基础数据类型
整型
不同类型的整型不能直接互相赋值,需要强制转换,强制转换时需注意精度损失和值溢出。
Go语言同时提供了有符号和无符号类型的整数运算,有int8、int16、int32和int64四种截然不同大小的有符号整数类型,分别对应8、16、32、64bit大小的有符号整数,与此对应的是uint8、uint16、uint32和uint64四种无符号整数类型。
一般对应特定CPU平台机器字大小的有符号和无符号整数int和uint;其中int是应用最广泛的数值类型。这两种类型都有同样的大小,32或64bit,但是不能对这些类型的长度做任何假设,因为不同的编译器即使在相同的硬件平台上可能产生不同的大小。
Unicode字符rune类型是和int32等价的类型,通常用于表示一个Unicode码点。这两个名称可以互换使用。同样byte也是uint8类型的等。
还有一种无符号的整数类型uintptr,没有指定具体的bit大小但是足以容纳指针。uintptr类型只有在底层编程时才需要,特别是Go语言和C语言函数库或操作系统接口相交互的地方。
布尔型、数字类型和字符串等基本类型都是可比较的,也就是说两个相同类型的值可以用==和!=进行比较。此外,整数、浮点数和字符串可以根据比较结果排序。许多其它类型的值可能是不可比较的,因此也就可能是不可排序的。
布尔类型
Go语言中的布尔类型与其他语言基本一致,关键字也为bool,可赋值为预定义的true和false。if和for语句的条件部分都是布尔类型的值,并且==和<等比较操作也会产生布尔型的值。
布尔类型不能接受其他类型的赋值,不支持自动或强制的类型转换。
浮点型
Go语言提供了两种精度的浮点数,float32和float64。它们的算术规范由IEEE754浮点数国际标准定义,该浮点数规范被所有现代的CPU支持。float32和float64相互赋值需要强制转换。
float32相当于float,float64相当于double。
因为浮点数不是一种精确的表达方式,所以像整型那样直接用==来判断两个浮点数是否相等是不可行的,这可能会导致不稳定的结果。需要两个值相减和自定义的精度进行比较。
字符串
一个字符串是一个不可改变的字节序列。字符串可以包含任意的数据,包括byte值0,但是通常是用来包含人类可读的文本。文本字符串通常被解释为采用UTF8编码的Unicode码点(rune)序列。
字符串的值是不可变的:一个字符串包含的字节序列永远不会被改变,尝试修改字符串内部数据的操作是被禁止的。
字符串可以用==和<进行比较;比较通过逐个字节比较完成的,因此比较的结果是字符串自然编码的顺序。
子字符串操作s[i:j]基于原始的s字符串的第i个字节开始到第j个字节(并不包含j本身)生成一个新字符串。也可以[:j]和[i:]。
字符串遍历:
str := "Hello,世界"n := len(str)for i := 0; i < n; i++ {ch := str[i] // 依据下标取字符串中的字符,类型为bytefmt.Println(i, ch)}//或者:str := "Hello,世界"for i, ch := range str {fmt.Println(i, ch)//ch的类型为rune}
记住,在range右边的str实际上是str的一个拷贝,且i和ch是一个固定地址的值。
for range创建了每个元素的副本,而不是直接返回每个元素的引用,如果使用该值变量的地址作为指向每个元素的指针,就会导致错误,在迭代时,返回的变量是一个迭代过程中根据切片依次赋值的新变量,所以值的地址总是相同的,导致结果不如预期。
复合数据类型
数组

数组是一个由固定长度的特定类型元素组成的序列,一个数组可以由零个或多个元素组成。因为数组的长度是固定的,因此在Go语言中很少直接使用数组。
