- Introduction
- Benefits of using HyperBDR:
- 1.Lower TCO of cloud Disaster Recovery compared to traditional Disaster Recovery
- 2.Support AWS automated Disaster Recovery, one-click launch of workloads in the cloud
- 4.Minute-level RPO and RTO
- 5.Three-step wizard design, easy operation
- 6.Cloud-based drills ensure uninterrupted operations
- 7.Support Disaster Recovery of different architecture platforms to AWS
- Technical Advantages of HyperBDR:
Introduction
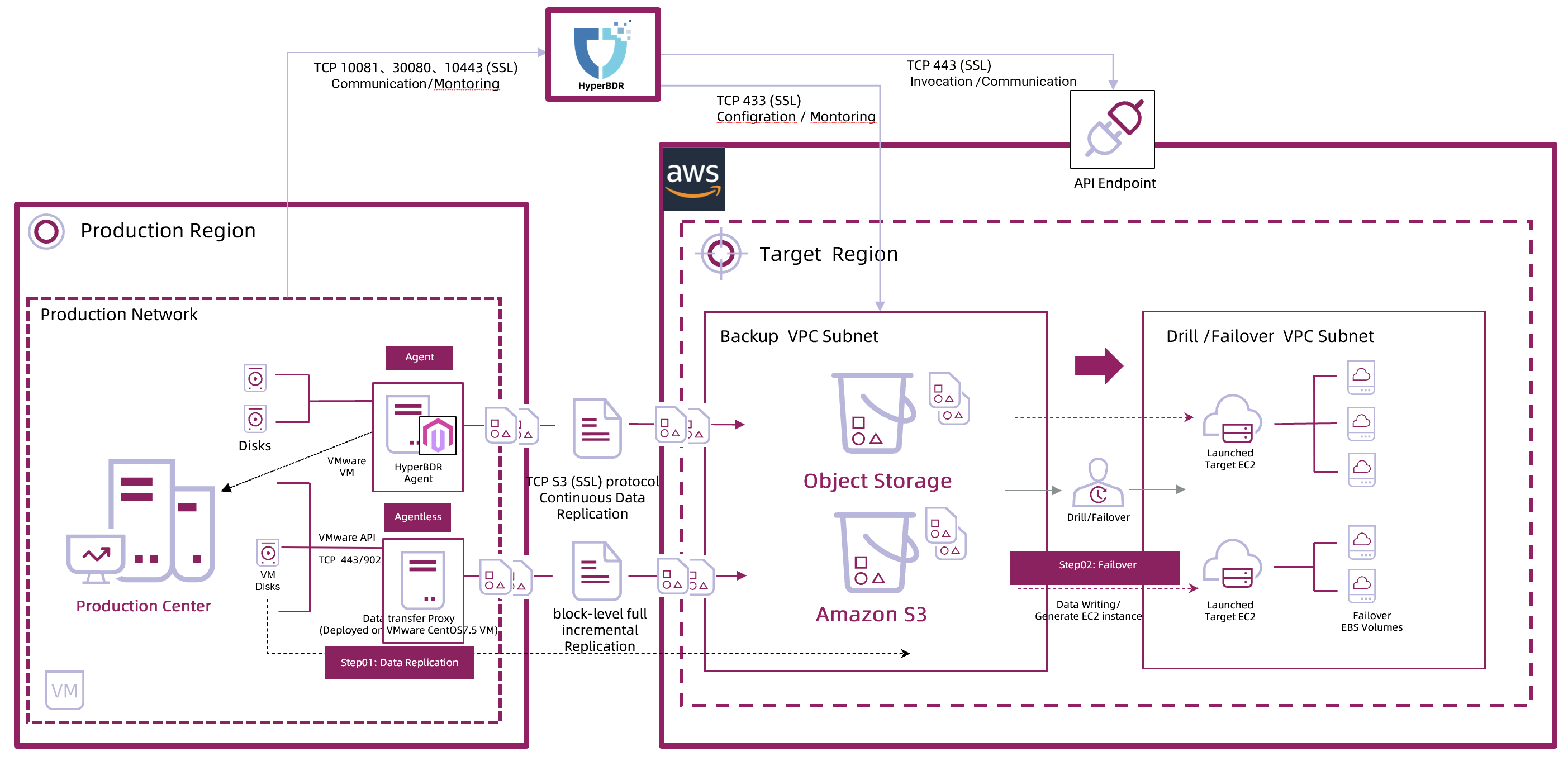
HyperBDR is a cloud-native business-level Disaster Recovery tool that fully utilizes cloud-native capabilities to improve Disaster Recovery efficiency and reduce TCO. It adopts block-level full incremental replication technology with high backup efficiency; Hostless Data Sync Technology makes Disaster Recovery data storage costs lower and data can flow more freely across platforms. Its self-developed “Boot-in-Cloud” technology supports one-click restoration of business to an available state in the cloud, while its cloud-native orchestration capabilities ensure business resources are one-click disaster-resilient, ensuring business continuity and high availability. HyperBDR supports more than 20 clouds with 40+ versions.
