SQLite
目录
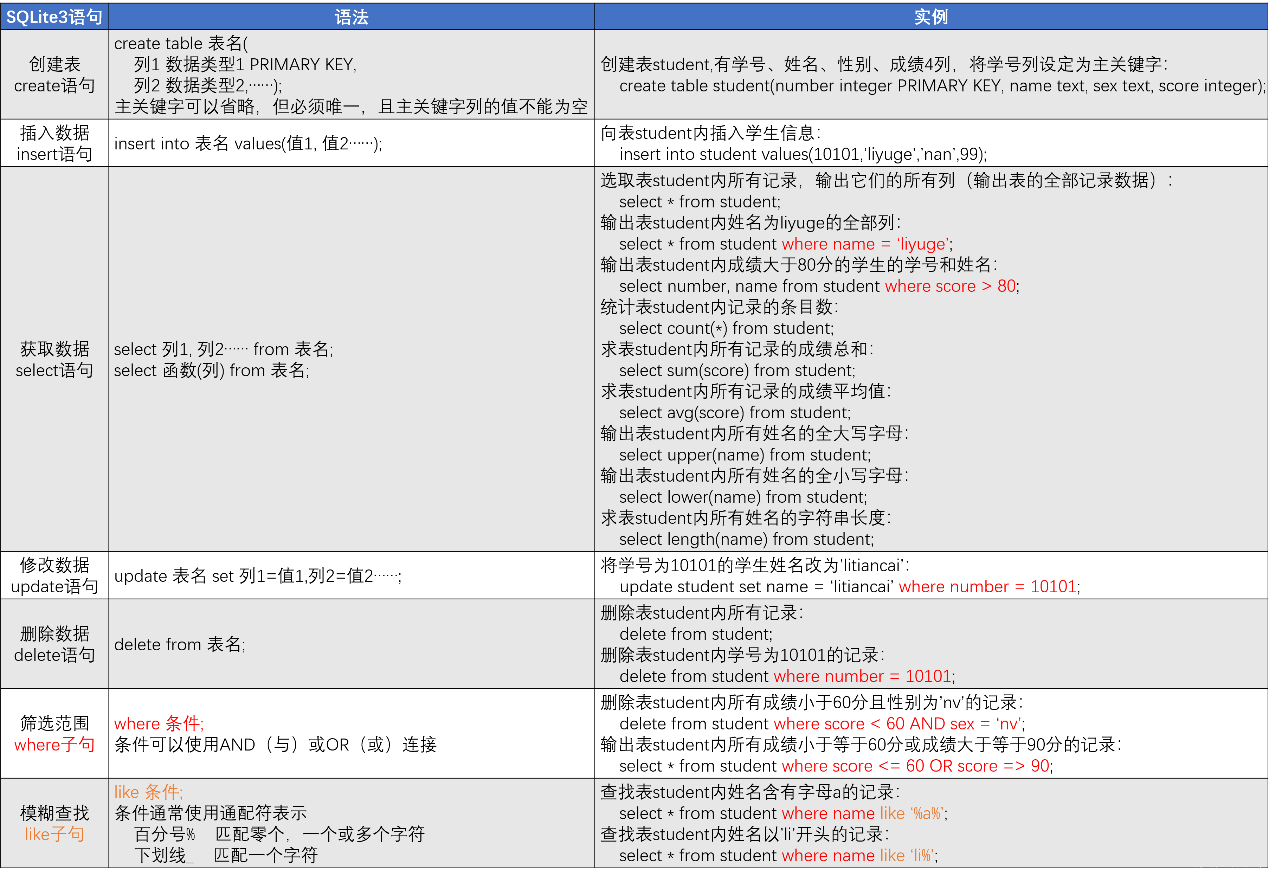
常见命令
创建数据库文件
Excel表格数据导入数据库文件
创建表和删除表
SQLite3支持的基本数据类型
SQLite 约束
创建表
删除表
显示表头与对齐
INSERT INTO添加
Select 语句
SQLite 表达式
布尔表达式
AND 运算符
OR 运算符
数值表达式
日期表达式
Update 修改
Delete 删除
Like 匹配
Glob 子句匹配
Limit语句
配合OFFSET
Order By排序
常用聚合函数
Group By分组
Having过滤
Distinct 关键字
**
常见命令

