数组
数组作为数据存储结构的缺陷
- 在无序数组中,搜索是低效的
- 而在有序数组中插入效率又很低
- 不管在哪一种数组中删除效率都很低
-
链表
链表是一种有序的列表
- 链表的内容通常存储与内存中分散的位置上
- 链表由节点组成,每一个节点的结构都相同
节点分为数据域和链域,数据域是存放节点的内容,链域存放的是下一个节点的指针
用编程的思想来理解链表以及节点的关系:
一个链表中有许多类似的节点,所以有必要用一个描述节点的类来表达节点,这个类我们称为Node;
每个Node对象中都包含一个表示该节点内容的数据部分,我们称为数据域,和一个对下一个节点引用的字段next,即链域
单向循环链表(循环链表)
循环链表与单链表的区别仅仅在于其尾节点的链域值不是null,而是一个指向头节点的引用
循环链表的优点:
从表中任一节点出发都能通过后移操作而扫描整个循环链表。
在单链表中,每个节点所含的链城指向其后继节点,故从任一节点找其后继很方便;但要找前趋节点则比较困难。
查找算法
蓝色是非常重要的
遍历(暴力)
- 二分法 (需要有序)
- 哈希(最高效)
- 插值
- 索引:搜索引擎,Lucence
- bfs&dfs:图论里面的遍历
- 平衡树
- B+树
- B-tree
- 红黑树
- 二叉搜索树
二分查找
需要有顺序,它可以转成数据结构—》二叉查找树(二叉树)
二叉树
- 左边节点小,右边节点大
- 时间复杂度就是数的深度:最优O(logn),有可能为O(n)
二叉查找树
可以是下面两种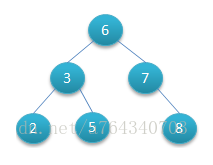

但是右边的二叉树的查询效率就低了。因此若想二叉树的查询效率尽可能高,需要这棵二叉树是平衡的,从而引出新的定义——平衡二叉树,或称AVL树。
平衡二叉树
平衡二叉树(AVL树)在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。下面的两张图片,左边是AVL树,它的任何节点的两个子树的高度差<=1;右边的不是AVL树,其根节点的左子树高度为3,而右子树高度为1;
如果在AVL树中进行插入或删除节点,可能导致AVL树失去平衡,这种失去平衡的二叉树可以概括为四种姿态:LL(左左)、RR(右右)、LR(左右)、RL(右左)。 这四种失去平衡的姿态都有各自的定义: LL:LeftLeft,也称“左左”。插入或删除一个节点后,根节点的左孩子(Left Child)的左孩子(Left Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。 RR:RightRight,也称“右右”。插入或删除一个节点后,根节点的右孩子(Right Child)的右孩子(Right Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。 LR:LeftRight,也称“左右”。插入或删除一个节点后,根节点的左孩子(Left Child)的右孩子(Right Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。 RL:RightLeft,也称“右左”。插入或删除一个节点后,根节点的右孩子(Right Child)的左孩子(Left Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。 AVL树失去平衡之后,可以通过旋转使其恢复平衡。下面分别介绍四种失去平衡的情况下对应的旋转方法。
