Oracle和mysql对比
2019年4月4日 星期四
21:59
mysql:一个用户可以有多个数据库

Oracle可以有多个实例
表空间中主要存储的是.DBF和.ORA数据文件,物理存储
Oracle中的用户相当于Mysql中的database
1.登录超级管理员:sqlplus sys/sys as sysdba
2.查看当前连接数据库的用户:show user;
3.查看当前用户下的表:select from tab;
4.登录超级管理员时,可以访问其他用户下的表:select from scott.dept;
表空间查询
2019年11月21日
15:45
数据库表空间缩减:
—数据库表空间大小及使用
SELECT A.TABLESPACE_NAME “表空间名”,
TOTAL “表空间大小”,
FREE “表空间剩余大小”,
(TOTAL - FREE) “表空间使用大小”,
TOTAL / (1024 1024 1024) “表空间大小(G)”,
FREE / (1024 1024 1024) “表空间剩余大小(G)”,
(TOTAL - FREE) / (1024 1024 1024) “表空间使用大小(G)”,
ROUND((TOTAL - FREE) / TOTAL, 4) 100 “使用率 %”
FROM (SELECT TABLESPACE_NAME, SUM(BYTES) FREE
FROM DBA_FREE_SPACE
GROUP BY TABLESPACE_NAME) A,
(SELECT TABLESPACE_NAME, SUM(BYTES) TOTAL
FROM DBA_DATA_FILES
GROUP BY TABLESPACE_NAME) B
WHERE A.TABLESPACE_NAME = B.TABLESPACE_NAME;
—查询单表占用空间
SELECT T.SEGMENT_NAME,
T.BYTES B,
T.BYTES / 1024 KB,
T.BYTES / 1024 / 1024 MB,
T.BYTES / 1024 / 1024 / 1024 GB,
O.
FROM USER_SEGMENTS T, MAXOBJECT O
WHERE T.TABLESPACE_NAME = ‘MAXIMO_DATA’
AND T.SEGMENT_NAME = O.OBJECTNAME
ORDER BY T.BYTES DESC;
创建用户和表空间
2019年4月23日 星期二
13:59
—删除用户
drop user rocket cascade;
drop tablespace ROCKETDATA including contents and datafiles;
drop tablespace ROCKET_INDEX including contents and datafiles;
—创建表空间
CREATE TABLESPACE ROCKET_DATA DATAFILE ‘D:\tablespace\rocket_data.ora’ SIZE 300M AUTOEXTEND ON;
CREATE TABLESPACE ROCKET_INDEX DATAFILE ‘D:\tablespace\rocket_index.ora’ SIZE 100M AUTOEXTEND ON;
create user rocket identified by rocket;
alter user rocket default tablespace ROCKET_DATA quota unlimited on ROCKET_DATA;
alter user rocket quota unlimited on ROCKET_INDEX;
alter user rocket temporary tablespace temp;
grant create trigger to rocket;
grant create session to rocket;
grant create sequence to rocket;
grant create synonym to rocket;
grant create table to rocket;
grant create view to rocket;
grant create procedure to rocket;
grant alter session to rocket;
grant create job to rocket ;
grant execute on ctxsys.ctx_ddl to rocket;
grant OEM_MONITOR to rocket ;
GRANT EXP_FULL_DATABASE TO rocket;
GRANT IMP_FULL_DATABASE TO rocket;
grant dba to rocket;
grant create user to rocket;
grant drop user to rocket;
grant create session to rocket with ADMIN OPTION;
grant alter user to rocket;
