参考:
- Hadoop.The.Definitive.Guide.4th
本章介绍如何在一个计算机集群上构建Hadoop系统。尽管在单机上运行HDFS、MapReduce和YARN有助于学习这些系统,但是要想执行一些有价值的工作,必须在多节点系统上运行。
有多个选择来获得一个Hadoop集群,从建立一个专属集群,到在租借的硬件设备上运行Hadoop系统,乃至于使用云端作为托管服务提供的Hadoop。被托管的选项数很多,这里就不逐一列举,但是即使你选择自己建立一个Hadoop集群,仍然会有很多安装选项要考虑。
Apache tarball
Apache Hadoop项目及相关的项目为每次发布提供了二进制(和源)压缩包(tarbal)。用二进制压缩包安装最灵活,但工作量也最大,这是由于需要确定安装文件、配置文件和日志文件在文件系统中的位置、正确设置文件访问权限等等。Packages
从Apache Bigtop项目(http://bigtop.apache.org/)及所有Hadoop供应商那里都可以获取RPM和Debian包。这些包比压缩包有更多的优点,它们提供了一个一致性的文件系统布局,可以作为一个整体进行测试(这样可以知道Hadoop和Hive的多个版本能够在一起运行),并且它们可以和配置管理工具如Puppet一起运行。Hadoop集群管理工具
有一些工具用于Hadoop集群全生命期的安装和管理,Cloudera Manager和Apache Ambari就是这样的专用工具。它们提供了简单的WebUI,并且被推荐给大多数用户和操作者用以构建Hadoop集群。这些工具集成了Hadoop 运行有关的操作知识。例如,它们基于硬件特点使用启发式方法来选择好的默认值用于Hadoop配置设置。对于更复杂的构建,例如HA,或secure Hadoop(安全性),这些管理工具提供了经过测试的向导,能够帮助在短时间内建立一个能够工作的集群。最后,它们增加了额外的、其他安装选项没有提供的特性,例如统一监控和日志搜索,滚动升级(升级集群时不用经历停机)。
从操作的角度深人理解Hadoop 的工作机制。
集群规范(cluster specification)
机器硬件规范
Hadoop运行在商业硬件上。用户可以选择普通硬件供应商生产的标准化的、广泛有效的硬件来构建集群,无需使用特定供应商生产的昂贵、专有的硬件设备。
首先澄清两点。第一,商业硬件并不等同于低端硬件。低端机器常常使用便宜的零部件,其故障率远高于更贵一些(但仍是商业级别)的机器。当用户管理几十台、上百台,甚至几千台机器时,选择便宜的零部件并不划算,因为更高的故障率推高了维护成本。第二,也不推荐使用大型的数据库级别的机器,因为这类机器的性价比太低了。用户可能会考虑使用少数几台数据库级别的机器来构建一个集群,使其性能达到一个中等规模的商业机器集群。然而,某一台机器所发生的故障会对整个集群产生更大的负面影响,因为大多数集群硬件将无法使用。
硬件规格很快就会过时。但为了举例说明,下面列举一下硬件规格。 在2014年,运行Hadoop的datanode和YARN节点管理器的典型机器有以下规格:
- 处理器(Processor)
两个十六核(或八核) 3 GHz CPUs - 内存(Memory)
64~512 GB ECC RAM - 存储器(Storage)
12~24 x 1~4 TB SATA硬盘(12TB~96TB) - 网络(Network)
带链路聚合的千兆以太网(Gigabit Ethernet with link aggregation)
据有部分用户报告称,在Hadoop 集群中使用非ECC内存时会产生校验和错误,建议采用ECC内存。
尽管各个集群采用的硬件规格肯定有所不同,但是Hadoop一般使用多核CPU和多磁盘,以充分利用硬件的强大功能。
为何不使用RAID
尽管建议采用RAID(Redundant Array of Independent Disk, 即磁盘阵列)作为 namenode 的存储器以保护元数据,但是若将RAID作为datanode的存储设备则不会给HDFS带来益处。
HDFS所提供的节点间数据复制技术已可满足数据备份需求,无需使用RAID的冗余机制。此外,尽管RAID条带化技术(RAID 0)被广泛用于提升性能,但是其速度仍然比用在HDFS里的JBOD(Just a Bunch Of Disks)配置慢。
JBOD 在所有磁盘之间循环调度HDFS块。RAID 0 的读/写操作受限于磁盘阵列中响应最慢的盘片的速度,而JBOD的磁盘操作均独立,因而平均读/写速度高于最慢盘片的读/写速度。需要强调的是,各个磁盘的性能在实际使用中总存在相当大的差异,即使对于相同型号的磁盘。
在一些针对某一雅虎集群的基准评测中,在一项测试(Gridmix)中,JBOD 比RAID 0快10%;在另一测试(HDFS写吞吐量)中,JBOD比RAID0快30%。
最后,若JBOD配置的某一磁盘出现故障,HDFS 可以忽略该磁盘,继续工作。而RAID的某一盘片故障会导致整个磁盘阵列不可用,进而使相应节点失效。
集群规模
一个Hadoop集群到底应该多大?这个问题并无确切的答案。但是,Hadoop 的魅力在于用户可以在初始阶段构建-一个小集群(大约10 个节点),并随存储与计算需求增长持续扩充。
从某种意义上讲,更恰当的问题是:你的集群需要增长得多快?
