1. 背景
前一段时间在工作中遇到了这样一个场景:我手上的一个业务需要依赖其它部门的业务数据,来在己方的服务上做一些定制化的策略和规则。所以这一份数据,我们会持久化到我们的数据库中。但是由于这些数据在其它部门的库中是是可变的。所以在我方跑一些实时流程等的时候就需要对数据做一次匹配,即要求能匹配上远程数据的本地数据才算有效数据。说白了,即做一个求交集的处理。
为了方便大家理解,我画了两张图,其实就是每次执行逻辑时会执行有效数据匹配的处理。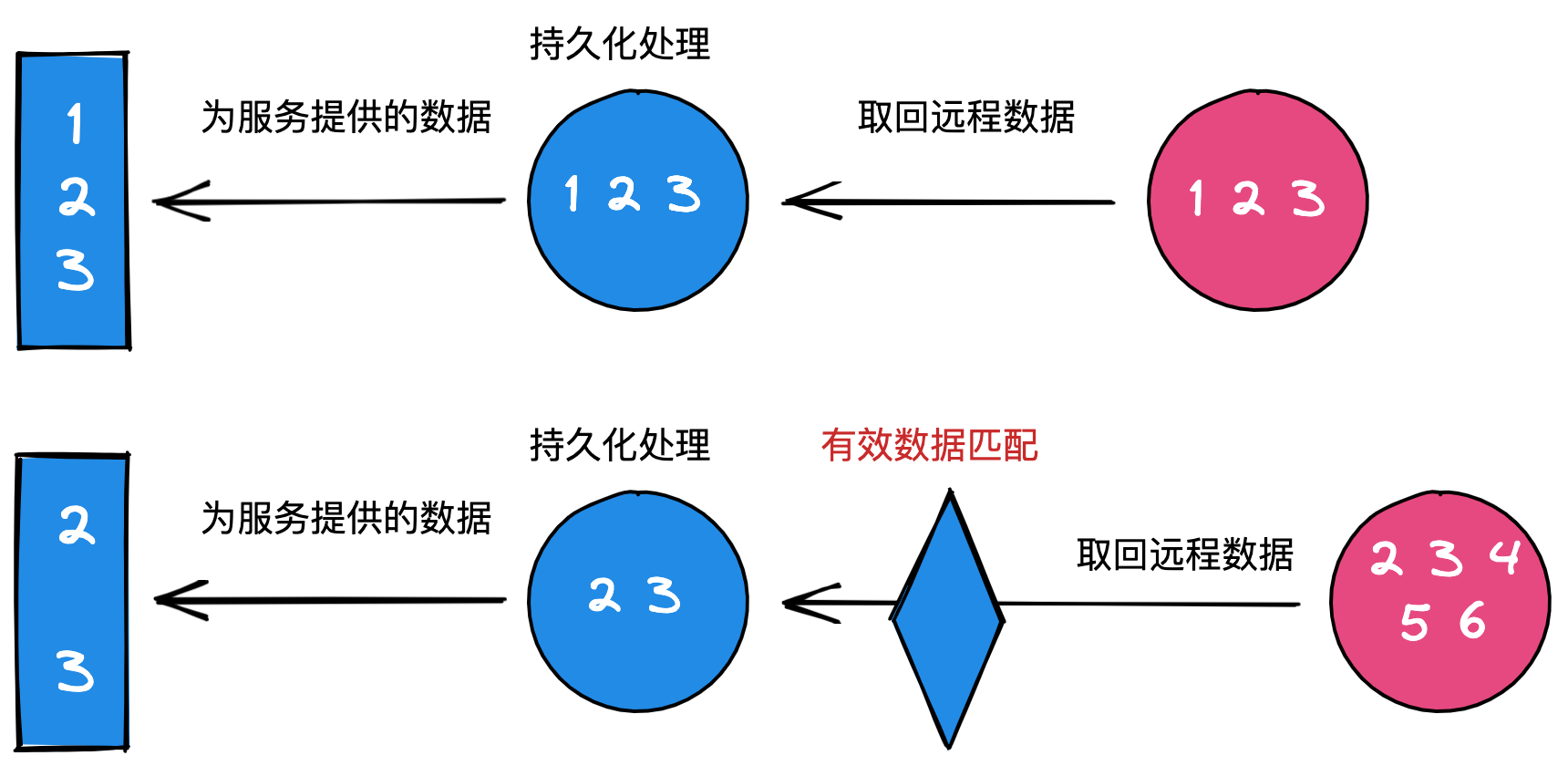
下面我们一起看看我们对于这种场景的有效处理方式,以及算法的时间性能等问题。
注:至于如何校正本地数据库中的数据,以及什么时机去校正。这里我们不去关心,我也可以在后面算法介绍完毕后提及一下。
2. 求交集算法
我们简化各种逻辑,专注算法本身,先来模拟一个场景:例如我们的数据实体是一个学生类(如下)。localDataList 集合中的数据代表本地数据,remoteDataList
�集合中的数据代表远程数据。
- 问题:本地数存在滞后,例如存储的 id 分别为 1 2 3 4,但远程数据的已经变为了 2 3 5(1 删除了,5 是新增的)。
处理:做一次求交集的处理(只有 2 3 是有效数据)。
@Data@NoArgsConstructor@AllArgsConstructorpublic class Student {/*** 主键 id*/private Long id;/*** 年龄*/private String name;/*** 年龄*/private Integer age;}
public class Demo {public static void main(String[] args) {// 本地数据List<Student> localDataList = new ArrayList<>();localDataList.add(new Student(1L,"张三",18));localDataList.add(new Student(2L,"李四",20));localDataList.add(new Student(3L,"王五",22));localDataList.add(new Student(4L,"赵六",24));// 远程数据List<Student> remoteDataList = new ArrayList<>();remoteDataList.add(new Student(2L,"李四",20));remoteDataList.add(new Student(3L,"王五",22));remoteDataList.add(new Student(5L,"孙七",26));}}
2.1 两层 for 循环的暴力解法
2.1.1 最简单粗暴的方式(两层 for 循环)
虽然基本不会有人真的在项目中这么用,但是它确实是解决问题的一种直观手段。
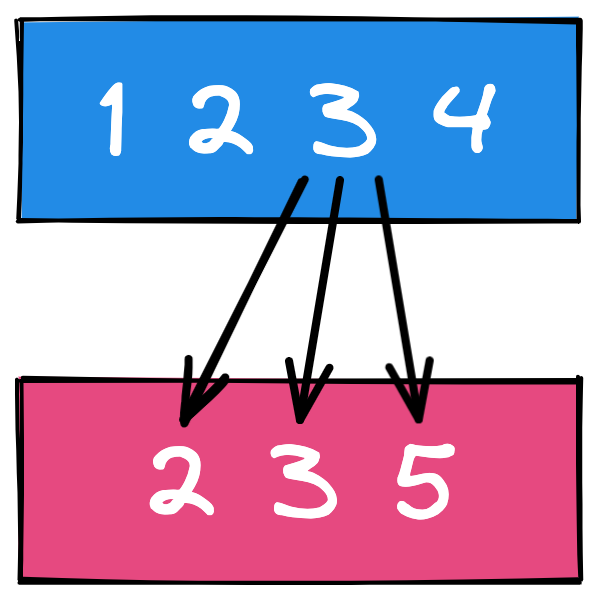
思路:依次拿本地数据集合的每一项在远程数据集合中进行一次全遍历,当判断到有相等的对象(lombok 注解帮助我们重写了 equals 和 hashCode方法)则会将其添加到 Set 中,然后转为 List 返回为什么转 Set 会在文章最后的补充中提及。
代码:
/*** 两层 for 循环比对方法** @param localDataList 本地数据集合(或存在脏数据的一方)* @param remoteDataList 远程数据集合(准确的一方)* @param <T> 泛型 类型统一即可* @return*/public static <T> List<T> getIntersectionList(List<T> localDataList, List<T> remoteDataList) {Set<T> tempSet = new HashSet<>();for (T localData : localDataList) {for (T remoteData : remoteDataList) {if (localData.equals(remoteData)){tempSet.add(localData);}}}return new ArrayList<>(tempSet);}
运行结果:
[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
- 优点:逻辑非常直观,易理解,可读性高,难度低。
- 缺点:循环次数过多,效率严重低下。(只有能保证两个集合数量极少的情况才或许可考虑)
所以,这这样看来,只要你能接受它的效率,其实暴力循环可以解决很多场景的问题。
2.1.2 粗暴的方法也能简单优化(基于两层 for 优化)
如果实在想不到更好的办法,硬着头皮用两层 for 循环,但是也得在此基础上,做点优化才好。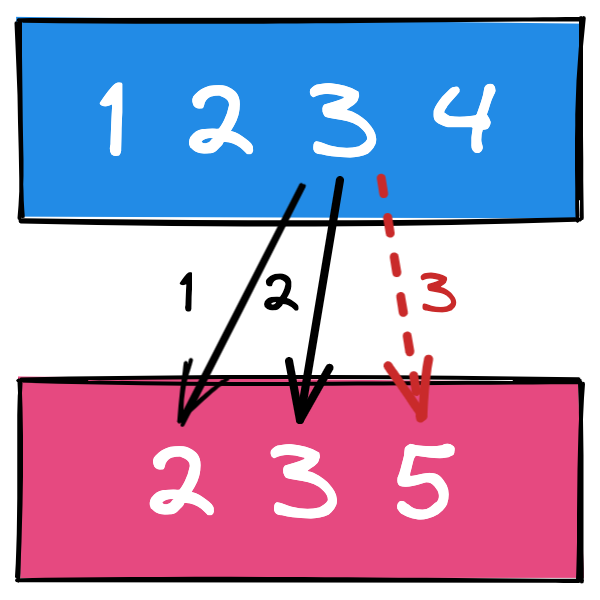
思路:两层循环中,当某一次匹配成功了,就不应该继续向下循环了,例如上图中,拿着本地数据中的 3 ,去远程数据中寻找,当执行到第二次的时候,就已经找到了,所以第三次那个遍历完全是多余的。可以直接换本地数据中的 4 进行遍历了。
代码:
/*** 两层 for 循环比对方法优化** @param localDataList 本地数据集合(或存在脏数据的一方)* @param remoteDataList 远程数据集合(准确的一方)* @param <T> 泛型 类型统一即可* @return*/public static <T> List<T> getIntersectionList2(List<T> localDataList, List<T> remoteDataList) {Set<T> tempSet = new HashSet<>();for (T localData : localDataList) {for (T remoteData : remoteDataList) {if (localData.equals(remoteData)){tempSet.add(localData);break;}}}return new ArrayList<>(tempSet);}
- 其实这份代码就是在判断到已经匹配到数据了,就会跳出内层循环,直接去拿本地数据的下一个数据再去做遍历,如果数据量大的情况下,还是能做到挺大的优化的
- 就在这份代码中,我分别打印了一下循环的次数。优化前:12次 优化后:9次。
运行结果:
[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
- 优点:性能略有提升
-