—DOS命令窗口导入
—impdp rocket/rocket@orcl directory=dump_dir dumpfile=ROCKET**.dmp schemas=rocket
impdp rocket/rocket@orcl dumpfile=ROCKET_20180803.dmp schemas=rocket
impdp rocket/rocket@orcl dumpfile=data.dmp schemas=rocket
1.设置最大的数据库连接数session
2.关闭登录审计功能
//创建访问用户
#进入数据库
su - oracle
sqlplus / as sysdba
1.创建用户:
create user xbpms identified by nwpn_2019xbpms default tablespace ROCKET_DATA;
2.授权connect
grant connect to xbpms;
grant create session to zhangsan;
3、授权查询表的权限
grant select on XB_ZTJC_SDXL to xbpms;
grant select on XB_ZTJC_BDZ to xbpms;
4、创建同义词:
grant create synonym to xbpms;
create or replace synonym xbpms.XB_ZTJC_SDXL for rocket.XB_ZTJC_SDXL;
create or replace synonym xbpms.XB_ZTJC_BDZ for rocket.XB_ZTJC_BDZ;
基础知识
2019年4月4日 星期四
22:23
1.distinct 必须所有的列的数据相同时才可以去重
2.字符串的连接可以使用“||”或者concat(‘A’,’B’)
3.空与非空:is null , is not null
4.或条件:or
5.between A and B 相当于 >=A 和<=B
eg:select from emp where sal between 150 and 300;
6.模糊查询:”_”可以匹配一个长度的内容
eg: like ‘_M%’ 查询姓名中第二个字符包含“M”的人
7.不等号:!= 或者 <>
8.upper(‘smith’) 转换为大写 , lower(’ABC’)转换为小写
9.字符的长度:length(’hello’)
10.字符串的替换:replace(’hello’,’l’,’xx’) → hexxxxo
11.字符串的截取:substr(’hello’,1,3)截取是从1开始,使用0也是从1开始
即:substr(’hello’,0,3)= substr(’hello’,1,3)
12.to_char也可以对字符串进行格式化,或者按照一定的格式分割,例如对钱的小数位进行格式化。
13.在日期中to_char后不满10的月份/时间前面会加“0”,称为前导“0”,可以使用fm去掉。
例如:select to_char(sysdate,’fmyyyy-mm-dd’)from dual. 就会有2019-2-3
14.select from A,B;其中A与B进行了笛卡尔积,是每一条数据(也就是表中的一行),不是其中的一个数据。
15.针对一个表里面的递归查询,可以from两个相同的表
eg:select e.eno,e1.ename from emp e,emp e1
这种相对比较简单,也可以使用connection by start with
数值函数
2019年4月5日 星期五
8:08
1.四舍五入:
round(12.78) → 13
round(12.78,1) → 12.8
2.trunc去掉小数部分:
trunc(12.87) → 12
trunc(12.877,2) → 12.87
3.取余:
mod(10,3) → 1
4.sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
a=10,b=20
则sign(a-b)返回-1
5.select decode(sign(变量1-变量2),-1,变量1,变量2) from dual; —取较小值
sign()函数根据某个值是0、正数还是负数,分别返回0、1、-1
例如:
变量1=10,变量2=20
则sign(变量1-变量2)返回-1,decode解码结果为“变量1”,达到了取较小值的目的。
日期函数
2019年4月5日 星期五
8:14
Oracle中提供了很多和日期相关的函数,有如下的规律:
日期 - 数字 = 日期
日期 + 数字 = 日期
日期 - 日期 = 数字(天)
1.周数
(sysdate - ‘某一日期’)/ 7
2.两个日期的月数:
months_between(sysdate,pasetime)
3.获得几个月后的日期:
add_months(sysdate,3) → 3个月后的时间
4.下一个星期:
next_day(sysdate,’星期一’) 输出一个日期的几号
5.本月最后一天:
last_day(sysdate) → 输出一个日期
通用函数
