数据类型
基本类型
八大基本类型:
- byte:字节型,用于存储整数的,占用1个字节,范围-128到127。
- short:短整型,用于存储整数的,占用2个字节,范围-32768到32767。
- int:整型,用于存储整数的,占用4个字节,范围-2^31到2^31-1 。
- long:长整型,用于存储整数的,占用8个字节,范围-2^63到2^63-1 。
- float:单精度浮点型,用于存储小数的,占用4个字节,不能表示精确的值 。
- double:双精度浮点型,用于存储小数的,占用8个字节,不用表示精确的值。
- boolean:布尔型,用于存储true或false的,占用1个字节 。
- char:字符型,采用Unicode字符编码格式,用于存储单个字符,占用2个字节 。
包装类
- java定义了8个包装类,目的是为了解决基本类型不能直接参与面向对象开发的问题,使得基本类型可以通 过包装类的实例以对象的方式存在
- 包括:Integer、Character、Byte、Short、Long、Float、Double、Boolean。其中Character和Boolean是直接继承自Object的,而其余6个包装类都继承自java.lang.Number
- JDK1.5推出了一个新的特性:自动拆装箱,该特性是编译器认可以,当编译器编译时若发现有基本类型与包 装类型相互赋值时,将会自动补充代码来完成他们的转换工作,这个过程称为自动拆装箱 ```java // 演示自动拆装箱
// 包装类与基本类型之间赋值是: 触发了自动装箱特性 Integer i1 = 5; //会被编译为: Integer i1 = Integer.valueOf(5); // 触发了自动拆箱特性 int i2 = i1; //会被编译为: int ii = i1.intValue();
// 演示包装类的实际操作: // 可以通过包装类来得到基本类型的取值范围: int max = Integer.MAX_VALUE; //获取int的最大值 int min = Integer.MIN_VALUE; //获取int的最小值 System.out.println(“int的最大值为:”+max); System.out.println(“int的最小值为:”+min);
long lMax = Long.MAX_VALUE; //获取long的最大值 long lMin = Long.MIN_VALUE; //获取long的最小值 System.out.println(“long的最大值为:”+lMax); System.out.println(“long的最小值为:”+lMin);
// 包装类可以将字符串转换为对应的基本类型 // 前提是该字符串正确表达了基本类型的值 // 若不能正确表达,则发生NumberFormatException数字转换异常 String str = “123”; int num = Integer.parseInt(str); //将字符串str转换为int类型 System.out.println(num); //123
str = “123.456”; double dou = Double.parseDouble(str); //将字符串str转换为double类型 System.out.println(dou); //123.456
<a name="i3zGE"></a>## 引用类型- 所有的非基本类型都是应用类型,包括包装类,他们指向的都是地址,并且存在堆中 . 基本类型都存在栈中.<a name="jfxU4"></a>## 缓存池1. new Integer(123) 与 Integer.valueOf(123) 的区别在于:- new Integer(123) 每次都会新建一个对象- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。```javaInteger x = new Integer(123);Integer y = new Integer(123);System.out.println(x == y); // false,==比较地址,所以创建了新的Integer z = Integer.valueOf(123);Integer k = Integer.valueOf(123);System.out.println(z == k); // true,==比较地址,所以没有创建新的
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }在 Java 8 中,Integer 缓存池的大小默认为 -128~127。 ```java static final int low = -128; static final int high; static final Integer cache[];
static { // high value may be configured by property int h = 127; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty(“java.lang.Integer.IntegerCache.high”); if (integerCacheHighPropValue != null) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h;
cache = new Integer[(high - low) + 1];
int j = low;
for(int k = 0; k < cache.length; k++)
cache[k] = new Integer(j++);
// range [-128, 127] must be interned (JLS7 5.1.7)
assert IntegerCache.high >= 127;
}
4. 编译器会**在缓冲池范围内的基本类型**自动装箱过程调用 valueOf() 方法,因此多个 Integer 实例使用自动装箱来创建并且值相同,那么**就会引用相同的对象。**
```java
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
- 基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
- 在使用这些基本类型对应的包装类型时,就可以直接使用缓冲池中的对象。如果在缓冲池之外:
Integer m = 323; Integer n = 323; System.out.println(m == n); // false运算
参数传递
基本类型是用过值传递的方式把值传进去 , 该方法内部的修改并不会影响调用方法的基本类型 (基本类型在栈中), 当传进去的引用类型的时候 , 传进去的是一个地址 , 当调方法时 , 修改的会是引用对象的值(这个值在堆中),不会改变地址,所以会改变对象的值 .