2.1.3 粗暴的方法再优化(基于两层 for 再优化)
其实上面的方法还可以继续优化
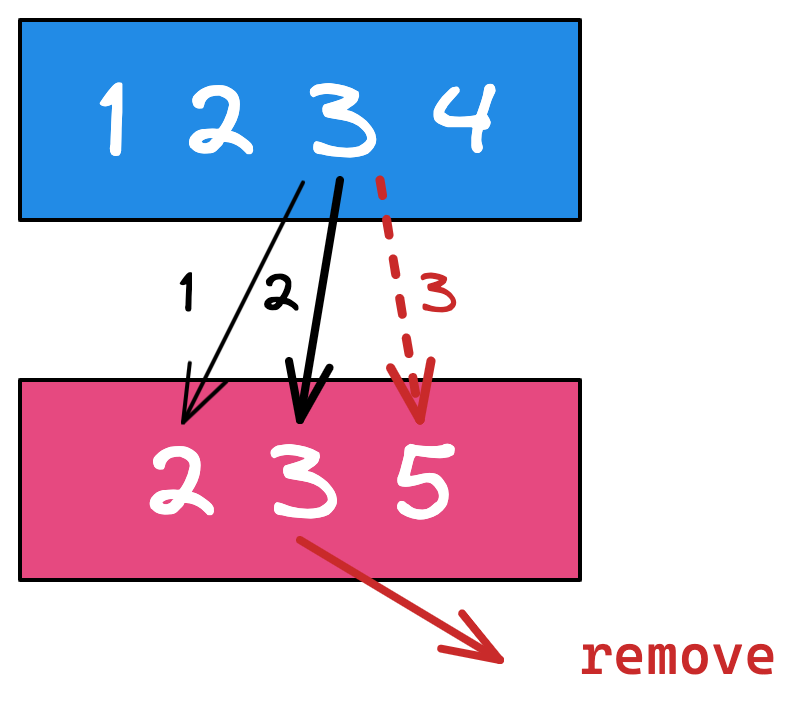
思路:如果某次循环中,本地的数据以及和远程某个数据匹配上了,那么下次本地的下一个数据和远程数据匹配时,就没有必要再次遇到刚才那个数据了。因为是没意义的。
代码:/*** 两层 for 循环比对方法再优化** @param localDataList 本地数据集合(或存在脏数据的一方)* @param remoteDataList 远程数据集合(准确的一方)* @param <T> 泛型 类型统一即可* @return*/public static <T> List<T> getIntersectionList3(List<T> localDataList, List<T> remoteDataList) {Set<T> tempSet = new HashSet<>();for (T localData : localDataList) {for (T remoteData : remoteDataList) {if (localData.equals(remoteData)){remoteDataList.remove(remoteData);tempSet.add(localData);break;}}}return new ArrayList<>(tempSet);}
我背后也打印了一下循环次数,这次只有 6 次,对于两层 for 循环的方式,我们简单的从 12 -> 9 -> 6 ,效果还算明显。
运行结果:
[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
- 优点:性能略有较为明显的提升
- 缺点:需要多考虑两步
注意:
这里其实是有一个小坑的,不过我们这个方法中其实已经规避了这一点。就是关于 remove 的并发修改异常。我们后面会专门补充这个问题。
2.1 巧用 Set 解法
2.1.1 Set 集合的 contains 方法
如果数据量特别大的情况下, 使用多层 for 毕竟是下策。
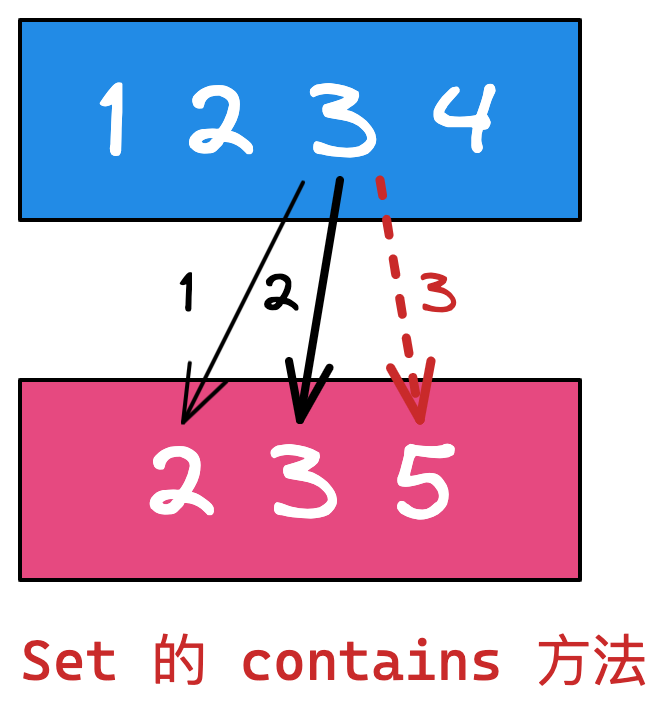
思路:因为 Set 方法的 contains 方法可以用来判断是否存某个元素,而且时间复杂度为 O(1),所以我们可以拿一个集合转为 Set,遍历另一个 List 集合,判断每个 List 中的元素是否存在 Set 中,存在的元素存储到另一个空 Set 中(此处是为了去重),然后转为 list 返回。
代码:/*** 利用 Set 集合的 contains 方法** @param localDataList 本地数据集合(或存在脏数据的一方)* @param remoteDataList 远程数据集合(准确的一方)* @param <T> 泛型 类型统一即可* @return*/public static <T> List<T> getIntersectionList4(List<T> localDataList, List<T> remoteDataList) {Set<T> remoteDataSet = new HashSet<>(remoteDataList);Set<T> localDataSet = new HashSet<>();for (T localData : localDataList) {if (remoteDataSet.contains(localData)){localDataSet.add(localData);}}return new ArrayList<>(localDataSet);}
