的触发等;
注意:上述方法并不适用于多分支pipeline、Github组织等类型的项目的触发,这些类型的任务都需要有相应的Jenkinsfile进行标识;
40.13. 周期性构建
这是一种cron类型的构建机制,它按照预定义的时间周期启动任务;
对于期望能够基于代码变更进行触的CI场景来说,周期性构建并非其最佳选项,但对于有些类型的任务,它却也能够通过精心编排的周期性构建来避免资源冲突;
Jenkins cron语法遵循Unix cron语法的定义,但在细节上略有差别;
一项cron的定义包含由空白字符或Tab分隔的5个字段,用于定义周期性的时间点;

Jenkins cron还可以使用以下特定字符,一次性指定多个值
specifies all valid values
M-N specifies a range of values
uM-N/X or /X steps by intervals of X through the specified range or whole valid range(以X为步长)
A,B,…,Z enumerates multiple values(逗号分隔的枚举值)
此外,H也可用于任何字段,它能够在一个时间范围内对项目名称进行散列值计算出一个唯一的偏移量,以避免所有配置相同cron值的项目在同一时间启动;
例如triggers { cron(H(0,30) ) }
40.13.1. cron构建示例

40.14. pollSCM 轮询SCM 轮询检查代码仓库是否有变更
轮询SCM指的是定期到代码仓库检查代码是否有变更,存在代码变更时就运行pipeline;
为了能够从CI中得到更多的收益,轮询操作越频繁越好;
显然,这种需求下的触发由SCM负责通知Jenkins最为理想,以避免给SCM带去无谓的压力;但在外部的SCM无法通知到局域网中的Jenkins时,倒也不失为一种选择;

40.15. upstream:由上游任务触发
若job-x依赖于job-y的执行结果,则称为job-y为job-x的upstream(上游);
Jenkins自2.22版本开始支持在triggers中定义upstream类型的触发条件;
前任务依赖到的upstream任务定义在upstreamProjects参数中,多个任务彼此间以逗号分隔;
触发条件为upstream的执行状态,它定义在threshold参数中,其值为hudson.model.Result.
Hudson.model.Result支持以下取值
ABORTED:任务被中止
FAILURE:构建失败
SUCCESS:构建成功
UNSTABLE:不稳定,即存在失败的步骤,但尚未导致失败;
NOT_BUILT:多阶段构建场景中,因前面阶段的问题导致后面的阶段无法执行;

40.16. gilab通知触发
GitLab通知触发,是指pipeline关联的GitLab Repository上的代码出现变更时,由GitLab将相关事件通知给Jenkins,从而触发Jenkins执行构建操作;
避免了pollSCM的频繁轮询依然存在滞后可能性的问题;
依赖于GibLab插件和Git插件;
40.16.1. 整合GitLab和Jenkins
配置要点
前提:GitLab和Jenkins同在本地网络时,需要以管理员权限设置“外发请求”,启用“允许Webhook和服务对本地网络的请求”;
授予Jenkins访问GitLab上仓库中特定用户的代码权限;
uJenkins基于SSH协议获取代码仓库中的内容,因而需要事先配置Jenkins能基于SSH密钥接入GitLab;
GitLab API访问授权
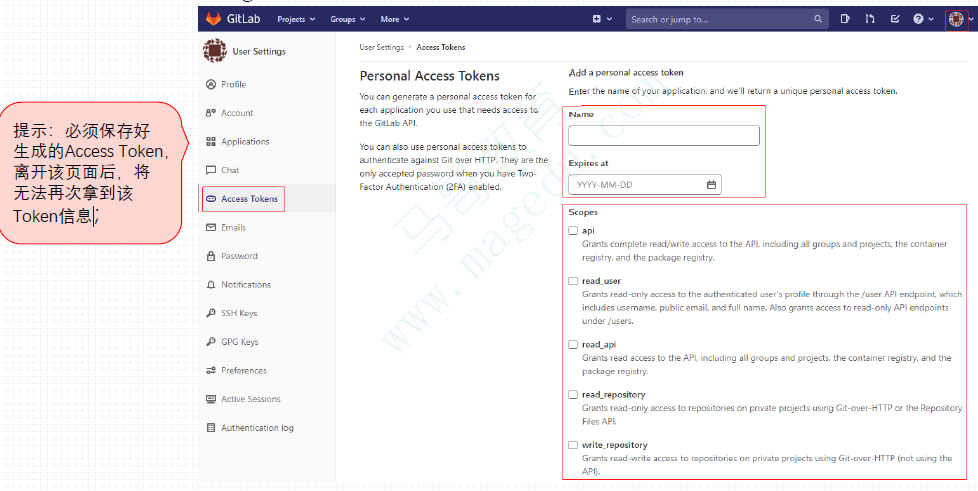
配置GitLab API访问认证(Access Token)及操作权限;
配置Jenkins启用/project端点认证,配置它能通过配置的Access Token接入GitLab API;
Jenkins pipeline项目的通知授权
创建pipeline任务,选择使用的“GitLabConnection”,并选定使用“Build when a change is pushed to GitLab.”触发器;
而后为构建触发器生成Secret token;
配置GitLab Repository能通过Webhook,基于该Secret Token触发构建;
具体配置过程相关文档
https://docs.gitlab.com/ce/integration/jenkins.html
40.16.2. 配置GitLab允许外发
以GitLab管理员的身份,设置系统在外发请求中,允许Webhook和服务对本地网络的请求;