2019年4月14日 星期日
下午3:04
1.空值处理:nvl
Oracle中空值与任何计算都为空值
select ename,sal*12 + nvl(comm,0)from emp
当comm为空时,用“0”代替
2.Decode函数:
Decode(col/expression,[search1,result1],[search2,result2],……,default)
其中col/expression为表达式或者列名
search用于比较的条件
result为比较后的结果
select decode(XL.dydj,
36,
‘交流750KV’,
85,
‘直流800KV’,
‘’) from T_SB_ZNYC_XL
3.case when函数:
select xl.xlmc,
case
when xl.dydj = 36 then ‘交流750’
when xl.dydj = 80 then ‘直流800’
else
‘交流440’
end as ‘交流等级’
from T_SB_ZNYC_XL
或者写成:
select xl.xlmc
case xl.dydj
when 36 then ‘交流750’
when 80 then ‘直流800’
else
‘交流440’
end as ‘交流等级’
from T_SB_ZNYC_XL
字符函数
2019年6月17日 星期一
16:36
1.字符查找instr
格式一
1 select instr(‘helloworld’,’l’) from dual; —返回结果:3 默认第一次出现“l”的位置
2 select instr(‘helloworld’,’lo’) from dual; —返回结果:4 即:在“lo”中,“l”开始出现的位置
3 select instr(‘helloworld’,’wo’) from dual; —返回结果:6 即“w”开始出现的位置
格式二
1 select instr(‘helloworld’,’l’,2,2) from dual; —返回结果:4 也就是说:在”helloworld”的第2(e)号位置开始,查找第二次出现的“l”的位置
2 select instr(‘helloworld’,’l’,3,2) from dual; —返回结果:4 也就是说:在”helloworld”的第3(l)号位置开始,查找第二次出现的“l”的位置
3 select instr(‘helloworld’,’l’,4,2) from dual; —返回结果:9 也就是说:在”helloworld”的第4(l)号位置开始,查找第二次出现的“l”的位置
4 select instr(‘helloworld’,’l’,-1,1) from dual; —返回结果:9 也就是说:在”helloworld”的倒数第1(d)号位置开始,往回查找第一次出现的“l”的位置
5 select instr(‘helloworld’,’l’,-2,2) from dual; —返回结果:4 也就是说:在”helloworld”的倒数第1(d)号位置开始,往回查找第二次出现的“l”的位置
6 select instr(‘helloworld’,’l’,2,3) from dual; —返回结果:9 也就是说:在”helloworld”的第2(e)号位置开始,查找第三次出现的“l”的位置
7 select instr(‘helloworld’,’l’,-2,3) from dual; —返回结果:3 也就是说:在”helloworld”的倒数第2(l)号位置开始,往回查找第三次出现的“l”的位置
统计函数Over
2019年7月19日 星期五
10:07
现在需要按照课程对学生的成绩进行排序:
—rownumber() 顺序排序
select name,course,row_number() over(partition by course order by score desc) rank from student;

—rank() 跳跃排序,如果有两个第一级别时,接下来是第三级别
select name,course,rank() over(partition by course order by score desc) rank from student;
—dense_rank() 连续排序,如果有两个第一级别时,接下来是第二级别
select name,course,dense_rank() over(partition by course order by score desc) rank from student;
TIPS:
使用rank over()的时候,空值是最大的,如果排序字段为null, 可能造成null字段排在最前面,影响排序结果。
可以这样: rank over(partition by course order by score desc nulls last)
来自 <[_https://www.cnblogs.com/qiuting/p/7880500.html](https://www.cnblogs.com/qiuting/p/7880500.html)>
数值函数和Over的结合