LL的旋转。LL失去平衡的情况下,可以通过一次旋转让AVL树恢复平衡。步骤如下:
- 将根节点的左孩子作为新根节点。
- 将新根节点的右孩子作为原根节点的左孩子。
- 将原根节点作为新根节点的右孩子。
如下图:
RR的旋转:RR失去平衡的情况下,旋转方法与LL旋转对称,步骤如下:
- 将根节点的右孩子作为新根节点。
- 将新根节点的左孩子作为原根节点的右孩子。
- 将原根节点作为新根节点的左孩子。
LR的旋转:LR失去平衡的情况下,需要进行两次旋转,步骤如下:
- 围绕根节点的左孩子进行RR旋转。
- 围绕根节点进行LL旋转。
RL的旋转:RL失去平衡的情况下也需要进行两次旋转,旋转方法与LR旋转对称,步骤如下:
- 围绕根节点的右孩子进行LL旋转。
- 围绕根节点进行RR旋转。

红黑树
底层数据结构就是二叉查找数
- 每个节点不是红色就是黑色
- 红色节点不能相连
- 根节点都是黑色root(没有父节点的结点叫根节点)
- 叶子结点都是黑色
- 从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
为了满足红黑树的性质,出现的旋转
红黑树有三种变换规则:
- 改变颜色
- 左旋
- 右旋
旋转和颜色变换规则:所有插入的点默认为红色
1.变颜色的情况:当前结点的父亲是红色,且它的祖父结点的另一个子结点
也是红色。(叔叔结点):
(1)把父节点设为黑色
(2)把叔叔也设为黑色
(3)把祖父也就是父亲的父亲设为红色(爷爷)
(4)把指针定义到祖父结点设为当前要操作的(爷爷)分析的点变换的规则
2.左旋:当前父结点是红色,叔叔是黑色的时候,且当前的结点是右子树。左旋
以父结点作为左旋。
3.右旋:当前父结点是红色,叔叔是黑色的时候,且当前的结点是左子树。右旋
(1)把父结点变为黑色
(2)把祖父结点变为红色(爷爷)
(3)以祖父结点旋转(爷爷)TreeMapJDK1.8大学给小学弟()
插入6的时候,红黑树的规则 符合变换颜色的规则,先变换颜色
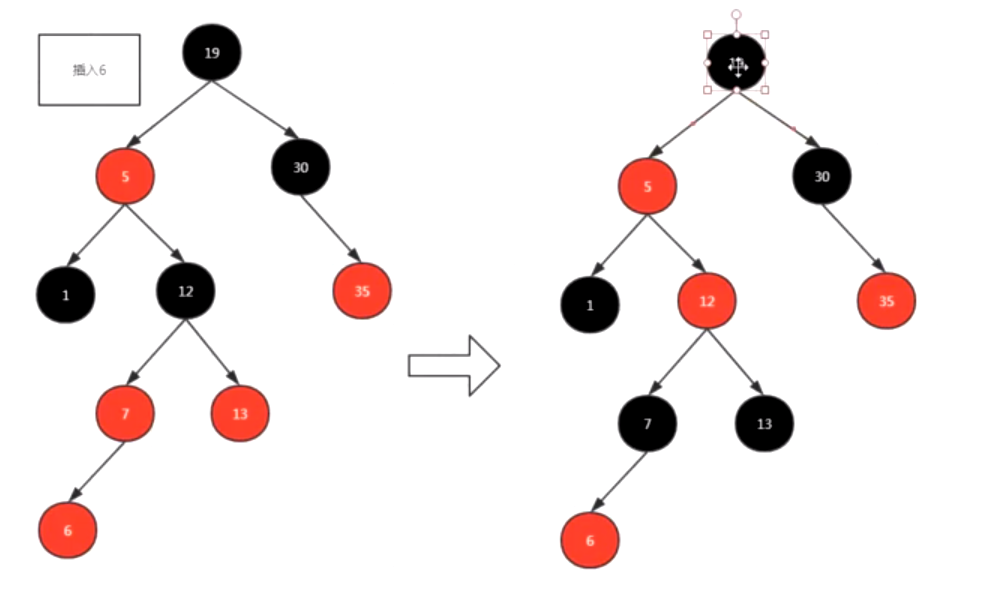
(右上图)还是不满足红黑树规则,但是符合左旋规则,进行左旋到 (左下图)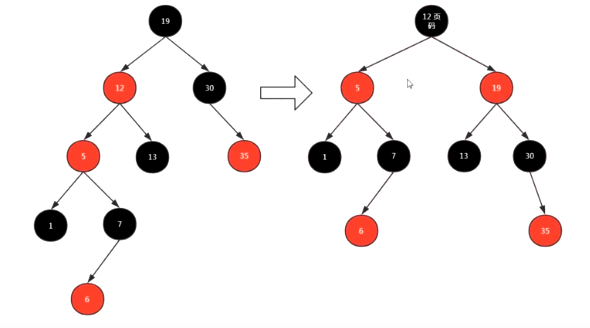
左上图还是不满足规则,但是符合右旋规则,进行右旋为(右上图)最后满足红黑树规则
疑问:HashMap1.8为什么要用红黑树:
为了解决hash冲突
红黑树的颜色是保证红黑树查找速度的一种方式,从任意的节点开始到叶节点的路径,黑节点的个数是相同的,这就能保证搜索路径的最大长度不超过搜索路径的最短长度的2倍。
红黑树有什么应用呢?