float 与 double
1.1 字面量属于 double 类型,不能直接将 1.1 直接赋值给 float 变量,因为这是向下转型。Java 不能隐式执行向下转型,因为这会使得精度降低。1.1f 字面量才是 float 类型。
- 拓展:如果基本的整数和浮点数精度不能够满足需求,那么可以使用 java.math 包下两个很有用的类:BigInteger 和 BigDecimal。这两个类可以处理包含任意长度数字序列的数值,BigInteger 实现了任意精度的整数运算,BigDecimal 实现了任意精度的浮点数运算。BigDecimal 由于舍入模式的存在,使得这个类用起来比 BigInteger 要复杂。
// float f = 1.1;编译错误 float f = 1.1f;long
- 长整型直接量需在数字后加L或l
- 运算时若有可能溢出,建议在第1个数字后加L ```java //2)long:长整型,8个字节,很大很大很大 long a = 25L; //25L为长整型直接量 long b = 1000;//编译正常,没有超过int范围,默认是int类型,可以不加L //long b = 10000000000; //编译错误,100亿默认为int类型,但超出int范围了 long c = 10000000000L;
//运算时若有可能溢出,建议在第1个数字后加L long d = 1000000000210L; System.out.println(d); //200亿 long e = 1000000000310L; System.out.println(e); //不是300亿 long f = 1000000000L310; System.out.println(f); //300亿
<a name="LftO3"></a>
## 类型间的转换
1. 基本类型由小到大依次为:
- byte----short(char)----int----long----float----double
2. 两种方式:
1. **自动/隐式类型转换**:小类型到大类型
1. **强制类型转换**:大类型到小类型
- 语法:(要转换成为的数据类型)变量
- **int c = (int) b; //强制类型转换**
- 注意:**强转有可能发生溢出或丢失精度**
3. 两点规则:
1. 整数直接量可以直接赋值给byte,short,char,但不能超出范围
1. **byte,short,char型数据参与运算时,系统一律自动将其转换为int再运算**
```java
byte b1 = 5; //byte的范围为-128到127
byte b2 = 6;
byte b3 = (byte)(b1+b2);//这里必须强转,否则编译不通过
System.out.println(2+2); //4
System.out.println(2+'2'); //52,2加上'2'的码50
System.out.println('2'+'2'); //100,'2'的码50,加上'2'的码50
运算的符号
1. 算术
+,-,*,/,%,++,—
1.%:取模/取余,余数为0即为整除
2.++/–:自增1/自减1,可在变量前也可在变量后
- 单独使用时,在前在后都一样
- 被使用时,在前在后不一样
- a++的值为a--------(a–的值为a)
- ++a的值为a+1------(–a的值为a-1)
2.关系
,<,>=,<=,==(用他的时候两边类型必须一样,否则不合法),!=
1.关系运算的结果为boolean型,
关系成立则为true,关系不成立则为false3.逻辑
&&,||,!
1.&&:短路与(并且),两边都为真则为真,见false则false
当第1个条件为false时,发生短路(后面的不执行了)
2.||:短路或(或者),有真则为真,见true则true
当第1个条件为true时,发生短路(后面的不执行了)
3.!:逻辑非(取反),非真则假,非假则真
4.补充:&为不短路与,|为不短路或4.赋值
=,+=,-=,=,/=,%=
1.简单赋值运算符:=
2.扩展赋值运算符:+=,-=,=,/=,%=
注:扩展赋值自带强转功能5.字符串连接:+
1.若两边为数字,则做加法运算
2.若两边出现了字符串,则做字符串连接
3.任何类型与字符串相连,结果都会变为字符串类型——同化作用
4.运算顺序是从前往后,没遇到字符串类型之前的数字依然做加法遇到后直接连接
例如:System.out.println(1+5+”测试”+8+1);//6测试816.条件/三目
注意:三目运算符中:第二个表达式和第三个表达式中如果都为基本数据类型,整个表达式的运算结果由容量高的决定。99.9是double类型而9是int类型, double 容量高。
1.语法:
boolean?数1:数2
2.执行过程:
注:整个表达式是有值的,值为数1或数2。
1.计算boolean的值:
若为true,则整个表达式的值为?号后的数1
若为false,则整个表达式的值为:号后的数2分支结构
1.if结构:1条路
1.语法:
if(boolean){undefined
语句块
}
2.执行过程:
判断boolean的值:
若为true,则执行语句块1(if整个结束)
若为false,则if直接结束2.if…else结构:2条路
1.语法:
if(boolean){undefined
语句块1
}else{undefined
语句块2
}
2.执行过程:
判断boolean的值:
若为true,则执行语句块1(整个结束)
若为false,则执行语句块2(整个结束)
3.说明:
语句块1和语句块2,必走其中之一——————2选13.if…else if结构:多条路
1.语法:
if(boolean-1){
语句块1
}else if(boolean-2){
语句块2
}else if(boolean-3){
语句块3
}else{
语句块4
}
2.执行过程:
判断boolean-1,若为true则执行语句块1(结束),若为false则
再判断boolean-2,若为true则执行语句块2(结束),若为false则
再判断boolean-3,若为true则执行语句块3(结束),若为false则执行语句块4(结束)
3说明:
语句块1/2/3/4,只能执行其中之一——————多选1 ```java public class ScoreLevel { public static void main(String[] args) { Scanner scan = new Scanner(System.in); System.out.println(“请输入成绩:”); double score = scan.nextDouble();