创建数据库文件
sqlite3+数据库名.db 的方式可以打开数据库文件,如果该数据库文件不存在,则创建一个
使用 .database 可以查看创建的数据库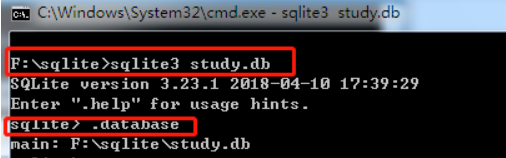
使用 .quit 命令退出sqlite提示符
**
Excel表格数据导入数据库文件
示例:
1、 将Excel之中存储的数据另存为csv的格式bookroom.csv(有中文的话要用utf-8编码保存),(若已经建立过表和表头,则excel中只要数据即可。若没有建立表,则表中第一行是表头)。
示例已建立表。
Excel数据:
2、 利用sqlite3的import命令将数据从文件导入到表中,在执行import之前需要用.separator命令设置数据的分隔符逗号,否则默认的分割符号是竖线’|’。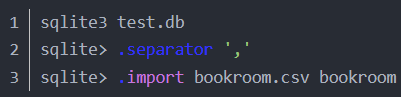
3、 这样数据就导入到了bookroom表中了,如下测试
**
创建表和删除表
SQLite3支持的基本数据类型

SQLite 约束
以下是在 SQLite 中常用的约束。
l NOT NULL 约束:确保某列不能有 NULL 值。
l DEFAULT 约束:当某列没有指定值时,为该列提供默认值。
l UNIQUE 约束:确保某列中的所有值是不同的。
l PRIMARY Key 约束:唯一标识数据库表中的各行/记录。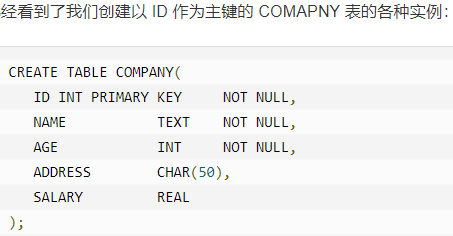
l CHECK 约束:CHECK 约束确保某列中的所有值满足一定条件。
在 SQLite 中,ALTER TABLE 命令允许用户重命名表,或向现有表添加一个新的列。重命名列,删除一列,或从一个表中添加或删除约束都是不可能的
创建表
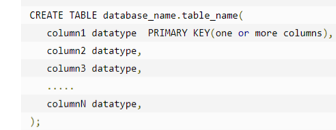
CREATE TABLE 语句后跟着表的唯一的名称或标识。您也可以选择指定带有 table_name 的 database_name。
实例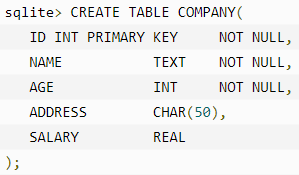
可以使用 .schema 命令得到表的完整信息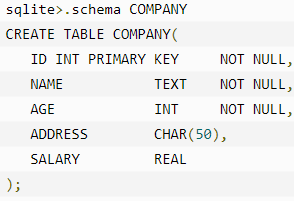
删除表


显示表头与对齐
“.header on” 启用表头
“.mode column” 使用列模式
列操作



INSERT INTO添加
INSERT INTO 语句有两种基本语法
 (没有中括号)
(没有中括号)
l 在这里,column1, column2,…columnN 是要插入数据的表中的列的名称。