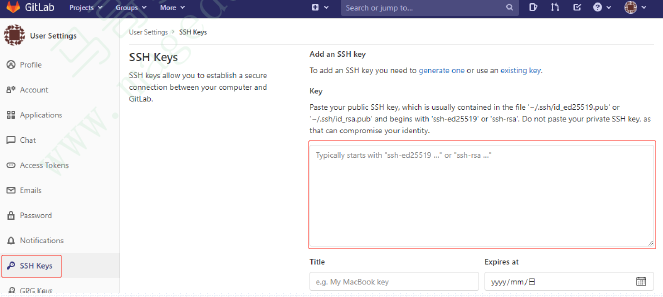
40.16.3. 为GitLab用户添加SSH公钥
生成SSH密钥对,将公钥保存于GitLab用户账号之上,以使得git或jenkins等客户端能使用匹配的私钥认证到GitLab服务上;
可在Jenkins Server上以jenkins用户的身份生成;
~# usermod-s /bin/bash jenkins
~# su-jenkins
~# ssh-keygen -t ed25519 -C ““ 或者
~# ssh-keygen -t rsa -b 2048 -C “email@magedu.com”
复制公钥文件的内容,贴在
GitLab上的用户账号配置
属性中;
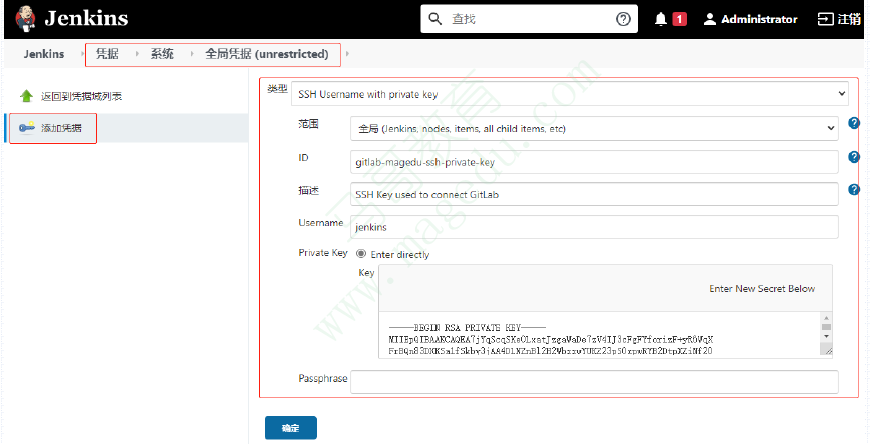
40.16.4. 在Jenkins上通过凭证添加SSH私钥以认证到GitLab
复制SSH密钥对儿的私钥信息,保存为Jenkins上的凭据;
40.16.5. 在GitLab上创建创建Access Token
User Account —> Settings —> Access Tokens
40.16.6. 在Jenkins上授权启用/project端点以创建GitLab连接
Manage Jenkins —> Manage Plugins
安装GitLab插件;
Manage Jenkins —> Configure System
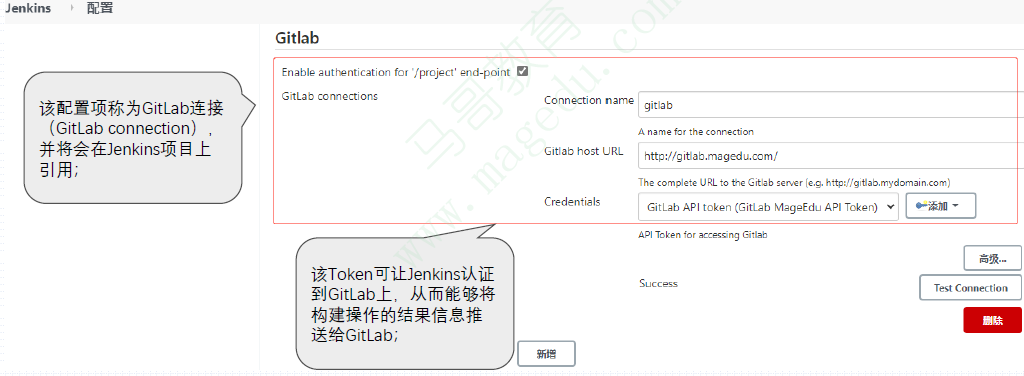
40.16.7. 配置Jenkins项目可经由GitLab上的事件触发
首先,在Jenkins的pipeline和freestyle类型的项目上,选择使用的GitLabconnection;
接着,选中Build when a change is pushed to GitLab,并按需勾选允许的触发事件
而后,还应该配置如何通知给GitLab;
Freestyle项目可以选择通过
Post-build Actions指定;
Pipeline项目只能通过pipeline代码指定,下面是一个简单示例;
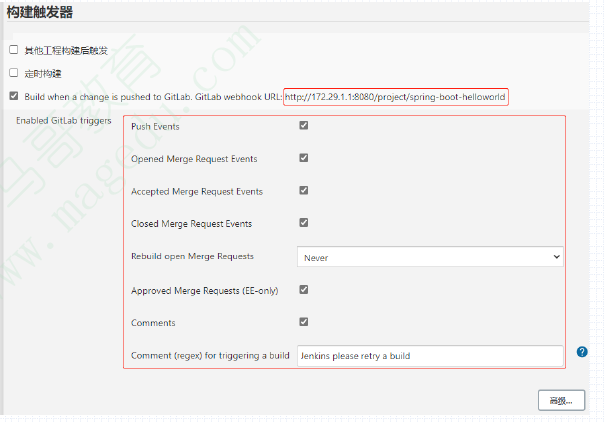
配置Jenkins项目可经由GitLab上的事件触发(2)
接下来,点击如前页图中的高级按钮,在Jenkins项目的上生成Secret Token,该Token将被GitLab用作触发时的认证信息;
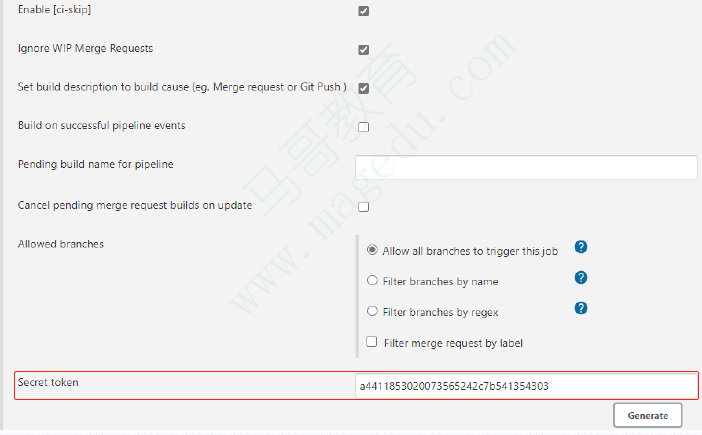
40.16.8. 配置Jenkins项目对应的GitLab上的代码仓库
在GitLab上对应代码仓库的配置菜单上,Settings —> Webhooks
创建一个Webhook,指向前面配置的Jenkins项目及其相应的Secret Token