数组是值类型,每次传递都将产生一份副本。当调用一个函数的时候,函数的每个调用参数将会被赋值给函数内部的参数变量,所以函数参数变量接收的是一个复制的副本,并不是原始调用的变量。当然,可以显式地传入一个数组指针,那样的话函数通过指针对数组的任何修改都可以直接反馈到调用者。
var a [3]int // array of 3 integersvar aa [...]int{1, 2, 3} // array of 3 integersfmt.Println(a[0]) // print the first elementfmt.Println(a[len(a)-1]) // print the last element, a[2]// Print the indices and elements.for i, v := range a {fmt.Printf("%d %d\n", i, v)}// Print the elements only.for _, v := range a {fmt.Printf("%d\n", v)}
Slice
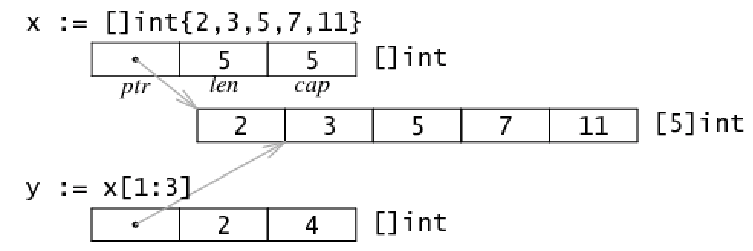
Slice是引用类型,类似于C里的指针,作为函数参数是浅拷贝。
Slice(切片)代表变长的序列,序列中每个元素都有相同的类型。一个slice类型一般写作[]T,其中T代表slice中元素的类型;slice的语法和数组很像,只是没有固定长度而已。
类似于std::vector,Slice的数据结构可以抽象成以下三个数据结构:
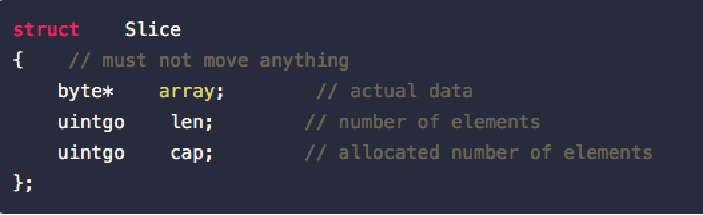
指针指向第一个slice元素对应的底层数组元素的地址,要注意的是slice的第一个元素并不一定就是数组的第一个元素。长度对应slice中元素的数目;长度不能超过容量,容量一般是从slice的开始位置到底层数据的结尾位置。内置的len和cap函数分别返回slice的长度和容量。
slice扩容:
内置的append函数用于向slice追加元素:
var runes []runefor _, r := range "Hello, 世界" {runes = append(runes, r)}fmt.Printf("%q\n", runes) // "['H' 'e' 'l' 'l' 'o' ',' ' ' '世' '界']"mySlice := []int{1, 2, 3}mySlice2 := []int{4, 5, 6}mySlice = append(mySlice, mySlice2...)
内置的append函数可能使用比appendInt更复杂的内存扩展策略。因此,通常我们并不知道append调用是否导致了内存的重新分配,因此我们也不能确认新的slice和原始的slice是否引用的是相同的底层数组空间。同样,我们不能确认在原先的slice上的操作是否会影响到新的slice。因此,通常是将append返回的结果直接赋值给输入的slice变量:
runes = append(runes, r)

slice比较
和数组不同的是,slice之间不能比较,因此我们不能使用==操作符来判断两个slice是否含有全部相等元素。不过标准库提供了高度优化的bytes.Equal函数来判断两个字节型slice是否相等([]byte),但是对于其他类型的slice,我们必须自己展开每个元素进行比较:
func equal(x, y []string) bool {if len(x) != len(y) {return false}for i := range x {if x[i] != y[i] {return false}}return true}
slice唯一合法的比较操作是和nil比较,例如:
if summer == nil { /* ... */ }
一个零值的slice等于nil。一个nil值的slice并没有底层数组。一个nil值的slice的长度和容量都是0,但是也有非nil值的slice的长度和容量也是0的,例如[]int{}或make([]int, 3)[3:]。