2019年7月19日 星期五
10:48
1.连续求和
统计某商店的营业额。
date sale
1 20
2 15
3 14
4 18
5 30
select day,sale,sum(sale) over (order by day asc ) as 连续求和,sum(sale) over() as 总和 from t_temp;
2、分类统计最大值、最小值、求和等
A B C
— — ———————————
m a 2
n a 3
m a 2
n b 2
n b 1
x b 3
x b 2
x b 4
h b 3
select a,c,sum(c)over(partition by a) from t2
得到结果:
A B C SUM(C)OVER(PARTITIONBYA)
— — ———- ————————————
h b 3 3
m a 2 4
m a 2 4
n a 3 6
n b 2 6
n b 1 6
x b 3 9
x b 2 9
x b 4 9
———————————————————
正则表达式函数
2019年7月19日 星期五
9:37
1.简单的:select regexpreplace(‘0123456789’,’01234’,’0abc’) from dual;
Oracle正则表达式函数-REGEXP_REPLACE使用例子
6个参数
第一个是输入的字符串
第二个是正则表达式
第三个是替换的字符
第四个是标识从第几个字符开始正则表达式匹配。(默认为1)
第五个是标识第几个匹配组。(默认为全部都替换掉)
第六个是是取值范围:
i:大小写不敏感;
c:大小写敏感;
n:点号 . 不匹配换行符号;
m:多行模式;
x:扩展模式,忽略正则表达式中的空白字符。
全部测试数据
SQL> select from test_reg_substr;
A
—————————————————-
ABC123XYZ
ABC123XYZ456
Edward
替换数字
SQL> SELECT
2 REGEXP_REPLACE (a,’[0-9]+’,’QQQ’) AS A
3 FROM
4 test_reg_substr;
A
———————————————————————-
ABCQQQXYZ
ABCQQQXYZQQQ
Edward
替换数字(从第一个字母开始匹配,替换第1个匹配项目)
SQL> SELECT
2 REGEXP_REPLACE (a,’[0-9]+’,’QQQ’, 1, 1) AS A
3 FROM
4 test_reg_substr;
A
———————————————————————————
ABCQQQXYZ
ABCQQQXYZ456
Edward
替换数字(从第一个字母开始匹配,替换第2个匹配项目)
SQL> SELECT
2 REGEXP_REPLACE (a,’[0-9]+’,’Q’, 1, 2) AS A
3 FROM
4 test_reg_substr;
A
—————————————————————————-
ABC123XYZ
ABC123XYZQ
Edward
*替换第二个单词
SQL> SELECT
2 REGEXP_REPLACE (a,’\w+’,’Kimi’, 1, 2) AS A
3 FROM
4 test_reg_substr;
A
—————————————————————————-
ABC123XYZ
ABC123XYZ456
来自 <[_http://blog.sina.com.cn/s/blog_18dbf52650102y6zb.html](http://blog.sina.com.cn/s/blog_18dbf52650102y6zb.html)>
Oralce导入/导出dmp文件
2019年3月11日 星期一
17:13
第一种导入方法:
第一步将dmp文件放入此目录下
F:\app\Administrator/admin/orcl/dpdump
第二步在cmd下,输入下面的命令
impdp rocket/rocket@127.0.0.1:1521/orcl dumpfile=allgisdata.dmp transform=segmentattributes:n remap_schema=mw_app:rocket
第二种导入方法:
imp rocket/rocket@192.168.1.25 file=F:\app\Administrator\admin\orcl\dpdump\allgisdata.dmp full=y
第一种导出方法:
exp scyw/scyw@192.168.1.25 file=d:\xxx.dmp full=y 导出所有用户的数据,不加full=y是导入当前用户的数据
或者导出指定表:
exp scyw/scyw@YTHGKPT file=d:\xxx.dmp tables=’CMST%’ //导出所有以CMST_开头的数据表
或者
exp scyw/scyw@YTHGKPT file=d:\xxx.dmp tables=(CMST_A,CMST_B) //导出制定的CMST_A,CMST_B
Oracle查看索引问题
2019年3月11日 星期一
17:16