40.16.9. 在Pipeline中实现GitLab trigger
对于如上步骤中需要手动操作的部分,同样也能够在Jenkinsfile中直接实现,如右侧的代码所示;
triggerOnPush:GitLab触发push事件时是否执行构建;
triggerOnMergeRequest:GitLab触发mergeRequest事件时,是否执行构建;
branchFilterType:只有符合条件的分支才会被触发;必选配置,否则将无法实现触发,支持如下值;
NameBaseFilter:基于分支名进行过滤,多个分支名彼此间以逗号分隔;
RegexBaseFilter:基于正则表达式模式对分支名过滤;
All:所有分支都会被触发;
includeBranchSpec:基于branchFilterType值,输入期望包括的分支的规则;
excludeBranchSpec:基于branchFilterType值,输入期望排队的分支的规则
更详细的配置参数请参考GitLab-Plugin项目的描述
https://github.com/jenkinsci/gitlab-plugin

40.17. 凭证的作用域和Provider
凭证的作用域决定了它可用的目标范围;
系统:作用于Jenkins系统自身,仅可用于系统和后台任务,且一般用于连接到agent节点之上;
全局:作用于Jenkins上的所有任务,以确保任务的正常执行;
用户:作用于用户级别,仅生效于Jenkins中的线程代表该用户进行身份验证之时;
凭证提供者(Provider)
凭证Provider是指能够存储和获取凭证的地方,它可以Jenkins内部的凭证存储,也可以是外部的凭证库
Jenkins共支持如下几个凭证Provider
系统凭证Provider:支持系统和全局两个作用域的凭证;
用户凭证Provider:用户凭证的存储机制,且每个用户仅能看到自己的凭证;
文件夹凭证Provider:文件夹凭证存储,可作用于该文件夹及其子文件夹;
Blue Ocean凭证插件:作用于Blue Ocean接口,以及通过该接口创建或访问的项目;
40.18. 在Pipeline中使用凭证
有时候,我们需要在Pipeline中为steps提供凭证,以完成steps中必要的操作步骤;
在steps中使用凭证,依赖于Credential BindingPlugin,该插件由Jenkins自行部署;
在Pipeline中,要使用withCredentials( ){ //code}来引用凭证,需要认证到特定系统的操作则定义在{}中;
sername with password
withCredentials([usernamePassword(credentialsID: ‘‘,
passwordVariable: ‘‘,
usernameVariable: ‘‘)])
其中,无论用户名和密码使用变量名可自行指定,而后,Jenkins都会通过credentialsID从指定的凭证填充用户名和密码;
下面是一个简单的示例;
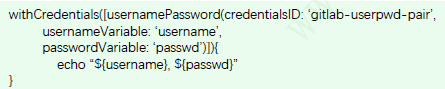
在Pipeline中,要使用withCredentials( )来引用凭证;
SSH密钥
withCredentials([sshUserPrivateKey(credentialsId: ‘,
keyFileVariable: ‘MYKEYFILE,
passphraseVariable: ‘PASSPHRASE,
usernameVariable: ‘USERNAME’)])
{ // some block }
另外,若安装了SSHAgent Plugin,还可以使用sshagent([]) { }代码块;

40.19. 参数化pipeline的常用参数
声明式Pipeline中,parameters指令用于为Pipeline声明参数;该指令用于pipeline{}之中,且常见于agent指令之后;
可用参数有如下这些
name 参数名称
defaultValue 默认值
description 描述信息
string
A parameter of a string type, for example: parameters { string(name: ‘DEPLOY_ENV’, defaultValue: ‘staging’, description: ‘ ‘) }
text
A text parameter, which can contain multiple lines, for example: parameters { text(name: ‘DEPLOY_TEXT’, defaultValue: ‘One\nTwo\nThree\n’, description: ‘ ‘) }
booleanParam 布尔型
A booleanparameter, for example: parameters { booleanParam(name: ‘DEBUG_BUILD’, defaultValue: true, description: ‘ ) }
值传递也是string类型;
choice 选择型 单选
A choice parameter, for example: parameters { choice(name: ‘CHOICES’, choices: [‘one’, ‘two’, ‘three’], description: ‘ ‘) }
password 密码 不会显示出来
A password parameter, for example: parameters { password(name: ‘PASSWORD’, defaultValue: ‘SECRET’, description: ‘A secret password’) }
40.19.1. 使用示例:string类型的参数
string方法默认用于定义一个字符串类型的参数,它接收三个参数
name:参数名;
defaultValue:默认值;
description:参数的描述信息;
传入的参数会放在一个名为params的对象中,该参数可以在pipeline中引用;例如下面的示例中,params.userRole就是对引用了名为userRole的参数;