//带数(-25,888,95,85,65,45)
if(score<0 || score>100){
System.out.println("成绩不合法");
}else if(score>=90){ //合法
System.out.println("A-优秀");
}else if(score>=80){
System.out.println("B-良好");
}else if(score>=60){
System.out.println("C-中等");
}else{
System.out.println("D-不及格");
}
}
}
<a name="MvMbd"></a>
## 4.switch…case结构:多条路
(**一定要记得break,没有default也能跑**)<br />优点:效率高、结构清晰<br />缺点:只能对整数判断相等<br />break:跳出switch<br />常见面试题:switch可以作用于什么类型的数据上<br />-------------------------byte,short,int,char,String,枚举类型
```java
public class CommandBySwitch {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
System.out.println("请选择功能: 1.取款 2.存款 3.查询余额 0.退卡");
int command = scan.nextInt();
switch(command){
case 1:
System.out.println("取款操作...");
break;
case 2:
System.out.println("存款操作...");
break;
case 3:
System.out.println("查询余额操作...");
break;
case 0:
System.out.println("退卡操作...");
break;
default:
System.out.println("输入错误");
}
}
}
循环结构
0.循环三要素
1.循环变量的初始化
2.循环的条件(以循环变量为基础)
3.循环变量的改变(向着循环的结束变)
循环变量:在整个循环过程中所反复改变的那个数
1.while结构
先判断后执行,有可能一次都不执行
1.语法:
while(boolean){
语句块——————-反复执行的代码
}
2.执行过程:
判断boolean的值,若为true则执行语句块,
再判断boolean的值,若为true则再执行语句块,
再判断boolean的值,若为true则再执行语句块,
如此反复,直到boolean的值为false时,while循环结束
int times = 0; //1)循环变量的初始化
while(times<5){ //2)循环的条件
System.out.println("行动是成功的阶梯");
times++; //3)循环变量的改变
}
System.out.println("继续执行...");
2.do…while结构
先执行后判断,至少执行一次
————-要素1与要素3相同时,首选do…while
1.语法:
do{
语句块
}while(boolean);
2.执行过程:
先执行语句块,再判断boolean的值,若为true则
再执行语句块,再判断boolean的值,若为true则
再执行语句块,再判断boolean的值,若为true则
再执行语句块,如此反复,直到boolean的值为false,则 do…while结束
public class Guessing {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
int num = (int)(Math.random()*1000+1); //1到1000之内的随机数
System.out.println(num); //作弊
//假设num=250
//300(大),200(小),250(对)
int guess;
do{
System.out.println("猜吧!");
guess = scan.nextInt(); //1+3
if(guess>num){
System.out.println("太大了");
}else if(guess<num){
System.out.println("太小了");
}else{
System.out.println("恭喜你猜对了");
}
}while(guess!=num); //2
}
}
3.for结构
普通for
- 应用率高、与次数相关的循环
语法:
for(要素1;要素2;要素3){ 语句块/循环体----------------反复执行的代码 4 } for(int x = 0 ; i < 10 ; i++ ){ System.out.println("hello"); }2.执行过程:
1243 243 243 243 243 243… 2增强型for循环
- 增强型for循环:也称为新循环,使得我们可以使用相同的语法遍历集合或数组。foreach:
注意:
- 新循环的语法是编译器认可的,而不是虚拟机.编译器在编译代码时会把新循环遍历数组改为普通的for循环遍历.新循环遍历集合就是迭代器遍历.编译器会改为迭代器.所以注意!不要在使用新循环遍历集合的过程中使用集合的方法增删元素,否则会抛出异常! ```java for(元素类型 变量名 : 集合或数组){ 循环体; }
for(String str : array){
System.out.println(str);4.三种循环结构的选择规则
1.先看循环是否与次数相关:
1.若相关——————————————直接上for
2.若无关,再看要素1与要素3是否相同:
1.若相同————————————直接上do…while
2.若不同————————————直接上while5.循环常用关键词
break:跳出当前一层循环<br />continue:跳过循环体中剩余语句而进入下一次循环6.嵌套循环
1.循环中套循环,常常多行多列时使用,一般外层控制行,内层控制列
2.执行过程:外层循环走一次,内层循环走所有次
3.建议:嵌套层数越少越好,能用一层就不用两层,能用两层就不用三层
4.break只能跳出当前一层循环String
定义
- String 被声明为 final,因此它不可被继承.
- java中的String在内存中采用Unicode编码方式,任何一个字符占用两个字节的编码.