运行结果:
[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
优点:性能有极大的提升,时间复杂度直接降低到 O(n) 可作为为最终方法之一。
- 缺点:需要熟悉 List 和 Set 的特点,灵活运用
补充:
- 为什么不用 List 的 contains 方法?(可阅读源码)
- ArrayList 本质是通过数组实现的,查找一个元素是否包含,会去对元素进行遍历,时间复杂度是O(n)
- HashSet 的包含是通过 HashMap 的 KeySet 实现,时间复杂度是O(1)
是否有别的方式?
- 答案是肯定的,例如还可以通过向一个 Set 中添加元素,然后在其中用一个变量计数,如果数变了,说明有新的,不重复的元素被添加进入了。等等方式。
2.3 神奇的 Map
2.3.1 Map 的 get 方法
思路:利用 Map 的 key value 特点,将一个 List 中一个字段作为 key,例如我们将主键 id 作为 key,这样遍历另一个集合的时候,就可以通过 getId 的方式拿到这个数据,我这里是直接将获取到的 Student 加入到返回的 Set 中了,如果想要的是本地那份数据中的 Student,那么就将循环中的 localData 加入到 Set 中,这个可以自己选择
代码: ```java /**
- 利用 Map 方法 *
- @param localDataList 本地数据集合(或存在脏数据的一方)
- @param remoteDataList 远程数据集合(准确的一方)
@return */ public static List
getIntersectionList6(List localDataList, List remoteDataList) { Map remoteDataSet = new HashSet<>(remoteDataList); for (Student remoteData : remoteDataSet) { remoteDataMap.put(remoteData.getId(), remoteData); }
Set
resultSet = new HashSet<>(); for (Student localData : localDataList) { if (remoteDataMap.get(localData.getId()) != null) { Student student = remoteDataMap.get(localData.getId());resultSet.add(student);
} } return new ArrayList<>(resultSet); }
**运行结果:**```java[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
- 答案是肯定的,例如还可以通过向一个 Set 中添加元素,然后在其中用一个变量计数,如果数变了,说明有新的,不重复的元素被添加进入了。等等方式。