多参数

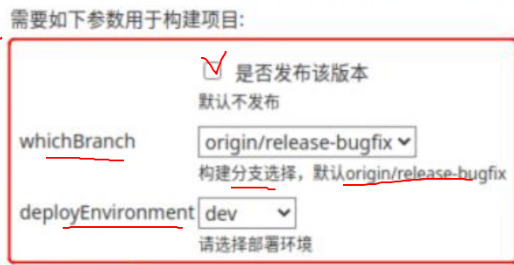
40.20. input步骤
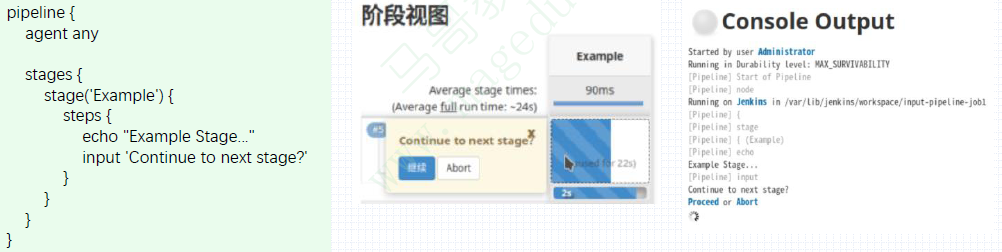
input步骤是Pipeline与用户交互的接口,用于实现根据用户输入改变pipeline的行为;
遇到input步骤时,Pipeline会暂停下来并等待用户的响应;
input步骤是特殊的参数化pipeline的方法,它常用于实现简易的审批流程,或者是手动实施后续的步骤等;
为了接收用户输入的不同数据,Jenkins提供了不同类型的参数;
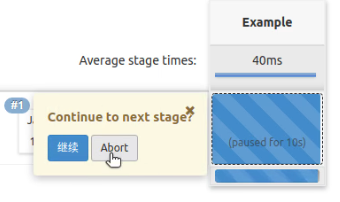
input步骤默认打印出的表单是打印一条消息并为用户提供一个选择:Proceed或者Abort;
执行中途,进行选择参数
input步骤的参数
input步骤的可用参数
message,String类型;
其内容将打印给用户,并要求用户选择Proceed或Abort;
若input仅提供了该参数时,还可以省略message参数名称;
id (optional),String类型;
每个input都有一个惟一的ID标识,用于生成专用的URL,以便于根据用户输入继续或中止pipeline;
/job/[job_name]/[build_id]/input/[input_id]/
该URL可通过POST方法进行请求,后跟proceedEmpty表示空输入并继续,而abort则表示中止;
未定义时,Jenkins将自动为input生成ID;
ok (optional),String类型;
用于自定义Proceed按钮的标签名称;例如,下面的示例中,Proceed按钮的名称为Yes
input message: ‘‘, ok: ‘Yes’
parameters (optional)
要求用户手动输入一个或多个参数列表;
pipeline中,parameters指令支持的参数类型仅是input步骤支持的参数类型的一个子集,因而,那些参数类型都会被input步骤所支持;
submitter (optional),String类型;
可以进行后续操作的用户的ID或用户组列表,彼此间以逗号分隔,且前后不允许出现空格;
submitterParameter(optional),String类型;
用于保存input步骤的实际操作者的用户名;
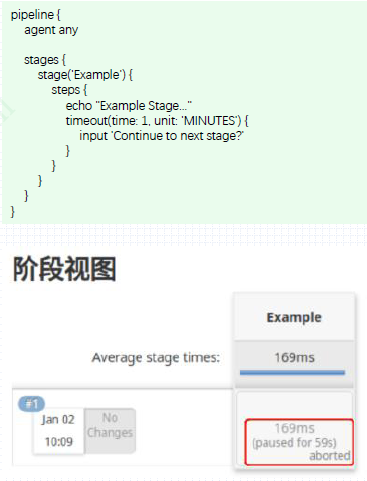
输入等待超时
input步骤与timeout步骤协同使用,可实现超时自动中止pipeline,以避免无限等待;
timeout(time, activity, unit) {}
time: The length of time for which this step will wait before cancelling the nested block. 整型数据
activity (optional):Timeout after no activity in logs for this block instead of absolute duration. 布尔型数据
unit (optional):The unit of the time parameter. Defaults to ‘MINUTES’ if not specified.
Values: NANOSECONDS, MICROSECONDS, MILLISECONDS, SECONDS, MINUTES, HOURS, DAYS
右侧的示例中,为input步骤指定了1分钟的等待时长;
生产中,发布操作的等待时长通常可能会具有更长的时间,例如1小时等
40.21. 多分支流水线概述
- 多分支(multi-branch)流水线是基于git分支创建Jenkins pipeline的机制,它可以自动在SCM中发现新分支,并自动为新分支创建pipeline;
- 不期望出现在pipeline中的分支需要通过排除机制予以排除在外;
- Jenkins的多分支流水线项目类型支持Github、GitLab和Bitbucket等;
- 多分支pipeline基于PR(pull request)进行分支发现;
- 有人从branch中执行PR操作时,Pipeline会自动发现分支;
- PR上升将自动触发构建操作
多分支和pipeline
右图示例中的仓库共有master、develop和feature三个分支
三个分支分别有其不同的pipeline
master分支有完整的CI/CDpipeline
develop分支仅有CI pipeline
feature分支仅有单元测试的功能