- 内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变.(注意变量还可以被赋值新的String.)
public final class String implements java.io.Serializable, Comparable<String>, CharSequence { /** The value is used for character storage. */ private final char value[]; ......}优点(不可变)
1.可以缓存 hash 值
- 因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要(堆中的常量池)
- 如果一个 String 对象已经被创建过(必须是直接量或者字面量)了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
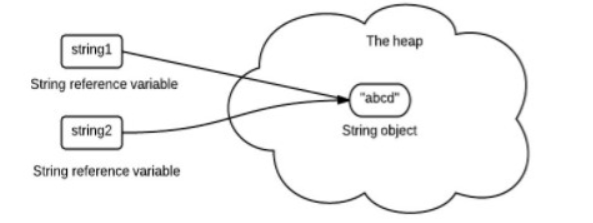
- 这里注意 , java推荐我们用字面量/直接量的方式来创建字符串,并且会缓存所有以字面量形式创建的字符串对象到常量池中,当使用相同字面量再创建对象时将复用常量池中的对象以减少内存开销,从而避免内存中堆积大量内容相同的字符串对象 . ```java / 使用字面量来创建字符串对象时,JVM会检查常量池中是否有该对象: 1)若没有,则会创建该字符串对象并存入常量池中 2)若有,则直接将常量池中的对象返回(不会再创建新的字符串对象) /
String s1 = “123abc”; //常量池还没有,因此创建该字符串对象,并存入常量池 String s2 = “123abc”; //常量池中已经有了,直接重用对象 String s3 = “123abc”; //常量池中已经有了,直接重用对象 //引用类型==,比较地址是否相同 System.out.println(s1==s2); //true System.out.println(s1==s3); //true System.out.println(s2==s3); //true
s1 = s1+”!”; //创建新的字符串对象并将地址赋值给s1 System.out.println(s1==s2); //false,因为s1为新对象的地址,与s2不同了
3. 如果是**字面量或者直接量拼接起来(但凡有一个拼接不是字面量都不行)**的话,也会尝试复用拼接后的常量池字符串.**有则复用**
```java
String s4 = "123abc"; //堆中创建一个123abc对象,常量池中存储这个对象的引用
//编译器在编译时,若发现是两个字面量连接,
//则直接运算好并将结果保存起来,如下代码相当于String s2="123abc";
String s5 = "123"+"abc"; //复用常量池中的123abc对象
System.out.println(s4==s5); //true
String s6 = "123";
//因为s3不是字面量,所以并不会直接运算结果
String s7 = s6+"abc"; //会在堆中创建新的123abc对象,而不会重用常量池中的对象
System.out.println(s4==s7); //false
3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
String常用方法
String.length( )
获取变量字符串的长度(int型)
String str = "我爱Java!"; int len = str.length(); //获取str的长度 System.out.println(len); //7String.trim( )
去除当前字符串两边的空白字符(返回值是string)
String str = " hello world "; System.out.println(str); // hello world str = str.trim(); //去除当前字符串两边的空白字符 System.out.println(str); //hello worldString.toUpperCase( ), String.toLowerCase( )
将当前字符串中的英文部分转为全大写/全小写(返回值是string)
String str = "我爱Java!"; String upper = str.toUpperCase(); //将str中英文部分转为全大写 System.out.println(upper); //我爱JAVA! String lower = str.toLowerCase(); //将str中英文部分转为全小写 System.out.println(lower); //我爱java!String.startsWith( ), String.endsWith( )
判断当前字符串是否是以给定的字符串开始/结尾的(boolean型)
String str = "thinking in java"; boolean starts = str.startsWith("think"); //判断str是否是以think开头的 System.out.println("starts:"+starts); //true boolean ends = str.endsWith(".png"); //判断str是否是以.png结尾的 System.out.println("ends:"+ends); //falseString.charAt( )
返回(char值)当前字符串指定位置上的字符
// 111111 // 0123456789012345 String str = "thinking in java"; char c = str.charAt(9); //获取位置9所对应的字符 System.out.println(c); //iString.indexOf( )
返回(int值)给定字符串(“string”)在当前字符串中的位置 ```java String str = “thinking in java”; int index = str.indexOf(“in”); //检索in在字符串str中的开始位置 System.out.println(index); //2 index = str.indexOf(“in”,3); //从下标为3的位置开始找in第一次出现的位置 System.out.println(index); //5
index = str.indexOf(“IN”); //当前字符串不包含IN,所以返回-1 System.out.println(index); //-1
index = str.lastIndexOf(“in”); //找in最后一次出现的位置 System.out.println(index); //9
<a name="ZAYat"></a>
### String.substring( )
- **变量名.substring(int a,int b)**:截取当前字符串中下标为a到**b-1**范围的字符串
- **变量名.substring(int a)**:截取当前字符串中下标为a开始到结尾的字符串
```java
String str = "www.baidu.com";