What is HyperBDR?
HyperBDR is a cloud-native business-level Disaster Recovery tool that can be used in various business scenarios, including Disaster Recovery between traditional IDC physical and virtualization environments and the cloud, as well as between public, private and dedicated clouds. HyperBDR can quickly recover Windows, CentOS, Red Hat Enterprise Linux (RHEL), SUSE Linux Enterprise Server (SLES), Ubuntu and other systems to the target platform and provide continuous business protection.
Benefits of using HyperBDR:
1.Lower TCO of cloud Disaster Recovery compared to traditional Disaster Recovery
Unlike traditional Disaster Recovery methods, which require a duplicate set of infrastructure correspond to the production centre’s potential failure or malfunction, which may take months or even years to build and include costs such as data centre operations, servers, storage devices, security equipment, network equipment, electricity expenses… etc. HyperBDR with AWS cloud can help enterprises save the above-mentioned operation, equipment, construction and maintenance costs.
2.Support AWS automated Disaster Recovery, one-click launch of workloads in the cloud
In the configuration stage of traditional Disaster Recovery model, the Disaster Recovery platform host must be started in advance for data synchronization, the configuration process is complex and wastes of resources. HyperBDR has completed automation integration with AWS, no host needs to be started on the target platform during the routine data protection process. Instead, the system data, including the operating system, applications and data are stored in object storage, reducing storage costs by 95% compared to traditional Disaster Recovery. Its self-developed Boot-in-Cloud technology automatically creates a protected host on AWS and activates business operations with one click when a disaster occurs.
3.Pay-as-you-go, low cost with high scalability HyperBDR transforms the traditional procurement model into a delivery model that uses AWS cloud services. The resources are available immediately, enabling quick deployment and the shortening the process of cloud Disaster Recovery construction significantly, making it a universal service. During Disaster Recovery, enterprises only need to pay for the storage resources, do not occupy computing resources and the Disaster Recovery storage cost is extremely low. In the event of a drill or failover, cloud resources can be paid for by usage.
4.Minute-level RPO and RTO
Enterprises can customize snapshot strategies through HyperBDR based on the actual needs of their business. HyperBDR will perform continuous data replication based on the set snapshot strategy. When a disaster occurs, customers can use HyperBDR to activate business operations with one click on AWS cloud and recover to the nearest snapshot time point, achieving minute-level RPOs and RTOs.
5.Three-step wizard design, easy operation
Traditional backup and Disaster Recovery deployment processes are complex. First, a host cluster of the same scale and specifications as the source end needs to be created at the target end. It takes about 20 steps to create a host, including but not limited to basic configuration, network and security group selection and system configuration. The more the hosts, the longer it takes and the higher error rate for manual operations. HyperBDR uses a simple 3-step wizard design for Disaster Recovery deployment: [1. Select Host -> 2. DR Configuration -> 3. Start DR]. Operations personnel without much technical skills can operate it easily, greatly reducing the threshold for cloud Disaster Recovery and improving the efficiency while avoiding human error.
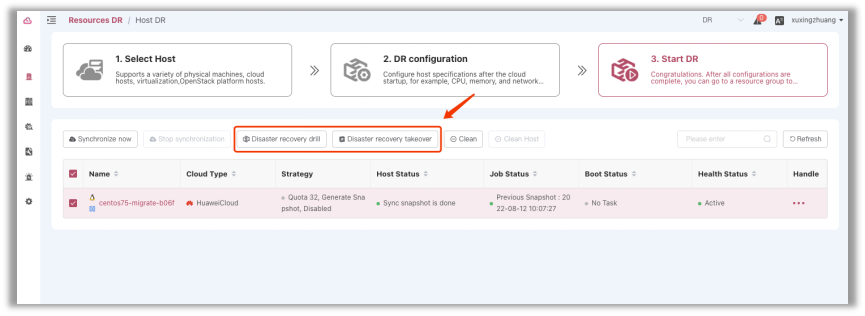
6.Cloud-based drills ensure uninterrupted operations
Upon the completion of the Disaster Recovery solution deployment, customers can conduct regular Disaster Recovery drills based on their actual needs to ensure the high availability of their Disaster Recovery plans. Leveraging the highly automated features of HyperBDR and its ability to launch business operations in the cloud without a host, customers can launch Disaster Recovery drills with just one click. They can then recover their business to any specified point in time based on custom snapshot policies, restoring the corresponding system data and status without affecting the production environment.
