Centos8配置hadoop全记录
最近开始学hadoop,跟着尚硅谷视频安装hadoop做一个记录。
1、安装Vmware
2、安装Centos8
3、配置ip和主机名称
配置Vmware的ip地址
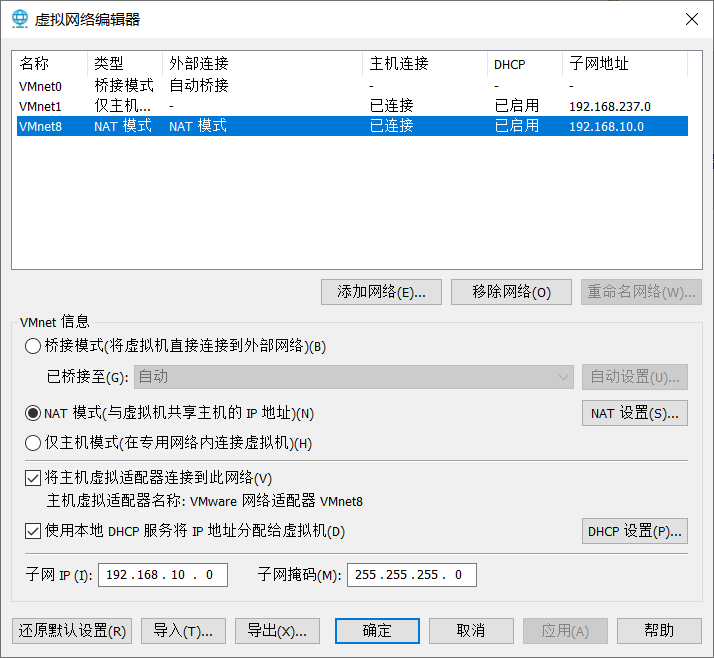
配置Windows10的ip地址
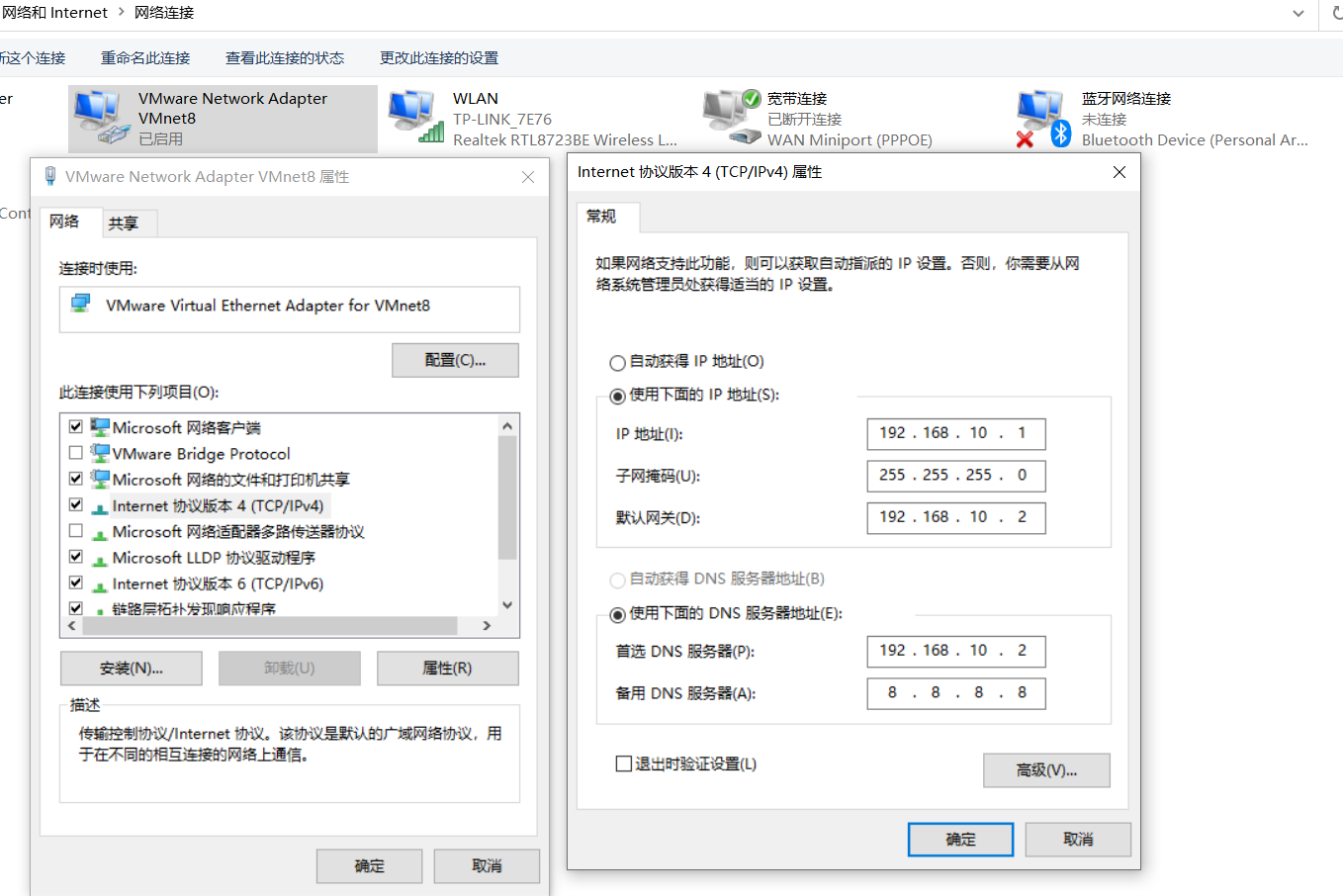
配置Centos8的ip地址
修改ifcfg-ens160文件里面的配置
vim /etc/sysconfig/network-scripts/ifcfg-ens160
将BOOTPROTO=dhcp修改为BOOTPROTO=static
追加
id address
IPADDR=192.168.10.100
gateway
GATEWAY=192.168.10.2
Domain name resolver
DNS1=192.168.10.2
修改主机名称
vim /etc/hostname
这里我们修改为 “hadoop100”
配置主机名称映射
vim /etc/hosts
向hosts文件添加如下内容
192.168.10.100 hadoop100192.168.10.101 hadoop101192.168.10.102 hadoop102192.168.10.103 hadoop103192.168.10.104 hadoop104192.168.10.105 hadoop105192.168.10.106 hadoop106192.168.10.107 hadoop107192.168.10.108 hadoop108
然后重启查看ip地址配置成功没有
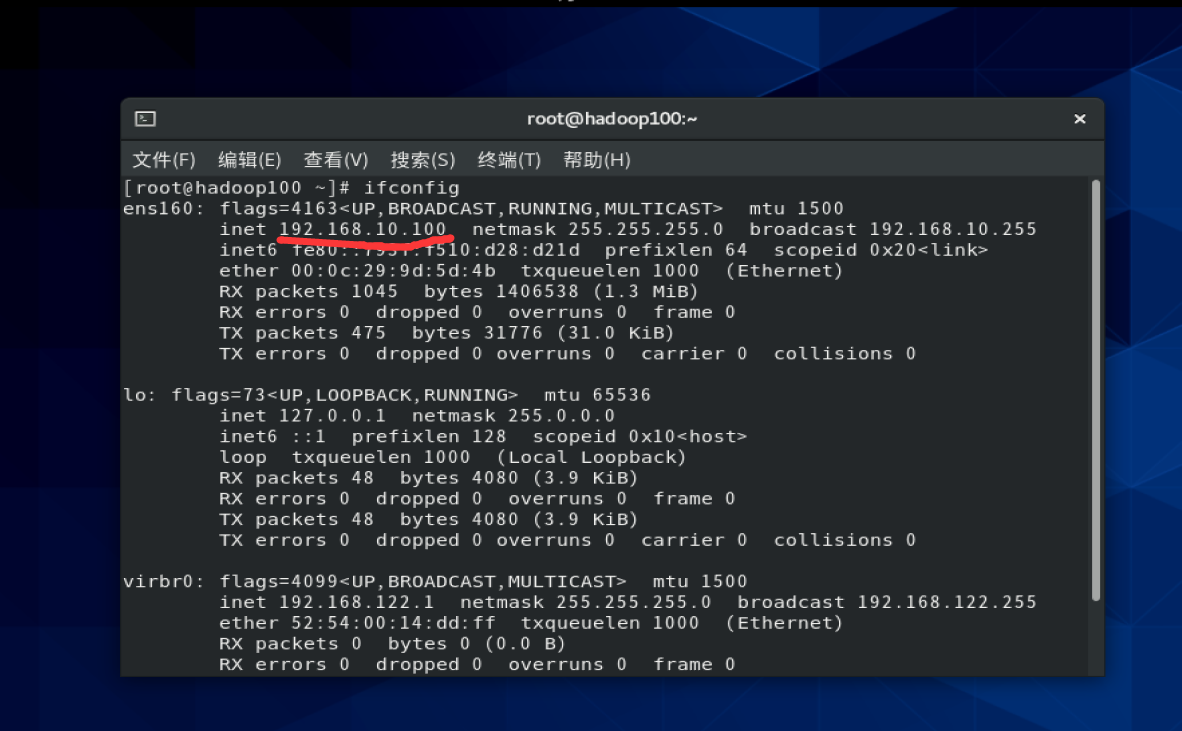
再ping一下网站看看有无
4、Xshell远程访问
自配Xshell和Xftp,创建模板虚拟机。
5、安装其他
yum install -y epel-release
关闭防火墙
systemctl stop firewalld
systemctl disable firewalld.service
修改用户权限:修改/etc/sudoers
