最近做的一个项目中,遇到一个难题。某一个存储过程每月执行一次,前几月执行时长均是在3-5个小时,但6月份执行了3天依然还未执行完,异常缓慢!
因此脑海中穷尽所有的可能性:
- 存储过程SQL逻辑有修改吗?
没有,SQL逻辑一直未修改
- 存储过程中涉及的表数据量级有很大的变化吗?
没有,查看了各个表中数据,每个月的数据都是在一个量级
- 存储过程执行过程中是否有死锁等待的问题?
检查了锁表情况,未发现有死锁情况,且存储过程逻辑中也没有可能产生死锁的SQL语句
以上情况均排除掉之后,必须深入到存储过程内部SQL逻辑。由于过程内部用到了游标,且游标内部含有大量逻辑,也涉及很多的INSERT DELETE等DML语句。在过程运行过程中,实际排查发现,执行缓慢确实是发生游标内部逻辑上。
那目前的思路就很明确了,将游标内部的每一段SQL语句都加上耗时统计,记录在一张日志表中。经过不断测试发现,最耗时的SQL如下:
SELECTsum(case when buyer_code = @seller_code then qty else 0 end),sum(case when seller_code = @seller_code then qty else 0 end)from res_sdm_sales_flow_tmp3_p8where product = @productand (seller_code = @seller_code or buyer_code = @seller_code);
该段SQL耗时为19毫秒,但执行此存储过程的时长也在正常范围内,因此本次测试并未复现当时的情景。
正在一筹莫展时,在网上查到资料,可以通过SQL Server Management Studio工具查询到SQL的历史执行信息。因此,特意找到当时执行过程时间较长的时间段,和本次测试的时间段,所对应的SQL执行信息,得到如下信息:
执行异常时间段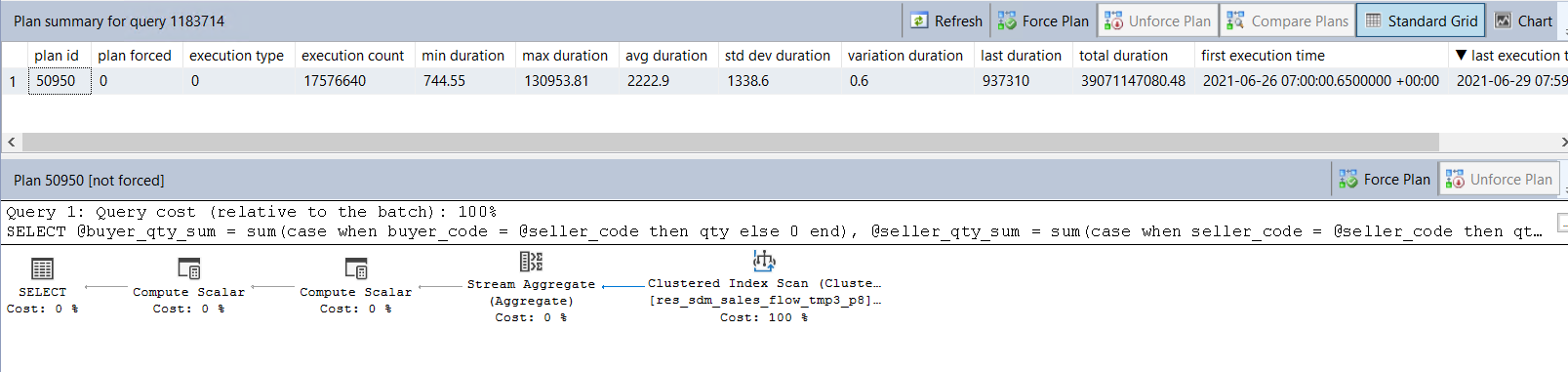
测试时间段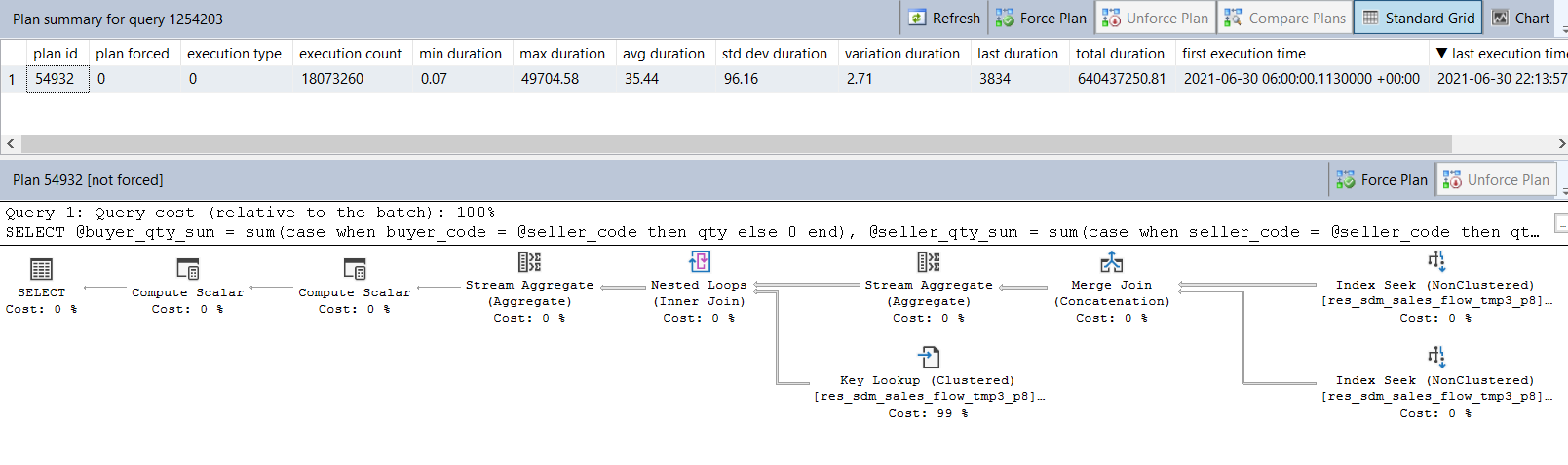