用户可以通过下面这个关于存储的例子得到更深的体会。
假如数据每天增长 1TB。如果采用三路HDFS复制技术,则每天需要增加 3TB 存储能力。再加上一些中间文件和日志文件(约占30%)所需空间,基本上相当于每周添设一台机器(2014年的典型机器,47=28TB ≈123)。实际上,用户一般不会每周买一台新机器并将其加入集群。类似粗略计算的意义在于让用户了解集群的规模。本例中,一
个集群保存两年的数据大致需要100台机器。(7204=2880TB *≈ 100123**)
Master节点场景
集群的规模不同,运行 master 守护进程的配置也不同,包括:namenode、辅助(secondary)namenode、资源管理器及历史服务器。对于一个小集群(几十个节点)而言,在一台master机器上同时运行namenode和资源管理器通常是可接受的(只要至少一份namenode的元数据被另存在远程文件系统中)。然而,随着集群规模增大,完全有理由分离它们。
由于namenode在内存中保存整个命名空间中的所有文件元数据和块元数据,其内存需求很大。辅助namenode在大多数时间里空闲,但是它在创建检查点时的内存需求与主namenode差不多。一旦文件系统包含大量文件,单台机器的物理内存便无法同时运行主namenode和辅助namenode。
除了简单的资源需求,在分开的机器上运行master的主要理由是为了高可用性。HDFS和YARN都支持以主备方式运行master的配置。如果主master故障,在不同硬件上运行的备机将接替主机,且几乎不会对服务造成干扰。在HDFS中,辅助namenode的检查点功能由备机执行,所以不需要同时运行备机和辅助namenode。
网络拓扑
Hadoop集群架构通常包含两级网络拓扑,如下图所示。一般来说,各机架装配30~40个服务器,共享一个10 GB的交换机(该图中各机架只画了3个服务器),各机架的交换机又通过上行链路与一个核心交换机或路由器(至少为 I0GB或更高)互联。
Typical two-level network architecture for a Hadoop cluster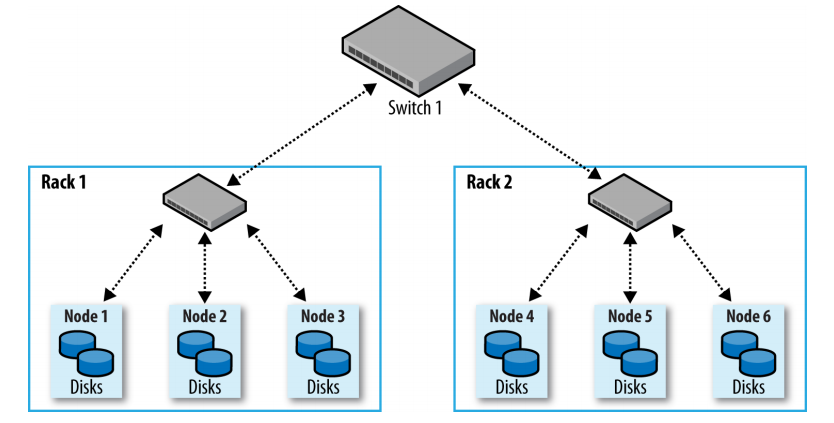
该架构的突出特点是同一机架**内部的节点之间的总带宽要远高于不同机架上的节点间的带宽**。
机架的注意事项(Rack awareness)
为了达到Hadoop的最佳性能,配置Hadoop系统以让其了解网络拓扑状况就极为关键。如果集群只包含一个机架,就无需做什么,因为这是默认配置。但是对于多机架的集群来说,描述清楚节点与机架的映射关系就很有必要。这使得Hadoop将MapReduce任务分配到各个节点时,会倾向于执行机架内的数据传输(拥有更多带宽),而非跨机架数据传输。HDFS还能够更加智能地放置复本(replica),以取得性能(performance)和弹性(resilience)的平衡。
诸如节点和机架等的网络位置以树的形式来表示,从而能够体现出各个位置之间的网络“距离”。namenode使用网络位置来确定在哪里放置块的复本;MapReduce的调度器根据网络位置来查找最近的复本,将它作为map任务的输入。
在上图所示的网络中,机架拓扑由两个网络位置来描述,即 /switch1/rack1 和 /swich/rack2。由于该集群只有一个顶层路由器,这两个位置可以简写为 /rack1和 /rack2。
Hadoop配置需要通过一个Java接口 org.apache.hadoop.net.DNSToSwitchMapping 来指定节点地址和网络位置之间的映射关系。该接口定义如下:
public interface DNSToSwitchMapping {public List<String> resolve(List<String> names);}
resolve() 函数的输入参数names描述IP地址列表,返回相应的网络位置字符串列表。net.topology.node.switch.mapping.impl 配置属性实现了 DNSToSwitchMapping 接口,namenode和资源管理器均采用它来解析工作节点的网络位置。
在上例的网络拓扑中,可将 node1、node2和node3映射到 /rack1,将node4、node5和node6映射到/rack2中。