在hadoop102上安装jdk
在/opt目录下新建目录module和software目录用Xftp将jdk压缩包放在software目录下,然后解压至module目录下
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module/
配置jdk环境变量
cd /etc/profile.d
到这个目录下新建一my_env.sh保存环境变量
sudo vim my_env.sh
然后配置变量
#JAVA_HOMEexport JAVA_HOME=/opt/module/jdk1.8.0_161export PATH=$PATH:$JAVA_HOME/bin
配置完成之后再重新加载一下profile文件
source /etc/profile
此时可以使用java命令查看
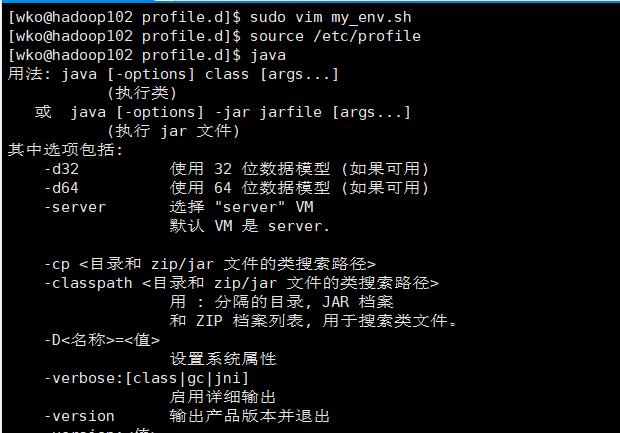
在hadoop102上安装hadoop
前面步骤与安装jdk相同
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
#HADOOP_HOMEexport HADOOP_HOME=/opt/module/hadoop-3.1.3export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin
source之后可以使用hadoop命令验证一下
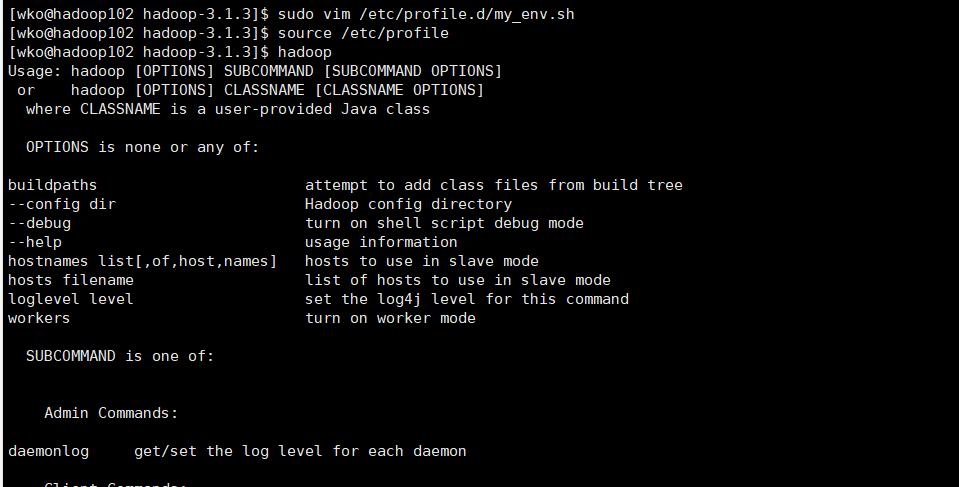
顺带记录一下hadoop的目录结构:
- bin:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
- etc:Hadoop的配置文件目录,存放Hadoop的配置文件
- include:存放类似c语言头文件形式的.h文件
- lib:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- libexec
- sbin:存放启动或停止Hadoop相关服务的脚本
- share:存放Hadoop的依赖jar包、文档、和官方案例