String name = str.substring(4,9); //截到下标4到8范围的字符串----含头不含尾
System.out.println(name); //baidu
name = str.substring(4); //从下标4开始一直截到末尾
System.out.println(name); //baibu.com
String.valueOf( )
- 将其它数据类型转换为String
- 这里注意.方便偷懒.可以不用这个方法,只要让其他类型加上空字符串就会自动转化为字符串. ```java int a = 123; String s1 = String.valueOf(a); //将int型变量a转换为String类型并赋值给s1 System.out.println(s1); //123—-字符串类型
double d = 123.456; String s2 = String.valueOf(d); //将double型变量d转换为String类型并赋值给s2 System.out.println(s2); //123.456——字符串类型
String s3 = a+””; //任何内容和字符串连接的结果都是字符串,效率低 System.out.println(s3); //123—-字符串类型
<a name="nSC9M"></a>
### String.intern( )
- 使用 String.intern() 可以保证相同内容的字符串变量引用同一的内存对象。
```java
String s1 = new String("aaa");
String s2 = new String("aaa");
System.out.println(s1 == s2); // false
String s3 = s1.intern();
System.out.println(s1.intern() == s3); // true
StringBuffer and StringBuilder
定义
- 由于String是不变对象,每次修改内容要创建新对象,因此String不适合做频繁修改操作,为了解决这个问 题,java提供了StringBuilder类和StringBuffer类。
StringBuilder是专门用于修改字符串的一个API,内部维护一个可变的char数组,修改都是在这个数组上进 行的,修改速度、性能优秀,并且提供了修改字符串的常见的方法:增、删、改、插
StringBuilder和StringBuffer的常用方法
append():追加内容
- replace():替换部分内容
- delete():删除部分内容
- insert():插入内容
- reverse():翻转内容 ```java String str = “好好学习java”; //复制str中的内容到builder中——-好好学习java StringBuilder builder = new StringBuilder(str);
//append():追加内容 builder.append(“,为了找个好工作!”); System.out.println(builder); //好好学习java,为了找个好工作!
//replace():替换部分内容 builder.replace(9,16,”就是为了改变世界”); //替换下标9到15的 System.out.println(builder); //好好学习java,就是为了改变世界!
//delete():删除部分内容 builder.delete(0,8); //删除下标0到7的 System.out.println(builder); //,就是为了改变世界!
//insert():插入操作 builder.insert(0,”活着”); //从下标0的位置插入 System.out.println(builder); //活着,就是为了改变世界!
//reverse():翻转 builder.reverse(); //翻转内容 System.out.println(builder); //!界世变改了为是就,着活
<a name="YiezU"></a>
## 三者区别对比
<a name="O4swK"></a>
### 1. 可变性
- String 不可变 ( 被final修饰 )
- StringBuffer 和 StringBuilder 可变 ( 内部维护一个可变的char数组 )
<a name="N8xPn"></a>
### 2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder **不是线程安全的**
- StringBuffer 是线程安全的,内部使用 **synchronized 进行同步**
<a name="hHGtF"></a>
### 3. 效率
- 修改效率从高到低
- StringBuilder (无限制)-->StringBuffer(同步锁限制)-->String(要创建新的)
<a name="xn3di"></a>
# 数组
<a name="TMcIc"></a>
## 定义
1. 是一种数据类型(引用类型)
1. 相同数据类型元素的集合
1. 声明:
- int[ ] arr=new int [i];
- int arr[ ]=new int [i];
4. 初始化:给数组中的元素做初始化(可以同时赋多个或者只赋值一个)
4. 访问:访问的是数组中的元素
- 通过(数组名.length)可以获取数组的长度(元素的个数)
- 通过下标/索引来访问数组中的元素
- 下标从0开始,最大到(数组的长度-1)
6. 遍历/迭代:采用for循环,从头到尾挨个走一遍
<a name="LW9eB"></a>
## 复制
1. System.arraycopy(a,1,b,0,4)
```java
int[] a = {10,20,30,40,50};
int[] b = new int[6]; //0,0,0,0,0,0
//a:源数组
//1:源数组的起始下标
//b:目标数组
//0:目标数组的起始下标
//4:要复制的元素个数
System.arraycopy(a,1,b,0,4); //灵活性好
for(int i=0;i<b.length;i++){
System.out.println(b[i]);
}
//{20,30,40,50,0,0}
- int[ ] b = Arrays.copyOf(a,6); ```java //常规复制 int[] a = {10,20,30,40,50}; //a:源数组 //b:目标数组 //6:目标数组的长度(元素个数) //—-若目标数组长度>源数组长度,则末尾补默认值 //—-若目标数组长度<源数组长度,则将末尾的截掉 int[] b = Arrays.copyOf(a,6); //灵活性差 for(int i=0;i<b.length;i++){ System.out.println(b[i]); }//{10,20,30,40,50,0}
<a name="oUu4T"></a>
## 扩容
```java
//数组的扩容
int[] a = {10,20,30,40,50};
//数组扩容(创建了一个更大的新的数组,并将源数组数据复制进去了)
a = Arrays.copyOf(a,a.length+1);
for(int i=0;i<a.length;i++){
System.out.println(a[i]);