如果需要测试一个slice是否是空的,使用len(s) == 0来判断,而不应该用s == nil来判断。
内置的make函数创建一个指定元素类型、长度和容量的slice。容量部分可以省略,在这种情况下,容量将等于长度。
slice创建
make([]T, len)make([]T, len, cap) // same as make([]T, cap)[:len]
在底层,make创建了一个匿名的数组变量,然后返回一个slice;只有通过返回的slice才能引用底层匿名的数组变量。在第一种语句中,slice是整个数组的view。在第二个语句中,slice只引用了底层数组的前len个元素,但是容量将包含整个的数组。额外的元素是留给未来的增长用的。
Go语言支持用myArray[first:last]这样的方式来基于数组生成一个数组切片,而且这个用法还很灵活,比如下面几种都是合法的。
基于myArray的所有元素创建数组切片:
mySlice = myArray[:]
基于myArray的前5个元素创建数组切片:
mySlice = myArray[:5]
基于从第5个元素开始的所有元素创建数组切片:
mySlice = myArray[5:]
创建一个初始元素个数为5的数组切片,元素初始值为0:
mySlice1 := make([]int, 5)
创建一个初始元素个数为5的数组切片,元素初始值为0,并预留10个元素的存储空间:
mySlice2 := make([]int, 5, 10)
直接创建并初始化包含5个元素的数组切片:
mySlice3 := []int{1, 2, 3, 4, 5}
map
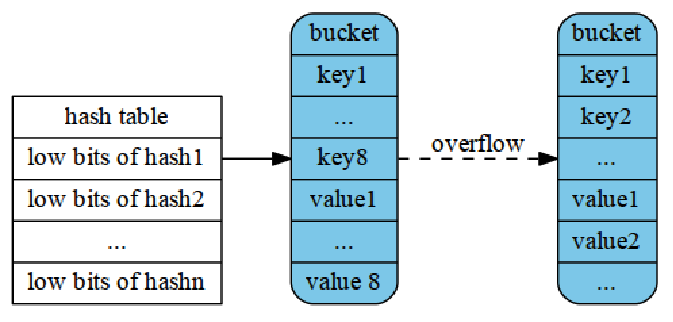
类似于C++的std::unordered_map。在Go语言中,一个map就是一个哈希表的引用,map类型可以写为map[K]V,其中K和V分别对应key和value。map中所有的key都有相同的类型,所有的value也有着相同的类型,但是key和value之间可以是不同的数据类型。其中K对应的key必须是支持==比较运算符的数据类型,所以map可以通过测试key是否相等来判断是否已经存在。虽然浮点数类型也是支持相等运算符比较的,但是将浮点数用做key类型则是一个坏的想法,最坏的情况是可能出现的NaN和任何浮点数都不相等。对于V对应的value数据类型则没有任何的限制。
内置的make函数可以创建一个map:
ages := make(map[string]int) // mapping from strings to ints
我们也可以用map字面值的语法创建map,同时还可以指定一些最初的key/value:
ages := map[string]int{"alice": 31,"charlie": 34,}
这相当于
ages := make(map[string]int)ages["alice"] = 31ages["charlie"] = 34
因此,另一种创建空的map的表达式是map[string]int{}。
Map中的元素通过key对应的下标语法访问:
ages["alice"] = 32fmt.Println(ages["alice"]) // "32"
使用内置的delete函数可以删除元素:
delete(ages, "alice") // remove element ages["alice"]
所有这些操作是安全的,即使这些元素不在map中也没有关系;如果一个查找失败将返回value类型对应的零值,例如,即使map中不存在“bob”下面的代码也可以正常工作,因为ages[“bob”]失败时将返回0。
ages["bob"] = ages["bob"] + 1 // happy birthday!