但是,大多数安装并不需要自己实现接口,默认的实现是 org.apache.hadoop.net.ScriptBasedMapping ,它运行用户定义的脚本来描述映射关系。脚本的存放路径由属性 net.topology.script.file.name 控制。脚本接受一系列输入 参数,描述带映射的主机名称或IP地址,再将相应的网络位置以空格分开,输出到标准输出。(https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/RackAwareness.html)
如果没有指定脚本位置,默认情况下会将所有节点映射到单个网络位置,即/defaul-rack。
集群的构建与安装
本节介绍如何在Unix操作系统下使用Apache Hadoop分发包安装和配置一个基础的Hadoop集群。同时也介绍一些在安装Hadoop过程中需要仔细思考的背景知识。对于产品安装,大部分用户和操作者应该考虑使用本章开始部分列举的Hadoop集群管理工具。
1 安装 Java
Hadoop在Unix和Windows操作系统上都可以运行,但都需要安装Java。对于产品安装,应该选择一个经过Hadoop 产品供应商认证的,操作系统、Java和Hadoop的组合。Hadoop 英文维基页面上列出了能够成功运行的组合。(https://cwiki.apache.org/confluence/display/HADOOP2/HadoopJavaVersions)
2 创建 Unix用户账号
最好创建特定的Unix用户帐号以区分各Hadoop进程,及区分同一机器上的其他服务。HDFS,MapReduce 和YARN 服务通常作为独立的用户运行,分别命名为 hdfs,mapred和yarn。它们都属于同一hadoop组。
3 安装 Hadoop
从Apache Hadoop 的发布页面(http://archive.apache.org/dist/hadoop/core/stable/)下载Hadoop发布包,并在某一本地目录解压缩,例如 /usr/local (/opt是另一标准选项)。注意,鉴于hadoop用户的home目录可能挂载在NFS上,Hadoop 系统最好不要安装在该目录上:
% cd /usr/local% sudo tar xzf hadoop-x.y.z.tar.gz
此外,还需将Hadoop文件的拥有者改为hadoop用户和组:
% sudo chown -R hadoop:hadoop hadoop-x.y.z
在shell PATH 路径里添加Hadoop执行程序所在目录很方便:
% export HADOOP_HOME=/usr/local/hadoop-x.y.z% export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
4 SSH配置
Hadoop控制脚本(并非守护进程)依赖SSH来执行针对整个集群的操作。例如,某个脚本能够终止并重启集群中的所有守护进程。值得注意的是,控制脚本并非唯一途径,用户也可以利用其他方法执行集群范围的操作,例如,分布式shell 或专门的 Hadoop 管理应用。
为了支持无缝式工作,SSH 安装好之后,需要允许来自集群内机器的hdfs用户和yarn用户能够无需密码即可登陆。(mapred用户不使用SSH,如同Hadoop2和以后版本中的一样,唯一的MapReduce守护进程是作业历史服务器。)最简单的方法是创建一个公钥/私钥对,存放在NFS之中,让整个集群共享该密钥对。
首先,键入以下指令来产生一个RSA密钥对。你需要做两次,一次以hdfs用户身份,一次以yarn用户身份:
% ssh-keygen -t rsa -f ~/.ssh/id_rsa
尽管期望无密码登录,但无口令的密钥并不是一个好的选择。因此,当系统提示输入口令时,用户最好指定一个口令。 可以使用 ssh-agent 以免为每个连接逐一输入密码。
私钥放在由 -f 选项指定的文件之中,例如~/.ssh/id_rsa。存放公钥的文件名称与私钥类似,但是以“.pub” 作为后缀,例如 ~/.ssh/id_rsa.pub。
接下来,需确保公钥存放在用户打算连接的所有机器的 ~/.ssh/authorized_keys 文件中。
如果用户的home目录是存储在NFS文件系统中,则可以键入以下指令在整个集群内共享密钥(第一次作为hdfs用户,第二次作为yarn用户):
% cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
如果home目录并没有通过NFS共享,则需要利用其他方法共享公钥(比如 ssh-copy-id )。