l 如果要为表中的所有列添加值,您也可以不需要在 SQLite 查询中指定列名称。但要确保值的顺序与列在表中的顺序一致。
实例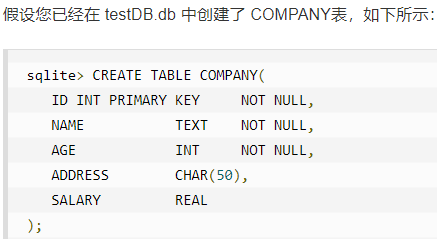
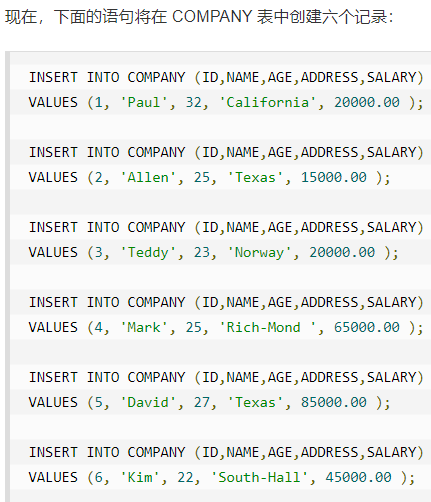

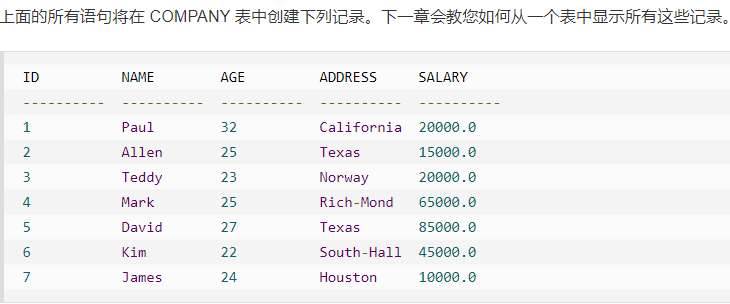
**
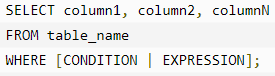
Select 语句
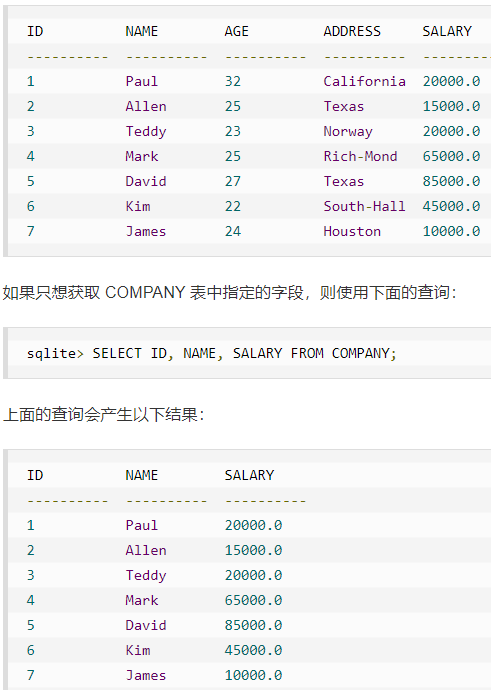
SELECT 语句用于从 SQLite 数据库表中获取数据,以结果表的形式返回数据。这些结果表也被称为结果集。
如果您想获取所有可用的字段
Update 修改
UPDATE 查询用于修改表中已有的记录。可以使用带有 WHERE 子句的 UPDATE 查询来更新选定行,否则所有的行都会被更新。
例子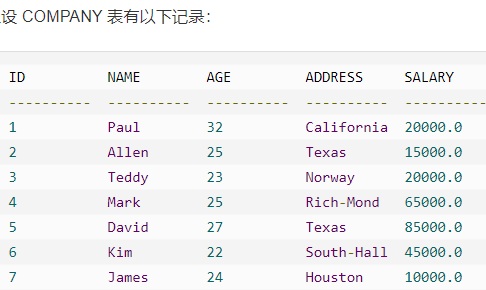