}
排序
- Array.sort(arr);升序排列(从小到大)(这只是排序,输出还是要用for) ```java //数组的排序: int[] arr = new int[10]; for(int i=0;i<arr.length;i++){ arr[i] = (int)(Math.random()*100); System.out.println(arr[i]); }
Arrays.sort(arr); //对arr进行升序排列
System.out.println(“数组排序后的数据:”); for(int i=0;i<arr.length;i++){ System.out.println(arr[i]); }
<a name="zMk1P"></a>
## 补充
- ArrayIndexOutOfBoundsException数组下标越界异常-----数组下标范围为0到(数组长度-1),超出范围则发生如上的异常
<a name="PmdSV"></a>
# 继承
<a name="TkJpF"></a>
## 定义:
1. 作用:代码复用
1. 通过**extends**来实现继承
1. 超类/父类: 共有的属性和行为--------------派生类/子类: 特有的属性和行为
1. 派生类既能访问自己的,也能访问超类,但是**超类不能访问派生类的**
1. 一个超类可以有多个派生类,一个派生类只能有一个超类---------**单一继承**
1. 具有传递性
1. java规定:构造派生类之前必须先构造超类
1. 在派生类的构造方法中若没有调用超类的构造方法,则**默认super()调用超类的无参构造方法**
1. 在派生类的构造方法中若自己调用了超类的构造方法,则不再默认提供
1. super()调用超类构造方法,必须位于**派生类构造方法的第1行**
<a name="TPcgQ"></a>
## super
-----指代当前对象的超类对象
1. super的用法:
- super.成员变量名---------------------访问超类的成员变量(一般省略不写,只在子类出现,子类继承的话,子类写this也可以,实用性不高)
- super.方法名()-------------------------调用超类的方法
- super()-----------------------------------调用超类的构造方法(**有参传参**)
<a name="TmiNU"></a>
## 向上造型
1.向上造型的意义:**--------实现代码复用**<br />当多种角色能干的事是一样的,可以将那多种角色造型到超类数组中,统一访问<br />2.超类型的引用指向派生类的对象<br /> **Aoo o3 = new Boo(); //向上造型**<br />3.能点出来什么,**看引用的类型(Aoo)**
<a name="W3k3G"></a>
## 方法的重写
1. 发生在**父子类**中,方法名相同,参数列表相同
1. 重写方法被调用时,**看对象的类型(如上对应Boo)**
1. 重写遵循"**两同两小一大**"原则:-----------一般都是一模一样的
1. 两同:
- 方法名相同
- 参数列表相同
2. 两小:
- 派生类方法的返回值类型小于或等于超类方法的
- void和基本类型时,必须相等
- 引用类型时,小于或等于
- 2派生类方法抛出的异常小于或等于超类方法的
3. 一大:
- 派生类方法的访问权限大于或等于超类方法的-------------明天讲
<a name="gxxIF"></a>
## 重写与重载的区别
1.重写(override):发生在父子类中,方法名相同,参数列表相同<br />2.重载(overload):发生在同一类中(父子类的子类中因为继承了也可以重载),方法名相同,参数列表不同<br />3.发生**重载的**类的对象可以点出所有方法,发生**重写的**类的对象,看new出来的对象是什么就点出对应的方法,一个对象只能点出一个方法。
```java
SeaObject bbb=new SeaObject(95,95);
bbb.move();//这个move是Sea类的
SeaObject aaa=new TorpedoSubmarine();
aaa.move();//这个move是Tor类的
特殊关键词
package
1.package:声明包
1.避免类的命名冲突
2.同包中的类不能同名,但不同包中的类可以同名
3.类的全称:包名.类名
4.包名常常用层次结构,建议所有字母都小写
import
1.import:导入类
1.同包中的类可以直接访问
1.不同包中的类不能直接访问,若想访问:
1.先import声明类,再访问类(常用导包)
2.类的全称(不导包太傻了)
访问控制修饰符
--------------------------保证数据的安全<br />1.private: 私有的, 本类<br />2.默认的: 什么也不写, 本类、同包类<br />3.protected: 受保护的, 本类、同包类、派生类(继承)<br />4.public: 公开的, 任何类<br />**说明:**<br />- 类的访问权限只能是public或默认的<br />- 类中成员的访问权限如上4种都可以<br />- 访问权限由高到低依次为:public>protected>默认的>private
package ooday05;
//访问控制修饰符的演示
public class Aoo {
private int d; //本类
int c; //本类、同包类
protected int b; //本类、同包类、派生类
public int a; //任何类
void show(){//同类中调用,都能使用
a = 1;
b = 2;
c = 3;
d = 4;
}
}
class Boo{ //同包不同类中使用。
void show(){
Aoo o = new Aoo();
//o.a = 1;//编译错误,private,被调用
o.b = 2;
o.c = 3;
o.d = 4;
}
}
package ooday05_vis;
import ooday05.Aoo;//这是导包,如果没有这一步,接下来每次使用都需要用全名,
public class Coo { //----------------演示不同包不继承的
void show(){
Aoo o = new Aoo();
//不导入包的话这里就只能写成 ooday05.Aoo o=new ooday05.Aoo
//o.a = 1; //编译错误
//o.b = 2; //编译错误
//o.c = 3; //编译错误
o.d = 4;
}
}
class Doo extends Aoo{ //演示跨包继承
void show(){
//a = 1; //编译错误
//b = 2; //编译错误
c = 3;
d = 4;
}
}
final
最终的、不可改变的
——————单独应用几率极低(一般跟static一起使用)
1.修饰变量:变量不能被改变(变量可以在后续赋值,不是声明就必须赋值)(都是final修饰的变量参与计算的时候不会转类型)
2.修饰方法:方法不能被重写
3.修饰类:类不能被继承
static
1.静态变量:
1.由static修饰
2.属于类,存储在方法区中,只有一份,每次变动涉及它都会变,所以一般声明所有对象共享的