问题:ora-29861:域索引标记为loading/failed/unusable
select owner,index_name from all_indexes where domidx_status != ‘VALID’ or domidx_opstatus !=’VALID’;
drop index CONTRACTLINE_NDX2;
Oracle官网账户密码
2019年3月11日 星期一
17:14
账户:308620864@qq.com
密码:521Tuzi#
Oracle空间数据的查询
2019年3月25日 星期一
11:13
select a.sbmc, a.dydj, to_char(sdo_util.to_gmlgeometry(a.shape)) from t_tx_znyc_dz a
with as
2019年4月9日 星期二
15:18
1.Oracle的with as用法:
With查询语句不是以select开始的,而是以“WITH”关键字开头
可认为在真正进行查询之前预先构造了一个临时表,之后便可多次使用它做进一步的分析和处理
WITH Clause方法的优点
增加了SQL的易读性,如果构造了多个子查询,结构会更清晰;更重要的是:“一次分析,多次使用”,这也是为什么会提供性能的地方,达到了“少读”的目标。
第一种使用子查询的方法表被扫描了两次,而使用WITH Clause方法,表仅被扫描一次。这样可以大大的提高数据分析和查询的效率。
另外,观察WITH Clause方法执行计划,其中“SYS_TEMP_XXXX”便是在运行过程中构造的中间统计结果临时表。
—相当于建了个e临时表
with e as (select from scott.emp e where e.empno=7499)
select from e;
—相当于建了e、d临时表
with
e as (select from scott.emp),
d as (select from scott.dept)
select * from e, d where e.deptno = d.deptno;
start with connect by prior递归用法
2019年4月9日 星期二
15:34
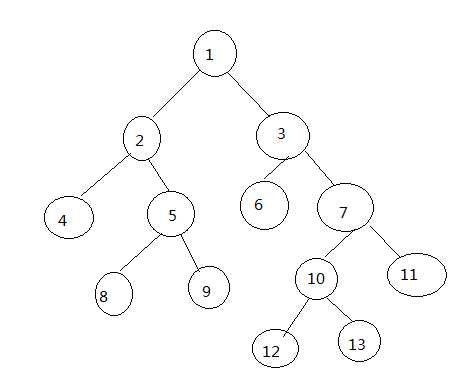
这个子句主要是用于B树结构类型的数据递归查询,给出B树结构类型中的任意一个结点,遍历其最终父结点或者子结点。
链接地址:https://www.cnblogs.com/benbenduo/p/4588612.html
create table a_test
( parentid varchar2(10),
subid varchar2(10));
insert into a_test values ( ‘1’, ‘2’ );
insert into a_test values ( ‘1’, ‘3’ );
insert into a_test values ( ‘2’, ‘4’ );
insert into a_test values ( ‘2’, ‘5’ );
insert into a_test values ( ‘3’, ‘6’ );
insert into a_test values ( ‘3’, ‘7’ );
insert into a_test values ( ‘5’, ‘8’ );
insert into a_test values ( ‘5’, ‘9’ );
insert into a_test values ( ‘7’, ‘10’ );
insert into a_test values ( ‘7’, ‘11’ );
insert into a_test values ( ‘10’, ‘12’ );
insert into a_test values ( ‘10’, ‘13’ );
commit;
select * from a_test;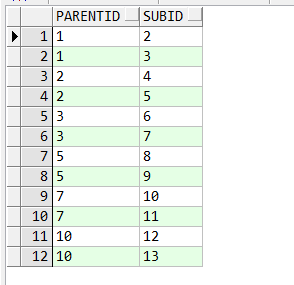
序列sequence
2019年4月20日 星期六
18:31
语法:
create sequence 序列名
[increment by n] - - 可有可无,默认一次增加1
[start with n]
[{maxvalue/minvalue n | nomaxvalue}]
[cycle|nocycle] - -是否循环,达到最大值后回到最小值开始,一般设置为不循环
[cache n|nocahce]
使用:
select 序列名.nextval from dual
select 序列名.currval from dual
索引
2019年4月20日 星期六
20:27
创建索引:
1.单例索引:单例索引是基于单个列所建的索引
create index 索引名 on 表名(列名)
2.复合索引:复合索引是有顺序的(where 后面的条件必须是表名1的条件再表名2的条件)
create index 索引名 on 表名(表名1,表名2……)
索引使用原则:
1.在大表上建立索引才有意义
2.在where子句后面或者是连接的条件上建立索引
3.索引的层次不要超过4层

若有收获,就点个赞吧
0 人点赞