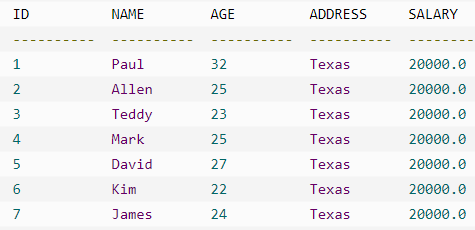
如果想修改 COMPANY 表中 ADDRESS 和 SALARY 列的所有值,则不需要使用 WHERE 子句。
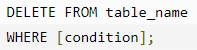
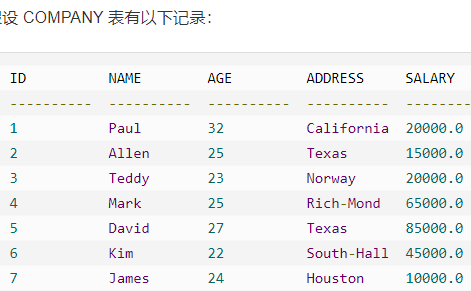
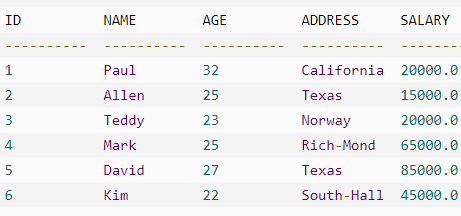
Delete 删除

SQLite 表达式
布尔表达式
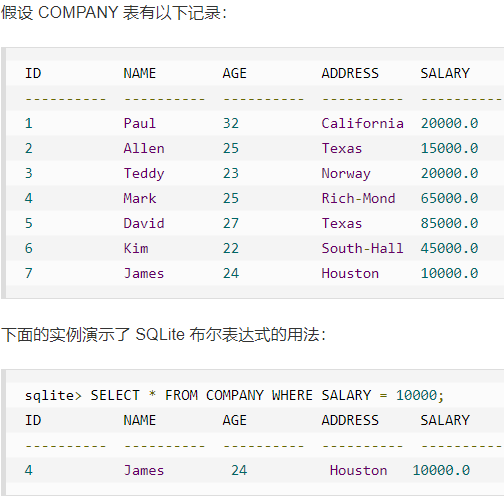
AND 运算符
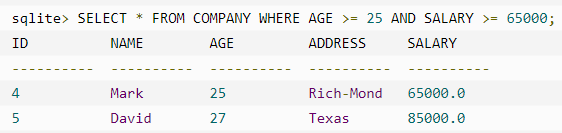
OR 运算符
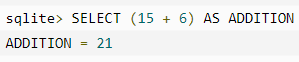
数值表达式