Jenkins Server会自动从仓库中发现所有分支,并提取每个分支,而后根据Jenkinsfile运行pipeline;
之后,每当git仓库上的任何分支发生新的代码变更时,Jenkins Server将自动触发相应的pipeline
多分支pipeline的简要工作逻辑
基于Feature、Develop和Master分支构建内部研发工作逻辑是较为常见的工作流模型
Developer通过具体的feature分支开发新的功能,并向feature提交代码;
每当开发人员从feature分支提PR至develop分支时,Jenkins pipeline都应触发以运行单元测试和静态代码分析;
feature分支中的代码测试成功后,开发人员将PR合并到develop分支;
在将要发布代码时,开发人员将PR从develop分支提到master,此时将触发Jenkins上的pipeline运行单元测试、代码分析等,并将代码部署到dev/QA环境;
when指令
- when指令用于在pipeline中为stage添加自定义的执行条件
- when指令必须包含至少一个条件,多个条件间为与逻辑,即所有的子条件必须返回True,stage才能执行;
- 支持使用not、allOf和anyOf来构建更复杂的条件结构;
内置条件
配置Jenkins的邮件通知功能
Jenkins管理员的邮箱地址在Jenkins Location系统配置段中的定义
该邮箱地址将为作为发给项目owner的通知邮件的发件人地址(From)
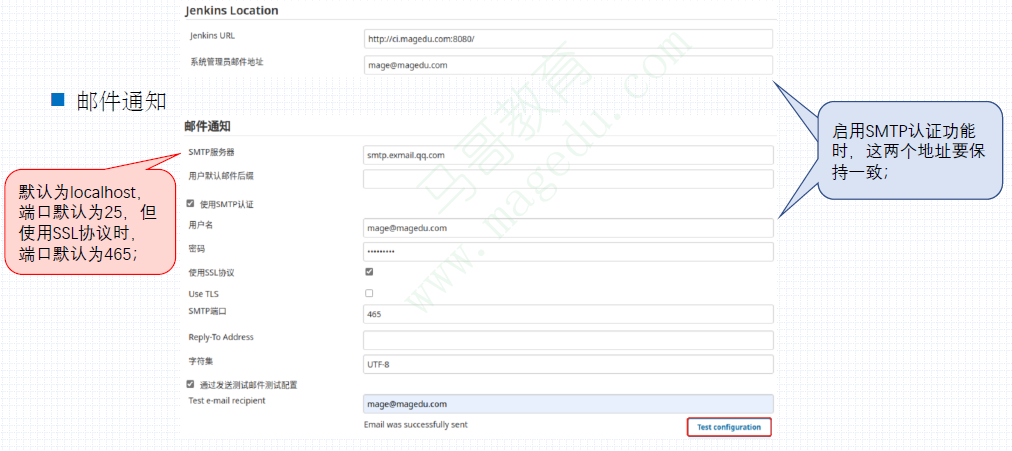
在pipeline中发送通知
在声明式pipeline的post{}里可以使用mail这一step来发送通知
该步骤支持有参数有如下几个
subject:邮件主题;
to:收件人地址;
body:邮件正文;
from:发件地址;
扩展电子邮件通知
除了基本的email功能外,Jenkins还支持通过Extension Email插件提供更多的高级选项和控制级别,它包含有类似邮件mail插件的基础配置,并增加了其它几个功能区,如右侧的图形所示;
emailext新增了以下几个功能区
内容:可以动态地修改email通知的主题和正文;
收件人:可以定义哪些角色的用户会收到email通知;
触发器:可以指定发送email通知的条件;
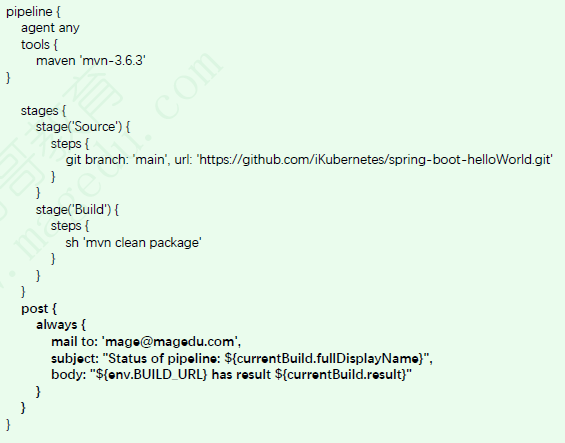
emailext步骤
在声明式pipeline的post{}中使用扩展email通知时要使用emailext步骤实现,它支持如下几个常用参数
subject
body
attachLog(optional):是否将构建日志以附件形式发送;
attachmentsPattern(optional):需要发送的附件的路径,要使用Ant风格的路径表达式;
compressLog(optional):是否压缩日志;
mimeType(optional)
postsendScript(optional)
presendScript(optional)
from(optional)
to(optional)
recipientProviders(optional):收件人类型,列表型数据;
replyTo(optional)
recipientProviders
除了指定的收件人外,emailext可支持多种不同类型的收件人
buildUser 手动发起构建操作的
culprits:最近一次非失败构建至今有变更提交的用户列表;
developers
brokenTestsSuspects:导致单元测试失败的嫌疑用户列表;
brokenBuildSuspects:导致构建失败的嫌疑用户列表;
recipients:项目上的recipient列表;
requestor:触发构建的用户;push时触发构建操作的用户
upstreamDevelopers:触发本地构建的上游项目的变更提交者;
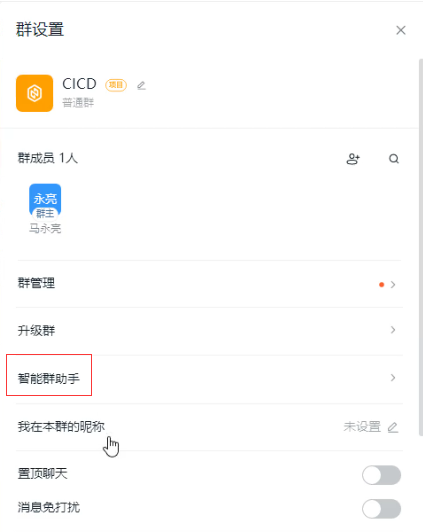
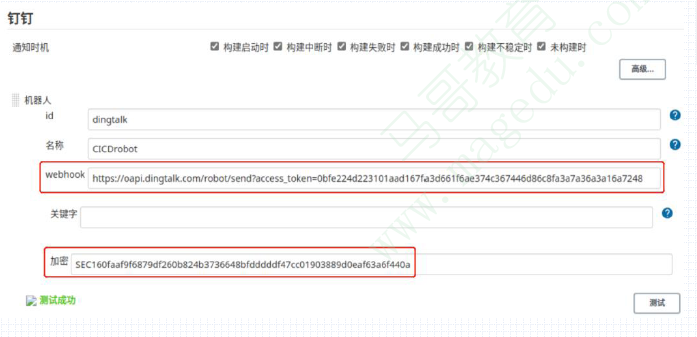
40.23. 钉钉通知DingTalk通知
钉钉配置过程
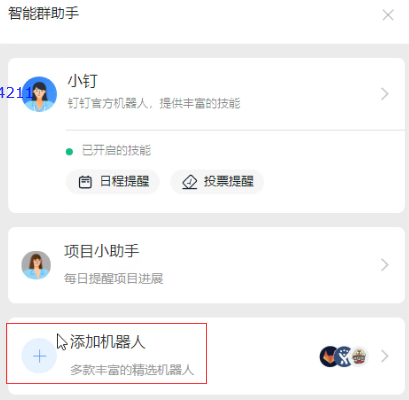
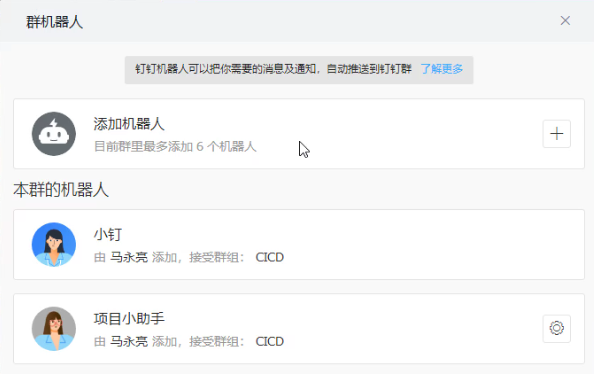
在相应的钉钉群上添加自定义类型的机器人;
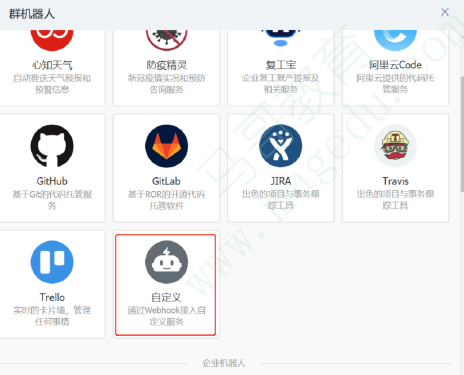
DingTalk通知
钉钉配置过程
为机器人选择合适的安全设置,这里以加签方式为例,相应的密钥信息需要在Jenkins上用到;