3.常常通过类名点来访问
public static void main(String[] args) {
Loo o1 = new Loo();
o1.show();
Loo o2 = new Loo();
o2.show();
Loo o3 = new Loo();
o3.show();
System.out.println(Loo.b); //常常通过类名点来访问
}
2..静态方法:
1.由static修饰
2.属于类,存储在方法区中,只有一份
3.常常通过类名点来访问
4.静态方法中没有隐式this传递,不能直接访问实例成员
5.何时用:方法的操作与对象无关
public class StaticDemo {
public static void main(String[] args) {
Moo.test();
}
}
//演示静态方法
class Moo{
int a; //实例变量(对象点来访问)
static int b; //静态变量(类名点来访问)
void show(){ //有隐式this,一般不写出来
System.out.println(this.a);
System.out.println(Moo.b);
}
static void test(){ //没有隐式this
//静态方法中没有隐式this传递
//没有this就意味着没有对象
//而实例变量a必须通过对象点来访问
//所以如下代码发生编译错误
//System.out.println(a); //编译错误
System.out.println(Moo.b);
}
}
//演示静态方法在何时用
class Noo{
int a; //对象的属性a
//在show()中用到了对象的属性a,意味着show()方法与对象有关,所以不能设计为静态方法
void show(){
System.out.println(a);
}
//在plus()中没有用到对象的属性,意味着plus()方法与对象无关,所以可以设计为静态方法
static int plus(int num1,int num2){
int num = num1+num2;
return num;
}
}
3.静态块:
1.由static修饰
2.属于类,在类被加载期间自动执行,一个类只被加载一次,所以静态块只执行一次
3.何时用:加载/初始化静态资源(图片、音频、视频等)
public class StaticDemo {
public static void main(String[] args) {
Poo o4 = new Poo();
Poo o5 = new Poo();
}
}
//演示静态块
class Poo{
static{
System.out.println("静态块");
}
Poo(){
System.out.println("构造方法");
}
}
static final常量
1.必须声明同时初始化
2.类名点来访问,不能被改变
3.建议:常量名所有字母都大写,多个单词用_分隔
4.编译器在编译时会将常量直接替换为具体的数,效率高
5.何时用:数据永远不变,并且经常使用
public class StaticFinalDemo {
public static void main(String[] args) {
System.out.println(Aoo.PI); //常常通过类名点来访问
//Aoo.PI = 3.1415926; //编译错误,常量不能被改变
//1)加载Boo.class到方法区中
//2)静态变量num一并存储到方法区中
//3)到方法区中获取num的值并输出
System.out.println(Boo.num);
//编译器在编译时会将常量直接替换为具体的值,效率高
//相当于System.out.println(5);
System.out.println(Boo.COUNT);
}
}
class Boo{
public static int num = 5; //静态变量
public static final int COUNT = 5; //常量
}
class Aoo{
public static final double PI = 3.14159;
//public static final int NUM; //编译错误,常量必须声明同时初始化
}
abstract 抽象的
抽象方法
1.由abstract修饰
2.只有方法的定义,没有具体的实现(连{}都没有)
public abstract class SeaObject {
public abstract void move();//无返回值抽象方法,
public abstract ImageIcon getImage();//有返回值方法,一般出现在父类,所在类必须写成抽象类
}
抽象类
- 由abstract修饰
- 包含抽象方法的类必须是抽象类
- 抽象类不能被实例化(new对象)
- 派生类继承抽象类会报错,解决方法:
抽象类:是需要被继承的
派生类:
1.重写所有抽象方法————————-变不完整为完整
2.也声明为抽象类——————————-一般不这么用,因为没有意义
- 抽象类的意义:
- 封装共有的属性和行为———————-代码复用
- 为所有派生类提供统一的类型———向上造型
- 可以包含抽象方法,为所有派生类提供统一的入口(能点出来)
- 派生类的行为不同,但入口是一致的,同时相当于定义了一个标准(强制重写)
- ——————一般团队协作需要,自己一个人可以不写,但是需要适应。
interface 接口
接口的特征
1.是一种引用数据类型
2.由interface定义
3.只能包含常量和抽象方法
4.接口不能被实例化(new对象)
5.接口是需要被实现/继承的,实现类/派生类:
——必须重写所有抽象方法
6.一个类可以实现多个接口,用逗号分隔,若又继承又实现时,应先继承后实现
7.接口可以继承接口
8.类与类单继承,接口与接口多继承,类与接口多实现 ```java //接口的演示 public class InterfaceDemo { public static void main(String[] args) { //Inter5 o1 = new Inter5(); //编译错误,接口不能被实例化 Inter5 o2 = new Doo(); //向上造型(可以造型为它所实现的接口) Inter4 o3 = new Doo(); //向上造型 } }
- ——————一般团队协作需要,自己一个人可以不写,但是需要适应。
//演示接口继承接口 interface Inter4{ void show(); } interface Inter5 extends Inter4{ void test(); } class Doo implements Inter5{ public void test(){} public void show(){} }
//演示接口多实现 interface Inter2{ void show(); } interface Inter3{ void test(); } abstract class Boo{ abstract void say(); } class Coo extends Boo implements Inter2,Inter3{ public void show(){} public void test(){} public void say(){} }