而且x += y和x++等简短赋值语法也可以用在map上,所以上面的代码可以改写成
ages["bob"] += 1
更简单的写法
ages["bob"]++
但是map中的元素并不是一个变量,因此我们不能对map的元素进行取址操作:
_ = &ages["bob"] // compile error: cannot take address of map element
禁止对map元素取址的原因是map可能随着元素数量的增长而重新分配更大的内存空间,从而可能导致之前的地址无效。
要想遍历map中全部的key/value对的话,可以使用range风格的for循环实现,和之前的slice遍历语法类似。下面的迭代语句将在每次迭代时设置name和age变量,它们对应下一个键/值对:
for name, age := range ages {fmt.Printf("%s\t%d\n", name, age)}
map上的大部分操作,包括查找、删除、len和range循环都可以安全工作在nil值的map上,它们的行为和一个空的map类似。但是向一个nil值的map存入元素将导致一个panic异常:
ages["carol"] = 21 // panic: assignment to entry in nil map
在向map存数据前必须先创建map。
要从map中查找一个特定的键,可以通过下面的代码来实现:
value, ok := myMap["1234"]if ok { // 找到了// 处理找到的value}

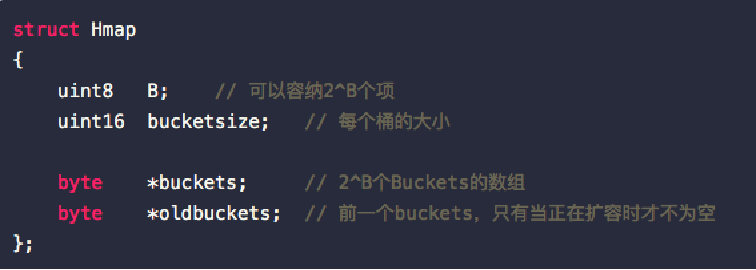
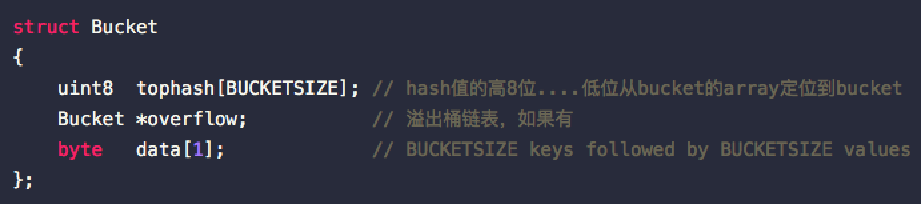
map扩容
- 哈希表大小始终为2的指数倍,每次扩容都变为原来大小的两倍。如,扩容前的哈希表大小为2^B,扩容之后的大小为2^(B+1);
- 扩容后,需将旧的pair重新哈希到新的table上,该过程并非一次到位,而是逐步完成,如,insert或remove时每次搬移1-2个pair;只有所有的bucket都从旧表移到新表之后,才会将oldbucket释放掉。
- 扩容时机(扩容填充因子):如果grow的太频繁,会造成空间的利用率很低, 如果很久才grow,会形成很多的overflow buckets,查找的效率也会下降。
define LOAD 6.5:如果table中元素的个数大于table中能容纳的元素个数的65%,则触发扩容。
注意事项:golang内建map不是并发安全的,解决方案: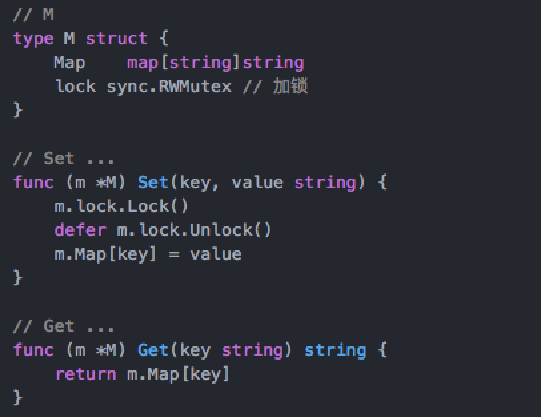

若有收获,就点个赞吧
0 人点赞