DingTalk通知
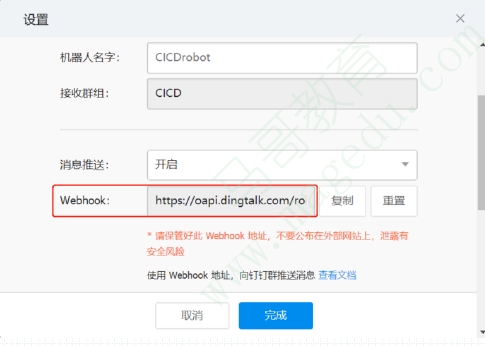
钉钉配置过程
最后自动生成webhook,该webhook也将会由Jenkins所使用;
配置Jenkins的dingtalk插件
在Jenkins上安装dingtalk插件;
而后配置钉钉插件:ManageJenkinsàConfigure System à钉钉
配置完成后,建议点击测试按钮确认是否配置成功

dingtalk步骤
dingtalk是由相应插件引入的步骤,它支持以下字段;
robot
at (optional)
atAll(optional)
btnLayout(optional)
btns(optional)
hideAvatar(optional)
messageUrl(optional)
picUrl(optional)
singleTitle(optional)
singleUrl(optional)
text (optional)
title (optional)
type (optional)
各参数说明:https://jenkinsci.github.io/dingtalk-plugin/guide/pipeline.html#%E5%8F%82%E6%95%B0%E8%AF%B4%E6%98%8E
测试由dingtalk发送通知
将此前示例中的email通知修改为dingtalk通知方式
通知结果如下图中最后一条消息所示
注意:即便是钉钉机器人引用错误,Jenkins的执行状态也不会报错

40.24. SonarQube简介
SonarQube是一种自动代码审查工具,用于检测代码中的错误、漏洞和代码异味,它集成到现有的工作流程,以便在项目分支和拉取(PR)请求之间进行连续的代码检查;
SonarQube有四个关键组件
SonarQube Server运行三个主要进行
Web Server:UI
Search Server:为UI提供搜索功能,基于ElasticSearch
Compute Engine Server:处理代码分析报告并将之存储到SonarQube Database中
SonarQube Database:负责存储SonarQube的配置,以及项目的质量快照等
SonarQube Plugin
Code analysis Scanners:代码扫描器,扫描后将报告提交给SonarQube Server
部署的先决条件(以7.9 LTS为例)
硬件需求
小型应用至少需要2GB的RAM
磁盘空间取决于SonarQube分析的代码量
必须安装在读写性能较好的磁盘上
存储数据的目录中包含了ElasticSearch的索引,服务器启动并运行时,将会在该索引上进行大量I/O操作
不支持32位操作系统
支持PostgreSQL、SQL Server和Oracle,不再支持MySQL,且要求PostgreSQL必须使用9.3-9.6,或者10以上的版本;
JVM需求
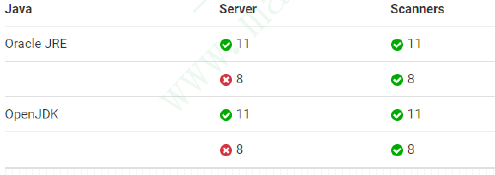
Linux平台要求
将SonarQube部署于Linux系统时,必须确保满足如下需求
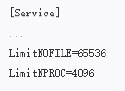
vm.max_map_countis greater or equals to 262144
fs.file-max is greater or equals to 65536
the user running SonarQube can open at least 65536 file descriptors
the user running SonarQube can open at least 4096 threads
前两个参数通过sysctl系统设定;
后两个参数需要在配置文件/etc/security/limits.conf中完成