安装完毕之后可以使用share文件夹里面的官方例子测试一下:wordcount
- 新建wcinpt目录:/opt/module/hadoop-3.1.3/wcinput
- 建一个word.txt文本,写一些内容进去。
- 然后调用share中的官方jar包。指定输出目录
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput
执行完毕后到指定输出目录查看
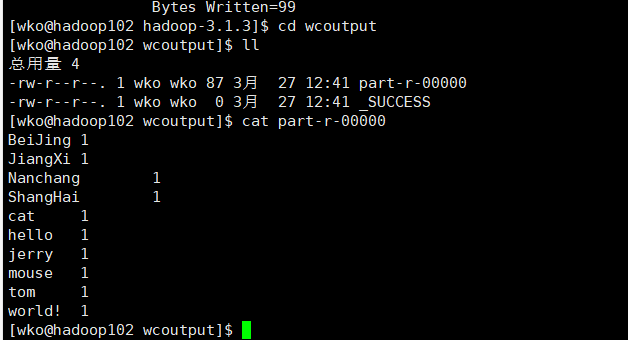
hadoop完全分布式搭建
准备条件
- 准备三台客户机(关闭防火墙、配置静态ip及主机名称)
- 安装JDK
- 配置环境变量
- 安装hadoop
- 配置环境变量
- 配置集群
- 单点启动
- 配置ssh
- 群起并测试集群
因为之前我们已经配置好hadoop102,并且已经有另外两台配置了ip的客户机(只是没有安装JDK和hadoop)为了避免麻烦,我们将hadoop的安装好的环境拷贝给另外两台机机器。
scp命令
Linux scp 命令用于 Linux 之间复制文件和目录。scp 是 secure copy 的缩写, scp 是 linux 系统下基于 ssh 登陆进行安全的远程文件拷贝命令。
#语法scp [-1246BCpqrv] [-c cipher] [-F ssh_config] [-i identity_file][-l limit] [-o ssh_option] [-P port] [-S program][[user@]host1:]file1 [...] [[user@]host2:]file2
- -1: 强制scp命令使用协议ssh1
- -2: 强制scp命令使用协议ssh2
- -4: 强制scp命令只使用IPv4寻址
- -6: 强制scp命令只使用IPv6寻址
- -B: 使用批处理模式(传输过程中不询问传输口令或短语)
- -C: 允许压缩。(将-C标志传递给ssh,从而打开压缩功能)
- -p:保留原文件的修改时间,访问时间和访问权限。
- -q: 不显示传输进度条。
- -r: 递归复制整个目录。