日期表达式

Like 匹配
LIKE 运算符是用来匹配通配符指定模式的文本值。
如果搜索表达式与模式表达式匹配,LIKE 运算符将返回真(true),也就是 1。
这里有两个通配符与 LIKE 运算符一起使用:
l 百分号 (%)—-代表零个、一个或多个数字或字符。
l 下划线 (_)——代表一个单一的数字或字符。
例子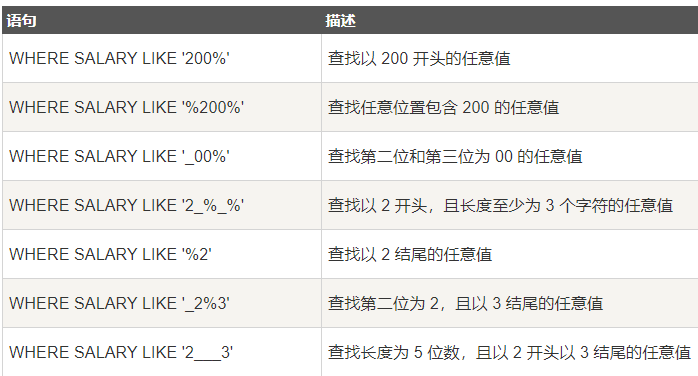
Glob 子句匹配
GLOB 运算符是用来匹配通配符指定模式的文本值。
如果搜索表达式与模式表达式匹配,GLOB 运算符将返回真(true),也就是 1。
与 LIKE 运算符不同的是,GLOB 是大小写敏感的。
对于下面的通配符,它遵循 UNIX 的语法。
l 星号 (*)——代表零个、一个或多个数字或字符。
l 问号 (?)——代表一个单一的数字或字符
例子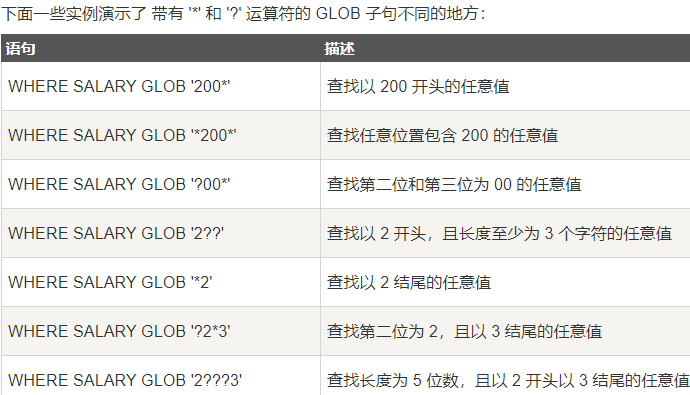
Limit语句
LIMIT 子句用于限制由 SELECT 语句返回的数据数量。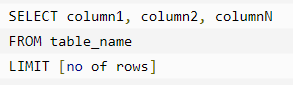
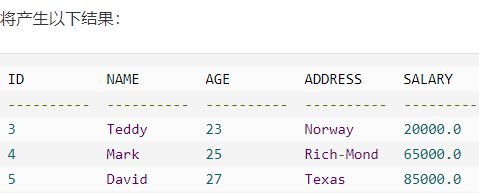
例子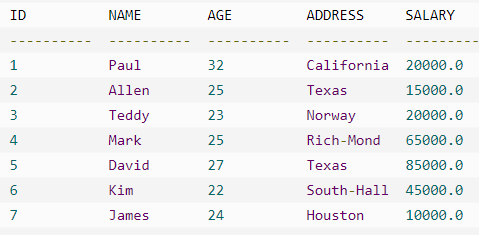

会返回前六行
配合OFFSET

Order By排序
ORDER BY 子句是用来基于一个或多个列按升序或降序顺序排列数据。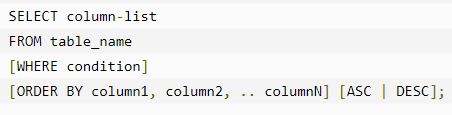
ASC :升序
DESC:降序
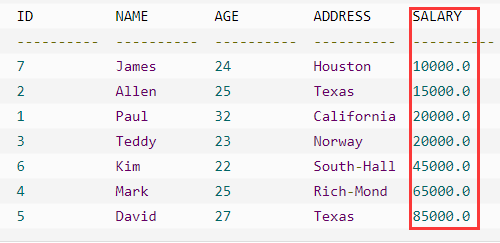
例子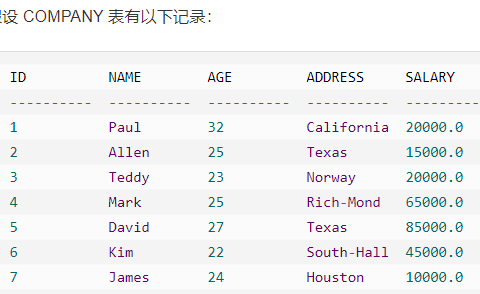
常用聚合函数
l count() 计数
l sum() 求和
l avg() 平均数
l max() 最大值
l min() 最小值
Group By分组
GROUP BY 子句用于与 SELECT 语句一起使用,来对相同的数据进行分组。
在 SELECT 语句中,GROUP BY 子句放在 WHERE 子句之后,放在 ORDER BY 子句之前。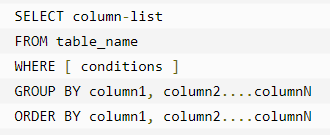
例子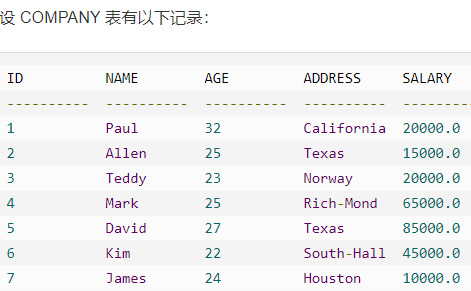