- 优点:性能同样很优好,可作为为最终方法之一。
缺点:需要熟悉 List 和 Set 和 Map 的特点,灵活运用
2.3.2 Map 的 containsKey 方法
思路:Map 同样提供了很好用的方法 containsKey 来判断是否存在某个 key,基本思路与上一个大同小异。
代码:/*** 利用 Map 的 containsKey 方法** @param localDataList 本地数据集合(或存在脏数据的一方)* @param remoteDataList 远程数据集合(准确的一方)* @return*/public static List<Student> getIntersectionList6(List<Student> localDataList, List<Student> remoteDataList) {Map<Long, Student> remoteDataMap = new HashMap<>();Set<Student> remoteDataSet = new HashSet<>(remoteDataList);for (Student remoteData : remoteDataSet) {remoteDataMap.put(remoteData.getId(), remoteData);}Set<Student> resultSet = new HashSet<>();for (Student localData : localDataList) {if (remoteDataMap.containsKey(localData.getId())) {resultSet.add(localData);}}return new ArrayList<>(resultSet);}
运行结果:
[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
优点:性能同样很优好,可作为为最终方法之一。
缺点:需要熟悉 List 和 Set 和 Map 的特点,灵活运用
2.3.3 stream 转 Map
思路:思路与上面没打的区别,但是我们上面是用循环的方式将 List/Set 转为了 Map, 同样还可以使用 stream 来转换,不过这种方式除非是并行流,否则效率不会特别高。
代码:/*** 利用 Map 的 containsKey 方法(stream 转 map)** @param localDataList 本地数据集合(或存在脏数据的一方)* @param remoteDataList 远程数据集合(准确的一方)* @return*/public static List<Student> getIntersectionList7(List<Student> localDataList, List<Student> remoteDataList) {Map<Long, Student> remoteDataMap = remoteDataList.stream().collect(Collectors.toMap(Student::getId, v -> v));Set<Student> resultSet = new HashSet<>();for (Student localData : localDataList) {if (remoteDataMap.containsKey(localData.getId())) {resultSet.add(localData);}}return new ArrayList<>(resultSet);}