//演示接口的实现 interface Inter1{ void show(); //访问权限默认是public void test(); } class Aoo implements Inter1{ public void show(){} //重写接口中的抽象方法,访问权限必须是public public void test(){} }
//演示接口的语法 interface Inter{ public static final int NUM = 5; //接口中成员的访问权限只能是public的 public abstract void show(); int COUNT = 6; //默认public static final void say(); //默认public abstract //int number; //编译错误,常量必须声明同时初始化 //void test(){} //编译错误,抽象方法不能有方法体 }
<a name="LuWFo"></a>
### 接口的意义
1.实现多继承<br />2.制定了一套标准、规则
<a name="RLhvx"></a>
# Object常用方法
<a name="vU0YP"></a>
## 概览
```java
public final native Class<?> getClass()
public native int hashCode()
public boolean equals(Object obj)
protected native Object clone() throws CloneNotSupportedException
public String toString()
public final native void notify()
public final native void notifyAll()
public final native void wait(long timeout) throws InterruptedException
public final void wait(long timeout, int nanos) throws InterruptedException
public final void wait() throws InterruptedException
protected void finalize() throws Throwable {}
equals()
等价关系
//自反性
x.equals(x); // true
//对称性
x.equals(y) == y.equals(x); // true
//传递性
if (x.equals(y) && y.equals(z))
x.equals(z); // true;
//一致性
//多次调用 equals() 方法结果不变
x.equals(y) == x.equals(y); // true
//与 null 的比较
//对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
x.equals(null); // false;
equals() 与 ==
- 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
Integer x = new Integer(1); Integer y = new Integer(1); System.out.println(x.equals(y)); // true System.out.println(x == y); // false作用
检查是否为同一个对象的引用,如果是直接返回 true;
- 检查是否是同一个类型,如果不是,直接返回 false;
- 将 Object 对象进行转型;
判断每个关键域是否相等。
public class EqualExample { private int x; private int y; private int z; public EqualExample(int x, int y, int z) { this.x = x; this.y = y; this.z = z; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; EqualExample that = (EqualExample) o; if (x != that.x) return false; if (y != that.y) return false; return z == that.z; } }hashCode()
- hashCode() 返回散列值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价。
- 在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等。
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象,但是因为 EqualExample 没有实现 hasCode() 方法,因此这两个对象的散列值是不同的,最终导致集合添加了两个等价的对象。
EqualExample e1 = new EqualExample(1, 1, 1); EqualExample e2 = new EqualExample(1, 1, 1); System.out.println(e1.equals(e2)); // true HashSet<EqualExample> set = new HashSet<>(); set.add(e1); set.add(e2); System.out.println(set.size()); // 2理想的散列函数应当具有均匀性,即不相等的对象应当均匀分布到所有可能的散列值上。这就要求了散列函数要把所有域的值都考虑进来,可以将每个域都当成 R 进制的某一位,然后组成一个 R 进制的整数。R 一般取 31,因为它是一个奇素数,如果是偶数的话,当出现乘法溢出,信息就会丢失,因为与 2 相乘相当于向左移一位。
一个数与 31 相乘可以转换成移位和减法: 31*x == (x<<5)-x,编译器会自动进行这个优化。
@Override public int hashCode() { int result = 17; result = 31 * result + x; result = 31 * result + y; result = 31 * result + z; return result; }toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示。 ```java public class ToStringExample { private int number;
public ToStringExample(int number) {
this.number = number;} }
ToStringExample example = new ToStringExample(123); System.out.println(example.toString());
//ToStringExample @4554617c 会给一个地址而不是一个值
```

若有收获,就点个赞吧
0 人点赞