测试是否可以从主机器SSH到工作机器。若可以,则表明 ssh-agent 正在运行,再运行 ssh-add 来存储口令。这样的话,用户即可不用再输入口令就能SSH到一台工作机器。
5 配置Hadoop
如果希望 Hadoop 以分布式模式在集群上运行,必须正确对其进行配置。
6 格式化HDFS文件系统
在能够使用之前,全新的HDFS安装需要进行格式化。通过创建存储目录和初始版本的namenode持久数据结构,格式化进程将创建一个空的文件系统。由于namenode管理所有的文件系统元数据,datanode可以动态加入或离开集群,所以初始的格式化进程不涉及到datanode。同样原因,创建文件系统时也无需指定大小,这是由集群中的datanode数目决定的,在文件系统格式化之后的很长时间内都可以根据需要增加。
格式化HDFS是一个快速操作。以hdfs用户身份运行以下命令:
% hdfs namenode -format
7 启动和停止守护进程
Hadoop自带脚本,可以运行命令并在整个集群范围内启动和停止守护进程。
为使用这些脚本(在sbin目录下),需要告诉Hadoop集群中有哪些机器。文件 slaves 正是用于此目的,该文件包含了机器主机名或IP地址的列表,每行代表一个机器信息。
文件 slaves 列举了可以运行 datanode 和 nodemanager 的机器。文件驻留在Hadoop配置目录下,尽管通过修改 hadoop-en.sh 中的 HADOOP_SLAVES 设置可能会将文件放在别的地方(并赋予一个别的名称)。并且,不需要将该文件分发给工作节点,因为仅有在 namenode 和 resourcemanager 节点上运行的控制脚本使用它。
以 hdfs 用户身份运行一下命令可以启动 HDFS 守护进程:
% start-dfs.sh
namenode 和 secondary namenode 运行的所在的机器,通过向Hadoop配置询问机器主机名来决定。例如,通过执行以下命令,脚本能够找到namenode的主机名。
% hdfs getconf -namenodes
默认情况下,该命令从 fs.defaultFS 中找到namenode的主机名。更具体一些,start-dfs.sh 脚本所做的事情如下:
- 在由执行
hdfs get conf -namenodes得到的返回值所确定的每台机器上启动一个namenode。(运行HDFS HA时,可能会有多个namenode) - 在 slaves 文件列举的每台机器上启动一个datanode。
- 在由执行
hdfs get conf -secondarynamenodes得到的返回值所确定的每台机器上启动一个辅助namenode。
YARN守护进程以相同的方式启动,通过以yarn用户身份在托管资源管理器的机器上运行以下命令:
% start-yarn.sh
在这种情况下,资源管理器总是和 start-yarn.sh 脚本运行在同一机器上。脚本明确完成以下事情。
- 在本地机器 上启动一个资源管理器。
- 在 slaves 文件列举的每台机器上启动一个节点管理器。
同样,还提供了 stop-dfs.sh 和 stop-yarn.sh 脚本用来停止由相应的启动脚本启动的守护进程。
这些脚本实质是使用了 hadoop-daemon.sh 脚本(YARN 中是 yarn-daemon.sh 脚本)启动和停止Hadoop守护进程。如果你使用了前面提到的脚本,那么你不能直接调用 hadoop-daemon.sh。 但是如果你需要从另一个系统或从你自己的脚本来控制Hadoop守护进程,hadoop-daemon.sh 脚本是一个很好的切入点。
类似的,当需要在一个主机集上启动相同的守护进程时,使用 hadoop-daemons.sh (带有“s” )会很方便。
最后,仅有一个MapReduce守护进程,即作业历史服务器,是以 mapred 用户身份用以下命令启动的:
% mr-jobhistory-daemon.sh start historyserver
8 创建用户目录
一旦建立并运行了Hadoop集群,就需要给用户提供访向手段。涉及到为每个用户创建home目录,以及给目录设置用户访问许可:
% hadoop fs -mkdir /user/username% hadoop fs -chown username:username /user/username
此时是给目录设置空间限制的好时机。以下命令为给定的用户目录设置了1TB的容量限制: .
% hdfs dfsadmin -setSpaceQuota 1t /user/username

若有收获,就点个赞吧
0 人点赞