- -v:详细方式显示输出。scp和ssh(1)会显示出整个过程的调试信息。这些信息用于调试连接,验证和配置问题。
- -c cipher: 以cipher将数据传输进行加密,这个选项将直接传递给ssh。
- -F ssh_config: 指定一个替代的ssh配置文件,此参数直接传递给ssh。
- -i identity_file: 从指定文件中读取传输时使用的密钥文件,此参数直接传递给ssh。
- -l limit: 限定用户所能使用的带宽,以Kbit/s为单位。
- -o ssh_option: 如果习惯于使用ssh_config(5)中的参数传递方式,
- -P port:注意是大写的P, port是指定数据传输用到的端口号
- -S program: 指定加密传输时所使用的程序。此程序必须能够理解ssh(1)的选项。
我们在这里使用 -r 指定相同的目录在102主机复制jkd至103
scp -r jdk1.8.0_161/ wko@hadoop103:/opt/module/
同样也可以在hadoop103访问hadoop102,拉取hadoop
scp -r wko@hadoop102:/opt/module/hadoop-3.1.3 ./
也可以在主机103上将102的文件向104传输
scp -r wko@hadoop102:/opt/module/* wko@hadoop104:/opt/module/
分发文件脚本
为了方便之后进行的配置,写一个文件分发的脚本。要让脚本在任何路径都能使用。我们把脚本放在声明了全局环境变量的路径在:/home/wko/bin目录下。
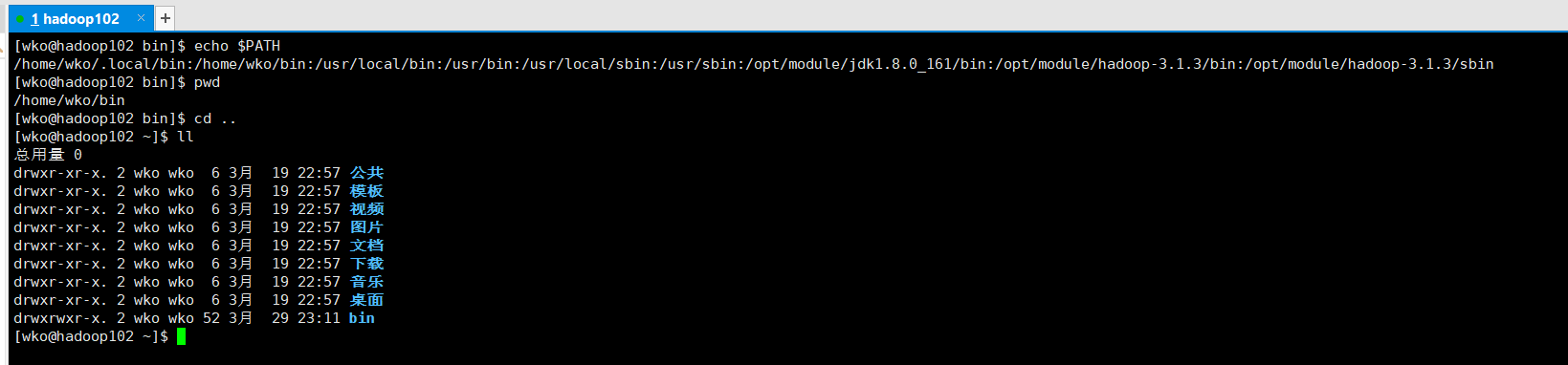
vim xsync
chmod +x xsync 修改权限
#!/bin/bash#1. 判断参数个数if [ $# -lt 1 ]thenecho Not Enough Arguement!exit;fi#2. 遍历集群所有机器for host in hadoop102 hadoop103 hadoop104doecho ==================== $host ====================#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidonedone
编写完成后可以测试一下用xsync发放当前的bin目录
xsync bin./
第一次链接需要输入密码,环境变量也可以这样发送。
xsync /etc/profile.d/my_env.sh
ssh无密码登录配置
配置ssh
基本语法:ssh + ip地址
退出:exit
ssh的免密登录原理:
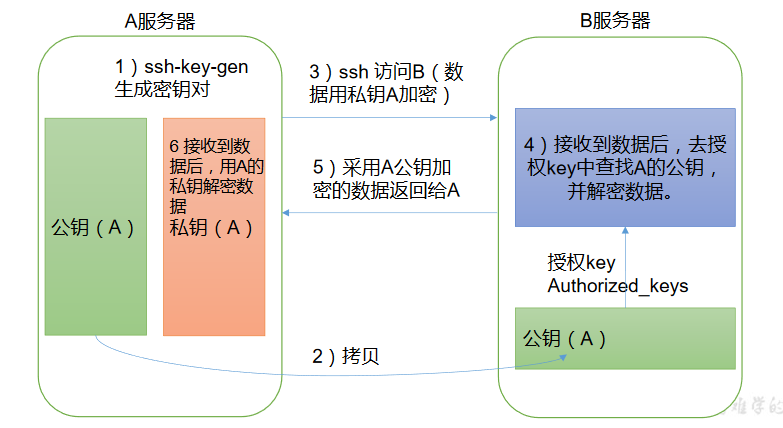
首先要配置ssh要先生成公钥和私钥
ssh-keygen -t rsa —生成id_rsa和id_rsa.pub对应私钥和公钥
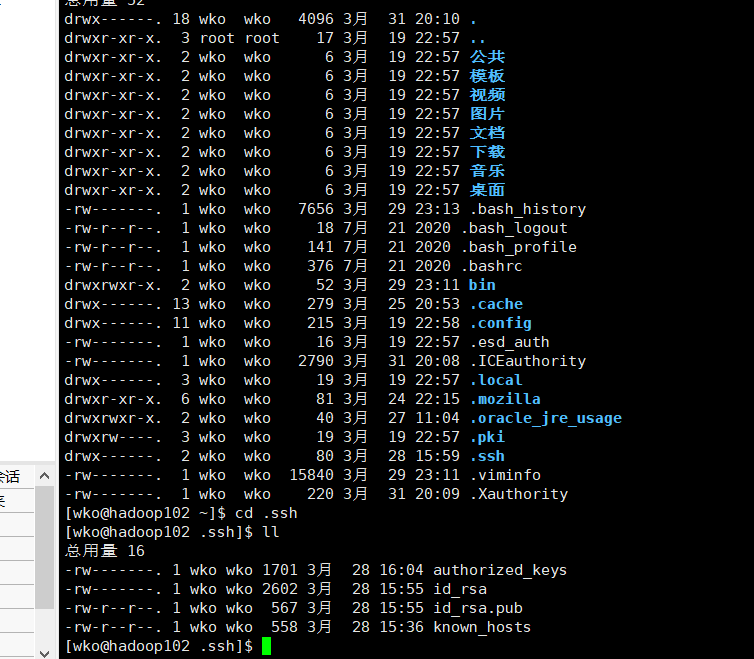
用过ssh登录的主机目录下会有.ssh文件
然后将公钥拷贝到其他要配置免密登录的主机上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
这里还需要用hadoop102的root账号、hadoop103用户和hadoop104用户进行同样的配置。
上图是配置好的.ssh文件各个文件的含义。
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
|---|---|
| id_rsa | 生成的私钥 |
| d_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
集群配置
集群的规划
NameNode、SecondaryNode、和ResourceManage很消耗内存、不要配置到同一台机器上。
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNode、DataNode |
| Yarn | NodeManager | ResourceManager、NodeManager | NodeManager |
配置文件
Hadoop的配置文件有两种:默认配置文件和自定义配置文件。