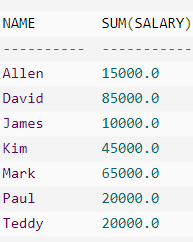

ORDER BY 子句可以与 GROUP BY 子句一起使用
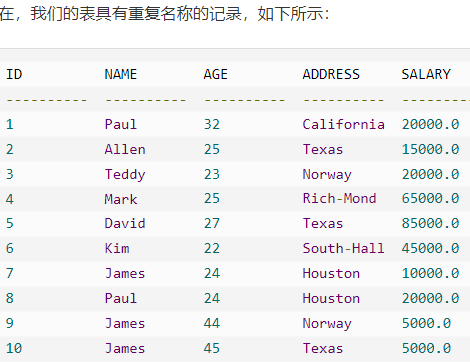

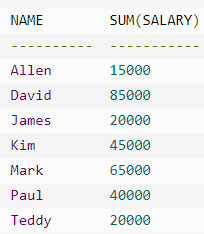
重复项被合并了
Having过滤
HAVING 子句允许指定条件来过滤将出现在最终结果中的分组结果。
在一个查询中,HAVING 子句必须放在 GROUP BY 子句之后,必须放在 ORDER BY 子句之前。下面是包含 HAVING 子句的 SELECT 语句的语法: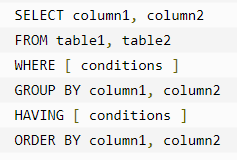
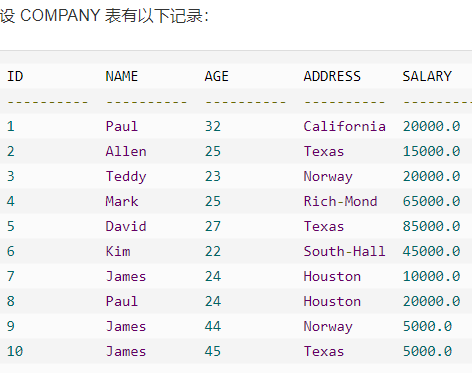

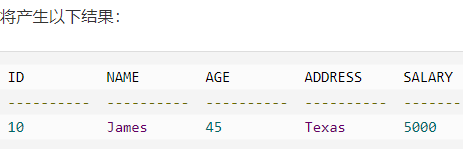
Distinct 关键字
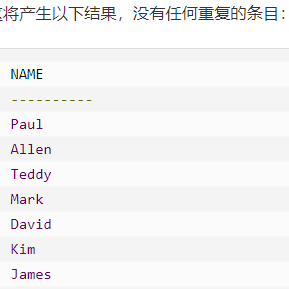
DISTINCT 关键字与 SELECT 语句一起使用,来消除所有重复的记录,并只获取唯一一次记录。
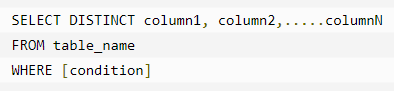
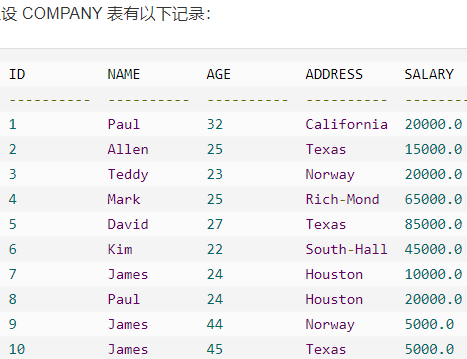
 `
`
若为下面命令,则会将所有名字展示,有重复
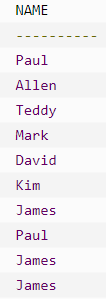

若有收获,就点个赞吧
0 人点赞
