为避免因歧义而产生混淆,本书中使用的术语定义如下:
算法是机器为实现特定目标而遵循的一组规则。算法可以被视为一个配方,定义输入、输出以及从输入到输出所需的所有步骤。烹饪食谱是一种算法,其中配料是输入,熟食是输出,准备和烹饪步骤是算法指令。
机器学习是一组方法,允许计算机从数据中学习以做出和改进预测(例如癌症、每周销售额、信用违约)。机器学习是一种范式的转变,从所有指令必须明确地提供给计算机的“正常编程”转变为通过提供数据进行的“间接编程”。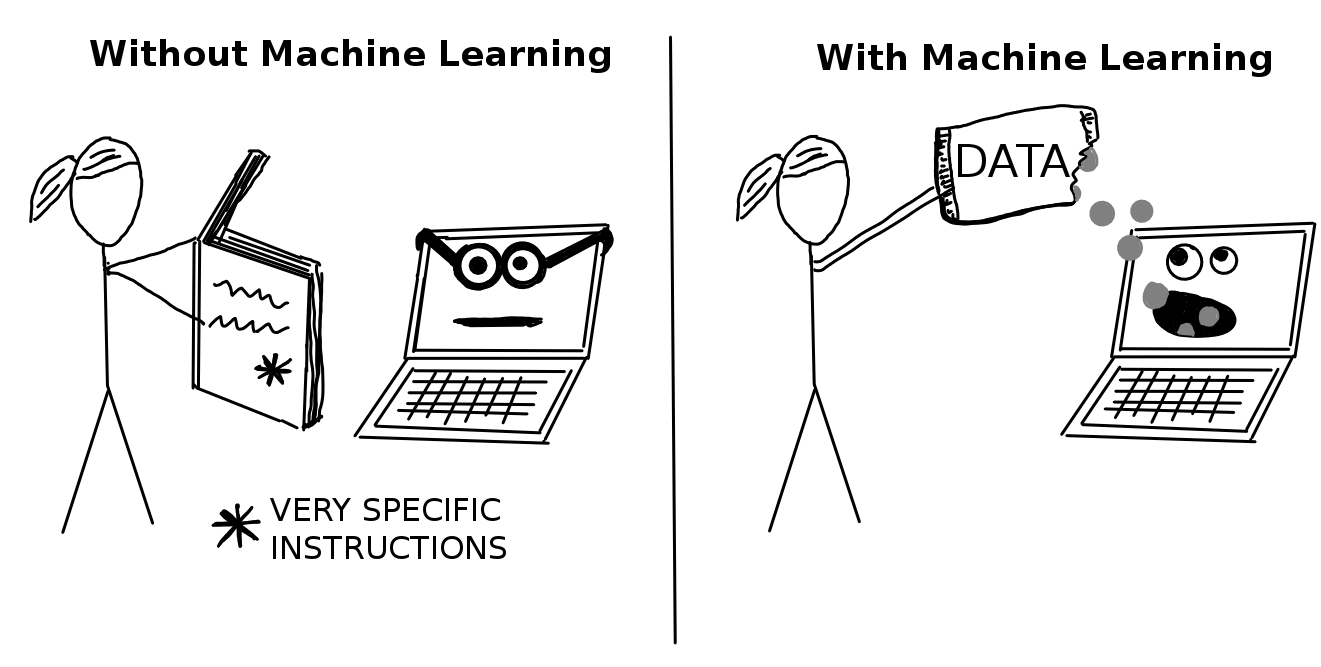
学习者或机器学习算法是用于从数据中学习机器学习模型的程序。另一个名称是“诱导剂”(例如“树木诱导剂”)。
机器学习模型是将输入映射到预测的学习程序。这可以是线性模型或神经网络的一组权重。“模型”这个不太明确的词的其他名称是“预测因子”或“分类器”或“回归模型”,具体取决于任务。在公式中,经过训练的机器学习模型称为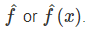
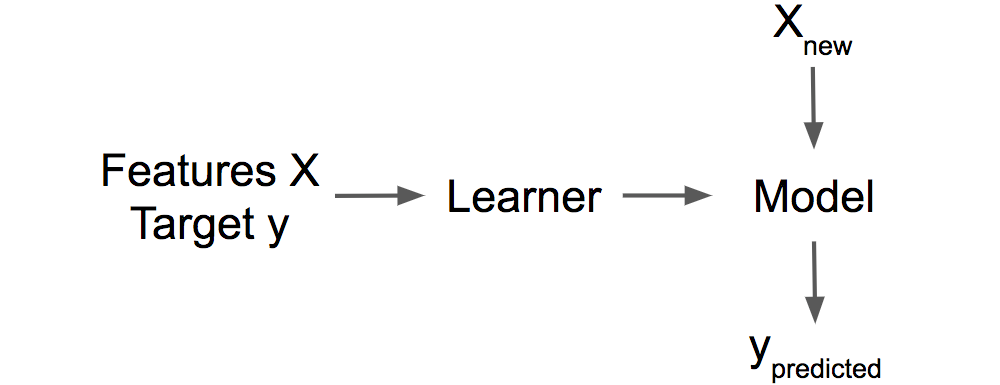
图1.1:学员从标记的培训数据学习模型。该模型用于进行预测。
黑箱模型是一个不揭示其内部机制的系统。在机器学习中,“黑匣子”描述了无法通过查看其参数(例如神经网络)来理解的模型。黑盒子的反面有时被称为白盒子,在本书中被称为可解释模型。模型不可知的可解释性方法将机器学习模型视为黑箱,即使它们不是。
可解释机器学习是指使机器学习系统的行为和预测为人类所理解的方法和模型。
数据集是一个包含机器从中学习的数据的表。数据集包含要预测的特征和目标。当用于归纳模型时,数据集称为训练数据。
实例是数据集中的一行。“实例”的其他名称包括:(数据)点、示例、观察。实例由特征值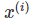 组成并且如果知道,目标结果是
组成并且如果知道,目标结果是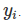 。
。
特征是用于预测或分类的输入。要素是数据集中的一列。在整本书中,特征被认为是可解释的,这意味着很容易理解它们的含义,比如某一天的温度或一个人的身高。特征的可解释性是一个很大的假设。但是如果很难理解输入特性,那么就更难理解模型的功能。具有所有特征的矩阵称为X和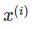 就一个例子来说。所有实例的单个特征向量为
就一个例子来说。所有实例的单个特征向量为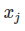 特征j和实例i的值为
特征j和实例i的值为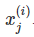 。
。
就一个例子来说,目标是机器学习预测的信息。在数学公式中,目标通常称为y或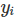 。
。
机器学习任务是具有特征的数据集和目标的组合。根据目标的类型,任务可以是分类、回归、生存分析、聚类或异常检测。
预测是机器学习模型根据给定的特征“猜测”目标值应该是什么。在本书中,模型预测用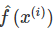 或者
或者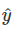 。
。

若有收获,就点个赞吧
0 人点赞