默认配置文件:core-default.xml、hdfs-default.xml、yarn-default.xml、mapred-default.xml,它存放在Hadoop的jar包中的位置:/hadoop-common-3.1.3.jar/*
自定义配置文件:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml它们存放在:hadoop-3.1.3/etc/hadoop,它可以根据项目需求更改配置。
core-site.xml
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><!-- 指定 NameNode 的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定 hadoop 数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property></configuration>
hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property> <name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>22528</value>
<discription>每个节点可用内存,单位MB</discription>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1500</value>
<discription>单个任务可申请最少内存,默认1024MB</discription>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>16384</value>
<discription>单个任务可申请最大内存,默认8192MB</discription>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/module/hadoop-3.1.3</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1500</value>
<description>每个Map任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3000</value>
<description>每个Reduce任务的物理内存限制</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx1200m</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2600m</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
workers
hadoop102
hadoop103
hadoop104
这里配置workers不允许有多余的空格
以上就是基本的配置文件信息了。
启动集群
第一次启动集群需要进行格式化(这里我们在hadoop102进行格式化)
hdfs namenode -format
启动HDFS
sbin/start-dfs.sh
在配置了ResourceManager的节点启动Yarn
sbin/start-yarn.sh
之前配置了Web端的查看端口
查看HDFS的NN:http://hadoop102:9870
查看Yarn的RM:http://hadoop103:8088
这其中的配置都是我经过各种报错加上去的:
下面的是没有设置检查虚拟内存的属性为false,会一直报错虚拟内存溢出
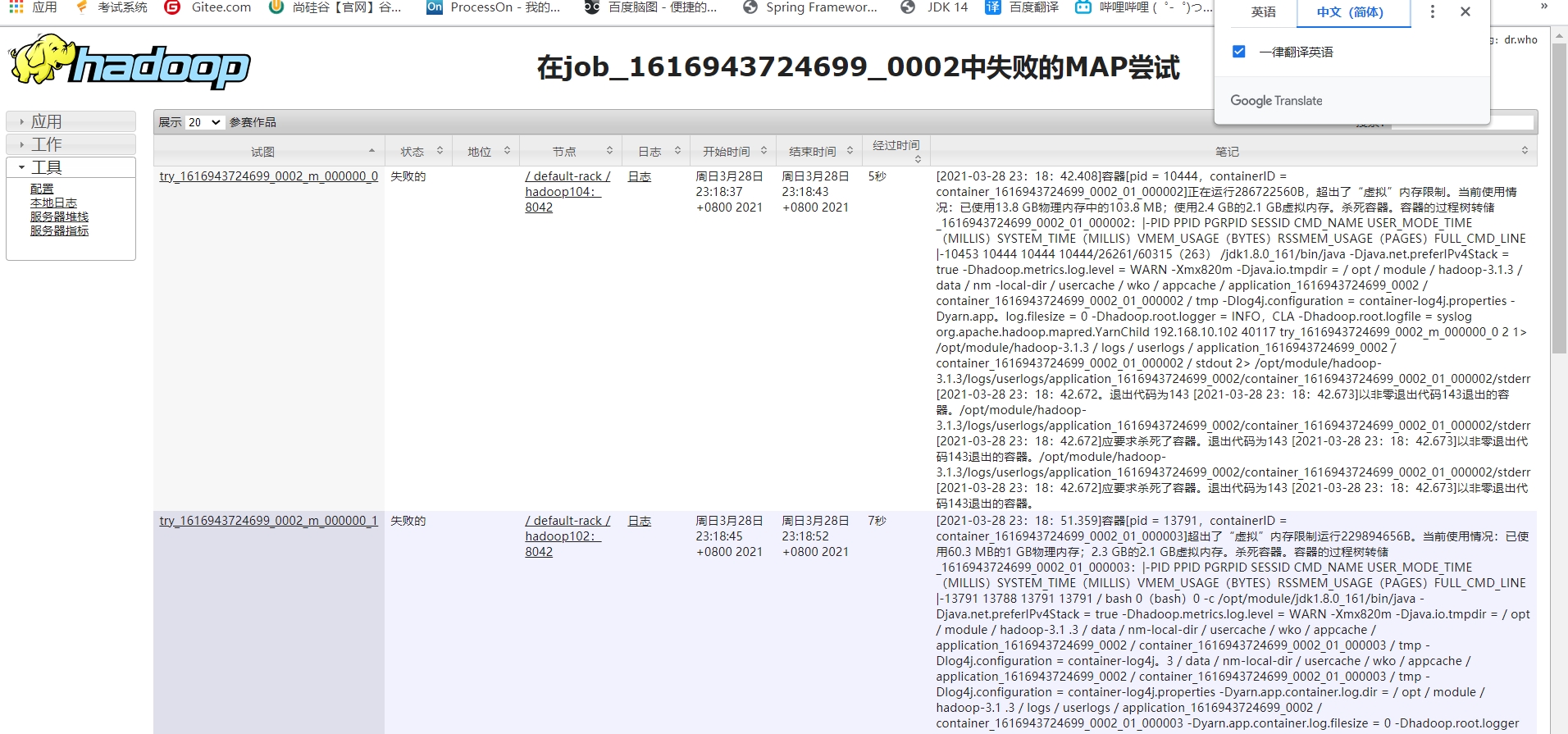
报错exitcode143:mapreduce运行中发现有任务被kill掉,多半是因为内存分配不足造成,需要修改,reduce和map的物理内存限制。
这里出现了内核软死锁,具体原因不知…
解决方案:重新格式化NameNode节点后重新配置(注意要把每个hadoop安装目录下的data和logs目录删去再进行格式化)
在配置完成后可以跑一下hadoop自带的一些例子:
下图就是最终成功配置完成并且跑了测试例子wordcount成功,留图纪念。

若有收获,就点个赞吧
0 人点赞