大多数自平衡BST(self-balancing BST) 库函数都是用红黑树实现的,比如C++中的map 和 set (或者 Java 中的 TreeSet 和 TreeMap)。红黑树也用于实现 Linux 操作系统的 CPU 调度。完全公平调度(Completely Fair Scheduler)使用的就是红黑树。
作者:程序员景禹
链接:https://www.zhihu.com/question/30317295/answer/1246106121
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
B-Tree(平衡多路查找树)
B树,N叉的排序树 :有序的数组+平衡多叉树 特性:
- 结点最多含有m颗子树(指针),m-1个关键字(数据)(m>=2):
- 除根结点和叶子结点外,其它每个结点至少有ceil(m/2)个子节点(子树),ceil为上取整;5/2=2.5取整,分裂 Ceil取上整数2.5=>3;2.1=>3
- 若根节点不是叶子节点,则至少有两颗子树。
BTree 有一个重要的操作,当一颗树不满足以上性质的时候会 分裂 BTree 中每个节点都包含卫星数据(索引元素所指向的数据记录),每个节点中每个元素都包含一个指针指向卫星数据,浪费空间
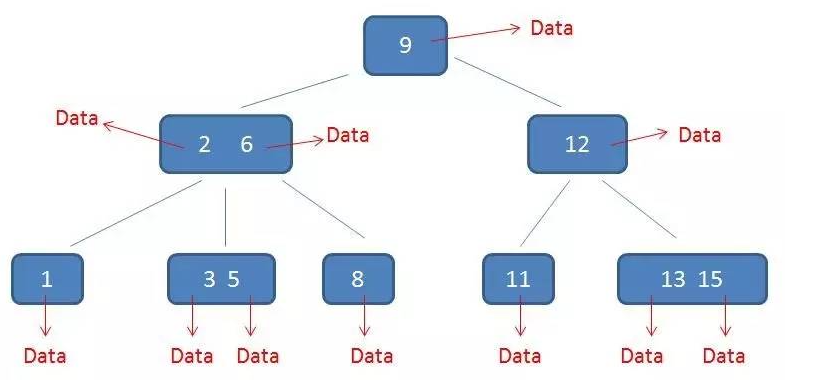
mysql为什么不用hash索引?
- HASH索引本身只存储对应的HASH值和行指针,而不是存储字段值
- HASH索引并不是按照索引顺序来存储的,因此无法排序
- HASH索引不支持部分索引列查找,因为HASH索引是使用全部的内容来计算HASH值的 例如在(A,B)两列建立索引,只查询A无法使用索引
- HASH索引只支持等值比较查询,包括 =、IN()不能进行任何的范围查询
- 最严重的是既然HASH值是数字,肯定会出现相同的,也就是HASH冲突
- 出现HASH冲突的时候,存储引擎必须遍历链表中所有的行指针,逐行进行比较,直到找到所有符合条件的行
当HASH冲突特别多的时候,维护操作的成本就会变大,比如一次数据的删除 引擎需要遍历对应HASH值链表上的每一行,找到并删除对应的引用,冲突越多,代价越大
为什么红黑树不能用于mysql索引?
读取磁盘次数过多IO次数过多
- 浪费性能(红黑树的树高)而b+tree是三层发生三次IO
为什么红黑树可以用于HashMap的查找呢?
因为这个是存在内存中,这个查找快
B+Tree
有序的数组链表+平衡多叉树
特性:
- 元素和子树个数相等
- 每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。(链表)
- 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
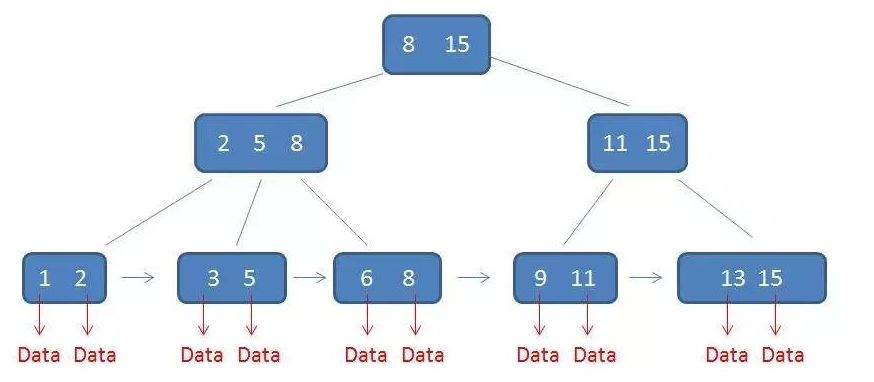
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
InnoDB的一棵B+树可以存放多少行数据?
约2千万

若有收获,就点个赞吧
0 人点赞