对于以systemd运行SonarQube的场景,也可通过设置其unitfile文件完成
40.25. Jenkins和SonarQube
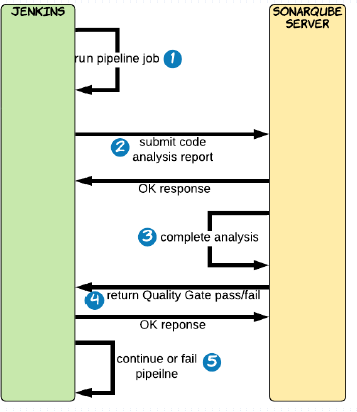
Jenkins借助于SonarQube Scanner插件将SonarQube提供的代码质量检查能力集成到pipeline上,从而确保质量阈检查失败时,能够避免继续进行后续的操作,例如发布等;
Jenkins pipeline启动;
SonarQube Scanner分析代码,并将报告发送至SonarQube Server;
SonarQube Server分析代码检测的结果是否符合预定义的质量阈;
SonarQube Server将通过(passed)或者失败(failed)的结果发送回Jenkins上的SonarQube Scanner插件暴露的Webhook;
质量域相关的阶段成功通过或可选地失败时,则Jenkins pipeline续费后面的Stage;否则,pipeline将终止;
然而,Jenkins的SonarQube Scanner插件将代码分析报告提交给SonarQube Server时,它不会同步响应质量阈的检测结果,为此,我们必须在SonarQube Server上配置一个webhook以回调Jenkins;
配置Jenkins使用SonarQube
配置Jenkins使用sonar-scanner进行代码质量扫描,并将结果报告给SonarQube Server的主要步骤如下
首先,在Jenkins上安装SonarQube插件
其次,配置Jenkins对接到SonarQube Server
第三,配置Jenkins的全局工具sonar-scanner
第四,在SonarQube上添加回调Jenkins的Webhook
第五,在Jenkins项目上调用sonar-scanner进行代码质量扫描
最后,通过SonarQube确认扫描结果的评估;
在SonarQube上生成令牌
p在SonarQube上以相应的用户生成令牌,该令牌将被Jenkins用于通过相应的URL打开SonarQube
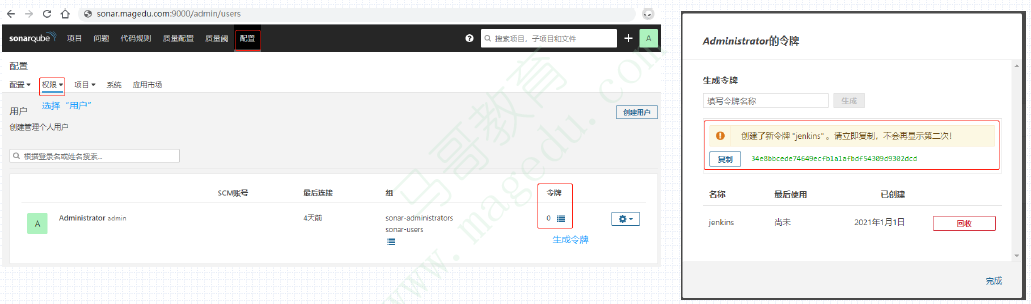
将SonarQube令牌存储为Jenkins凭证
在Jenkins上保存SonarQube的令牌为凭证,凭证类型为Secret text;
Manage Jenkins —> Manage Credentials
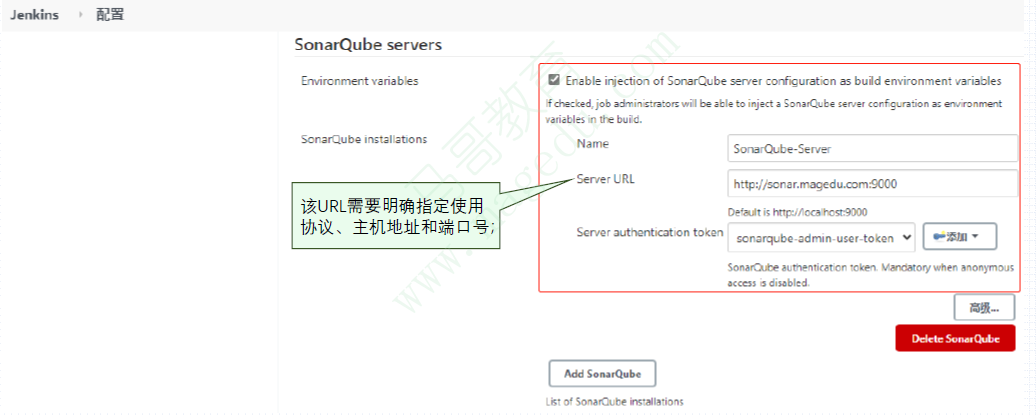
在Jenkins上添加SonarQube Server
在Jenkins的配置中,添加SonarQube Server,并选择打开该Server时使用的令牌凭证
Manage Jenkins —> Configure System —> SonarQube Servers
为Jenkins添加sonar-scanner工具
为Jenkins添加全局工具sonar-scanner,以便在构建任务中调用
Manage Jenkins —> 全局工具配置