如上图所示,以上SQL两次执行所生成的执行计划是不一样的。执行缓慢的时间段,其执行计划选择了【Clustered Index Scan】这种近乎全表扫描的方式,其平均执行时长为2222 ms;测试时间段,其执行计划选择了【Index Seek】这种通过索引直接查找的方式,其平均执行时长为35 ms,两者相差了67倍左右。
目前可以确定的是,由于执行计划的不同直接导致了执行效率的差异较大。
由于数据库查询优化器在选择执行计划时,会先从执行计划缓存中查找是否有缓存的执行计划,若有,则直接沿用,若缓存中的执行计划是低效的,这就导致了后续查询一直会采用低效的执行计划,从而使得整个存储过程执行变得异常缓慢。
至于为什么在首次编译生成的执行计划是低效的呢?由于执行计划的生成和统计信息有关,因此有可能在生成执行计划时,统计信息过期,导致生成了一个相对低效的执行计划。
因此,针对以上问题,有如下两点解决方案:
在对表res_sdm_sales_flow_tmp3_p8重新插入数据后,重新更新统计信息
UPDATE STATISTICS res_sdm_sales_flow_tmp3_p8;
对以上SQL进行优化处理,确保该查询采用索引查找的方式
SELECT @seller_qty_sum = sum(seller_qty_sum), @buyer_qty_sum = sum(buyer_qty_sum) from(SELECTsum(qty) seller_qty_sum,0 buyer_qty_sumfrom res_sdm_sales_flow_tmp3_p8where product = @productand seller_code = @seller_codeunion allSELECT0,sum(qty)from res_sdm_sales_flow_tmp3_p8where product = @productand buyer_code = @seller_code) a;
针对以上两点优化,至于效果如何,还有待验证……

若有收获,就点个赞吧
0 人点赞