运行结果:
[Student(id=2, name=李四, age=20), Student(id=3, name=王五, age=22)]
总结一下:
优点:数据少的时候,基本很慢,可读性比较高,但转 Map 的性能有待商榷。
缺点:涉及到 JDK 1.8 的特性,还可以封装工具类,对知识要求度比较高。
3. 时间测试
测试方式:
long startTime = System.currentTimeMillis();// 此处是待测试的方法long endTime = System.currentTimeMillis();System.out.println("程序1:XXX 方法:" + (endTim - startTime) + "ms");
我们可以简单测试一下,我分别将两个集合的数量放大到了各自 1w 个,看看执行结果:
程序1:两层 for 循环:7318ms程序2:两层 for 循环(break):1117ms程序3:两层 for 循环(break + remove)1306ms程序3:两层 for 循环(break + remove)颠倒顺序 1240ms程序4:Set 集合的 contains 方法:14ms程序5:利用 Map:14ms程序6:利用 Map 的 containsKey 方法:8ms程序7:stream 转 map:74ms
可以看出来,性能最好的是 利用 Map 的 containsKey 方法,其次是普通 Map ,然后是 Set 集合的 contains 方法,至于 stream 转 map 在数量较大的情况下还算理想,但是如果数量特别少,甚至效率不如两层 for 循环。最后两层 for 循环三个演进,依次会略好一些,但是总体仍然不堪大用(除了一些数量极少的情况)。
- 为什么程序3 中 break + remove 的方式甚至比单单 break 的方式还差呢?这是因为它受到元素的位置影响,也就是不同元素的位置摆放顺序,以及两个 list 遍历的里外关系都有关系,所以平均效率不高。
4. 说明
重点还是掌握思想,至于是求交集还是差集还是去一一匹配,这些操作思想都是一致的。一般来说都会用 Set 或者 Map 或者一些更好的工具类,不过了解 for 的演进过程对自己也是很有帮助。
我文中多次用了 Set 和 List 的转换,是因为我只想要交集的那一条,即使有很多条重复的数据也要去重,只保留一条。怎么会有重复呢?
是因为我们从数据库中查询到的数据是带着所有字段的例如 id name age,但是我们从远程请求到的结果可能只是 age 字段,我们就可以将这个 age 字段封装到与数据库实体一致的对象中,然后重写它们的 age 的 hashCode 和 equals 方法,这样比较的时候就只会通过 age 字段比较,同时我们刻意返回的交集对象还是来自本地数据库中的,所以就能既达到根据 age 字段求交集的目的,又能带着 id name 等字段回来。方便利用。
说明:文中很多地方值得优化,但是重点还是体会思想,有什么误差以后回过头再来修改。
最后说一句,这些小算法,确实很有用。

若有收获,就点个赞吧
0 人点赞