在SonarQube添加Jenkins的回调接口
在SonarQube上添加webhook(网络调用),以便于Jenkins通过SonarQube Quality Gate插件调用其质量阈信息;
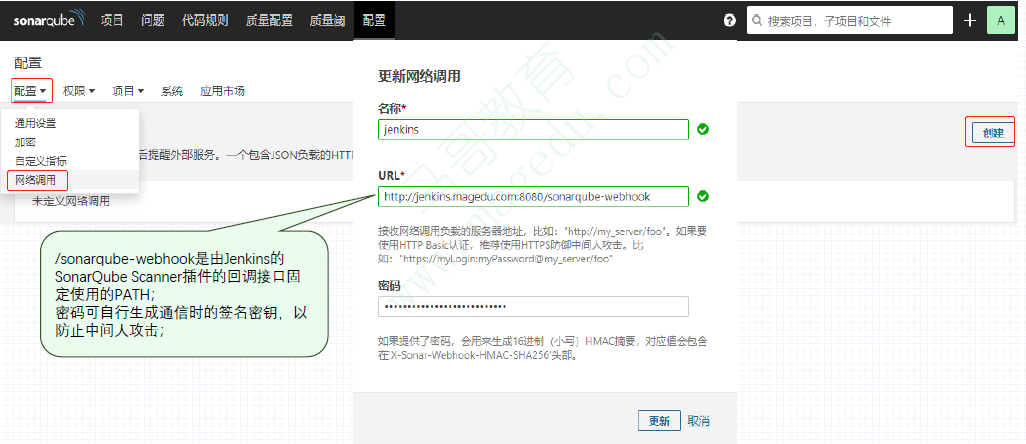
在Jenkins中使用SonarQube进行代码质量检查
pmvn可使用sonar:sonar这一target直接调用SonarQube进行代码质量分析
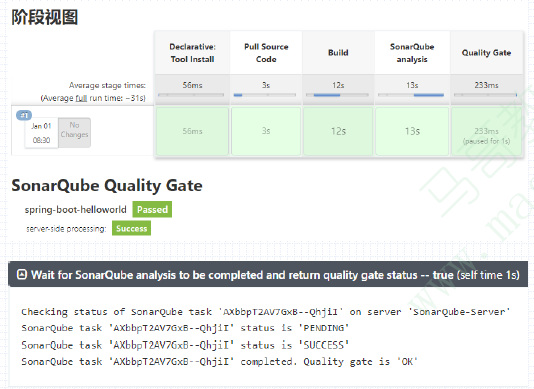
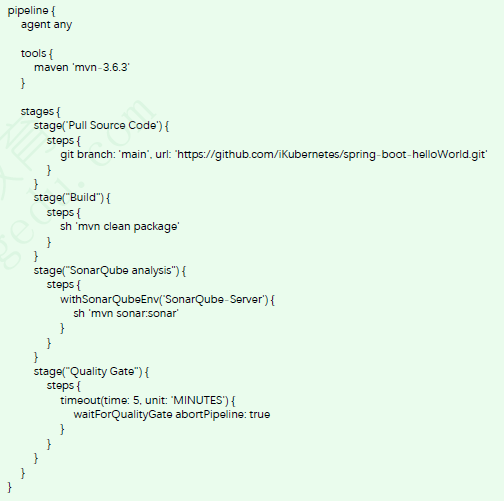
在Jenkins中使用SonarQube进行代码质量检查(2)
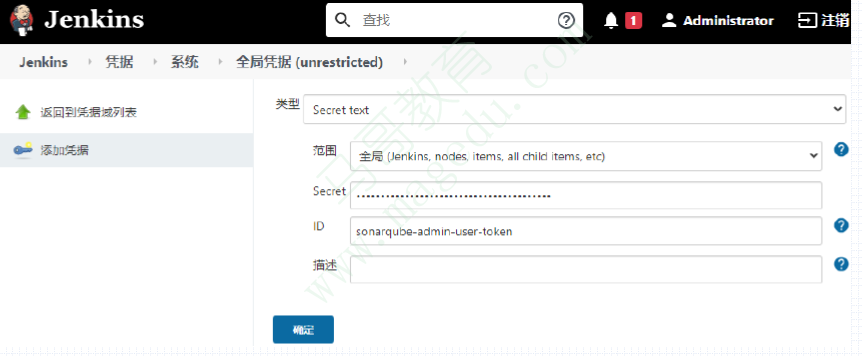
将SonarQube的用户token配置为Jenkins的凭证,便可在Jenkins的job中直接通过链接认证到SonarQube;
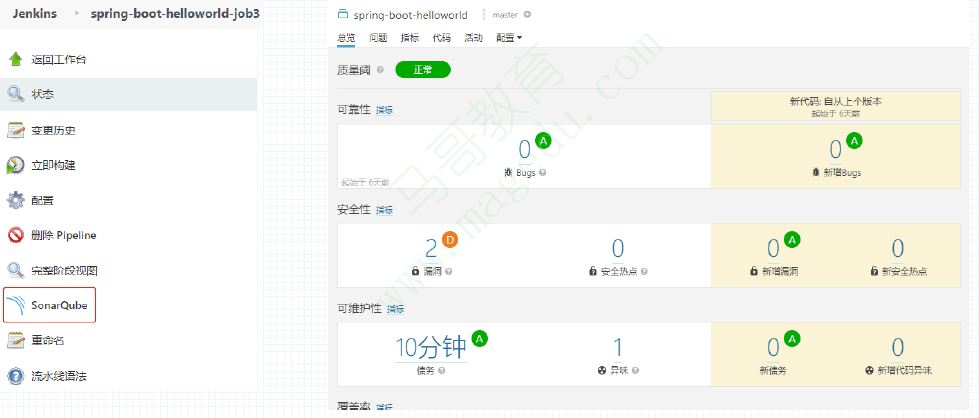
40.26. jenkins分布式
Master与Agent间的连接方式
为了能让master将一个主机识别为agent,需要事先在各agent上运行特定的代理程序以使得其能够与master之间建立双向通信
有多种方法实现master与agent之间的连接建立
SSH连接器:首选且最稳定的双向连接机制,它依赖于Jenkins内置的SSH客户端,并要求
各agent要部署并启动了SSH服务;
支持基于密钥及口令的两种认证方式,但认证信息要保存为master之上的凭证;
基于密钥认证时,master主机上私钥凭证对应的公钥要存在于各agent主机之上;
Inbound连接器:在agent上以手动或系统服务的方式经由JNLP协议触发双向连接的建立;
JNLP-HTTP连接器:在agent上经由JNLP协议通过HTTP建立双向连接;
agent配置段语法介绍
agent可接受多种形式的参数
any:任何可用节点
none:用于pipeline顶端时表示不定义默认的agent,这就需要为每个stage单独指定;
label { label “