Enterprises can also take full advantage of their Disaster Recovery environment to carry out drills, drilling, simulation and retrospective analysis of security incidents, enhancing the utilization of their Disaster Recovery resources.
7.Support Disaster Recovery of different architecture platforms to AWS
With the development of cloud computing, enterprises are gradually transitioning their business architecture from a single traditional on-premise architecture to a more complex hybrid cloud architecture; the flow of data between different architectures is hindered. HyperBDR is compatible with different architectures, including physical machines, virtual machines, hyper-converged platforms, public clouds and private clouds. It supports Disaster Recovery from different architecture platforms to AWS, enabling data mobility
Technical Advantages of HyperBDR:
1.Boot in Cloud Technology
HyperBDR utilizes object storage to store backup data, making full use of the dozens of APIs available on the AWS cloud platform for resource creation, retrieval, management and orchestration. This enables the rapid construction and deployment of AWS-based Disaster Recovery applications, achieving true cloud-native Disaster Recovery. After the Disaster Recovery configuration is complete, there is no need to pre-start computing instances. In the event of a disaster, the backup business system can be launched with a single click on the AWS side, bringing it to an available state and directly restoring it to the login page of the operating system, achieving minute-level RTO.
Enterprises can achieve the following with HyperBDR:
▶ From traditional IDC Disaster Recovery to AWS.
▶ From VMware Disaster Recovery to AWS (supporting agentless mode on the source platform).
▶ From OpenStack Disaster Recovery to AWS (supporting agentless mode on the source platform).
▶ From other clouds Disaster Recovery to AWS.
▶ Cross-availability zone Disaster Recovery within AWS.
▶ Cross-region Disaster Recovery within AWS.
2.Intelligent Adaptation
Due to differences in underlying architectures between traditional IDCs, virtual machines and clouds; compatibility issues may arise during Disaster Recovery between the source and target infrastructures and applications. HyperBDR has completed intelligent driver adaptation for multiple architecture platforms. During the Disaster Recovery configuration process, no manual intervention is required for driver repairs, achieving a highly automated AWS Disaster Recovery deployment and improving the efficiency and success rate.
3.Hostless Data Sync Technology
Unlike traditional Disaster Recovery, HyperBDR does not require the use of target platform hosts to synchronize data during Disaster Recovery. Instead, it innovatively slices the block data of the source-side host and stores it in AWS object storage. Only when restoring is required, the slices are combined into blocks and leveraging the cloud-native capability to restore them into the hosts. This approach means that Disaster Recovery no longer consumes any computing resources on the target platform, reducing Disaster Recovery storage costs to an extremely low level of around US$0.022/GB per year. In addition, using object storage for data transmission in the AWS environment does not incur any additional fees, resulting in a significant reduction in Disaster Recovery TCO.
Object storage also guarantees the security and accuracy of data during Disaster Recovery:
▶ Amazon S3 object storage can use industry-standard encryption methods (such as AES-256) to encrypt data in transit and at rest, ensuring that data is not subject to unauthorized access or tampering during transport or storage in the cloud.
▶ Object storage can provide object-level locking, allowing enterprises to lock objects in read-only mode, preventing any further modifications to ensure that data remains unchanged during Disaster Recovery.
4.Resource Group Disaster Recovery
Based on cloud-native orchestration capabilities, HyperBDR can support the recovery of machine groups which makes Disaster Recovery management more efficient. Enterprises can manage and orchestrate machine groups based on business type, business importance level and location. In the event of a disaster, enterprises can directly launch the affected machine group or gradually launch applications according to their importance, improving Disaster Recovery efficiency, reducing RPO and RTO, minimizing enterprise losses.
HyperBDR Network Architecture (Diagram)

若有收获,就点个赞吧
0 人点赞
